仍有一些标准库设施在很多应用中都是有用的:tuple、bitset、正则表达式以及随机数。还将介绍一些附加的I/O库功能:格式控制、未格式化I/O和随机访问
1、tuple 类型
1、tuple 是类似 pair 的模板。不同 tuple 类型的成员类型也不同,但一个 tuple 可以有任意数量的成员。每个确定的 tuple 类型的成员数目是固定的,但一个 tuple 类型的成员数目 可以与另一个 tuple 类型不同
希望 将一些数据组合成单一对象,而又不想 定义一个新的数据结构来表示这些数据
2、tuple 类型 及其伴随类型 和 函数 都定义在 tuple 头文件中
tuple 支持的操作
| 代码 | 操作 |
|---|---|
| tuple<T1, T2, …, Tn> t; | t 是一个 tuple,成员数为 n,第 i 个成员的类型为 Ti。所有成员都进行初始值初始化 |
| tuple<T1, T2, …, Tn> t(v1, v2, …, vn); | t 是一个 tuple,成员类型为 T1…Tn,每个成员用对应的初始值 v1 进行初始化。构造函数是 explicit 的,阻止隐式类型转换 和 复制初始化 |
| make_tuple(v1, v2, …, vn) | 返回一个 用给定初始值 初始化的 tuple。tuple 的类型从初始值的类型推断 |
| t1 == t2 t1 != t2 | 当两个tuple具有相同数量的成员且成员对应相等时,两个tuple相等。这两个操作使用成员的==运算符完成。一旦发现某对成员不等,接下来的成员就不用比较了 |
| t1 relop t2 | tuple 的关系运算使用字典序。两个 tuple 必须具有相同数量的成员。使用 < 运算符比较 t1 和 t2 中的对应成员 |
get<i>(t) | 返回 t 的第 i 个成员的引用;如果 t 是一个左值,结果是一个左值引用;否则,结果是一个右值引用。tuple 的所有成员都是 public 的 |
tuple_size<tupleType>::value | 一个类模板,可以通过一个 tuple 类型来初始化。它有一个名为 value 的 public constexpr static 数据成员,类型为 size_t,表示给定 tuple 类型中成员的数量 |
| tuple_element<i, tupleType>::type | 一个类模板,可以通过一个整型常量和一个 tuple 类型来初始化。它有一个名为 type 的 public 成员,表示给定 tuple 类型中指定成员的类型 |
tuple_size<tupleType>::value:
#include <iostream>
#include <tuple>
#include <type_traits>
int main() {
// 定义一个包含三个不同类型元素的 std::tuple
std::tuple<int, double, std::string> myTuple;
// 使用 tuple_size 获取 tuple 的大小
constexpr std::size_t tupleSize = std::tuple_size<decltype(myTuple)>::value;
// 打印 tuple 的大小
std::cout << "The size of the tuple is: " << tupleSize << std::endl;
return 0;
}
tuple_element<i, tupleType>::type:
#include <iostream>
#include <tuple>
#include <type_traits>
int main() {
// 定义一个包含三个不同类型元素的 std::tuple
std::tuple<int, double, std::string> myTuple;
// 给每个返回的类型赋予类型别名
// 使用 tuple_element 获取 tuple 中第一个元素的类型
using FirstElementType = std::tuple_element<0, decltype(myTuple)>::type;
// 使用 tuple_element 获取 tuple 中第二个元素的类型
using SecondElementType = std::tuple_element<1, decltype(myTuple)>::type;
// 使用 tuple_element 获取 tuple 中第三个元素的类型
using ThirdElementType = std::tuple_element<2, decltype(myTuple)>::type;
// 打印这些类型的信息
std::cout << "The type of the first element is: " << typeid(FirstElementType).name() << std::endl;
std::cout << "The type of the second element is: " << typeid(SecondElementType).name() << std::endl;
std::cout << "The type of the third element is: " << typeid(ThirdElementType).name() << std::endl;
return 0;
}
typeid 用于获取表达式或类型的类型信息,typeid 返回一个 type_info 对象,该对象包含类型的信息,name() 是 type_info 类的一个成员函数,返回一个指向以 null 结尾的字符数组的指针,该数组包含了一个实现定义的、表示类型名称的字符串
// 基础类型
int a = 42;
double b = 3.14;
// 使用 typeid 获取基础类型的信息
std::cout << "Type of a: " << typeid(a).name() << std::endl;
std::cout << "Type of b: " << typeid(b).name() << std::endl;
1.1 定义和初始化 tuple
1、定义一个 tuple 时,需要指出每个成员的类型:
tuple<size_t, size_t, size_t> threeD; //三个成员都设置为 0
tuple<string, vector<double>, int, list<int>>
someVal("constants", {3.14, 2.718}, 42, {0,1,2,3,4,5})
tuple 的这个构造函数是 explicit 的,因此 必须使用直接初始化语法:
tuple<size_t, size_t, size_t> threeD = {1,2,3}; // 错误
tuple<size_t, size_t, size_t> threeD{1,2,3}; // 正确
类似 make_pair 函数:std::make_pair(1, "one") -> 创建 std::pair<int, const char*> 对象
标准库定义了 make_tuple 函数,还可以用它来生成 tuple 对象:
// 表示书店交易记录的 tuple,包括:ISBN、数量和每本书的价格
auto item = make_tuple("0-999-78345-X", 3, 20.00);
类似 make_pair,make_tuple 函数使用初始值的类型来推断 tuple 的类型,item 是一个 tuple,类型为 tuple<const char*, int, double>
2、访问 tuple 的成员
一个 pair 总是有两个成员,这样,标准库就可以为它们命名(如 first 和 second)。因为一个 tuple 类型的成员数目 是没有限制的。因此,tuple 的成员 都是未命名的。要访问一个 tuple 的成员,就要使用一个名称为 get 的标准库函数模板。为了使用 get,必须指定 一个显式模板实参,它指出我们想要访问第几个成员
传递给 get 一个 tuple 对象,它返回指定成员的引用:
auto book = get<0>(item); // 返回 item 的第一个成员
auto cnt = get<1>(item); // 返回 item 的第二个成员
auto price = get<2>(item)/cnt; // 返回 item 的最后一个成员
get<2>(item) *= 0.8; // 打折 20%
尖括号中的值 必须是一个整型常量表达式,从 0 开始计数
如果不知道一个 tuple 确切的类型细节信息,可以 用两个辅助类模板 来查询 tuple 成员的数量和类型:
typedef decltype(item) trans; // trans 是 item 的类型
// 返回 trans 类型对象中成员的数量
size_t sz = tuple_size<trans>::value; // 返回 3
// cnt 的类型与 item 中第二个成员相同
tuple_element<1, trans>::type cnt = get<1>(item);
// cnt 是一个 int,tuple_element<1, trans>::type == int
为了使用 tuple_size 或 tuple_element,需要知道一个 tuple 对象的类型。确定一个对象的类型的最简单方法 就是使用 decltype。使用 decltype 来为 item 类型定义一个类型别名,用它来实例化两个模板
3、关系 和 相等运算符
tuple 的关系和相等运算符的行为 类似于容器的对应操作,这些运算符 逐对 比较左侧 tuple 和右侧 tuple 的成员。只有两个 tuple 具有相同数量的成员时,才可以比较它们
为了使用 tuple 的相等或不等运算符,对每对成员使用 == 运算符都是合法的;为了使用关系运算符,对每对成员使用 < 必须都是合法的
tuple<string, string> duo("1", "2");
tuple<size_t, size_t> twoD(1, 2);
bool b = (duo == twoD); // 错误:不能比较 size_t 和 string
tuple<size_t, size_t, size_t> threeD(1, 2, 3);
b = (twoD < threeD); // 错误:成员数量不同
tuple<size_t, size_t> origin(0, 0);
b = (origin < twoD); // 正确:b 是 true
由于 tuple 定义了 < 和 == 运算符,可以将 tuple 序列传递给算法,并且可以在无序容器中将 tuple 作为关键字类型
4、重写 12.3 节中的 TextQuery 程序,使用 tuple 替代 QueryResult 类
希望将一些数据合并成 单一对象,但又不想定义一个 新数据结构 表示这些数据
TextQuery.h
#pragma once
#ifndef TEXTQUERY_H_
#define TEXTQUERY_H_
#include <string>
#include <vector>
#include <map>
#include <fstream>
#include <sstream>
#include <set>
#include <memory>
#include <iostream>
#include <algorithm>
#include <iterator>
#include <tuple>
// // 用 std::tuple<std::string, std::shared_ptr<std::set<TextQuery::line_no>>, std::shared_ptr<std::vector<std::string>>>
// class QueryResult;
class TextQuery
{
public:
using line_no = std::vector<std::string>::size_type;
TextQuery(std::ifstream&);
// 把QueryResult换掉
std::tuple <std::string, std::shared_ptr<std::set<TextQuery::line_no>>, std::shared_ptr<std::vector<std::string>>> query(const std::string&) const;
private:
std::shared_ptr<std::vector<std::string>> file;
std::map<std::string, std::shared_ptr<std::set<line_no>>> wm;
};
//class QueryResult
//{
// friend std::ostream& print(std::ostream&, const QueryResult&);
//public:
// QueryResult(std::string s, std::shared_ptr<std::set<TextQuery::line_no>> p, std::shared_ptr<std::vector<std::string>> f) : sought(s), lines(p), file(f) { }
//private:
// std::string sought;
// std::shared_ptr<std::set<TextQuery::line_no>> lines;
// std::shared_ptr<std::vector<std::string>> file;
//};
TextQuery::TextQuery(std::ifstream& ifs) : file(new std::vector<std::string>)
{
std::string text;
while (std::getline(ifs, text))
{
file->push_back(text);
int n = file->size() - 1;
std::istringstream line(text);
std::string text;
while (line >> text)
{
std::string word;
std::copy_if(text.begin(), text.end(), std::back_inserter(word), isalpha);
// std::cout << word << std::endl;
auto& lines = wm[word];
if (!lines)
lines.reset(new std::set<line_no>);
lines->insert(n);
}
}
}
std::tuple <std::string, std::shared_ptr<std::set<TextQuery::line_no>>, std::shared_ptr<std::vector<std::string>>> TextQuery::query(const std::string& sought) const
{
static std::shared_ptr<std::set<TextQuery::line_no>> nodata(new std::set<TextQuery::line_no>);
auto loc = wm.find(sought);
if (loc == wm.end())
return std::tuple <std::string, std::shared_ptr<std::set<TextQuery::line_no>>, std::shared_ptr<std::vector<std::string>>>(sought, nodata, file);
else
return std::tuple <std::string, std::shared_ptr<std::set<TextQuery::line_no>>, std::shared_ptr<std::vector<std::string>>>(sought, loc->second, file);
}
std::ostream& print(std::ostream& os, const std::tuple <std::string, std::shared_ptr<std::set<TextQuery::line_no>>, std::shared_ptr<std::vector<std::string>>>& qr)
{
// get<>()获取 tuple 中的元素
os << std::get<0>(qr) << " occurs " << std::get<1>(qr)->size() << " " << std::endl;
for (auto num : *std::get<1>(qr))
os << "\t(line " << num + 1 << ") " << *((std::get<2>(qr))->begin() + num) << std::endl;
return os;
}
#endif
12.3.cpp
#include <iostream>
#include <string>
#include "TextQuery.h"
void runQueries(std::ifstream& infile)
{
TextQuery tq(infile);
while (true) {
std::cout << "enter word to look for, or q to quit: ";
std::string s;
if (!(std::cin >> s) || s == "q") break;
print(std::cout, tq.query(s)) << std::endl;
// tq.query(s);
}
}
int main()
{
std::ifstream file("data.txt");
runQueries(file);
}
运行结果
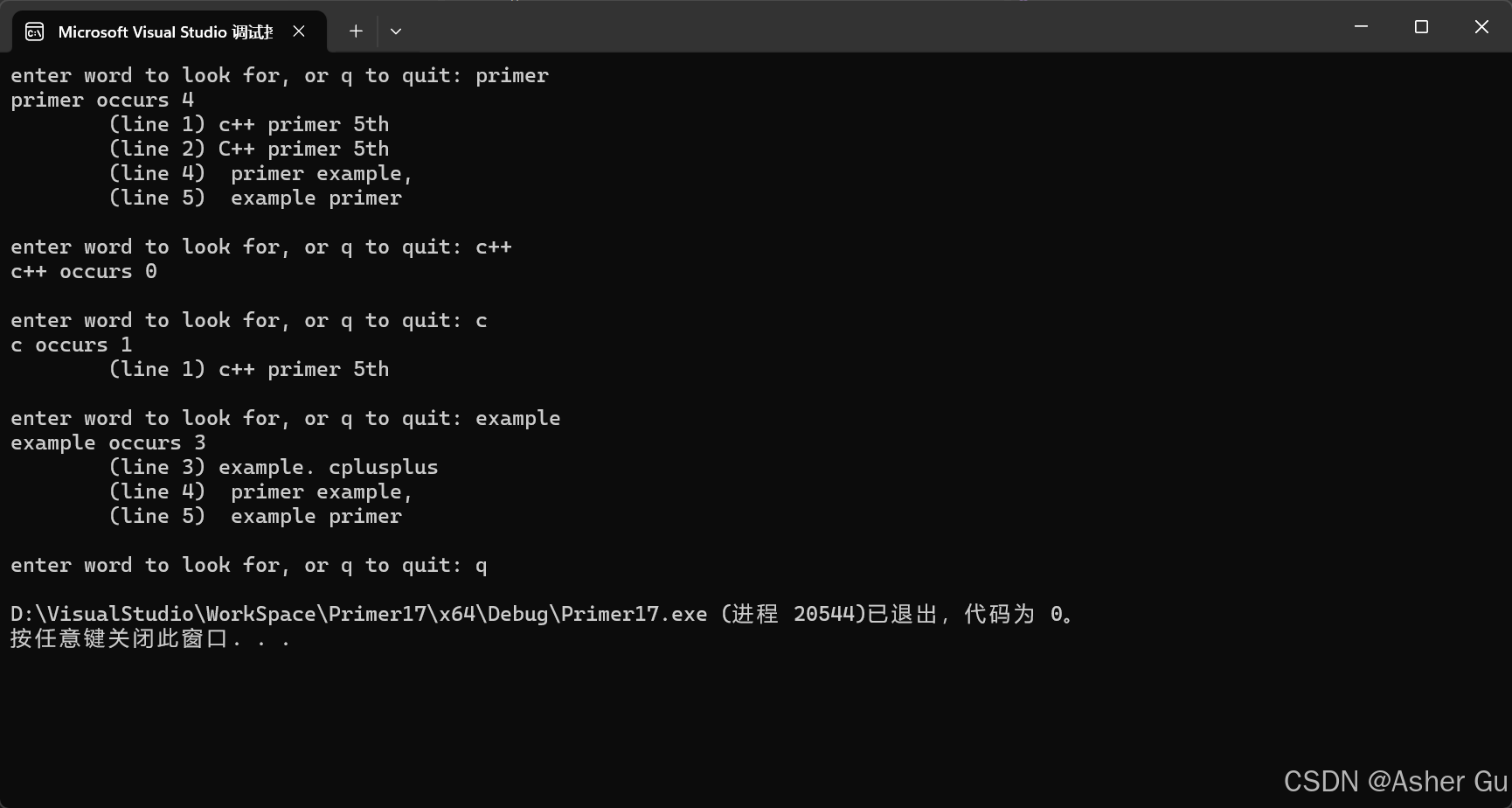
1.2 使用 tuple 返回多个值
1、假设每家书店都有一个销售记录文件。每个 Sales_data 文件都将每本书的所有销售记录 ISBN 存放在一个 vector 中。为每个书店创建一个 vector<Sales_data>,并将这些 vector 保存在 vector 的 vector 中:
// files 中的每个元素保存一家书店的销售记录
vector<vector<Sales_data>> files;
对每家有匹配销售记录的书店,将创建一个 tuple 来保存这家书店的索引和两个迭代器。索引 指出了书店在 files 中的位置,而两个迭代器 则标记了给定书籍 在此书店的 vector<Sales_data> 中第一条销售记录 和 最后一条销售记录之后的位置
2、返回 tuple 的函数
首先编写 查找给定书籍的函数。此函数的参数 是刚刚提到的 vector 的 vector 以及一个表示书籍 ISBN 的 string。函数 将返回一个 tuple 的 vector,凡是销售了给定书籍的书店,都在 vector 中有一项:
// matches 有三个成员:一家书店的索引 和 两个指向书店 vector 中元素的迭代器
typedef tuple<vector<Sales_data>::size_type,
vector<Sales_data>::const_iterator,
vector<Sales_data>::const_iterator> matches;
// files 保存每家书店的销售记录
// findBook 返回一个 vector,每家销售了给定书籍的书店在其中都有一项
vector<matches>
findBook(const vector<vector<Sales_data>> &files, const string &book)
{
vector<matches> ret; // 初始化为空 vector
// 对每家书店,查找与给定书籍匹配的记录范围(如果有的话)
for (auto it = files.cbegin(); it != files.cend(); ++it) {
// 单个书店(it)查找具有相同 ISBN 的 Sales_data 范围
// equal_range 用于在已排序的范围内查找等于某个值的子范围。它返回一对迭代器,这些迭代器表示该子范围的开始和结束位置
auto found = equal_range(it->cbegin(), it->cend(), book, compareIsbn);
if (found.first != found.second) // 此书店销售了给定书籍
// 记住此书店的索引及匹配的范围
ret.push_back(make_tuple(found.first, found.second));
}
return ret; // 如果未找到匹配记录的话,ret 为空
}
std::equal_range 在一个排序的容器中查找等于某个值的子范围
// 创建一个已排序的向量
std::vector<int> vec = {1, 2, 2, 2, 3, 4, 5, 5, 5, 6, 7};
// 查找等于 2 的范围
auto range = std::equal_range(vec.begin(), vec.end(), 2);
// 打印范围内的元素
std::cout << "Elements equal to 2: ";
for (auto it = range.first; it != range.second; ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
equal_range 的前两个实参是 表示输入序列的迭代器,第三个参数是 一个值。默认情况下,equal_range 使用 < 运算符来比较元素。由于 Sales_data 没有 < 运算符,因此 传给它一个指向 compareIsbn 函数的指针
equal_range 算法返回一个迭代器 pair,表示元素的范围。如果未找到 book,则两个迭代器相等,表示空范围。否则,返回的 pair 的 first 成员将表示第一条匹配的记录,second 则表示匹配的尾后位置
3、使用函数返回的 tuple
对每家 包含匹配销售记录的书店,将打印 其汇总销售信息:
void reportResults(istream &in, ostream &os, const vector<string>& files)
{
string s; // 要查找的书
while (in >> s) {
auto trans = findBook(files, s); // 销售了这本书的书店
if (trans.empty()) {
cout << s << " not found in any stores" << endl;
continue; // 继续下一本要查找的书
}
for (const auto &store : trans) // 对每家销售了给定书籍的书店
// get<n> 返回 store 中 tuple 的指定位置的值
os << "store " << get<0>(store) << " sales: "
<< accumulate(get<1>(store), get<2>(store), Sales_data(s))
<< endl;
}
}
使用 auto 来简化 trans 类型的代码编写,它是一个 tuple 的 vector
由于 不希望改变 trans 中的元素,将 store 声明为 const 的引用,由于 Sales_data 定义了加法运算符,因此 可以用标准库的 accumulate 算法 来累加销售记录
将Sales_data()作为第三个参数传递给accumulate,会发生什么
返回的 Sales_data 中的 bookNo 成员为空,因为只有 相同的 ISBN 才能加
4、编写并测试你自己版本的 findBook 函数
Sales_data.h
#pragma once
#ifndef SALES_DATA_H
#define SALES_DATA_H
#include <string>
#include <iostream>
struct Sales_data;
std::istream& operator>>(std::istream& is, Sales_data& item);
std::ostream& operator<<(std::ostream& os, const Sales_data& item);
Sales_data operator+(const Sales_data& s1, const Sales_data& s2);
class Sales_data {
public:
friend std::istream& operator>>(std::istream& is, Sales_data& item);
friend std::ostream& operator<<(std::ostream& os, const Sales_data& item);
friend Sales_data operator+(const Sales_data& s1, const Sales_data& s2);
// 使用委托函数重新编写构造函数
Sales_data(const std::string& s, unsigned u, double r) : bookNo(s), units_sold(u), revenue(r* u) { }
Sales_data() : Sales_data("", 0, 0) { }
Sales_data(const std::string& s) : Sales_data(s, 0, 0) { }
Sales_data(std::istream& is) : Sales_data() {
// read(is, *this);
is >> *this;
}
Sales_data& combine(const Sales_data&);
std::string isbn() const { return bookNo; }
double avg() const;
// 自定义类型转换运算符
explicit operator std::string() const {
return bookNo;
}
explicit operator double() const {
return revenue;
}
private:
std::string bookNo;
unsigned units_sold = 0;
double revenue = 0.0;
};
Sales_data& Sales_data::combine(const Sales_data& s) {
units_sold += s.units_sold;
revenue += s.revenue;
return *this;
}
double Sales_data::avg() const {
if (units_sold) {
return revenue / units_sold;
}
else {
return 0;
}
}
Sales_data operator+(const Sales_data& s1, const Sales_data& s2) {
Sales_data tmp = s1;
tmp.combine(s2);
return tmp;
}
std::istream& operator>>(std::istream& is, Sales_data& s) {
double singlePrice;
is >> s.bookNo >> s.units_sold >> singlePrice;
s.revenue = s.units_sold * singlePrice;
return is;
}
std::ostream& operator<<(std::ostream& os, const Sales_data& s) {
os << s.isbn() << " " << s.units_sold << " " << s.revenue << " " << s.avg();
return os;
}
#endif
17.4.cpp
#include "Sales_data.h"
#include <tuple>
#include <string>
#include <iterator>
#include <vector>
#include <algorithm>
#include <iostream>
#include <numeric>
using namespace std;
bool compareIsbn(const Sales_data& sd1, const Sales_data& sd2) {
return sd1.isbn() < sd2.isbn();
}
// const_iterator是_连在一起的,别忘了用size_type
typedef tuple<vector<Sales_data>::size_type, vector<Sales_data>::const_iterator, vector<Sales_data>::const_iterator> match;
// 在 findBook 函数中返回了一个局部变量 res 的引用,这在函数结束后会成为一个悬挂引用,从而导致未定义行为
// 当函数返回一个局部变量的引用时,这个引用在函数结束后会变得无效,因为局部变量的生命周期在函数返回时就结束了。访问这样的引用会导致未定义行为
vector<match> findBook(const vector<vector<Sales_data>>& file, const string& str) {
vector<match> res;
for (auto it = file.begin(); it != file.end(); it++) {
auto found = equal_range(it->begin(), it->end(), str, compareIsbn);
if (found.first != found.second) {
res.push_back(make_tuple(it - file.begin(), found.first, found.second));
}
}
return res;
}
void printRes(istream& is, const vector<vector<Sales_data>>& file) {
string book; // 输入要找的书
while (is >> book) {
auto res = findBook(file, book);
if (res.empty()) {
cout << book << " not found. " << endl;
}
else {
// 把vector中的信息都打印出来
for (const auto& vec : res) {
// accumulate复用了Sales_data的加法和<<运算,accumulate返回的是const Sales_data,注意Sales_data对应的声明和定义都要改
cout << get<0>(vec) << " sales: " << accumulate(get<1>(vec), get<2>(vec), Sales_data(book)) << endl;;
}
}
}
}
int main()
{
Sales_data sales_data1("001-01", 1, 100);
Sales_data sales_data2("001-01", 2, 100);
Sales_data sales_data3("001-02", 2, 80);
std::vector<Sales_data> vs1 = { sales_data1, sales_data3 };
std::vector<Sales_data> vs2 = { sales_data2 };
std::vector<std::vector<Sales_data>> vvs = { vs1, vs2 };
printRes(cin, vvs);
return 0;
}
重写 findBook,令其返回一个 pair,包含一个索引和一个迭代器 pair
#include "Sales_data.h"
#include <tuple>
#include <string>
#include <iterator>
#include <vector>
#include <algorithm>
#include <iostream>
#include <numeric>
using namespace std;
bool compareIsbn(const Sales_data& sd1, const Sales_data& sd2) {
return sd1.isbn() < sd2.isbn();
}
// 用两个嵌套的pair代替tuple (typedef tuple<vector<Sales_data>::size_type, vector<Sales_data>::const_iterator, vector<Sales_data>::const_iterator> match;)
typedef pair<vector<Sales_data>::size_type, pair<vector<Sales_data>::const_iterator, vector<Sales_data>::const_iterator>> match;
vector<match> findBook(const vector<vector<Sales_data>>& file, const string& str) {
vector<match> res;
for (auto it = file.begin(); it != file.end(); it++) {
auto found = equal_range(it->begin(), it->end(), str, compareIsbn);
if (found.first != found.second) {
// 压入数据也改成嵌套的 make_pair
res.push_back(make_pair(it - file.begin(), make_pair(found.first, found.second)));
}
}
return res;
}
void printRes(istream& is, const vector<vector<Sales_data>>& file) {
string book;
while (is >> book) {
auto res = findBook(file, book);
if (res.empty()) {
cout << book << " not found. " << endl;
}
else {
for (const auto& vec : res) {
// 获取元素的方法也要改
cout << vec.first << " sales: " << accumulate(vec.second.first, vec.second.second, Sales_data(book)) << endl;;
}
}
}
}
int main()
{
Sales_data sales_data1("001-01", 1, 100);
Sales_data sales_data2("001-01", 2, 100);
Sales_data sales_data3("001-02", 2, 80);
std::vector<Sales_data> vs1 = { sales_data1, sales_data3 };
std::vector<Sales_data> vs2 = { sales_data2 };
std::vector<std::vector<Sales_data>> vvs = { vs1, vs2 };
printRes(cin, vvs);
return 0;
}
重写 findBook,不使用 tuple 或 pair
#include "Sales_data.h"
#include <tuple>
#include <string>
#include <iterator>
#include <vector>
#include <algorithm>
#include <iostream>
#include <numeric>
using namespace std;
bool compareIsbn(const Sales_data& sd1, const Sales_data& sd2) {
return sd1.isbn() < sd2.isbn();
}
// 定义类
struct match
{
std::vector<Sales_data>::size_type index;
std::vector<Sales_data>::const_iterator first;
std::vector<Sales_data>::const_iterator last;
match(std::vector<Sales_data>::size_type index_, std::vector<Sales_data>::const_iterator first_, std::vector<Sales_data>::const_iterator last_) : index(index_), first(first_), last(last_) {}
};
vector<match> findBook(const vector<vector<Sales_data>>& file, const string& str) {
vector<match> res;
for (auto it = file.begin(); it != file.end(); it++) {
auto found = equal_range(it->begin(), it->end(), str, compareIsbn);
if (found.first != found.second) {
// 用类构造函数构造元素
res.push_back(match(it - file.begin(), found.first, found.second));
}
}
return res;
}
void printRes(istream& is, const vector<vector<Sales_data>>& file) {
string book;
while (is >> book) {
auto res = findBook(file, book);
if (res.empty()) {
cout << book << " not found. " << endl;
}
else {
for (const auto& vec : res) {
// 获取元素的方法也要改
cout << vec.index << " sales: " << accumulate(vec.first, vec.last, Sales_data(book)) << endl;;
}
}
}
}
int main()
{
Sales_data sales_data1("001-01", 1, 100);
Sales_data sales_data2("001-01", 2, 100);
Sales_data sales_data3("001-02", 2, 80);
std::vector<Sales_data> vs1 = { sales_data1, sales_data3 };
std::vector<Sales_data> vs2 = { sales_data2 };
std::vector<std::vector<Sales_data>> vvs = { vs1, vs2 };
printRes(cin, vvs);
return 0;
}
2、bitset 类型
1、标准库 定义了 bitset 类使得位运算更加容易,并且 能够处理 超过最长整型类型的大小的位集合。bitset 类定义在头文件 bitset 中
2.1 定义和初始化 bitset
1、bitset 类是一个类模板,它类似于 array 类,具有固定大小。当 定义一个 bitset 时,需要声明它包含多少个二进制定位:
bitset<32> bitvec(1U); // 32 位;低位为 1,其他位为 0
大小必须是一个常量表达式。这条语句定义 bitvec 为一个包含 32 位的 bitset。就像 vector 包含 未命名的元素一样,bitset 中的二进制定位也是未命名的,通过位置来访问它们。二进制定位的位置是从 0 开始编号的。因此,bitvec 包含编号从 0 到 31 的 32 个二进制定位。编号从 0 开始的二进制定位称为低位
2、初始化 bitset 的方法
| 代码 | 功能 |
|---|---|
bitset<n> b; | b 有 n 位;每一位均为 0。此构造函数是一个 constexpr(用于指示一个函数或变量可以在编译时求值) |
bitset<n> b(u); | b 是 unsigned long long u 的低 n 位的拷贝。如果 n 大于 unsigned long long 的大小,则 b 中超出 unsigned long long 的高位被置为 0。此构造函数是一个 constexpr |
bitset<n> b(s, pos, m, zero, one); | b 是字符串 s 从位置 pos 开始 m 个字符的拷贝。s 只能包含字符零或一:如果 s 包含任何其他字符,构造函数会抛出 invalid_argument 异常。字符在 b 中分别保留为 zero 和 one。pos 默认为 0,m 默认为 string::npos,zero 默认为 ‘0’,one 默认为 ‘1’ |
bitset<n> b(cp, pos, m, zero, one); | 与上一个构造函数相同,但从 cp 指向的字符数组中拷贝字符。如果未提供 m,则 cp 必须指向一个 C 风格字符串。如果提供了 m,则从 cp 字符开始必须至少有 m 个 zero 或 one 字符 |
接受一个 string 或一个字符指针的构造函数 是 explicit 的。在新标准中增加了为 0 和 1 指定其他字符的功能
3、用 unsigned 值初始化 bitset
使用一个整型值用来初始化 bitset 时,该值 将被转换为 unsigned long long 类型 并被当作位模式来处理。bitset 中的二进制位 将是此模式的一个副本。如果 bitset 的大小大于一个 unsigned long long 中的二进制定位数,则剩余的高位被置为 0。如果 bitset 的大小小于一个 unsigned long long 中的二进制定位数,则只使用 给定值的低位,超出 bitset 大小的高位 被丢弃(bitset 低位始终为 靠右的)
// bitvec1 比初始值小;初始值的高位被丢弃
bitset<13> bitvec1(0xbeeF); // 二进制定位序列为 11110111101111
// bitvec2 比初始值大;它的高位被置为 0
bitset<20> bitvec2(0xbeeF); // 二进制定位序列为 00001011110111101111
// 在 64 位机器中,long long 0ULL 是 64 个 0 比特,因此~0ULL 是 64 个 1
bitset<128> bitvec3(~0ULL); // 0~63 位为 1;63~127 位为 0
4、从一个 string 初始化 bitset
可以从一个 string 或一个字符数组指针 来初始化 bitset。两种情况下,字符都直接表示位模式。当使用字符串 来表示数时,字符串中下标最小的字符 对应 bitset(也是数字本身的) 高位,反之亦然:
bitset<32> bitvec4("1100"); // 2、3两位为1,其余两位为0
如果 string 包含的字符数比 bitset 少,则 bitset 的高位被置为 0
string 的下标编号习惯 与 bitset 恰好相反:string 中下标最大的字符(最右字符)用来初始化 bitset 中的低位(下标为 0 的二进制定位)
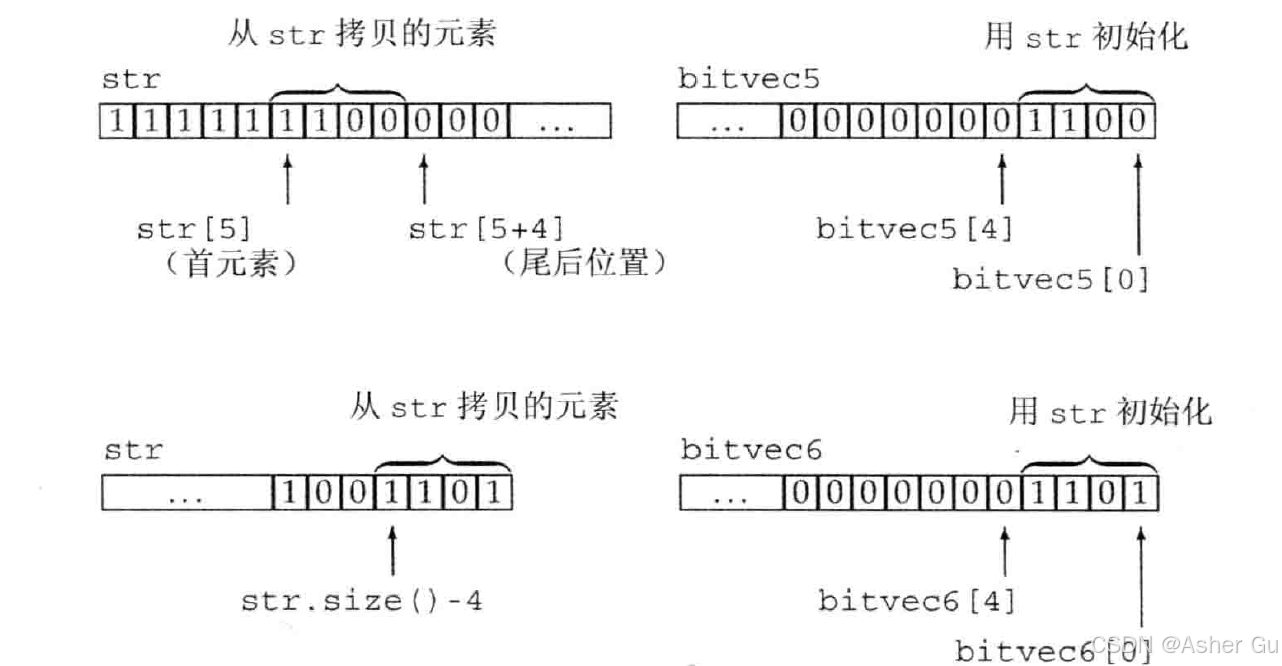
可以只用一个子串作为初始值
string str = "11111100000110100";
bitset<32> bitvec5(str, 5, 4); // 使用str[5]开始的四个二进制定位
bitset<32> bitvec6(str, str.size()-4); // 使用最后四个字符
bitvec5 用 str 中从 str[5] 开始长度为 4 的子串(都是string 的下标)进行初始化。子串的最右边字符 在 bitset 中表示最低位。因此,bitvec5 中第 3 位到第 0 位(bitset 中的下标规则)被设置为 1100,其余位被设置为 0
5、解释下列每个bitset 对象所包含的位模式
(a) bitset<64> bitvec(32);
(b) bitset<32> bv(1010101); // 先要把 1010101 转成二进制形式
(a)用unsigned值初始化:0000000000000000000000000000000000000000000000000000000000100000;
(b)用unsigned值初始化:00000000000011110110100110110101;
2.2 bitset 操作
1、定义了 多种检测或设置 一个或多个二进制定位的方法,这些运算符 用于 bitset 对象的含义 与 内置运算符用于 unsigned 运算对象相同(与有符号类型不同:unsigned int d = 2; unsigned int e = 5; unsigned int f = d - e; // 结果为 4294967293(假设 unsigned int 为 32 位))
| 代码 | 操作 |
|---|---|
| b.any() | b 中是否存在 置位(即等于1) 的二进制定位 |
| b.all() | b 中所有位都置位了吗 |
| b.none() | b 中不存在置位的二进制定位吗 |
| b.count() | b 中置位的数目,返回 size_t |
| b.size() | 一个 constexpr 函数(可以用在 要求常量表达式的地方),返回 b 中的位数,返回 size_t |
| b.test(pos) | 若 pos 位置的位是置位的,则返回 true,否则返回 false |
| b.set(pos, v) b.set() | 将位置 pos 处的位设置为 bool 值 v。v 默认为 true。如果没有传入实参,则将 b 中所有位置位为默认值 true |
| b.reset(pos) b.reset() | 将位置 pos 处的位复位 或 将 b 中所有位复位 |
| b.flip(pos) b.flip() | 改变位置 pos 处的位的状态 或 改变 b 中每一位的状态 |
| b[pos] | 访问 b 中位置 pos 处的位:如果 b 是 const 的,则当该位 置位时 返回一个 bool 值 true,否则返回 false |
| b.to_ulong() | 返回一个 unsigned long 或一个 unsigned long long 值,其位模式与 b 相同。如果 b 中位模式 不能放入指定的结果类型,则抛出一个 overflow_error 异常 |
| b.to_string(zero, one) | 返回一个 string,表示 b 中的位模式。zero 和 one 的默认值分别为 0 和 1,来表示 b 中的 0 和 1 |
| os << b | 将 b 中二进制定位打印为字符 0 或 1,打印到流 os |
| is >> b | 从 is 取得字符存入 b。当下一个字符不是 0 或 1,或是已读入 b.size() 个字节时,读取过程停止 |
count、size、all、any 和 none 等几个操作都不接受参数,返回整个 bitset 的状态。其他操作——set、reset 和 flip 则改变 bitset 的状态。改变 bitset 状态的成员函数 都是重载的。对每个函数,不接受参数的版本 对整个集合执行给定的操作:接受一个位置参数的版本 则对指定位执行操作
bitvec.flip(0); // 翻转第一位
bitvec.set(bitvec.size() - 1); // 置位最后一位
bitvec.reset(0); // 复位第一位
bitvec.set(0, 0); // 复位第一位
bitvec.test(0); // 返回 false,因为第一位是复位的
下标运算符对 const 属性进行了重载。const 版本的下标运算符 在指定位置 置位时返回 true,否则返回 false。非 const 版本返回 bitset 定义的一个特殊类型,它允许我们操作指定位置的值:
bitvec[0] = 0; // 将第一位复位
bitvec[31] = bitvec[0]; // 将最后一位 设置为 与第一位一样
bitvec[0].filp(); // 翻转第一位
~bitvec[0]; // 等价于翻转第一位
bool b = bitvec[0]; // 将 bitvec[0] 的值转换为 bool 类型
2、提取 bitset 的值
to_ulong 和 to_ullong 操作都返回一个值,保存了与 bitset 对象相同的位模式。只有当 bitset 的大小小于等于对应的大小 (to_ulong 为 unsigned long, to_ullong 为 unsigned long long) 时,才能使用这两个操作:
unsigned long ulong = bitvec3.to_ulong();
cout << "ulong = " << ulong << endl;
如果 bitset 中的值 不能放入给定类型的变量中,则这两个操作 会抛出一个 overflow_error 异常
3、bitset 的 IO 运算符
输入运算符 从一个输入流读取字符,保存到一个临时的 string 对象中。直到读取的字符数 达到对应 bitset 的大小时,或者遇到不是 1 或 0 的字符时,或者 遇到文件尾或输入错误时,读取过程才停止
随即用临时 string 对象来初始化 bitset。如果读取的字符数 小于 bitset 的大小,则与往常一样,高位将被置为 0
bitset<16> bits;
cin >> bits; // 从 cin 读取最多 16 个 0 或 1
cout << "bits: " << bits << endl; // 打印刚读取的内容
4、使用 bitset
0 AND 1 = 0 0 OR 1 = 1
bool status;
// 使用位运算法版的版本
unsigned long quizA = 0; // 被当作位集合使用
quizA |= (UUL << 27); // 指出第27个学生通过了测验
status = quizA & ~(UUL << 27); // 检查第27个学生是否通过了测验
quizA &= ~(UUL << 27); // 第27个学生未通过测验
// 使用标准库类 bitset 完成等价的工作
bitset<30> quizB; // 每个同学分配了一位,所有位都被初始化为0
quizB.set(27); // 指出第27个学生通过了测验
status = quizB[27]; // 检查第27个学生是否通过了测验
quizB.reset(27); // 第27个学生未通过测验 quizB.reset(27);
5、定义一个数据结构,包含一个整型对象,记录一个包含 10 个问题的真假测验的答案。如果测验包含 100 道题,你需要对数据结构做出什么改变(如果需要的话)
#include <bitset>
#include <string>
#include <iostream>
using namespace std;
template <unsigned N>
class Problems {
template <unsigned M>
friend ostream& operator<<(ostream& os, const Problems<M>& p);
public:
Problems(string &s) : bset(s) {} // 用string初始化
void update(size_t pos, bool e) {
bset[pos] = e;
}
private:
bitset<N> bset;
};
template <unsigned N>
ostream& operator<<(ostream& os, const Problems<N>& p) {
os << p.bset; // 定义运算符不要加endl
return os;
}
int main()
{
// Problems<10> p1("0101010101"); 没办法直接初始化,需要先初始化string
string str1("0101010101");
Problems<10> p1 = str1;
cout << p1 << endl; // 函数参数会自己推导模板参数,类必须要带
p1.update(0, 0);
cout << p1 << endl;
string str2("0101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101");
Problems<100> p2(str2);
return 0;
}
编写一个函数,接受一个问题编号和一个表示真/假解答的值,函数根据这两个参数更新测验的解答;并 使用它来为 数据结构生成测验成绩
#include <bitset>
#include <iostream>
template <unsigned N>
class quiz
{
template <unsigned M>
friend std::ostream &operator<<(std::ostream&, const quiz<M>&);
template <unsigned M>
friend size_t grade(const quiz<M>&, const quiz<M>&);
public:
quiz(std::string &s) : bset(s) {}
void update(size_t n, bool b)
{
bset[n] = b;
}
private:
std::bitset<N> bset;
};
template <unsigned M>
std::ostream &operator<<(std::ostream &os, const quiz<M> &q)
{
os << q.bset;
return os;
}
template <unsigned M>
size_t grade(const quiz<M> &lhsQ, const quiz<M> &rhsQ) // lhsQ为对象,rhsQ为正确答案,相同为1,不同为0
{
return (lhsQ.bset ^ rhsQ.bset).flip().count(); // ^异或,两个对应位相同为0,不同为1
// 如:翻转整数 num 的第 k 位 num^(1<<k)
}
int main()
{
std::string s1("0101010101");
std::string s2("0101010100");
quiz<10> q1(s1);
quiz<10> q2(s2);
q1.update(1,true); // 函数根据这两个参数更新测验的解答
std::cout << q1 << std::endl;
std::cout << grade(q1, q2) << std::endl;
return 0;
}
3、正则表达式
1、正则表达式 是一种描述字符序列的方法。如何使用 C++11 正则表达式库(RE 库),RE 库定义在头文件 regex 中
正则表达式库组件
| 代码 | 功能 |
|---|---|
| regex | 表示有一个正则表达式类 |
| regex_match | 将一个字符串序列 与一个正则表达式匹配 |
| regex_search | 寻找 第一个 与正则表达式匹配的子序列 |
| regex_replace | 使用给定格式 替换一个正则表达式 |
| sregex_iterator | 迭代器适配器,调用 regex_search 来遍历一个 string 所有匹配的子串 |
| smatch | 容器类,保存在 string 搜索的结果 |
| ssub_match | string 匹配的子表达式结果 |
如果整个输入序列 与 表达式匹配,则 regex_match 函数返回 true;如果输入序列中有一个子串 与 表达式匹配,则 regex_search 函数返回 true
如果匹配成功,这些函数 将成功匹配的相关信息 保存在给定的 smatch 对象中
regex_search 和 regex_match 的参数(这些操作返回 bool 值,指出是否找到匹配)
| 代码 | 功能 |
|---|---|
| (seq, m, r, mft) (seq, r, mft) | 在字符序列 seq 中查找 regex 对象 r 中的正则表达式。seq 可以是一个 string、表示范围的一对迭代器以及一个指向空字符结尾的字符数组的指针,m 是一个 match 对象,用来保存 匹配结果的相关细节。m 和 seq 必须具有兼容的类型;mft 是一个可选的 regex_constants::match_flag_type 值。它们会影响匹配过程 |
3.1 使用正则表达式库
1、查找 拼写规则“i 除非在 c 之后,否则必须在 e 之前”的单词:
// 查找不在字符 c 之后的字符串 ei
string pattern = "[^c]ei";
// 我们需要包含 pattern 的整个单词
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern); // 构造一个用于查找模式的 regex
smatch results; // 定义一个对象保存搜索结果
string test_str = "receipt freind theif receive";
// 用 r 在 test_str 中查找与 pattern 匹配的子串
if (regex_search(test_str, results, r)) // 如果有匹配子串
cout << results.str() << endl; // 打印匹配的单词
首先定义了一个 string 来保存 希望查找的正则表达式。正则表达式 [^c] 表明 希望匹配任意不是 ‘c’ 的字符,而 [^c]ei 指出我们想要匹配 这种字符后接 ei 的字符串。此模式描述的字符串 恰好包含三个字符。想要包含此模式的单词的完整内容。为了与 整个单词匹配,还需要一个正则表达式 与这个三字母模式之前的 和 之后的字母匹配
默认情况下,regex 使用的正则表达式语言是 ECMAScript。在 ECMAScript 中,模式 [[:alpha:]] 匹配任意字母,符号 + 和 * 分别表示 希望 “一个或多个” 或 “零或多个” 匹配。因此 [[:alpha:]]* 将匹配零个或多个字母
还定义了一个名为 results 的 smatch 对象,它将被传递给 regex_search。如果找到匹配子串,results 将会保存匹配位置的详细信息
接下来 调用了 regex_search。如果它找到匹配子串,就返回 true。用 results 的 str 成员来打印 test_str 中与模式匹配的部分。函数 regex_search 在 输入序列中只要找到一个匹配子串 就会停止查找。因此,程序的输出将是 freind
2、指定 regex 对象的选项
定义一个 regex 或是 对一个 regex 调用 assign 为其赋予新值时,可以指定一些标志来影响 regex 如何操作。这些标志控制 regex 对象处理的过程。对这 6 个标志,必须设置其中之一,且只能设置一个。默认情况下,ECMAScript 标志被设置,从而 regex 会使用 ECMA-262 规范,这也是很多 Web 浏览器所使用的 正则表达式语言
regex(和 wregex)选项
| 代码 | 功能 |
|---|---|
| regex r(re) regex r(re, f) | re 表示一个正则表达式,它可以是一个 string、一个表示字符范围的迭代器对、一个指向空字符结尾的字符数组的指针、两个字符指针和一个计数器或是一个花括号包围的字符列表。f 是指针对像如何处理的标志。f 通过下面列出的值来设置。如果未指定 f,默认值为 ECMAScript |
| r1 = re | 将 r1 中的正则表达式替换为 re。re表示一个正则表达式,它可以是 另一个 regex 对象、一个 string、一个指向空字符结尾的字符数组的指针 或是 一个花括号包围的字符列表 |
| r1.assign(re, f) | 与使用赋值运算法则(=)效果相同:可选的标志 f 也与 regex 的构造函数参数对应的参数含义相同 |
| r.mark_count() | r 中正则表达式的数目 |
| r.flags() | 返回 r 的标志集 |
定义 regex 时指定的标志:定义在 regex 和 regex_constants::syntax_option_type 中
| 代码 | 功能 |
|---|---|
| icase | 在匹配过程中忽略大小写 |
| nosubs | 不保留匹配的子表达式 |
| optimize | 执行速度优先于构造速度 |
| ECMAScript | 使用 ECMA-262 指定的语法(下面6个选1个) |
| basic | 使用 POSIX 基本的正则表达式语法 |
| extended | 使用 POSIX 扩展的正则表达式语法 |
| awk | 使用 POSIX 版本的 awk 语言的语法 |
| grep | 使用 POSIX 版本的 grep 的语法 |
| egrep | 使用 POSIX 版本的 egrep 的语法 |
最上面 3 个标志 允许我们指定 正则表达式处理过程中与语言无关的方面。例如,可以指定正则表达式 以大小写无关的方式进行匹配
可以用 icase 标志 查找具有特定扩展名的文件名。大多数操作系统都是 按大小写无关的方式来识别扩展名——可以将一个 C++ 程序保存在 .cc 结尾的文件中,也可以保存在 .Cc、.cc 或者 .CC 结尾的文件中
// 一个或多个字母或数字字符后接一个'.'再接"cpp"或"cxx"或"cc"
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$", regex::icase);
smatch results;
string filename;
while (cin >> filename)
if (regex_search(filename, results, r))
cout << results.str() << endl; // 打印匹配结果
此表达式 将匹配这样的字符串:一个或多个字母或数字后 接一个句点 再接三个文件扩展名之一。此正则表达式 将匹配指定的文件扩展名 而不理大小写
正则表达式语言 也有特殊字符。例如,字符点 (.)通常匹配任意字符。与C++一样,可以在字符之前 放置一个反斜线 来去掉其特殊含义。由于反斜线也是 C++ 中的一个特殊字符,我们在字符串字面量中 必须连续使用两个反斜线 来告诉 C++ 我们想要一个普通反斜线字符
3、正则表达式用法
是一种用于匹配字符串中字符组合的模式。正则表达式在文本搜索、替换和验证中非常有用
检查是否是有效的邮箱地址



#include <iostream>
#include <regex>
int main() {
std::string email = "example@example.com";
std::regex pattern(R"((\w+)(\.?\w+)*@(\w+)\.(\w+))");
if (std::regex_match(email, pattern)) {
std::cout << "有效的邮箱地址。" << std::endl;
} else {
std::cout << "无效的邮箱地址。" << std::endl;
}
return 0;
}
正则表达式分解R"(...)":
这是 C++11 引入的原始字符串字面量语法。它允许你在字符串中包含反斜杠和引号,而不需要进行转义。所有在 R"(…)" 之间的字符都被解释为字面字符串。
(\w+):
\w:匹配任何单词字符(字母、数字或下划线),相当于 [a-zA-Z0-9_]。
+:匹配前面的字符一次或多次。因此,\w+ 匹配一个或多个单词字符。
(\w+):捕获组1,匹配并捕获一个或多个单词字符。这个部分通常代表电子邮件地址中的用户名部分(在 @ 符号前的部分)
(\.?\w+)*:
.:匹配一个点字符(.)。因为点在正则表达式中是一个特殊字符,需要用反斜杠转义。
?:匹配前面的字符零次或一次。因此,.? 匹配零个或一个点字符。
\w+:匹配一个或多个单词字符(如上所述)。(\.?\w+)*:这是一个捕获组,但没有进行捕获(因为没有实际的需求),匹配零个或多个点后跟一个或多个单词字符的组合。这个部分用于匹配用户名部分中可能出现的点和单词字符的组合,如 john.doe
@:
直接匹配 @ 符号,这是电子邮件地址中的分隔符,分隔用户名和域名
(\w+):
和第一个 (\w+) 一样,这是捕获组2,匹配并捕获一个或多个单词字符。这个部分通常代表电子邮件地址中的域名部分(在 @ 符号后的部分)。
.:
匹配一个点字符(.),同上所述。
(\w+):
和前面的 (\w+) 一样,这是捕获组3,匹配并捕获一个或多个单词字符。这个部分通常代表电子邮件地址中的顶级域名部分(如 .com, .net 等)
^[a-zA-Z][0-9],(?:[a-zA-Z][0-9],)[a-zA-Z][0-9]$
\b:单词边界,确保匹配的是完整的单词
假设 想在一个字符串中匹配单词 cat,但只匹配完整的单词,而不是作为其他单词的一部分。例如,在字符串 “concatenate cats cat caterpillar” 中,pattern = r'\bcat\b' 只匹配 cat 这个单词,而不会匹配 concatenate 或 caterpillar 中的部分 cat




import re
# 示例字符串
text = "This is a test test to see how backreferences work. Let's try another word word pair."
# 正则表达式:使用捕获组和反向引用
pattern = r'\b(\w+)\s+\1\b'
# 在字符串中查找所有匹配
matches = re.findall(pattern, text)
# 输出所有匹配的内容
print("匹配的重复单词组:", matches)
\1:反向引用,匹配捕获组1中捕获的相同内容
运行这段代码将会输出:
匹配的重复单词组: ['test', 'word']
这表示它找到了两个重复的单词对:“test test” 和 “word word”
4、指定或使用正则表达式时的错误
可以将 正则表达式 本身看作 一种简单程序设计语言编写的“程序”。这种语言不是由 C++ 编译器解释的。正则表达式是在运行时,当一个 regex 对象被初始化 或 被赋予一个新模式时,才被“编译”的
如果 编写的正则表达式 存在错误,则在 运行时 标准库会抛出一个类型为 regex_error 的异常。类似标准异常类型,regex_error 还有一个 what 成员来描述发生了什么错误。regex_error 还有一个名为 code 的成员,用来返回某个错误类型对应的数值代码。code 返回的值是由具体实现定义的
try {
// 错误:alnum 漏掉了右括号,构造函数会抛出异常
regex r("[[:alnum:]+\\.(cpp|cxx|cc)$", regex::icase);
} catch (regex_error e) {
cout << e.what() << "\ncode: " << e.code() << endl;
}
运行结果
regex_error(error_brack):
The expression contained mismatched [ and ].
Code: 4
5、正则表达式错误类型
定义在 regex 和 regex_constants::error_type 中,code 编号从0开始
| 代码 | 类型 |
|---|---|
| error_collate | 无效的元素校对请求 |
| error_ctype | 无效的字符类 |
| error_escape | 无效的转义字符 或 无效的尾部转义 |
| error_backref | 无效的向后引用 |
| error_brack | 不匹配的方括号( [ 或 ] ) code 4 |
| error_paren | 不匹配的小括号( ( 或 ) ) |
| error_brace | 不匹配的花括号( { 或 } ) |
| error_badbrace | { }中无效的范围 |
| error_range | 无效的字符范围(如[z-a]) |
| error_space | 内存不足,无法处理此正则表达式 |
| error_badrepeat | 重复字符( *、?、+ 或 {)之前没有有效的正则表达式 |
| error_complexity | 要求的匹配过于复杂 |
| error_stack | 栈空间不足,无法处理匹配 |
1)要触发 error_collate 错误,通常涉及到正则表达式中 使用了无效 或 不支持的字符类排序(collation)顺序
POSIX 规定了多种字符类和排序规则,它们通常用于正则表达式中来匹配特定类型的字符
常用的 POSIX 字符类:
[[:alnum:]] - 匹配任何字母数字字符。
[[:alpha:]] - 匹配任何字母字符。
[[:blank:]] - 匹配任何空白字符(空格和制表符)。
[[:cntrl:]] - 匹配任何控制字符。
[[:digit:]] - 匹配任何十进制数字。
[[:graph:]] - 匹配任何图形字符(即除空白符外的所有可打印字符)。
[[:lower:]] - 匹配任何小写字母。
[[:print:]] - 匹配任何可打印字符(包括空格)。
[[:punct:]] - 匹配任何标点符号。
[[:space:]] - 匹配任何空白字符。
[[:upper:]] - 匹配任何大写字母。
[[:xdigit:]] - 匹配任何十六进制数字
[[.a.]] 表示 POSIX 字符类排序,假设 希望匹配字母 a 的某种特殊排序形式。这个正则表达式在一个不支持 POSIX 字符类排序的正则表达式引擎中会触发 error_collate 错误
try {
regex r("[[:anum:]]+\\.(cpp|cxx|cc)$", regex::icase);
}
catch (regex_error e)
{
cerr << e.what() << "\ncode: " << e.code() << endl; // code: 1 anum无效字符
}
2)error_escape 错误 通常发生在 正则表达式中包含不正确或不完整的转义字符,当使用反斜杠 \ 进行转义时,后面必须跟随一个有效的转义字符,正则表达式 \k 试图转义字符 k,但 \k 不是一个有效的转义字符,因此会导致 error_escape 错误
3)error_backref 错误通常发生在 正则表达式中 包含了无效或不正确的反向引用。反向引用 用于引用之前捕获的组,但如果 引用了 不存在的组 或 使用了无效的语法,就会导致 error_backref 错误
正则表达式 (a)\2
这个正则表达式 \2 试图引用 第二个捕获组,但正则表达式中 只有一个捕获组 (a)。由于第二个捕获组不存在,会导致 error_backref 错误
4)花括号 {} 在正则表达式中一般用于量词来指定匹配的次数,比如 {n} 或 {n,m},而错误使用花括号可能会导致error_badbrace错误
如:std::regex pattern("l{2,a}"); // 无效的量词 std::regex pattern("l{2,"); // 缺少闭合花括号 std::regex pattern("l{2,1}"); // 起始范围大于结束范围
在正则表达式中,花括号 {} 用于指定重复次数。以下是花括号 {} 的不同用法及其含义:
{n}:恰好匹配 n 次。
{n,}:至少匹配 n 次。
{n,m}:匹配 n 到 m 次
6、避免创建不必要的正则表达式
一个正则表达式 所表示的“程序” 是在运行时而非编译时编译的。正则表达式的编译 是一个非常慢的操作,特别是在你使用了 扩展的正则表达式语法 或是 复杂的正则表达式时。因此,构造一个regex对象 以及 向一个已存在的regex赋一个新的正则表达式 可能是非常耗时的。为了最小化这种开销,应该努力避免创建 很多不必要的regex。特别是,如果 在一个循环中使用正则表达式,应该在循环外创建它,而不是在每步迭代时都编译它
7、正则表达式类型 和 输入序列类型
可以搜索 多种类型的输入序列。输入 可以是普通 char 数据 或 wchar_t 数据,字符串 可以保存在标准库 string 中 或是 char数组中(或是宽字符版本,wstring 或是 wchart_t数组中)。RE 为这些不同的输入序列类型 都定义了对应的类型
例如,regex 类存储类型 char 的正则表达式,标准库还定义了一个 wregex 类存储类型 wchar_t,其操作与regex完全相同。两者唯一的差别是 wregex 的初始值必须使用 wchar_t 而不是 char
匹配和迭代器类型 更为特殊。这些类型的差异 不仅在于字符类型(char 还是 wchar_t),还在于 序列是在标准库 string 中 还是 在数组中:smatch 表示 string 类型的输入序列;cmatch 表示 字符数组序列;wsmatch 表示宽字符串(wstring)输入;而 wcmatch 表示宽字符数组
重点在于 使用的RE库类型必须与输入序列类型匹配
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$", regex::icase);
smatch results; // 将匹配 string 输入序列,而不是 char*
if (regex_search("myfile.cc", results, r)) { // 错误: 输入 "myfile.cc" 为 char*
cout << results.str() << endl;
}
因为 match 参数的类型 与输入序列的类型不匹配。如果 希望搜索一个字符数组,则必须使用 cmatch 对象:
cmatch results; // 将匹配字符数组输入序列
if (regex_search("myfile.cc", results, r)) // 错误:输入为 char*
cout << results.str() << endl;
正则表达式库类
| 如果输入序列类型 | 则使用正则表达式类 |
|---|---|
| string | regex、smatch、ssub_match 和 sregex_iterator |
| const char* | regex、cmatch、csub_match 和 cregex_iterator |
| wstring | wregex、wsmatch、wssub_match 和 wsregex_iterator |
| const wchar_t* | wregex、wcmatch、wcsub_match 和 wcregex_iterator |
8、在正则表达式里面 * ^ 分别是怎么跟别的符号结合的
如果不加(),* 只能匹配前面的一个;而 ^ 可以匹配后面的多个


3.2 匹配与 Regex 迭代器类型
1、可以使用 sregex_iterator 来获得所有匹配。regex 迭代器是一种迭代器适配器,被绑定到 一个输入序列 和 一个 regex 对象上。每种不同输入序列类型 都有对应的特殊的 regex 迭代器类型
sregex_iterator 操作
这些操作也适用于 cregex_iterator、wsregex_iterator 和 wcregex_iterator
| 代码 | 操作 |
|---|---|
| sregex_iterator it(b, e, r) | 一个sregex_iterator,遍历迭代器 b 和 e 表示的string。它调用 sregex_search(b, e, r) 将 it 定位到输入中 第一个匹配的位置 |
| sregex_iterator end; | sregex_iterator 的尾后迭代器 |
| *it it-> | 根据最后一个调用 regex_search 的结果,返回一个 smatch 对象的引用或一个指向 smatch 对象的指针 |
| ++it it++ | 从输入序列当前匹配位置 开始调用 regex_search,在输入 string 中查找下一个匹配。前置版本返回旧值;后置版本返回新值 |
| it1 == it2 it1 != it2 | 如果两个 sregex_iterator 都是尾后迭代器,则它们相等;两个非尾后迭代器是 从相同的输入序列 和 regex 对象构造,则它们相等 |
将一个 sregex_iterator 绑定到一个 string 和一个 regex 对象时,迭代器 自动定位到给定 string 中第一个匹配位置。即,sregex_iterator 构造函数对给定 string 和 regex 调用 regex_search。当我们解引用迭代器时,会得到一个 对应最近一次搜索结果的 smatch 对象
2、使用 sregex_iterator
扩展之前程序,在一个文本文件中 查找所有违反 “i 在 e 之前,除非在 c 之后” 规则的单词。假定名为 file 的 string 保存了 要搜索的输入文件的全部内容。程序将 使用与前一个版本一样的 pattern,但会使用一个 sregex_iterator 来进行搜索:
// 查找第一个字符不是 c 的字符串 ei
string pattern = "[^c]ei";
// 我们想要包含 pattern 的单词的全部内容
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern, regex::icase); // 在进行匹配时将忽略大小写
// 它将反复调用 regex_search 来寻找文件中的所有匹配
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it)
{
cout << it->str() << endl; // 匹配的单词
}
for 语句中的初始值 定义了 it 和 end_it。当定义 it 时,sregex_iterator 的构造函数调用 regex_search 将 it 定位到 file 中 第一个与 r 匹配的位置。而 end_it 是一个空 sregex_iterator,起到尾后迭代器的作用
解引用迭代器时,会得到一个表示当前匹配结果的 smatch 对象。调用它的 str 成员来打印匹配的单词
3、smatch(涉及匹配组的使用)
std::smatch 标准库 <regex> 中的一个类,用于存储 正则表达式匹配的结果。它是 std::match_results 类模板的一个特化版本,用于处理 std::string 类型的字符串匹配结果。std::smatch 提供了对匹配结果的访问,包括整个匹配结果 和 所有捕获组
构造函数
smatch():默认构造函数,创建一个空的匹配结果对象
成员函数
- bool ready() const:检查匹配结果是否已准备好
- bool empty() const:检查匹配结果是否为空
- size_type size() const:返回匹配结果的数量,包括整个匹配和所有捕获组
整个匹配:这是指整个正则表达式匹配到的部分
所有捕获组:这是指正则表达式中使用圆括号 () 捕获的各个子表达式的匹配部分 - const_reference operator[](size_type n) const:访问第 n 个匹配结果。n = 0 返回整个匹配结果,n > 0 返回第 n 个捕获组,返回类型是 std::ssub_match
- std::string str(size_type n = 0) const:返回第 n 个匹配结果的字符串表示形式,默认返回第0个
- begin() 和 end():返回迭代器,指向匹配结果的起始和终止位置
使用 std::smatch 类来进行正则表达式匹配,并访问匹配结果
#include <iostream>
#include <regex>
#include <string>
int main() {
std::string text = "The quick brown fox jumps over the lazy dog.";
// 创建正则表达式和匹配对象
std::regex pattern(R"((\w+)\s+(\w+)\s+(\w+))"); // 匹配三个连续的单词
std::smatch match;
// 尝试匹配正则表达式,访问匹配结果
if (std::regex_search(text, match, pattern)) {
std::cout << "匹配成功!" << std::endl;
std::cout << "整个匹配: " << match[0] << std::endl;
std::cout << "第一个单词: " << match[1] << std::endl;
std::cout << "第二个单词: " << match[2] << std::endl;
std::cout << "第三个单词: " << match[3] << std::endl;
// 使用迭代器遍历所有匹配结果
for (size_t i = 0; i < match.size(); ++i) { // 注意对 match.size()的使用
std::cout << "匹配组 " << i << ": " << match[i].str() << std::endl;
}
} else {
std::cout << "匹配失败。" << std::endl;
}
return 0;
}
输出
匹配成功!
整个匹配: The quick brown
第一个单词: The
第二个单词: quick
第三个单词: brown
匹配组 0: The quick brown
匹配组 1: The
匹配组 2: quick
匹配组 3: brown
4、使用匹配数据
希望看到匹配单词出现的上下文,如:
hey read or write according to the type
>>> being <<<
handled. The input operators ignore whi
匹配类型 有两个名为 prefix 和 suffix 的成员(两个都是 成员函数),分别返回 表示输入序列中 当前匹配之前 和 之后部分的 ssub_match 对象。一个 ssub_match 对象分别有 两个名为 str 和 length 的成员(都是成员函数),分别返回匹配的 string 和该 string 的大小
// 循环头与之前一样
for (sregex_iterator it(file.begin(), file.end(), r), end_it; it != end_it; ++it) {
auto pos = it->prefix().length(); // 前缀的大小
pos > 40 ? pos - 40 : 0; // 最多40个字符
cout << it->prefix().str().substr(pos) // 前缀的最后一部分
<< "\n\t\t>>> " << it->str() << "<<<\n" // 匹配的单词
<< it->suffix().str().substr(0, 40) // 后缀的第一部分
<< endl;
}
5、substr 和 match.position(n), match.length(n) 两个成员方法
1)substr
参数都是 size_t
std::string substr(size_t pos = 0, size_t len = npos) const;
pos:子字符串开始的位置,默认值为 0
len:要提取的子字符串的长度,默认值为 std::string::npos,表示直到字符串末尾
返回一个从 pos 开始、长度为 len 的子字符串
2)match.position(n), match.length(n) 两个成员方法
从正则表达式匹配结果中提取子字符串
match.position(n)
用途:返回匹配结果中第 n 个捕获组的起始位置(相对于原字符串的起始位置)
参数:n 是捕获组的索引。0 表示整个匹配结果,1 表示第一个捕获组,依此类推
返回值:一个 size_t 类型的值,表示匹配的起始位置
match.length(n)
用途:返回匹配结果中第 n 个捕获组的长度
参数:n 是捕获组的索引。0 表示整个匹配结果,1 表示第一个捕获组,依此类推
返回值:一个 size_t 类型的值,表示匹配的长度
std::string text = "The quick brown fox jumps over the lazy dog.";
std::regex pattern(R"((\w+)\s+(\w+)\s+(\w+))");
std::smatch match;
if (std::regex_search(text, match, pattern)) {
std::cout << "匹配成功!" << std::endl;
for (size_t i = 0; i < match.size(); ++i) {
std::cout << "匹配组 " << i << ": " << match[i].str() << std::endl;
// match[i]是 std::ssub_match,这是 std::ssub_match.str(),跟之前的 smatch.str() 不一样
}
// 使用 substr 提取原字符串中匹配的子字符串
std::string sub = text.substr(match.position(0), match.length(0));
std::cout << "提取的子字符串: " << sub << std::endl;
}
else {
std::cout << "匹配失败。" << std::endl;
}
3)operator[](size_type n) const 的返回类型是 std::ssub_match
std::ssub_match 类包含以下成员,可以用于获取更多匹配信息:
str() const:返回匹配的字符串。
first:指向匹配的起始位置的迭代器。
second:指向匹配的结束位置的迭代器。
length() const:返回匹配的长度。
matched:一个布尔值,指示是否有匹配
4)std::string::npos
std::string::npos 的值是 size_t 类型的最大值
搜索操作:在使用 std::string 类的搜索相关方法时,如果搜索失败(即未找到指定的子字符串或字符),这些方法会返回 std::string::npos(find, rfind, find_last_of 方法)
边界检查:可以用来判断搜索操作是否成功,或者用作边界检查的条件
substr 方法:std::string::npos 可以用作默认的长度参数,表示提取到字符串末尾
6、smatch操作
这些操作也适用于 cmatch,wsmatch,wmatch 和 对应的 csub_match,wssub_match 和 wcsub_match
| 代码 | 操作 |
|---|---|
| m.ready() | 如果已经通过调用regex_search或regex_match设置了m,则返回true;否则返回false。如果ready返回false,则对m进行操作是未定义的 |
| m.size() | 如果匹配失败,则返回0;否则返回最近一次匹配的正则表达式中子表达式的数目 |
| m.empty() | 若m.size()为0,则返回true |
| m.prefix() | 一个ssub_match对象,表示当前匹配之前的序列 |
| m.suffix() | 一个ssub_match对象,表示当前匹配之后的部分 |
| m.format(…) | 见后 |
| 在接下来 接受一个索引的操作中,n的默认值为 0 且 必须小于 m.size() | 第一个子匹配 (索引为0) 表示整个匹配 |
| m.length(n) | 第n个正则的子表达式的大小 |
| m.position(n) | 第n个子表达式距序列开始的距离 |
| m.str(n) | 第n个子表达式 对应的string |
| m[n] | 对应第n个子表达式的ssub_match对象 |
| m.begin(), m.end() m.cbegin(), m.cend() | 表示m中sub_match元素范围的迭代器。与往常一样,cbegin和cend返回const_iterator |
17.17 查找输入序列中所有违反"ei"语法规则的单词
sregex_iterator,$ 表示匹配字符串的结尾
#include <regex>
#include <string>
#include <iostream>
using namespace std;
int main()
{
string str = "[[:alpha:]]*[^c]ei[[:alpha:]]"; // 不能在末尾加$
// $ 表示匹配字符串的结尾。如果在正则表达式末尾加上 $,它会要求匹配的模式必须在字符串的末尾
regex r(str, regex::icase); // 忽略大小写
// std::regex pattern(R"([[:alpha:]]*[^c]ei[[:alpha:]])", std::regex::icase);一样
string file = "freind receipt theif receive";
for (sregex_iterator it(file.begin(), file.end(), r), end_empty; it != end_empty; it++) {
cout << it->str() << " ";
}
cout << endl;
return 0;
}
std::sregex_iterator 典型的初始化方法
std::sregex_iterator it(begin, end, regex);
17.18 修改你的程序,忽略包含“ei”但并非拼写错误的单词,如“albeit”和“neighbor”
string::find()用法
std::vector<std::string> vec{"neighbor","albeit","beige","feint","heir","reign","their",
"counterfeit","foreign","inveigh","rein","veil","deign",
"forfeit","inveigle","seize","veineiderdown","freight",
"leisure","skein","weigheight","heifer","neigh","sleigh",
"weighteither","height","neighbour","sleight","weirfeign",
"heinous","neither","surfeit","weird"};
for(std::sregex_iterator it(s.begin(), s.end(), r), end_it; it != end_it; ++it)
{
if (find(vec.begin(), vec.end(), it->str()) != vec.end())
continue;
}
3.3 使用子表达式
1、正则表达式中的模式 通常包含一个或多个子表达式。一个子表达式是 模式的一部分,本身也具有意义。正则表达式语法 通常用括号表示子表达式
用括号来分组 可能的文件扩展名,模式中 点之前表示文件名前的部分也成为子表达式
// r有两个子表达式:第一个是点之前表示文件名的部分,第二个表示文件扩展名
regex r("([[:alnum:]]+)\\.(cpp|cxx|cc)$", regex::icase);
通过修改输出语句 使之只打印文件名
if (regex_search(filename, results, r))
cout << results.str(1) << endl; // 打印第一个子表达式
调用 regex_search 在名为 filename 的 string 中查找模式 r,并且传递 smatch 对象 results 来保存匹配结果
匹配对象 除了提供 匹配整体的相关信息外,还提供 访问模式中每个子表达式的功能。子匹配 是按位置来访问的。第一个子匹配位置为 0,表示 整个模式对应的匹配,随后是 每个子表达式对应的匹配。因此,模式中第一个子表达式,即表示文件名的子表达式,其位置为 1,而文件扩展名对应的子表达式 位置为 2
例如,如果文件名为 foo.cpp,则 results.str(0) 将保存 foo.cpp;results.str(1) 将保存 foo;而 results.str(2) 将保存 cpp
2、子表达式用于数据验证
子表达式的一个常见用途是 验证必须匹配 特定格式的数据。例如,美国的电话号码有十位数字,包含一个区号 和 一个七位的本地号码。区号通常放在括号里,但这并不是必需的。剩余七位数字可以用一个短横线、一个点或是一个空格分隔,也可以完全不用分隔符。希望接受任何这种格式的数据 而拒绝任何其他格式的数
将分两步来实现这一目标:首先,将用一个正则表达式 找到可能是电话号码的序列,然后 再调用一个函数来 完成数据验证
ECMA Script 正则表达式语言的一些特性:
- \d 表示单个数字 而 \d{n} 则表示一个 n 个数字的序列。(如,\d{3} 匹配三个数字的序列)
- 在方括号中的字符集 表示匹配这些字符中的 任意一个。(如,[- . ] 匹配一个短横线 或一个点 或一个空格。注意,点 在括号中没有特殊含义。)
- 后接 ‘?’ 的组件是 可选的。(如,\d{3}[- . ]? \d{4} 匹配这样的序列:开始是三个数字,后接一个可选的短横线或点或空格,然后是四个数字。此模式可以匹配 555-0132 或 555.0132 或 555 0132 或 5550132
- 类似 C++,ECMAScript 提供反斜线 表示一个字符本身 而不是其特殊含义。由于模式包含 括号 字符,而括号是 ECMAScript 中的特殊字符,因此 必须用 ( 和 ) 表示 括号是模式的一部分 而不是 特殊含义
由于反斜线是 C++中的特殊字符,在模式中 每次嵌入斜线时,都必须 用一个额外的反斜线 来告知 C++我们需要一个反斜线字符 而不是一个特殊符号。因此,用 \d{3} 来表示正则表达式 \d{3}
希望验证区号部分的数字 如果用了左括号,那么它是否也在区号后面 用了右括号。即,不希望出现 (908-555-1800 这样的号码
为了获得匹配的组成部分,在定义正则表达式时 使用了子表达式。每个子表达式 用一对括号包围:
// 整个正则表达式包含 七个子表达式:(ddd) 分隔符 ddd 分隔符 dddd
// 子表达式 1、3、4 和 6 是可选的;2、5 和 7 保存号码
"(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
- (\()? 表示 区号部分可选的左括号
- (\d{3}) 表示 区号
- (\))? 表示 区号部分可选的右括号
- [-. ]? 表示 区号部分可选的分隔符
- (\d{3}) 表示 号码的下三位数字
- ([-. ])? 表示 可选的分隔符
- (\d{4}) 表示 号码的最后四位数字
读取一个文件,并用此模式 查找与完整的电话号码匹配的数据。会调用一个名为 valid 的函数来检查电话号码格式是否合法:
string phone =
"(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phone); // regex 对象,用于查找电话号码的模式
smatch m;
string s;
// 输入文件中读取每条记录
while (getline(cin, s)) {
// 对每个匹配的电话号码
for (sregex_iterator it(s.begin(), s.end(), r), end_it;
it != end_it; ++it)
// 检查号码格式是否合法
if (valid(*it))
cout << "valid: " << it->str() << endl;
else
cout << "not valid: " << it->str() << endl;
}
3、使用子匹配操作
使用 下表 中描述的子匹配操作 来编写 valid 函数。pattern 有七个子表达式。每个 smatch 对象会包含八个 ssub_match 元素。位置 [0] 的元素表示 整个匹配;元素 [1]…[7] 表示 每个对应的子表达式
当调用 valid 时,已经有一个完整的匹配,但不知道 每个可选的子表达式是否是匹配的一部分。如果 一个子表达式 是完整匹配的一部分,则其对应的 ssub_match 对象的 matched 成员为 true
子匹配操作
注意:这些操作适用于ssub_match、csub_match、wssub_match、wcsub_match
| 代码 | 功能 |
|---|---|
| matched | 一个 public bool 数据成员,指出此 ssub_match 是否匹配了 |
| first, second | public 数据成员,指向 匹配序列首元素 和 尾后位置的迭代器。如果 未匹配,则 first 和 second 是相等的 |
| length() | 匹配的大小。如果 matched 为 false,则返回 0 |
| str() | 返回一个 包含输入中匹配部分的 string。如果 matched 为 false,则返回空 string |
| s = ssub | 将 ssub_match 对象 ssub 转换为 string 对象 s。等价于 s = ssub.str()。转换运算符不是 explicit 的 |
区号要么是 完整括号包围的,要么 完全没有括号,且有括号的 后面不能跟 -。因此,valid 要做什么工作依赖于 号码是否以一个括号开始:
bool valid(const smatch& m) {
// 如果区号前有一个左括号
if (m[1].matched)
// 则区号后必须有一个右括号,之后紧跟剩余号码或一个空格
return m[3].matched && (m[4].matched == 0 || m[4].str() == " ");
else
// 否则,区号后不能有右括号
// 另两个组成部分间的分隔字符必须匹配
return !m[3].matched && m[4].str() == m[6].str();
}
17.20 编写 自己的版本验证电话号码程序
#include <iostream>
#include <string>
#include <regex>
using namespace std;
bool Valid(const smatch& s) { // smatch数组,对应每个子表达式的符合情况
if (s[1].matched) {
return s[3].matched && (s[4].matched == 0 || s[4].str() == " ");
}
else
return !s[3].matched && (s[4].str() == s[6].str());
}
int main()
{
string p = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(p);
smatch s;
string str;
while (getline(cin, str)) {
for (sregex_iterator it(str.begin(), str.end(), r), end; it != end; it++) {
if (Valid(*it)) // sregex_iterator引用为smatch
cout << "valid: " << it->str() << endl;
else
cout << "not valid: " << it->str() << endl;
}
}
return 0;
}
17.22 重写的你的电话号码程序,使之允许在号码的三个部分之间放置任意多个空白符
// 多了 ([ ]*)?
std::string phone = "(\\()?(\\d{3})(\\))?([-. ])?([ ]*)?(\\d{3})([-. ]?)([ ]*)?(\\d{4})";
17.23 编写查找邮政编码的正则表达式。一个美国邮政编码可以由五位或九位数字组成。前五位数字和后四位数字之间可以用一个短横线分隔
#include <iostream>
#include <regex>
#include <vector>
using namespace std;
bool valid(const smatch& s) {
// 一定要加const,因为*it是 const sregex_iterator 去引用,被加了 const
// 另外,如果参数被声明为 const 引用,就可以接受临时对象作为参数,因为临时对象不能绑定到非常量引用,但可以绑定到常量引用
if (s[3].matched) { // 别忘了使用matched属性
return true; // 9位数
}
else {
return !s[2].matched; // 5位数
}
}
int main()
{
string str = "(\\d{5})([-])?(\\d{4})?";
regex r(str);
string s;
while (getline(cin, s)) {
for (sregex_iterator it(s.begin(), s.end(), r), end; it != end; ++it) {
if (valid(*it)) {
cout << "valid: " << it->str() << endl;
}
else {
cout << "invalid: " << it->str() << endl;
}
}
}
return 0;
}
3.4 使用 regex_replace
1、正则表达式 不仅用在 希望查找一个给定序列的时候,还用于 在当想将找到的序列 替换为 另一个序列的时候
希望在输入序列中 查找并替换一个正则表达式时,可以调用 regex_replace。下表 描述了 regex_replace,类似搜索函数,它接受一个输入字符序列 和 一个regex对象,不同的是,它还接受 一个描述我们想要的输出格式的字符串
正则表达式替换操作
| 代码 | 操作 |
|---|---|
| m.format(dest, fmt, mft); m.format(fmt, mft) | 使用格式字符串fmt生成格式化输出,匹配在m中,可选的match_flag_type标志在mft中。第一个版本写入迭代器dest指向的目的位置 并接受fmt参数,可以是一个string,也可以是表示字符数组中范围的一对指针。第二个版本 返回一个string,保存输出,并接受fmt参数,可以是一个string,也可以是 一个指向空字符结尾的 字符数组的指针。mft的默认值为format_default |
| regex_replace(dest, seq, r, fmt, mft); regex_replace(seq, r, fmt, mft) | 遍历seq,用regex_search查找与regex对象r匹配的子串。使用格式字符串fmt 和 可选的match_flag_type标志来生成输出。第一个版本 将输出写入到迭代器dest指定的位置,并接受一对迭代器seq表示范围。第二个版本 返回一个string,保存输出,且seq 既可以是一个string 也可以是一个指向 空字符结束的字符数组的指针。在所有情况下,fmt既可以是一个string 也可以是一个指向空字符结束的字符数组的指针,且mft的默认值为match_default |
替换字符串 由想要的字符组合与匹配的子串 对应的子表达式而组成。希望 在替换字符串中 使用第二个、第五个和第七个子表达式,用一个符号 $ 后跟子表达式的索引号 来表示一个特定的子表达式:
string fmt = "$2.$5.$7"; // 将号码格式改为 ddd.ddd.dddd
可以 像下面这样使用 正则表达式模式和替换字符串:
regex r(phone); // 用来寻找模式的regex对象
string number = "(908) 555-1800";
cout << regex_replace(number, r, fmt) << endl;
此程序的输出为:
908.555.1800
2、只替换输入序列的一部分
morgan (201) 555-2368 862-555-0123
drew (973) 555-0130
lee (609) 555-0132 2015550175 800.555-0000
希望将数据转换为下面这样:
morgan 201.555.2368 862.555.0123
drew 973.555.0130
lee 609.555.0132 201.555.0175 800.555.0000
可以使用下面的程序完成这种转换:
int main()
{
string phone = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phone); // 寻找模式所用的regex对象
string s;
string fmt = "$2.$5.$7"; // 将号码格式改为 ddd.ddd.dddd
// 从输入文件中读取每条记录
while(getline(cin, s))
cout << regex_replace(s, r, fmt) << endl; // 替换,把所有符合r要求的替换掉
return 0;
}
重写 电话号码程序,使之只输出每个人的第一个电话号码
#include <iostream>
#include <string>
#include <regex>
//tx 908.555.1500 (908)5551500
int main()
{
std::string phone = "(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ]?)(\\d{4})*";
std::regex r(phone);
std::smatch m;
std::string s;
std::string fmt = "$2.$5.$7";
while (std::getline(std::cin, s))
{
std::smatch result;
std::regex_search(s, result, r); // sregex_iterator / regex_replace来查找并处理所有匹配项
if (!result.empty())
{
std::cout << result.prefix() << result.format(fmt) << std::endl;
}
else
{
std::cout << "Sorry, No match." << std::endl;
}
}
return 0;
}
result.prefix():
result.prefix() 返回的是第一个匹配子字符串之前的字符串部分。如果有多个匹配,result.prefix() 仅会返回第一个匹配之前的内容
result.format(fmt):
result.format(fmt) 使用指定的格式 fmt 格式化匹配结果。fmt 中可以包含替换字符串,例如 $1 表示第一个子表达式匹配的内容,$2 表示第二个子表达式匹配的内容,以此类推。result.format(fmt) 仅会格式化第一个匹配的结果
如果 希望处理所有匹配结果,需要使用 std::sregex_iterator 进行迭代,而不是只使用 std::regex_search
3、用来控制匹配 和 格式化的标志
标准库 还定义了 用来在替换过程中控制匹配或格式化的标志。下表 列出了这些值。这些标志 可以传递给函数regex_search 或 regex_match 或是 类smatch的format成员
匹配和格式化标志的类型为 match_flag_type。这些值 都定义在名为 regex_constants 的命名空间中。类似用于bind 的 placeholders
#include <iostream>
#include <functional>
using namespace std::placeholders;
void print_values(int a, int b, int c) {
std::cout << "a: " << a << ", b: " << b << ", c: " << c << std::endl;
}
int main() {
// bind 的 placeholders
// 绑定第一个参数为10,其他两个参数位置交换
auto bound_func1 = std::bind(print_values, 10, _2, _1);
bound_func1(30, 20); // 输出:a: 10, b: 20, c: 30
// 绑定第三个参数为30,第一个和第二个参数按顺序传递
auto bound_func2 = std::bind(print_values, _1, _2, 30);
bound_func2(10, 20); // 输出:a: 10, b: 20, c: 30
return 0;
}
占位符 _1 表示调用时传递的第一个参数,_2 表示调用时传递的第二个参数,以此类推。它们在 std::placeholders 命名空间中定义,因此在使用时需要包含这个命名空间
regex_constants也是定义在命名空间std中的命名空间。为了使用regex_constants中的名字,我们必须在名字前加上两个命名空间限定符:
using std::regex_constants::format_no_copy;
如果代码中 使用了 format_no_copy,则表示 想要使用命名空间 std::constants 中的这个名字。也可以 用另一种形式的 using 来代替上面的代码
using namespace std::regex_constants;
匹配标志
定义在 regex_constants::match_flag_type 中
| 代码 | 功能 |
|---|---|
| match_default | 等价于 format_default |
| match_not_bol | 不将首字符 作为行首处理 |
| match_not_eol | 不将尾字符作为行尾处理 |
| match_not_bow | 不将首字母作为单词首处理 |
| match_not_eow | 不将尾字母作为单词尾处理 |
| match_any | 如果存在多于一个匹配,则可返回任意一个匹配 |
| match_not_null | 不匹配任何空序列 |
| match_continuous | 匹配必须从输入的首字符开始 |
| match_prev_avail | 输入序列 包含第一个匹配之前的内容 |
| format_default | 用ECMAScript规则替换字符串 |
| format_sed | 用POSIX sed规则替换字符串 |
| format_no_copy | 不输出输入序列中未匹配的部分 |
| format_first_only | 只替换子表达式的第一次出现 |
- 默认情况下,正则表达式的 ^ 元字符用于匹配字符串的开头。当使用 match_not_bol 标志时,正则表达式引擎会忽略 ^ 作为行首的作用,这意味着 ^ 将不会匹配字符串的开头
#include <iostream>
#include <regex>
#include <string>
int main() {
std::string text = "world"; // 在vs中只能有一行
std::regex pattern("^world");
std::smatch match;
// 不使用 match_not_bol 标志
if (std::regex_search(text, match, pattern)) {
std::cout << "匹配成功(无 match_not_bol): " << match.str() << std::endl;
}
else {
std::cout << "未匹配(无 match_not_bol)" << std::endl;
}
// 使用 match_not_bol 标志
if (std::regex_search(text, match, pattern, std::regex_constants::match_not_bol)) {
std::cout << "匹配成功(使用 match_not_bol): " << match.str() << std::endl;
}
else {
std::cout << "未匹配(使用 match_not_bol)" << std::endl;
}
return 0;
}
不使用 match_not_bol:会匹配成功,因为 ^ 在 首匹配到 world。
使用 match_not_bol:不会匹配成功,因为 ^ 被忽略,不能被匹配行首
- match_not_eol:正则表达式的 $ 元字符用于匹配字符串的结尾
std::string text = "Hello world";
std::regex pattern("world$");
不使用 match_not_bol:会匹配成功,使用 match_not_bol:不会匹配成功
-
match_not_bow,match_not_eow: \b
-
默认情况下,正则表达式引擎在匹配时假设搜索的起始位置之前没有可用字符。然而,在某些情况下,我们希望正则表达式引擎假设在搜索的起始位置之前有可用字符。match_prev_avail 标志可以实现这种行为
4、使用格式标志
默认情况下,regex_replace 输出整个输入序列。未与正则表达式匹配的部分 会原样输出;匹配的部分 按格式字符串指定的格式输出。可以通过在 regex_replace 调用中指定 format_no_copy 来改变这种默认行为:
// 只生成电话号码:用新的格式字符串
string fmt2 = "$2.$5.$7"; // 在最后一部分号码后 放置空格作为分隔符
// 通知regex_replace只拷贝它替换的文本
cout << regex_replace(s, r, fmt2, format_no_copy) << endl;
给定相同的输入,此版本的程序生成
01.555.2368 862.555.0123
973.555.0130 609.555.0132
201.555.0175 800.555.0000
4、随机数
1、C 库函数 rand 来生成随机数。此函数 生成均匀分布的伪随机整数,每个随机数的范围 在 0 和 一个系统相关的最大值(至少为 32767)之间
rand 函数有一些问题:很多程序 需要不同范围的随机数。一些应用需要随机浮点数。一些程序需要非均匀分布的数
定义在头文件 random 中的随机数数据库 通过一组协作的类 来解决这些问题:随机数引擎类 和 随机数分布类。一个引擎类 可以生成 unsigned 随机整数序列;一个分布类 使用一个引擎对象 生成指定类型的、在给定范围内的、服从特定概率分布的 随机数
随机数数据库的组成
| 类 | 作用 |
|---|---|
| 引擎 | 类型,生成随机 unsigned 整数序列 |
| 分布 | 类型,使用引擎返回 服从特定概率分布的随机数 |
C++程序不应该使用库函数 rand, 而应使用 default_random_engine 类 和 恰当的分布类对象
4.1 随机数引擎和分布
1、随机数引擎 是函数对象类,定义了一个调用运算符,该运算符不接受参数 并返回一个随机 unsigned 整数。可以通过调用 一个随机数引擎对象 来生成原始随机数:
default_random_engine e; // 生成随机无符号数
for (size_t i = 0; i < 10; ++i)
// e() “调用”对象来生成下一个随机数
cout << e() << " ";
16807 282475249 1622650073 984943658 1144108930 4700211272 …
标准库 定义 多个随机数引擎类,区别在于 性能和随机性质量不同。每个编译器 都会指定其中一个作为 default_random_engine 类型
2、随机数引擎操作
| 代码 | 操作 |
|---|---|
| Engine e; | 默认构造函数,使用该引擎类型默认的种子 |
| Engine e(s); | 使用整数值 s 作为种子 |
| e.seed(s) | 使用整数值 s 重置引擎的状态 |
| e.min(); e.max() | 此种子可生成的最小值和最大值 |
| Engine::result_type | 此引擎生成的 unsigned 整型类型 |
| e.discard(u) | 将引擎推进 u 步;u 的类型为 unsigned long long |
3、分布类型和引擎
为了得到 在一个指定范围内的数,使用一个分布类型的对象:
// 生成 0 到 9 之间(包含)均匀分布的随机数
uniform_int_distribution<unsigned> u(0,9);
default_random_engine e; // 生成无符号随机整数
for (size_t i = 0; i < 10; ++i)
// 将u 作为随机数源
// 每个调用 返回在指定范围内并服从均匀分布的值
cout << u(e) << " ";
此代码生成下面这样的输出:
0 1 7 4 5 2 0 6 6 9
将 u 定义为 uniform_int_distribution<unsigned>。此类型 生成均匀分布的 unsigned 值。此类生成均匀分布的 unsigned 值
类似引擎类型,分布类型也是 函数对象类。分布类型 定义了 一个调用运算符,它接受一个随机数引擎 作为参数。分布对象 使用它的引擎参数 生成随机数,并将其映射到指定的分布
传递给分布对象的是引擎对象本身,即 u(e),传递的是引擎本身(e),而不是它生成的下一个值(e()),原因是一些分布 可能需要调用引擎多次才能得到一个值
当我们说 随机数发生器 时,是指 分布对象 和 引擎对象的组合
3、比较随机数引擎和 rand 函数
随机数引擎生成的 unsigned 整数在一个系统定义的范围内,而 rand 生成的数的范围在 0 到 RAND_MAX 之间
4、引擎生成一个数值序列
即使生成的数 看起来是随机的,但对 一个给定的发生器,每次运行程序 它都会返回相同的数值序列。序列不变这一事实 在调试时非常有用
每次调用这个函数都会生成相同的 100 个数
vector<unsigned> bad_randVec()
{
default_random_engine e;
uniform_int_distribution<unsigned> u(0,9);
vector<unsigned> ret;
for (size_t i = 0; i < 100; ++i)
ret.push_back(u(e));
return ret;
}
但是,每次调用这个函数 都会返回相同的 vector
vector<unsigned> v1(bad_randVec());
vector<unsigned> v2(bad_randVec());
// 将打印"equal"
cout << ((v1 == v2) ? "equal" : "not equal") << endl;
要让每次调用这个函 数都会生成不同(不一定)的 100 个数,将引擎和关联的分布对象定义为 static 的
// 返回一个向量,包含 100 个均匀分布的随机数
vector<unsigned> good_randVec()
{
// 由于我们希望引擎和分布对象 保持状态,因此应该将它们定义为 static 的,从而每次调用都会生成新的数
static default_random_engine e;
static uniform_int_distribution<unsigned> u(0, 9);
vector<unsigned> ret;
for (size_t i = 0; i < 100; ++i)
ret.push_back(u(e));
return ret;
}
由于 e 和 u 是 static 的,因此它们在函数调用之间会保持住状态。第一次调用会使用 u(e) 生成的序列中的前 100 个随机数,第二次调用会获得接下来 100 个,以此类推
#include <iostream>
#include <random>
using namespace std;
void random_func() {
static default_random_engine e;
static uniform_int_distribution<unsigned> u;
cout << u.min() << " " << u.max() << endl;
cout << u(e) << endl;
}
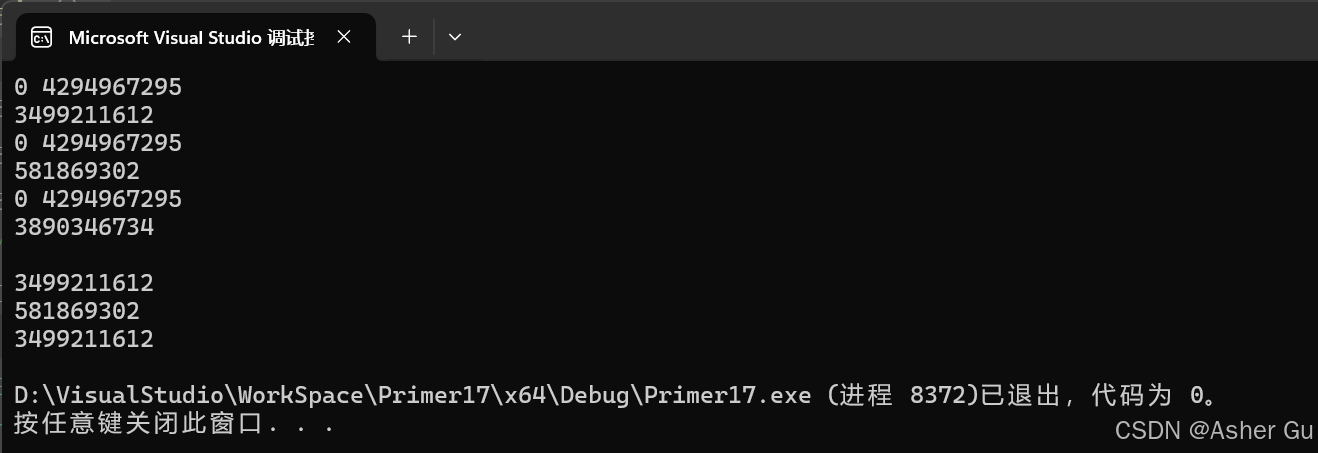
int main()
{
random_func(); // (1)
random_func();
random_func();
// 单次运行中 每次调用 产生的数值都不一样,但是 每次运行程序三个数的值都和上一次运行一致
cout << endl;
default_random_engine e;
uniform_int_distribution<unsigned> u;
cout << u(e) << endl; // (2)
cout << u(e) << endl; // 这两个是不一致的,如果每次调用都会创建新引擎,就会导致一致
default_random_engine e2;
uniform_int_distribution<unsigned> u2;
cout << u2(e2) << endl; // 这与(1)和(2)中调用 u(e)是一致的,都是初始化后第一次调用
return 0;
}
运行结果
第二次运行结果(跟第一次一样)
5、设置随机数生成器种子
随机数生成器 会生成 相同的随机数序列 这一特性在调试中很有用。但是,一旦我们的程序 调试完成,我们通常希望 每次运行程序都会生成 不同的随机结果。可以通过 提供一个种子来达到这一目的。种子就是一个数值,引擎可以利用它 从序列中提供一个新的位置 重新开始生成随机数
为引擎设置种子有两种方式:在创建引擎对象时提供种子,或者调用引擎的 seed 成员(不要使用 0 作为种子,因为这可能会导致引擎初始化为一个固定的初始状态):
default_random_engine e1; // 使用默认种子
default_random_engine e2(2147483646); // 使用指定的种子值
// e3 和 e4 将生成相同的序列,因为它们使用了相同的种子
default_random_engine e3; // 使用默认种子值
e3.seed(32767); // 调用 seed 设置一个新的种子值
default_random_engine e4(32767); // 将种子值设置为 32767
前两个引擎 e1 和 e2 的种子不同,因此应该 生成不同的序列。后两个引擎 e3 和 e4 有相同的种子,它们将生成相同的序列
选择一个好的种子,与生成 好的随机数 所涉及的其他技术事情相同,是极其困难的。最常用的方法是 调用系统函数 time。这个函数定义在头文件 ctime 中,它返回 从一个特定时刻到当前经过了多少秒。函数 time 接受单个指针参数,它指向用于写入时间的数据结构。如果此指针为空,则函数简单地返回时间
default_random_engine e1(time(0)); // 精确随机些的种子
由于 time 返回 以秒计的时间,因此这种方式 只适用于生成种子的间隔为 秒级或更长的应用
如果程序作为 一个自动进程的一部分 反复运行,将 time 的返回值 作为种子的方案就无效了,它可能 多次使用的都是相同的种子
17.29 每次调用生成 并返回一个均匀分布的随机 unsigned int,并允许用户 提供一个种子作为可选参数
#include <iostream>
#include <random>
#include <ctime>
using namespace std;
void random_func(unsigned i) {
default_random_engine e(i);
// 如果是static的话调用两次 random_func(2)还是不一样的
uniform_int_distribution<unsigned> u;
cout << u.min() << " " << u.max() << endl;
cout << u(e) << endl;
}
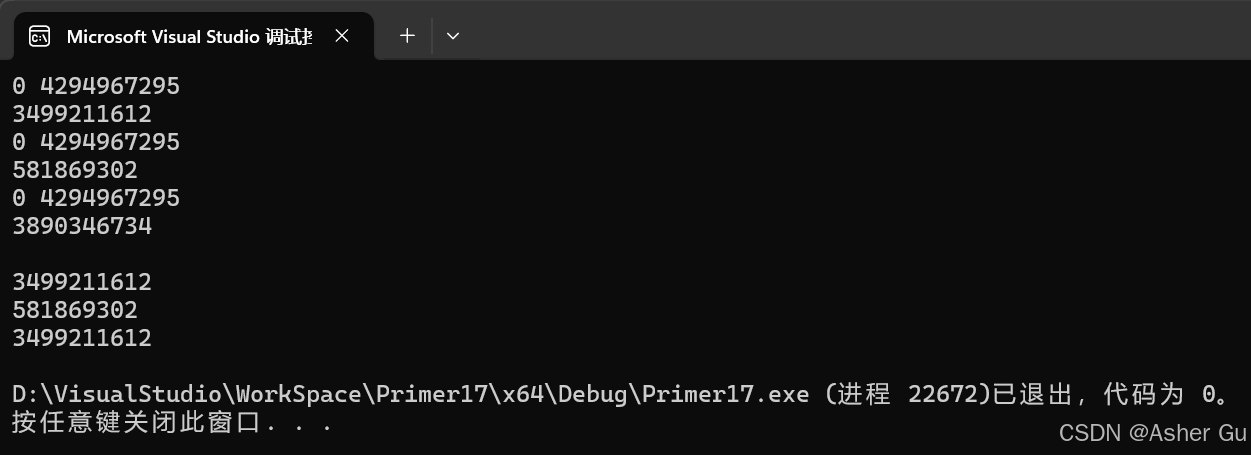
int main()
{
// (1),(2)不同,(2),(3)相同;每次运行生成的数不变
random_func(1); // (1)
random_func(2); // (2)
random_func(2); // (3)
random_func(time(0)); // 每次运行生成的数都是不同的
return 0;
}
运行结果
第二次运行结果
4.2 其他随机数分布
1、随机数引擎生成 unsigned 数,范围内的每个数被生成的概率都是相同的。程序常常需要不同类型或不同分布的随机数。分布对象和引擎对象协同工作,生成要求的结果
2、生成随机实数
程序常常 需要一个随机浮点数的源。特别是,程序经常需要 0 到 1 之间的随机数
最常用但不正确的从 rand 获得一个随机浮点数的方法是用 rand() 的结果除以 RAND_MAX,即系统定义的 rand 可以生成的最大随机数的上界。这种方法不正确的原因是随机整数的精度通常低于随机浮点数,这样,有一些浮点值就永远不会被生成了
假设 RAND_MAX 是 32767,意味着 rand() 可以生成的整数范围是 0 到 32767。如果我们把这些整数除以 32767,理论上得到的浮点数范围是 0.0 到 1.0。然而,由于 rand() 只能生成 32768 个离散的整数值,除以 RAND_MAX 后得到的浮点数也是离散的。对于浮点数来说,这种离散的分布导致了一些浮点值无法被生成,因为它们没有相应的整数值来表示
可以定义一个 uniform_real_distribution 类型的对象,并让标准库 来处理 从随机整数到随机浮点数的映射。与处理 uniform_int_distribution 一样,在定义对象时,我们指定最小值和最大值:
default_random_engine e; // 生成无符号随机整数
uniform_real_distribution<double> u(0,1);
for (size_t i = 0; i < 10; ++i)
cout << u(e) << " ";
0.131538 0.45865 0.218959 0.678865 0.934693 0.519416 …
3、分布类型所支持的操作(d 就是前面代码中的 u)
| 代码 | 操作 |
|---|---|
| Dist d; | 默认构造函数:使 d 准备好被使用。其他构造函数依赖于 Dist 的类型,分布类型的构造函数是 explicit 的 |
| d(e) | 用相同的 e 连续调用 d 会产生一个 根据 d 的分布类型生成的随机数序列;e 是一个随机数引擎对象 |
| d.min(), d.max() | 返回 d(e) 能产生的最小值和最大值 |
| d.reset() | 重建 d 的状态,使得随后对 d 的使用不依赖于 d 已经生成的值 |
4、使用分布的默认结果类型
分布类型都是模板,具有单一的模板类型参数,表示分布生成的随机数的类型,这些分布类型 要么生成浮点类型 要么生成整数类型
每个分布模板 都有一个默认模板实参。生成浮点值的分布类型 默认生成 double 值,而生成整数值的分布类型 默认生成 int 值。由于分布类型 只有一个模板参数,因此当希望使用默认随机数类型时 要记得在模板名之后使用空尖括号<>
// 空<>表示 希望使用默认结果类型
uniform_real_distribution<> u(0,1); // 默认生成double值
5、生成非均匀分布的随机数
将生成 一个正态分布的值的序列,并画出值的分布。由于 normal_distribution 生成浮点值,程序使用头文件 cmath 中的 lround 函数 将每个随机数舍入到最近的整数。将生成 200 个数,它们以均值 4 为中心,标准差为 1.5。由于使用的是正态分布,我们期望生成的数中大约 99%都在 0 到 8 之间(包含)
default_random_engine e; // 生成随机整数
normal_distribution<> n(4, 1.5); // 均值 4,标准差 1.5
vector<unsigned> vals(9); // 9个元素初始为0
for (size_t i = 0; i != 200; ++i) {
unsigned v = lround(n(e)); // 舍入到最接近的整数
if (v < vals.size()) // 如果结果在范围内
++vals[v]; // 统计每个数出现了多少次
}
for (size_t j = 0; j != vals.size(); ++j)
cout << j << ": " << string(vals[j], '*') << endl;
6、bernoulli_distribution 类
有一个分布不接受模板参数,即 bernoulli_distribution(伯努利),因为它是一个普通类,而非模板。此分布总是返回一个 bool 值。它返回 true 的概率是一个常数,此概率的默认值是 0.5

可以用一个范围 0 到 1 的 uniform_int_distribution 来选择先行的游戏者,也可以用 伯努利分布 来完成这一选择
string resp;
default_random_engine e; // e应该保持状态,所以必须在循环外定义!
bernoulli_distribution b; // 默认是 50/50 的概率
do {
bool first = b(e); // 若为true,则程序先行
cout << (first ? "We go first" : "You get to go first") << endl;
// 传递谁先行的指示,进行游戏
cout << ((play(first)) ? "sorry, you lost" : "congrats, you won") << endl;
cout << "play again? Enter 'yes' or 'no'" << endl;
} while (cin >> resp && resp[0] == 'y'); // 在循环内定义resp,会报错:未定义resp
由于引擎返回相同的随机数序列,所以 必须在循环外声明引擎对象。否则,每步循环 都会创建一个新引擎,因而每步循环 都会生成相同的值。类似的,分布对象 也要求保持状态,因此也应该在循环外定义
在此程序中使用 bernoulli_distribution 的一个原因是 它允许我们调整选择先行一方的概率:
bernoulli_distribution b(.55); // 给程序一个微小的优势
程序有 55/45 的机会先行
5、IO 库再探
三个更特殊的 IO 库特性:格式控制、未格式化 IO 和 随机访问
5.1 格式化输入与输出
1、除了条件状态外(eofbit, badbit, failbit, goodbit)
iostream对象(例如std::cin、std::cout、std::cerr等)都有一个内部的条件状态,用于表示流的当前状态。流的条件状态通过流的 state 标志来表示
eofbit:表示流到达了文件的末尾(end-of-file)
failbit:表示一次输入/输出操作失败,通常是由于数据格式不匹配或其他类似问题
badbit:表示一个更严重的I/O错误,例如物理读取或写入错误
goodbit:表示流没有任何错误。这实际上是条件状态的默认状态,即状态标志中没有其他位被设置时的状态
通过流对象的成员函数检查这些状态:bool eof() const; 检查eofbit是否被设置。bool fail() const; 检查failbit是否被设置。bool bad() const; 检查badbit是否被设置。bool good() const; 检查流是否处于有效状态(即没有错误)。
此外,流对象还提供了一个成员函数clear(),可以用于清除流的错误状态
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("example.txt");
if (!file) {
std::cerr << "Failed to open file.\n";
return 1;
}
int number;
while (file >> number) {
std::cout << "Read number: " << number << '\n';
}
if (file.eof()) {
std::cout << "Reached end of file.\n";
} else if (file.fail()) {
std::cerr << "Input failed (bad format or other error).\n";
} else if (file.bad()) {
std::cerr << "Bad I/O operation.\n";
}
file.clear(); // Clear the error state
return 0;
}
每个 iostream 对象 还维护一个 格式状态 来控制 IO 如何格式化的细节。格式状态控制 格式化的某些方面,如整型值是以 几进制、浮点值的精度、一个输出单位的宽度等
2、标准库定义了 一组操纵符 来修改流的格式状态。一个操纵符 是一个函数 或 一个对象,会影响流的状态,并能作为 输入或输出运算符的运算对象。类似输入和输出运算符,操纵符也返回它所处理的流对象,因此 可以在一条语句中 组合操纵符和数据
已经在程序中 使用过操纵符 endl,将它写到输出流时,就像它是一个值 一样。但 endl 不是一个普通值,而是一个操作:它输出一个换行符 并刷新缓冲区
3、很多操作符 改变格式状态
操纵符用于两大类输出控制:控制数值的输出形式 以及 控制补白的数量和位置。大多数改变格式状态的操作符 都是 设置/复原 成对的:一个操纵符 用来将格式状态设置为一个新值,另一个 用来将其复原,恢复为正常的默认格式
当操纵符 改変流的格式状态时,通常改変后的状态 对所有后续IO都生效
许多程序(而且更重要的是,许多程序员)期望流的状态 符合标准库的正常默认设置,将流的状态置于一个非标准状态 可能会导致错误。因此,通常 最好在不再需要特殊格式时 尽快将流回到默认状态
4、控制布尔值的格式
默认情况下,bool值打印为1或0。可以通过 对流使用 boolalpha 操纵符来覆盖这种格式:
cout << "default bool values: " << true << " " << false
<< boolalpha // 设置cout的内部状态,输出true和false而非1和0
"\nalpha bool values: " << true << " " << false << endl;
default bool values: 1 0
alpha bool values: true false
一旦向 cout “写入” 了 boolalpha,我们就改变了 cout 打印 bool 值的方式。后续打印 bool 值的操作都会打印 true 或 false 而非 1 或 0
为了取消 cout 格式状态的改变,我们使用 noboolalpha:
bool bool_val = get_status();
cout << boolalpha // 设置cout的内部状态
<< bool_val
<< noboolalpha; // 将内部状态恢复为默认格式,改变了bool值的格式,只对bool_val的输出有效
5、指定整数值的进制
默认情况下,整数值的输入输出 使用十进制。我们可以使用操纵符 hex、oct 和 dec 将其改为 十六进制、八进制或是改回十进制:
cout << "default:" << 20 << " " << 1024 << endl;
cout << "octal:" << oct << 20 << " " << 1024 << endl;
cout << "hex:" << hex << 20 << " " << 1024 << endl;
cout << "decimal:" << dec << 20 << " " << 1024 << endl;
类似 boolalpha,这些操作符 也会改变格式状态。它们会影响 下一个和随后所有的整型输出,直至 另一个操作符又改变了格式为止
操作符 hex、oct 和 dec 只影响 整型运算对象,浮点值的表示形式不受影响
6、在输出中指出进制:使用 showbase 操作符,遵循与整型常量中指定进制相同的规范
- 前导 0x 表示十六进制
- 前导 0 表示八进制
- 无前导字符串表示十进制
cout << showbase; // 当打印整型值时显示进制
cout << "default: " << 20 << " " << 1024 << endl;
cout << "in octal: " << oct << 20 << " " << 1024 << endl;
cout << "in hex: " << hex << 20 << " " << 1024 << endl;
cout << "in decimal: " << dec << 20 << " " << 1024 << endl;
cout << noshowbase; // 恢复原状
default: 20 1024
in octal: 024 02000
in hex: 0x14 0x400
in decimal: 20 1024
操纵符 noshowbase 恢复 cout 的状态,从而不再显示整型值的进制
默认情况下,十六进制值 会以小写字母打印,前导字符 也是小写的 x。可以通过使用 uppercase 操纵符 来输出大写的 X 并将 十六进制数字 a-f 以大写输出:
cout << uppercase << showbase << hex
<< "printed in hexadecimal: " << 20 << " " << 1024
<< nouppercase << noshowbase << dec << endl;
printed in hexadecimal: 0X14 0X400
使用了操纵符 nouppercase、noshowbase 和 dec 来重置流的状态
7、控制浮点数格式
可以控制浮点数输出三种格式:
- 以多高精度(多少个数字)打印浮点值
- 数值是打印为 十六进制、定点十进制还是科学记数法形式
- 对于没有小数部分的浮点值是否打印小数点
默认情况下,浮点值 按六位数字精度打印;如果 浮点值没有小数部分,则不打印小数点;
根据浮点数的值 选择 打印成定点十进制 或 科学计数法形式。非常大和非常小的值 打印为 科学计数法形式,其他值 打印为 定点十进制形式
8、指定打印精度
默认情况下,精度会控制打印的数字的总数。当打印时,浮点值按当前精度舍入而非截断。因此,如果当前精度为四位数字,则 3.14159 将打印为 3.142;如果精度为三位数字,则打印为 3.14
可以通过调用 IO 对象的 precision 成员 或 使用 setprecision 操作符来改变精度。precision 成员是重载的。一个版本接受一个 int 值,将精度设置为此值,并返回旧精度值。另一个版本不接受参数,返回当前精度值。setprecision 操作符接受一个参数,用来设置精度
// cout.precision 返回当前精度值
cout << "Precision: " << cout.precision()
<< ", Value: " << sqrt(2.0) << endl;
// cout.precision(12) 将打印精度设置为 12 位数字
cout.precision(12);
cout << "Precision: " << cout.precision()
<< ", Value: " << sqrt(2.0) << endl;
// 另一种设置精度的方法是使用 setprecision 操作符
cout << setprecision(3);
cout << "Precision: " << cout.precision() << ", Value: " << sqrt(2.0) << endl;
Precision: 6, Value: 1.41421
Precision: 12, Value: 1.41421356237
Precision: 3, Value: 1.41
此程序调用标准库 sqrt 函数,它定义在头文件 cmath 中
9、定义在 istream 中的操作符
| 代码 | 功能 |
|---|---|
| boolalpha | 将 true 和 false 输出为字符串 |
| *noboolalpha | 将 true 和 false 输出为 1,0 |
| showbase | 对整型值 输出表示进制的前缀 |
| *noshowbase | 不生成表示进制的前缀 |
| showpoint | 对浮点值总是显示小数点 |
| *noshowpoint | 只有当浮点值包含小数部分时 才显示小数点 |
| showpos | 对非负数显示+ |
| *noshowpos | 对非负数不显示+ |
| uppercase | 在十六进制中打印 0X,在科学记数法中打印 E |
| *nouppercase | 在十六进制中打印 0x,在科学记数法中打印 e |
| *dec | 整型值显示为十进制 |
| hex | 整型值显示为十六进制 |
| oct | 整型值显示为八进制 |
| left | 在值的右侧添加填充字符 |
| right | 在值的左侧添加填充字符 |
| internal | 在符号和值之间添加填充字符 |
| fixed | 浮点值显示为定点十进制 |
| scientific | 浮点值显示为科学记数法 |
| hexfloat | 浮点值显示为十六进制(C++11 新特性) |
| defaultfloat | 重置浮点数格式为十进制(C++11 新特性) |
| unitbuf | 每次输入操作后都刷新缓冲区 |
| *nounitbuf | 恢复正常的缓冲区刷新方式 |
| *skipws | 输入运算符跳过空白符 |
| noskipws | 输入运算符不跳过空白符 |
| flush | 刷新 ostream 缓冲区 |
| ends | 插入空字符,然后刷新 ostringstream 缓冲区 |
| endl | 插入换行,然后刷新 ostringstream 缓冲区 |
*表示默认流状态
10、指定浮点记数法
除非你需要控制浮点数的表示形式(如,按列打印数据或打印表示金额或百分比的数据),否则由标准库选择记数法是最好的方式
这些操作符 也改变 流的精度的默认含义。在执行 scientific、fixed 或 hexfloat 后,精度值控制的是 小数点后面的数字位数,而默认情况下 精度值 指定的是数字的总位数——包括小数点之后的数字 也包括小数点之前的数字。使用 fixed 或 scientific 让我们可以按列打印值,因为小数点距小数部分的距离是固定的:
#include <iostream>
#include <iomanip>
int main() {
double values[] = {3.14159, 2.71828, 1.61803, 0.57721};
std::cout << std::fixed << std::setprecision(2); // 固定小数点后两位
for (double value : values) {
std::cout << std::setw(10) << value << std::endl; // 按列对齐
}
return 0;
}
输出
3.14
2.72
1.62
0.58
11、打印小数点
默认情况下,当一个浮点值的小数部分为 0 时,不显示小数点。showpoint 操纵符强制打印小数点:
cout << 10.0 << endl; // 打印 10
cout << showpoint << 10.0; // 打印 10.0000
cout << noshowpoint << endl; // 恢复小数点的默认格式
12、输出补白
- setw 指定下一个数字 或 字符串值 的最小空间
- left 表示左对齐输出
- right 表示右对齐输出,右对齐是默认格式
- internal 控制负数的符号位置,它左对齐符号,右对齐值。用空格填满所有中间空间
- setfill 允许指定一个字符代替默认的空格来补白输出
setw 类似 endl,不改变输出流的内部状态。它只决定了 下一个输出的大小
int i = -16;
double d = 3.14159;
// 补白第一列,使用输出中最小 12 个位置
cout << "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
// 补白第一列,左对齐所有列
cout << left
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
cout << right; // 恢复正常右对齐
// 补白第一列,右对齐所有列
cout << right
<< "i: " << setw(12) << i << "next col" << '\n';
<< "d: " << setw(12) << d << "next col" << '\n';
// 补白第一列,但补在域的内部
cout << internal
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
// 补白第一列,用#作为补白字符
cout << setfill('#')
<< "i: " << setw(12) << i << "next col" << '\n'
<< "d: " << setw(12) << d << "next col" << '\n';
<< setfill(' '); // 恢复正常的补白字符

13、定义在 iomanip 中的操纵符(别忘了加头文件)
| 操纵符 | 功能 |
|---|---|
| setfill(ch) | 用 ch 填充空白 |
| setprecision(n) | 将浮点精度设置为 n |
| setw(w) | 读或写值的宽度为 w 个字符 |
| setbase(b) | 将整数输出为 b 进制 |
14、控制输入格式
默认情况下,输入运算符 会忽略空白符(空格符、制表符、换行符和回车符)
操纵符 noskipws 会令输入运算符 读取空白符,而不是跳过它们。为了恢复默认行为,可以使用 skipws 操纵符:
cin >> noskipws; // 设置 cin 读取空白符
while (cin >> ch)
cout << ch;
cin >> skipws; // 将 cin 恢复到默认状态,从而丢弃空白符
17.36
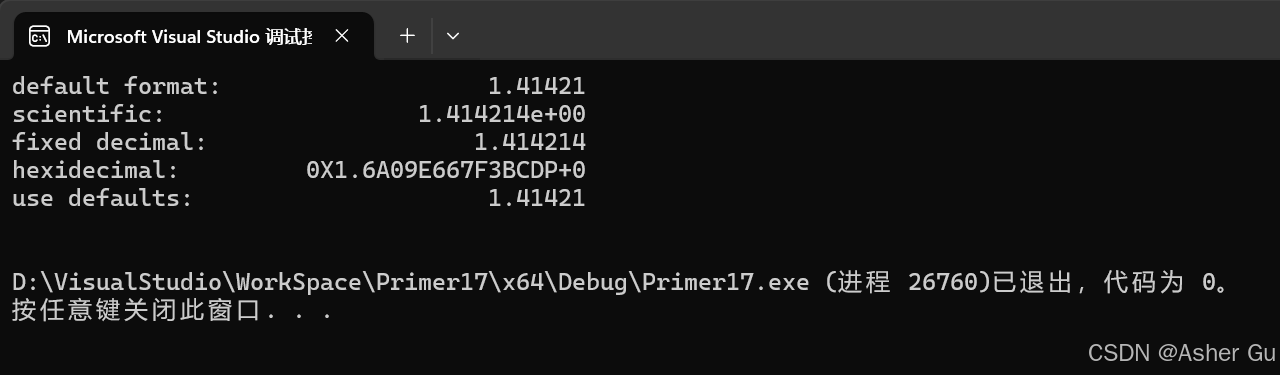
打印2的平方根,但这次打印十六进制数字的大写形式,并使它们排成一列
#include <iostream>
#include <cmath>
#include <iomanip>
using namespace std;
int main()
{
/*
int i = -16;
cout << "i: " << internal << setw(12) << i << '\n';
cout << "i: " << setw(12) << internal << i << '\n'; // 顺序无所谓,只要在i前面就都一样
*/
// 想要排成一列每次输入前都要使用操纵符 left/right + setw(别忘了需要包含头文件 iomanip)
std::cout << std::left << std::setw(16) << "default format: " << std::right << std::setw(25) << sqrt(2.0) << '\n'
<< std::left << std::setw(16) << "scientific: " << std::scientific << std::right << std::setw(25) << sqrt(2.0) << '\n'
<< std::left << std::setw(16) << "fixed decimal: " << std::fixed << std::right << std::setw(25) << sqrt(2.0) << '\n'
<< std::left << std::setw(16) << "hexidecimal: " << std::uppercase << std::hexfloat << std::right << std::setw(25) << sqrt(2.0) << '\n'
<< std::left << std::setw(16) << "use defaults: " << std::defaultfloat << std::right << std::setw(25) << sqrt(2.0)
<< "\n\n";
return 0;
}
5.2 未格式化的输入/输出操作
1、程序只使用过格式化 IO 操作。标准库还提供了一组低层操作,支持未格式化 IO。这些操作允许我们将一个流当作 一个无解释的字节序列来处理
2、单字节操作
数据是以最基本的字节或字符的形式进行操作的,没有针对数据类型的特殊处理
有几个未格式化操作每次一个字节地处理流。它们会读取 而不是忽略空白符。例如,可以使用未格式化 IO 操作 get 和 put 来读取和写入一个字符:
char ch;
while (cin.get(ch))
cout.put(ch);
此程序 保留输入中的空白符,其输出与输入完全相同。它的执行过程 与前一个使用 noskipws 的程序完全相同
单字节低层 IO 操作
| 操作 | 说明 |
|---|---|
| is.get(ch) | 从 istream 读取下一个字节存入字符 ch,并将其从流中删除。返回 is |
| os.put(ch) | 将字符 ch 输出到 ostream os。返回 os |
| is.get() | 将 is 的下一个字节作为 int 返回 |
| is.putback(ch) | 将字符 ch 放回 is。返回 is |
| is.unget() | 将 is 向后移动一个字节。返回 is。用于更复杂的回退,将最后一个从输入流中提取的字符 放回流中 |
| is.peek() | 将下一个字节作为 int 返回,但不从流中删除,通常用于检查下一个字符是什么,不改变输入流的状态 |
3、将字符放回输出流
有时 需要读取一个字符 才能知道还未准备好处理它。在这种情况下,希望将字符放回流中。标准库提供了三种方法返回字符
- peek 返回流中下一个字符的副本,但不会将它从流中删除,peek 返回的值仍然在流中
- unget 使得输入流向后移动,从而最后读取的值又回到流中。即使我们不知道最后从流中读取了什么值,仍然可以调用 unget
- putback 是更特殊版本的 unget:它返回从流中读取的一个值
peek() 用于查看下一个字符而不提取它
#include <iostream>
#include <sstream>
int main() {
std::istringstream is("Hello");
char ch;
// 查看下一个字符
char nextChar = is.peek();
std::cout << "Next character (using peek): " << nextChar << std::endl; // Output: H
// 读取字符并验证 peek 没有提取它
is.get(ch);
std::cout << "First character read: " << ch << std::endl; // Output: H
return 0;
}
unget() 将最后一个读取的字符放回流中
#include <iostream>
#include <sstream>
int main() {
std::istringstream is("Hello");
char ch;
is.get(ch);
std::cout << "First character read: " << ch << std::endl; // Output: H
// 将字符放回流中
is.unget();
// 再次读取字符
is.get(ch);
std::cout << "Character read after unget: " << ch << std::endl; // Output: H
return 0;
}
putback() 将指定的字符放回流中
#include <iostream>
#include <sstream>
int main() {
std::istringstream is("Hello");
char ch;
is.get(ch);
std::cout << "First character read: " << ch << std::endl; // Output: H
// 将一个不同的字符放回流中
is.putback('J');
// 读取被放回的字符
is.get(ch);
std::cout << "Character read after putback: " << ch << std::endl; // Output: J
return 0;
}
在读取下一个值之前,标准库保证 可以退回最多一个值。即,标准库不保证 在中间不进行读取操作的情况下 能连续调用 putback 或 unget
4、从输入操作返回的 int 值
函数 peek 和无参的 get 版本都以 int 类型从输入流返回一个字符
这些函数返回一个 int 的原因是:可以返回文件尾标记。我们使用 char 范围中的每个值 来表示一个真实字符,因此,取值范围中 没有额外的值可以用来表示文件尾
返回 int 的函数 将它们要返回的字符 先转换为 unsigned char,然后再将结果提升到 int。因此,即使字符集中有字符映射到负值,这些操作返回的 int 也是正值,而标准库 使用负值表示文件尾,这样 就可以保证与任何合法字符的值都不同。头文件 <cstudio> 定义了一个名为 EOF 的 const,可以用它来检测输入 get 返回的值是否是文件尾,而不必记住 表示文件尾的实际数值
int ch; // 使用一个 int,而不是一个 char 来保存 get() 的返回值
// 循环读取并输出 输入中的所有数据
while ((ch = cin.get()) != EOF)
cout.put(ch);
一个常见的编程错误是将 get 或 peek 的返回值赋予一个 char 而不是一个 int。这样做是错误的,但编译器却不能发现这个错误
例如,在一个 char 被实现为 unsigned char 的机器上,下面的循环将永远不会停止:
char ch; // 此处使用 char 就是引入灾难!
// 从 cin.get 返回的值被转换为 char,然后与一个 int 比较
while ((ch = cin.get()) != EOF)
cout.put(ch);
当 get 返回 EOF 时, 此值会被转换为一个 unsigned char。转换得到的值与 EOF 的 int 值不相等,因此循环永远也不会停止
在一台 char 被实现为 signed char 的机器上,不能预测循环的行为。当一个操纵符的值 被赋予一个 signed 变量时会发生什么 完全取决于编译器。循环会正常地工作,除非 输入序列中有一个字符与 EOF 值匹配。如果输入包含 ‘\377’ 的字符,循环会提前停止(被错当成文件尾指示符)。因为将 -1 转换为 signed char,就会得到 ‘\377’
当读写有类型的值时,这样错误就不会发生。如果 可以使用标准库提供的类型更加安全、更高层的操作,就应该使用它们
5、多字节操作
一些未格式化 IO 操作一次处理大块数据。如果 速度是要考虑的重点问题的话,这些操作是 很重要的,但类似其他低层操作,这些操作也容易出错。特别是,这些操作要求我们自己分配 并管理用来保存和获取数据的字符数组
速度优势:在需要处理大量数据 并且对性能要求较高的情况下,未格式化 IO 操作 可以提供更快的速度。因为它们省去了数据格式化的步骤,直接 进行字节级别的数据传输,这种方式比逐个处理数据要快得多
模拟了 读取文件数据到缓冲区的过程,但由于未正确管理内存 而导致错误
#include <iostream>
#include <fstream>
int main() {
std::ifstream file("data.bin", std::ios::binary);
if (!file) {
std::cerr << "Error opening file!" << std::endl;
return 1;
}
// 假设我们预计文件只有 100 字节,所以分配了一个 100 字节的缓冲区
char buffer[100];
// 读取文件内容到缓冲区
file.read(buffer, 200); // 错误:我们实际上试图读取 200 字节,但缓冲区只有 100 字节
// 处理数据 (在实际应用中,可能会有进一步的数据处理)
file.close();
return 0;
}
缓冲区分配不足:在这个例子中,buffer 缓冲区被分配了 100 字节的空间,但 file.read(buffer, 200) 试图从文件中读取 200 字节的数据。这会导致缓冲区溢出,即读取的数据超出了分配的内存范围
缓冲区溢出:缓冲区溢出是一种严重的错误,可能导致程序崩溃或不可预见的行为。这是因为程序会试图将数据写入到它不应该访问的内存位置,可能会覆盖其他重要的数据或代码,甚至导致安全漏洞
多字节低层 IO 操作
| 操作 | 说明 |
|---|---|
| is.get(sink, size, delim) | 从 is 中读取最多 size 个字符,并保存至字符数组 sink 中,字符数组的起始地址由 sink 给出。读取过程中直到遇到字符 delim 或读取了 size 个字符或遇到文件尾时停止。如果遇到了 delim,则将其留在输入流中,不读取出来存入 sink |
| is.getline(sink, size, delim) | 与接受三个参数的 get 版本类似,但会读取并丢弃 delim |
| is.read(sink, size) | 读取最多 size 个字节,存入字符数组 sink 中。返回 is |
| is.gcount() | 返回上一个未格式化读取操作从 is 读取的字节数 |
| os.write(source, size) | 将字符数组 source 中的 size 个字节写入 os。返回 os |
| is.ignore(size, delim) | 读取并忽略最多 size 个字符,包括 delim。与其他未格式化函数不同,ignore 有默认参数。size 的默认值为 1,delim 的默认值为文件尾 |
get 和 getline 函数接受相同的参数,它们的行为类似 但不相同。两个函数的差别是 处理分隔符的方式:get 将分隔符留在 istream 中的下一个字符,而 getline 则读取并丢弃分隔符。无论哪个函数 都不会将分隔符保存在 sink 中
6、确定读取了多少个字符:可以调用 gcount 来确定最后一个未格式化输入操作 读取了多少个字符。应该在任何后续未格式化输入操作之前 调用 gcount。特别是,将字符退回流中的单字符操作 也属于 未格式化输入操作。如果在调用 gcount 之前调用了 peek, unget 或 putback,则 gcount 的返回值为 0
gcount() 返回最后一次非格式化输入操作提取的字符数。这通常用于 get() 或 getline() 操作之后
#include <iostream>
#include <sstream>
int main() {
std::istringstream is("Hello world!");
//std::string str;
//is >> str;
//std::cout << str << std::endl; // output: hello
char buffer[10];
// 使用 get 读取字符到 buffer
is.get(buffer, 10);
std::cout << "Buffer: " << buffer << std::endl; // Output: Hello wor
// 输出最后一次读取的字符数
std::streamsize count = is.gcount();
std::cout << "Characters read: " << count << std::endl; // Output: 9,数组最后一个是\0
return 0;
}
5.3 流随机访问
1、流类型 通常都支持 对流中数据的随机访问。可以重定位流,使之跳过一些数据,准库提供了一对函数,来定位(seek)到流给定的位置,以及告诉(tell)我们当前位置
2、随机 IO 本质上是依赖于系统的。为了理解 如何使用这些特性,必须查询系统文档。在大多数系统中,绑定到 cin、cout、cerr 和 clog 的流 不支持随机访问
由于 istream 和 ostream 类型 通常不支持随机访问,所以本节剩余内容 只适用于 fstream 和 sstream 类型
3、seek 和 tell 函数
为了支持随机访问,IO 类型 维护一个标记 来确定下一个读写操作要在哪里进行。它们 还提供了两个函数:一个函数通过将标记 seek 到一个给定位置 来重定位它;另一个函数 tell 我们标记的当前位置。标准库实际上定义了两对 seek 和 tell 函数
一对 用于输入流,另一对 用于输出流。输入和输出版本的差别 在于名字的后缀是 g 还是 p。g 版本表示 正在“获得”(读取 get)数据,而 p 版本表示 正在“放置”(写出 put)数据
| 函数 | 功能 |
|---|---|
| tellg(), tellp() | 返回一个输入流中(tellg) 或 输出流中(tellp) 标记的当前位置 |
| seekg(pos), seekp(pos) | 在一个输入流 或 输出流中 将标记重定位到 给定的绝对地址。pos通常是前一个 tellg 或 tellp 返回的值 |
| seekg(off, from), seekp(off, from) | 在一个输入流或输出流中 将标记定位到 from 之前 或 之后 off 个字符,from 可以是下列值之一: beg,偏移量相对于流开始位置;cur,偏移量相对于流当前位置;end,偏移量相对于流结束位置 |
只能对 istream 和派生自 istream 的类型 ifstream 和 istringstream 使用 g 版本,同样只能对 ostream 和 派生自 ostream 的类型 ofstream 和 ostringstream 使用 p 版本。一个 iostream 、fstream 或 stringstream 既能读又能写关联的流,因此对这些类型的对象 既能使用 g 版本又能使用 p 版本
4、只有一个标记
在一个流中 只维护单一的标记——并不存在独立的读标记 和 写标记
fstream 和 stringstream 类型 可以读写同一个流。在这些类型中,有单一的缓冲区 用于保存读写的数据,同样,标记也只有一个,表示缓冲区中的当前位置。标准库将 g 和 p 版本的读写位置 都映射到这个单一的标记
由于只有单一的标记,因此只要 我们在读写操作间切换,就必须进行 seek 操作来重定位标记
5、重定位标记
seek 函数有两个版本:一个移动到文件中的“绝对”地址:另一个移动到一个给定位置的指定偏移量:
// 将标记移动到一个固定位置
seekg(new_position); // 将读标记移动到指定的 pos_type 位置
seekp(new_position); // 将写标记移动到指定的 pos_type 位置
// 移动到给定起始点之前或之后指定的偏移量处
seekg(offset, from); // 将读标记移动到距 from 偏移量为 offset 的位置
seekp(offset, from); // 将写标记移动到距 from 偏移量为 offset 的位置
参数 new_position 和 offset 的类型分别是 pos_type 和 off_type,这两个类型都是机器相关的,它们定义在 头文件 istream 和 ostream 中。pos_type 表示一个文件位置,而 off_type 表示距当前位置的一个偏移量。一个 off_type 类型的值可以是正的 也可以是负的,即,可以在文件中 向前移动或向后移动
6、访问标记
函数 tellg 和 tellp 返回一个 pos_type 值,表示流的当前位置。tell 函数通常用来记住一个位置,以便稍后再定位回来:
// 记住写位置
ostringstream writeStr; // 输出 stringstream
ostringstream::pos_type mark = writeStr.tellp();
// ...
if (cancelEntry)
// 回到刚才记住的位置
writeStr.seekp(mark);
7、读写同一个文件
要在此文件的末尾写入新的一行,这一行 包含文件中每行的相对起始位置。例如,给定下面文件:
abcd
efg
hi
j
生成如下修改过的文件:
abcd
efg
hi
j
5 9 12 14
不必输出第一行的偏移——它总是从位置 0 开始。还要注意,统计偏移量时 必须包含每行末尾不可见的换行符。最后,注意输出的最后一个数是 输出开始那行的偏移量
可以读取结果文件中 最后一个数,定位到 对应偏移量,即可得到 输出的起始地址
程序 将逐行读取该文件。对每一行,将递增计数器,将刚刚读取的一行的长度 加到计数器上,因此计数器 即为下一行的起始地址:
int main() {
// 以读写方式打开文件,并定位到文件尾
// fstream 是 C++ 标准库中的文件流类,用于处理文件的读写操作。inOut 是这个文件流对象的名字。这个对象将用于打开名为 "copyOut" 的文件,并执行后续的文件操作
// ate 是 fstream 中的一个模式标志。当你使用 ate 标志打开文件时,文件流的指针会在文件打开后立即移动到文件的末尾。尽管流指针开始时位于文件末尾,你仍然可以在文件中间或开头进行读写操作
// in 是另一个模式标志,表示以读的模式打开文件。设置了这个标志后,你可以从文件中读取数据
// out 是用于写的模式标志,表示以写的模式打开文件。设置了这个标志后,你可以向文件中写入数据
// | 是位或运算符,用于将多个标志组合在一起。在这个例子中,fstream::ate | fstream::in | fstream::out 的意思是以读写模式打开文件,并将文件流指针移动到文件末尾
fstream inOut("copyOut",
fstream::ate | fstream::in | fstream::out);
if (!inOut) {
cerr << "Unable to open file!" << endl;
return EXIT_FAILURE;
// EXIT_FAILURE 是 C++ 标准库中定义的一个宏,用于表示程序非正常退出的状态码
}
// inOut 以 ate 模式打开,因此一开始就定位到文件尾
auto end_mark = inOut.tellg(); // 记住原文件尾位置
inOut.seekg(0, fstream::beg); // 重定位到文件开始
size_t cnt = 0; // 字符统计累加器
string line; // 保存输入的每行
// 继续读取的条件:还未遇到错误 且 还在读取原数据
while (inOut && inOut.tellg() != end_mark
&& getline(inOut, line)) { // 且还可获取一行输入
cnt += line.size() + 1; // 加1表示换行符
auto mark = inOut.tellg(); // 记住读取位置
inOut.seekp(0, fstream::end); // 将写标记移动到文件尾
inOut << cnt; // 输出累积的长度
if (mark != end_mark) inOut << " "; // 如果不是最后一行,打印一个分隔符
inOut.seekg(mark); // 写完,恢复读位置
}
inOut.seekp(0, fstream::end); // 定位到文件尾
inOut << "\n\n"; // 在文件尾输出一个换行符
return 0;
}
使用到 in、out 和 ate 模式 打开 fstream。前两个模式 指示文件想要写入一个文件。指定 ate 会将读写定位到文件尾
由于 程序向输入文件写入数据,因此 不能通过文件尾来判断 是否停止读取,而是应该 在到达原数据的末尾时 停止。因此,必须 首先记住原文件尾的位置。由于 是以 ate 模式打开文件的,因此 inOut 已经定位到文件尾。将当前的位置(即,原文件尾)保存在 end_mark 中。记住文件尾位置之后,我们 seek 到距文件起始位置 偏移量为 0 的地方,即,将读标记 重定位到文件起始的位置
while 循环的条件由三部分组成:首先检查 流是否合法;如果合法,通过比较当前读位置(由 tellg 返回)和记录在 end_mark 中的位置 来检查是否读完了原数据;最后,假定前两种检查都已成功,调用 getline 读取输入的下一行,如果 getline 成功,则执行 while 循环体
循环体 首先将当前位置记录在 mark 中。保存当前位置 是为了在输出下一个偏移量后 再退回来。接下来调用 seekp 将写标记 重定位到文件尾。输出计数器的值,然后调用 seekg 回到记录在 mark 中的位置。回退到原位置后,就准备好继续检查循环条件了
小结与术语表
标准库不限制 一个 bitset 的大小必须与整型类型的大小匹配,bitset 的大小可以更大
bitset:标准库类,保存二进制位集合,大小在编译时已知,并提供 检测和设置集合中二进制位的操作
随机数发生器:一个随机数引擎类型 和 一个分布类型的组合
种子:提供给随机数引擎的值,使随机数引擎 移动到 生成的随机数序列中 一个新的点
格式化 IO 是指在输入或输出数据时,数据被以特定的格式进行处理。格式化操作 会根据数据类型 进行相应的转换或表示,确保数据在流中 以人类可读的形式表示或解析。例如,将整数、浮点数、字符串等类型的数据 按指定格式进行输出,或 按特定格式读取输入数据
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » C++ Primer 总结索引 | 第十七章:标准库特殊设施

发表评论 取消回复