小小练习。见代码+注释
# 加载必要的包
library(rvest)
library(dplyr)
library(tidyr)
# 指定网页URL
url <- "https://research.un.org/en/unmembers/scmembers"
# 读取网页内容
webpage <- read_html(url)
# 提取所有表格节点
table_nodes <- html_nodes(webpage, "table")
# 将第一个表格转换为数据框
sc_members_table1 <- html_table(table_nodes[1], fill = TRUE)
# 将第二个表格转换为数据框
sc_members_table2 <- html_table(table_nodes[2], fill = TRUE)
# 合并两个数据框
sc_members_combined <- bind_rows(sc_members_table1, sc_members_table2)
# 显示合并后的数据框
print(sc_members_combined)
# 保存合并后的数据框为CSV文件
write.csv(sc_members_combined, "web_data.csv", row.names = FALSE)
# ------------------------------ 处理数据。 ------------------------------
# 读取CSV文件
data <- read.csv("web_data.csv", stringsAsFactors = FALSE)
data
# 删掉最后一列
data <- data[, -ncol(data)]
head(data, 2)
# 拆分Members of Security Council列
print(colnames(data))
# Members.of.Security.Council
# 分割国家为单独的行 Members of Security Council
data_split <- data %>%
separate_rows(`Members.of.Security.Council`, sep = ", ") %>%
select(Year, `Members.of.Security.Council`)
# 重命名列
colnames(data_split) <- c("Year", "Country")
# 列出联合国常任理事国的英文名字
permanent_members <- c("China", "France", "Russian Federation", "United Kingdom", "United States")
# 新建一列 votes,所有值为 1
data_split <- data_split %>%
mutate(votes = 1)
# 新建一列 veto,对于常任理事国,veto 值为 1,否则为 0
data_split <- data_split %>%
mutate(veto = ifelse(Country %in% permanent_members, 1, 0))
# 新建一列 vote_share,根据 Year 列的值进行计算
data_split <- data_split %>%
mutate(vote_share = ifelse(Year >= 1996, 1/15, 1/11))
# 保存结果到新的CSV文件
write.csv(data_split, "clean_data.csv", row.names = FALSE)
# 查看结果
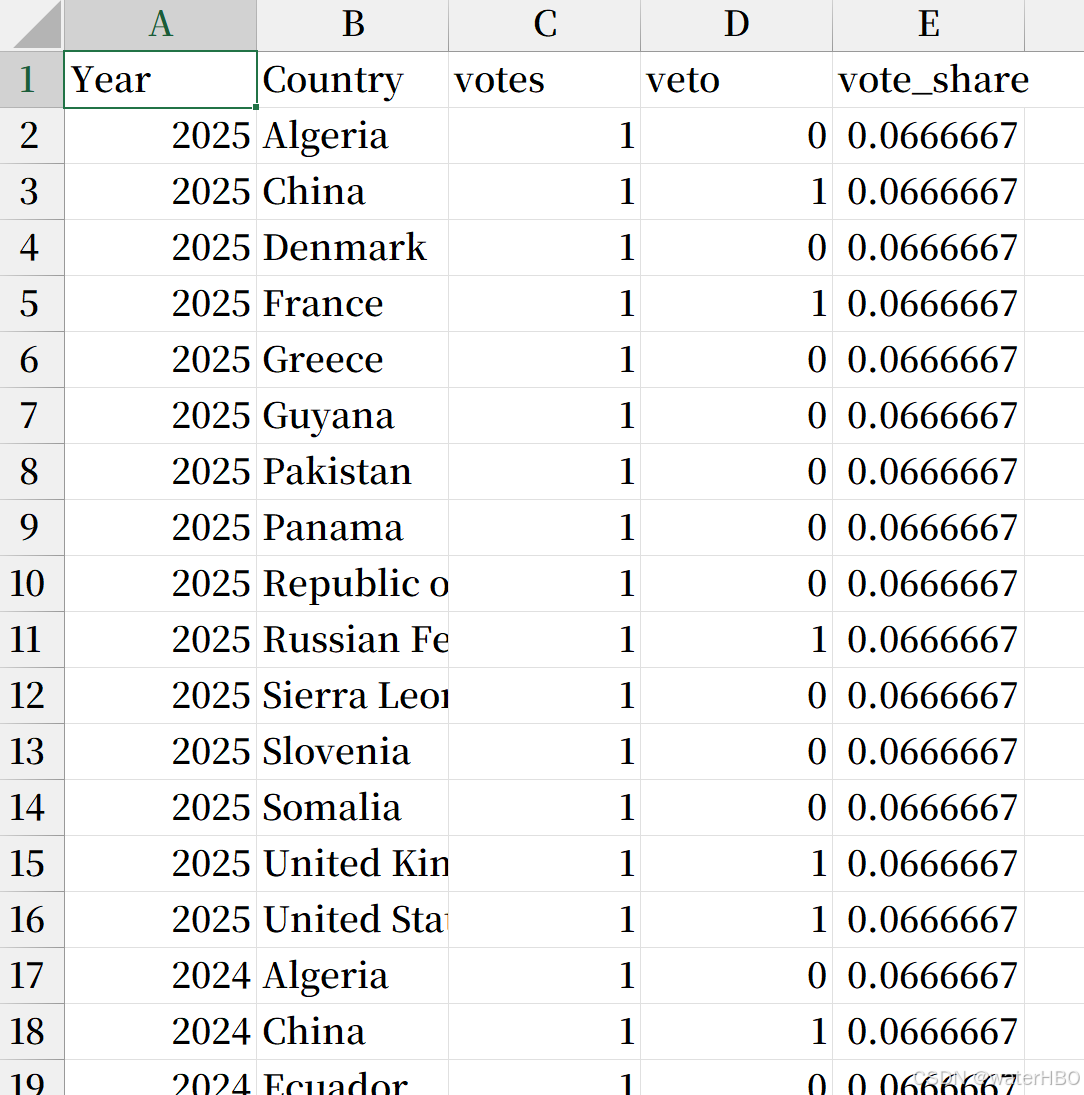
print(data_split)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » R语言 爬取数据+简单清洗

发表评论 取消回复