文章目录
1. 网络爬虫简介
1.1 什么是网络爬虫?
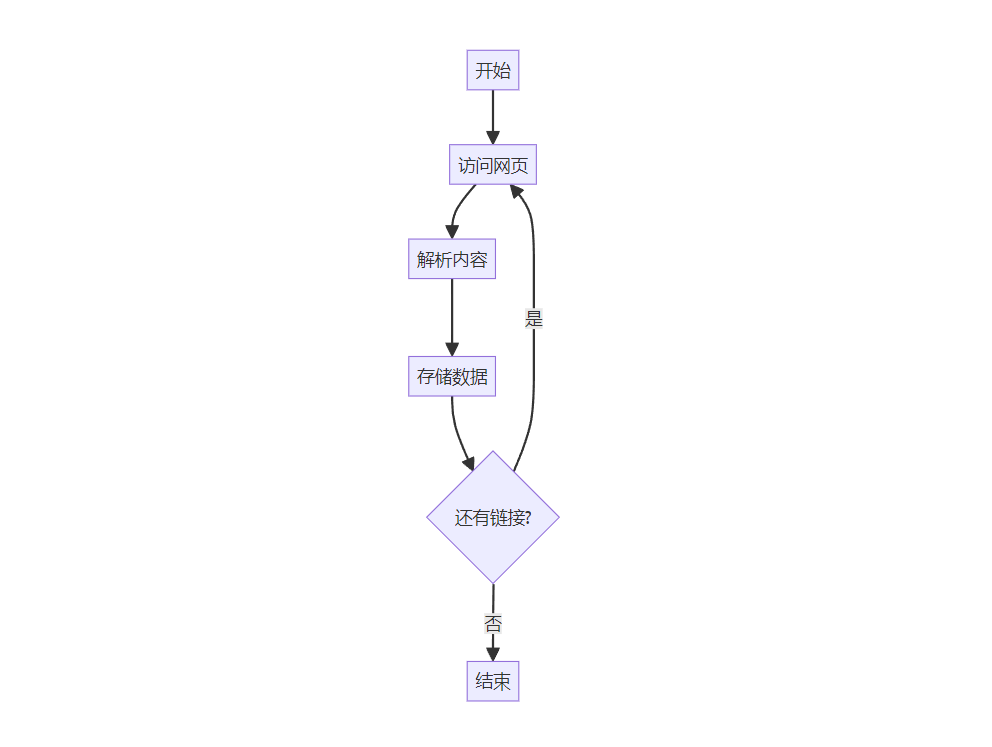
网络爬虫是一种自动化程序或脚本,能够系统地浏览互联网,以获取和处理特定信息。它按照预设的规则,通过访问网页、解析内容和存储数据三个主要步骤来工作。网络爬虫主要用于搜索引擎索引网页或为特定应用收集数据。
网络爬虫工作流程图:
1.2 网络爬虫的应用领域
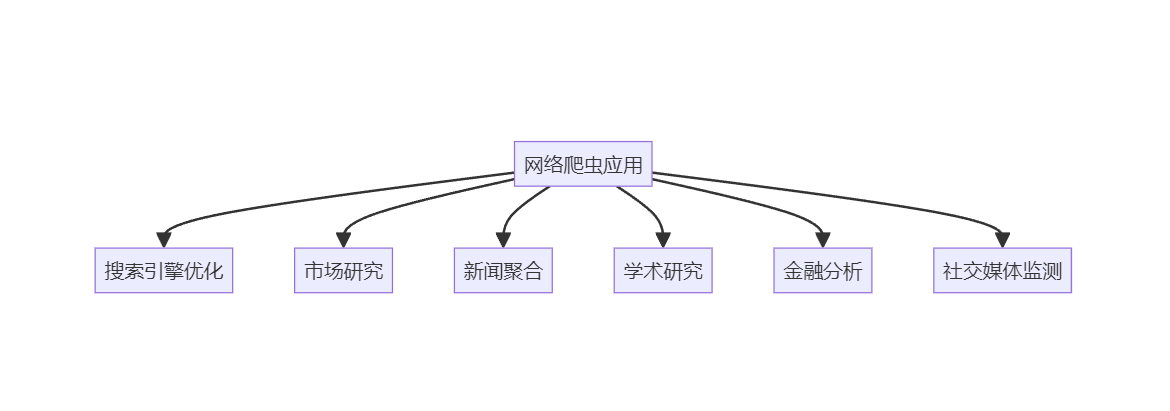
网络爬虫在多个领域都有广泛应用:
- 搜索引擎优化(SEO): 爬虫用于收集和分析网站数据,帮助提高搜索排名。
- 市场研究: 收集竞争对手价格、产品信息等市场数据。
- 新闻聚合: 自动收集各大新闻网站的最新报道。
- 学术研究: 收集大规模数据用于数据分析和机器学习。
- 金融分析: 实时获取股票价格、经济指标等金融数据。
- 社交媒体监测: 收集和分析社交平台上的用户评论和趋势。
1.3 网络爬虫面临的主要挑战
网络爬虫在执行任务时会遇到一些挑战,这些挑战包括技术、法律和运营方面的问题。下表列出了主要的挑战及其描述:
| 挑战 | 描述 |
|---|---|
| 爬虫验证机制 | 许多网站实施了安全验证技术,如验证码等。 |
| 隐私泄露问题 | 爬虫可能涉及网络活动被追踪,导致隐私泄露等问题。 |
| 网页结构变化 | 网站频繁更新可能导致爬虫失效。 |
| 大规模数据处理 | 处理和存储海量数据需要强大的计算资源。 |
| 动态内容 | JavaScript渲染的内容难以直接抓取。 |
| 网络带宽限制 | 网络延迟和带宽限制可能影响爬虫效率。 |
2. 代理IP:爬虫的得力助手
2.1 代理IP的定义和工作原理
代理IP是一种中间服务器,它充当客户端和目标服务器之间的桥梁。当使用代理IP时,您的请求首先发送到代理服务器,然后由代理服务器转发到目标网站。
工作原理如下步骤所示:
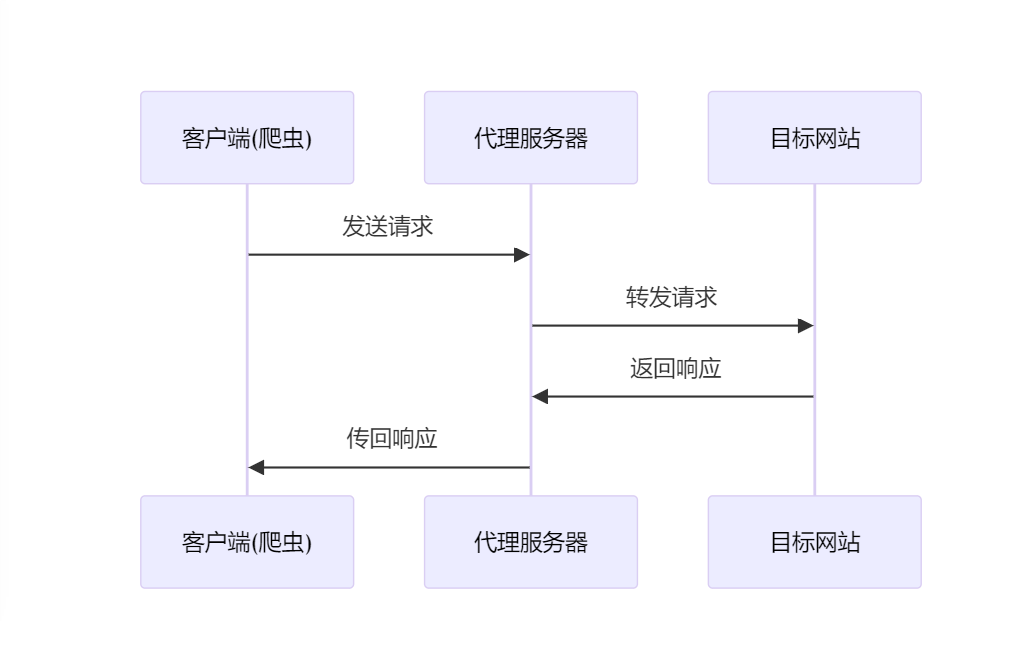
| 步骤 | 描述 |
|---|---|
| 1 | 客户端(爬虫)向代理服务器发送请求。 |
| 2 | 代理服务器接收请求并转发给目标网站。 |
| 3 | 目标网站响应代理服务器。 |
| 4 | 代理服务器将响应传回客户端。 |
2.2 爬虫使用代理IP的必要性
爬虫使用代理IP主要是为了解决以下问题:
- 避免爬虫失效:单IP频繁请求,可能会触发网站验证机制,导致爬虫任务中断。使用代理IP并对其轮换,可合理控制请求频率,降低同一IP频繁访问的风险,从而维持爬虫的正常运行。
- 获取更真实的数据:某些网站会因为所在的地理位置差异而导致信息也有所差异。此时,可使用相应地区的代理IP发起真实有效的请求,从而可获取到当地真实的公开数据。
- 提高安全性:使用个人真实IP容易被网站追踪,从而增加隐私泄露的风险。而代理IP可保护你的真实IP,提高爬虫的安全性。
- 增加并发能力:单个IP的请求数量有限,无法满足大量数据爬取的需求。使用多个代理IP同时发起多个请求,可大幅提升爬取效率。
综上所述,通过合理使用代理IP,可以更有效地应对爬虫过程中出现的各种技术障碍,提高数据采集的效率和可靠性。在接下来的章节中,我们将深入探讨不同类型的代理IP及其在爬虫中的具体应用。
3. 代理IP的类型及其在爬虫中的应用
3.1 动态住宅代理
这些IP地址来自真实的住宅用户,因此具有很高的匿名性和隐私性,不易被别为代理IP。而增加了爬虫任务的安全性。这类代理有以下特点:
- 高安全性:使用这类代理可发起真实有效的请求,提高爬虫效率的同时,大大降低了个人隐私泄露的风险。
- 地域覆盖广泛:动态住宅代理通常覆盖全球多个国家地区的IP,为用户提供了极大的灵活性和便利性,特别是在进行跨国市场调研、内容分发或数据分析等任务时,显得尤为重要。
- 灵活性:用户可以根据需要灵活控制代理IP的会话时长,避免单一IP超负载而导致爬虫失败。
- 价格相对较高:这主要是因为管理和维护大量的真实住宅IP地址,并且确保其稳定性和可用性
3.2 动态数据中心代理
这些IP地址由专业数据中心提供。它们的特点是速度快、灵活性高、价格相对便宜且数量多。适合用于大规模、高速爬取任务以及对速度要求高的项目。
- 响应快速:部署在高性能服务器上,提供极快的网络请求速度,适合大规模、高速爬取任务。
- 高稳定性:由专业数据中心维护,具备高可用性和冗余设计,确保服务稳定可靠。
- 性价比高:相对于其他类型的代理,价格更低,适合预算有限但仍需大大量代理IP的用户。
综上这两种代理类型是爬虫中最常用的,你可以根据自己预算、项目规模等综合考虑,选择最适合你项目的代理类型。
4. 选择合适的代理IP服务
4.1 评估代理IP质量的关键指标
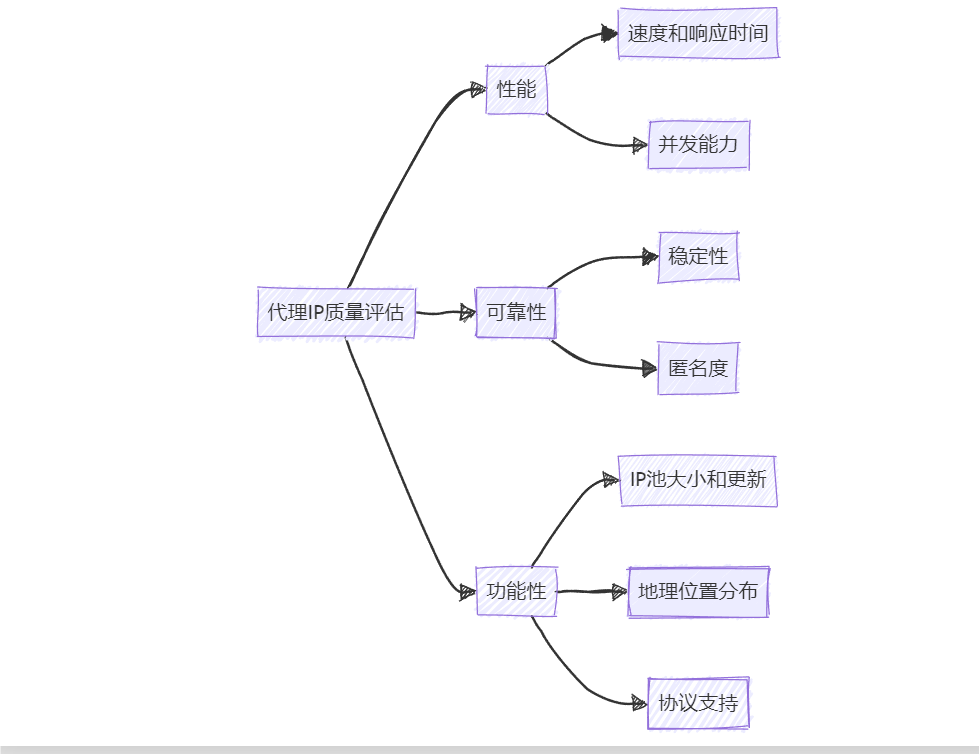
选择高质量的代理IP服务对于爬虫效率至关重要。以下是一些关键评估指标:
| 指标 | 描述 |
|---|---|
| 速度和响应时间 | 测试代理IP的响应速度;评估不同地理位置的速度表现 |
| 可靠性和稳定性 | 检查代理IP的上线时间;评估连接失败率 |
| 匿名度 | 验证代理IP;检查是否泄露HTTP头信息 |
| IP地址池大小和更新频率 | 确认可用IP数量是否满足您的需求;了解IP更新的频率 |
| 地理位置分布 | 检查是否提供您所需要的特定地区的IP;评估全球覆盖范围 |
| 协议支持 | 确认是否支持HTTP、HTTPS、SOCKS5等所需协议 |
| 并发连接数 | 了解单个账户可同时使用的最大连接数 |
| 客户支持和文档 | 评估技术支持的响应速度和质量;检查API文档的完整性和清晰度 |
4.2 考虑爬虫项目的特定需求
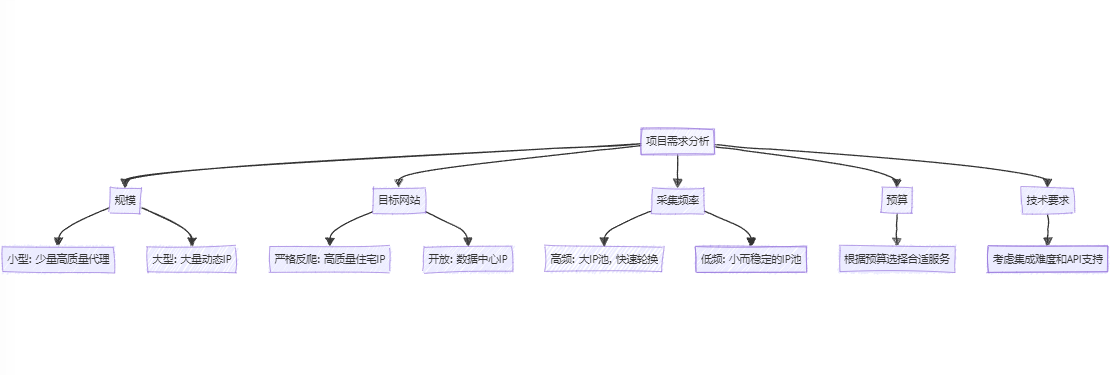
根据您的具体项目需求选择合适的代理IP服务:
-
项目规模
- 小型项目可能只需要少量高质量代理
- 大型项目可能需要大量动态IP和更高的并发能力
-
目标网站特征
- 针对反爬虫措施严格的网站,可能需要高质量的住宅IP
- 对于内容较为开放的网站,数据中心IP可能足够
-
数据采集频率
- 高频采集可能需要更大的IP池和更快的IP轮换
- 低频采集可以考虑使用较小但稳定的IP池
-
预算限制
- 权衡代理服务的成本和项目预算
- 考虑性价比,不一定最贵的服务就是最适合的
-
技术集成
- 评估代理服务是否易于集成到您现有的爬虫系统
- 检查是否提供所需的API和SDK
4.3 如何测试代理IP的有效性
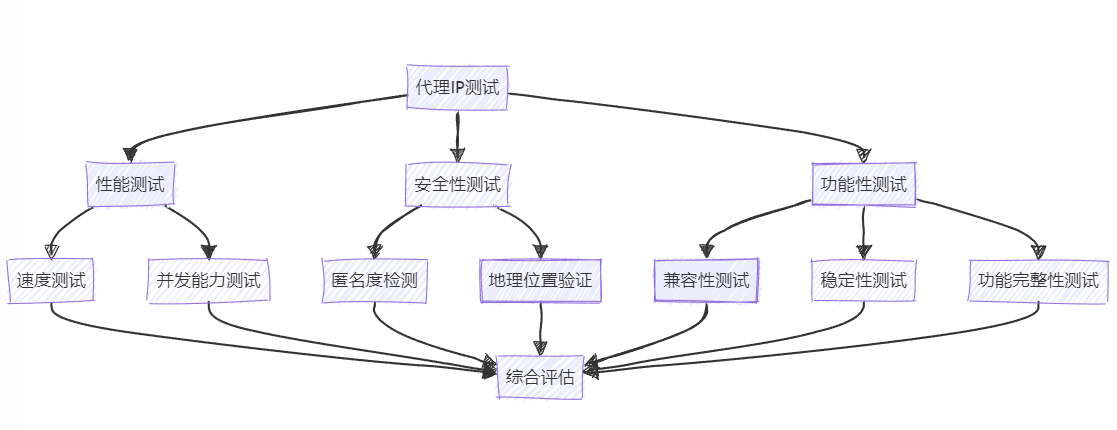
在正式使用前,对代理IP进行全面测试是非常必要的:
-
速度测试
- 使用ping工具测试响应时间
- 进行实际网页加载速度测试
-
匿名度检测
- 使用在线工具检查IP是否定位精准
- 验证请求头信息是否泄露身份
-
稳定性测试
- 进行长时间连续测试,检查连接稳定性
- 测试在高并发情况下的表现
-
兼容性测试
- 测试与目标网站的兼容性
- 检查是否能正常访问需要爬取的内容
-
并发能力测试
- 测试最大并发连接数
- 评估在高并发下的性能表现
-
功能性测试
- 测试IP轮换功能是否正常
- 验证会话保持能力
通过综合考虑这些因素并进行充分的测试,您可以选择最适合您爬虫项目需求的代理IP服务。记住,最佳的选择往往是在性能、可靠性、成本和特定需求之间找到平衡点。我目前使用的是IPIDEA代理,经过以上测试它在速度、稳定性、功能性、并发能力、覆盖地区等各方面都不错,如果你想免费测试,点击这里领取。
5. 代理IP在爬虫中的案例实践(推荐)
5.1 获取代理IP
这里我们以IPIDEA为例,注册账号并完成实名认证后,可领取免费测试,然后点击API获取进行代理提取
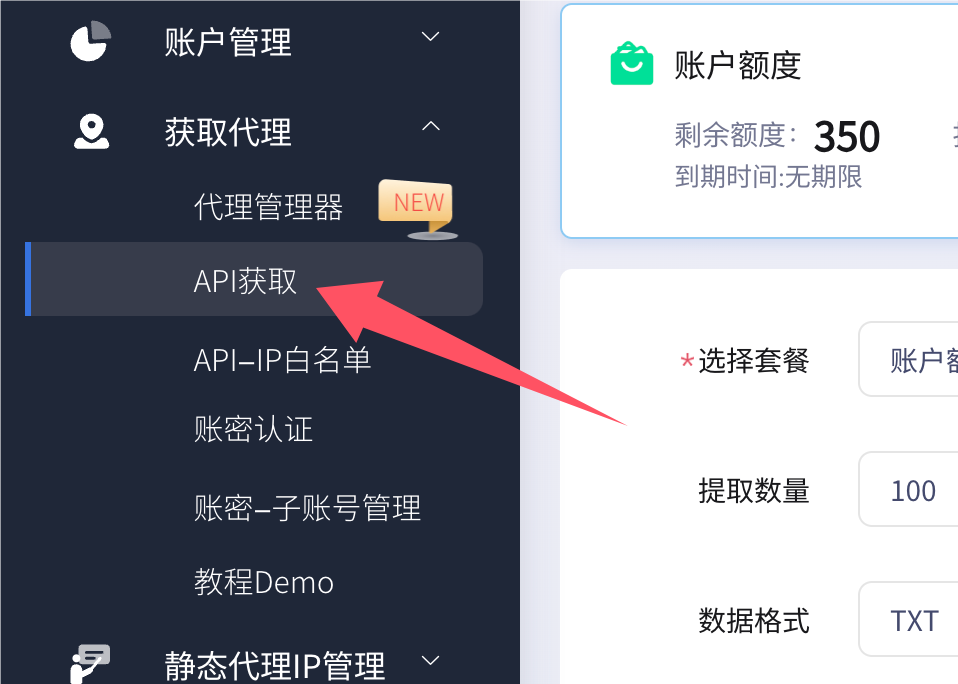
接着开始根据自己的需求选择配置:
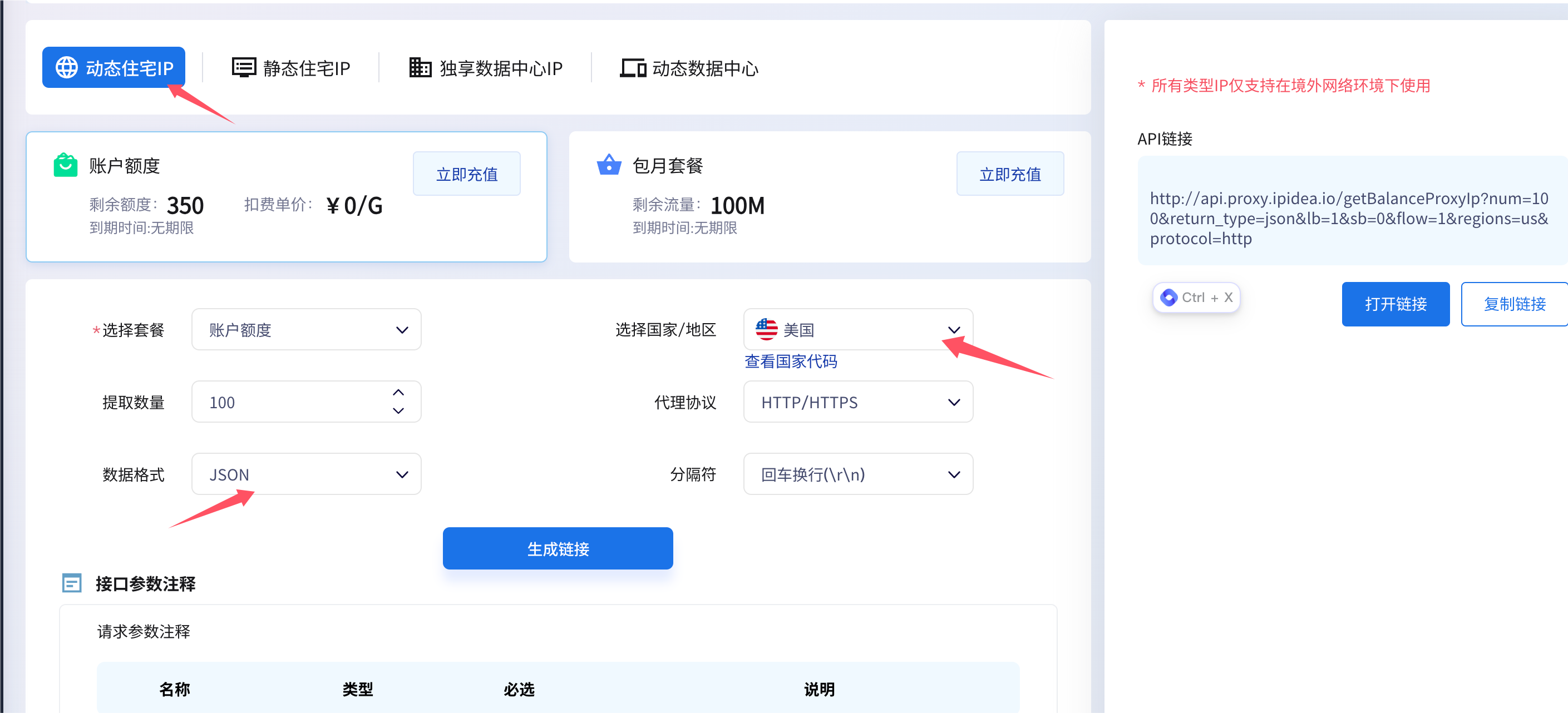
复制好右侧生成的链接,用以下代码来获取IP:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import requests
def seleniumSetUP(ip, port):
# 设置Chrome驱动程序的路径
# 创建Chrome浏览器实例
chrome_options = Options()
# 配置获取到的ip和port
chrome_options.add_argument(f'--proxy-server=http://{ip}:{port}')
browser = webdriver.Chrome(options=chrome_options)
# 使用代理访问
browser.get('http://ipinfo.io')
print(browser.page_source)
if __name__ == '__main__':
# 获取代理的url,一次仅获取一条
porxyUrl = "http://api.proxy.ipidea.io/getBalanceProxyIp?num=100&return_type=json&lb=1&sb=0&flow=1®ions=us&protocol=http"
# 访问并获取代理
ipInfo = requests.get(porxyUrl)
print(ipInfo.json())
info = ipInfo.json()["data"]
# 解析json,获取代理服务器地址
ip = info[0]["ip"]
# 解析json,获取代理的端口
port = info[0]["port"]
# 获取到的代理信息传入到selenium中进行配置
seleniumSetUP(ip, port)
运行输出如下:
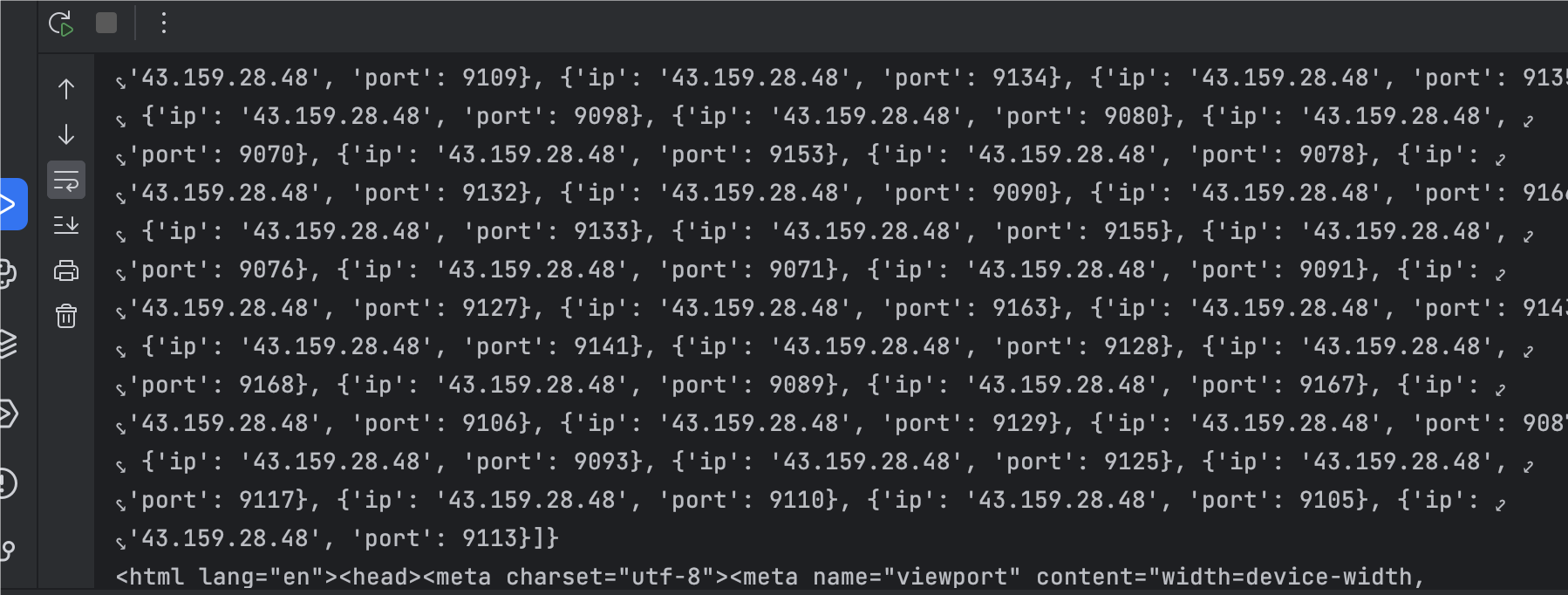
5.2 实战使用案例
这里以抓某AI网站为例,分析如下:
由于该网站对某些机制而无法直接获取,但我们使用代理IP就可以正常访问。完整代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import requests
from time import sleep
# 授权码
usertoken='free-for-anyone'
def seleniumSetUP(ip, port):
# 设置Chrome选项和代理
chrome_options = Options()
chrome_options.add_argument(f'--proxy-server=http://{ip}:{port}')
browser = webdriver.Chrome(options=chrome_options)
# 使用代理访问
browser.get('https://share.mosha.cloud/auth/login?carid=xxx')
sleep(3)
# 输入邮箱
email_field = browser.find_element(By.NAME, 'usertoken')
email_field.send_keys(usertoken)
# 提交表单
submit_button = browser.find_element(By.NAME, 'action')
submit_button.click()
# 等待登录完成
sleep(60)
# browser.quit() # 退出
if __name__ == '__main__':
proxy_url = "http://api.proxy.ipidea.io/getBalanceProxyIp?num=100&return_type=json&lb=1&sb=0&flow=1®ions=us&protocol=http"
ip_info = requests.get(proxy_url)
info = ip_info.json()["data"]
ip = info[0]["ip"]
port = info[0]["port"]
seleniumSetUP(ip, port)
效果如下所示
6. 总结
代理IP在现代网络爬虫中起着至关重要的作用。它不仅可以有效提高数据采集效率,还能提高爬虫的安全性和匿名性。通过合理选择和使用代理IP,可以显著提升爬虫的性能和数据获取能力。以IPIDEA为例,它提供了高质量的代理IP服务,包括数据中心代理和住宅代理,静态代理和动态代理,且地理覆盖广泛,能够满足不同业务的需求,如果对爬虫项目感兴趣的,可以这里领取免费测试。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 网络爬虫必备工具:代理IP科普指南

发表评论 取消回复