两种部署情况:部署在 PyTorch 数据集上,以及部署在本地存储的单个映像上。
目录
定义数据集
详细参照前文【PyTorch】单目标检测项目
import torchvision
import os
import pandas as pd
import matplotlib.pylab as plt
import torch
%matplotlib inline
# 定义一个函数,用于将a列表中的元素除以b列表中的对应元素,返回一个新的列表
def scale_label(a,b):
# 使用zip函数将a和b列表中的元素一一对应
div = [ai/bi for ai,bi in zip(a,b)]
# 返回新的列表
return div
# 定义一个函数,用于将a列表中的元素乘以b列表中的对应元素,返回一个新的列表
def rescale_label(a,b):
# 使用zip函数将a和b列表中的元素一一对应
div = [ai*bi for ai,bi in zip(a,b)]
# 返回新的列表
return div
import torchvision.transforms.functional as TF
# 定义一个函数,用于调整图像和标签的大小
def resize_img_label(image,label=(0.,0.),target_size=(256,256)):
# 获取原始图像的宽度和高度
w_orig,h_orig = image.size
# 获取目标图像的宽度和高度
w_target,h_target = target_size
# 获取标签的坐标
cx, cy= label
# 调整图像大小
image_new = TF.resize(image,target_size)
# 调整标签大小
label_new= cx/w_orig*w_target, cy/h_orig*h_target
# 定义一个transformer函数,用于对图像和标签进行变换
def transformer(image, label, params):
# 调用resize_img_label函数,对图像和标签进行尺寸调整
image,label=resize_img_label(image,label,params["target_size"])
# 如果params中scale_label参数为True,则调用scale_label函数,对标签进行缩放
if params["scale_label"]:
label=scale_label(label,params["target_size"])
# 将图像转换为张量
image=TF.to_tensor(image)
# 返回变换后的图像和标签
return image, label
from torch.utils.data import Dataset
from PIL import Image
class AMD_dataset(Dataset):
def __init__(self, path2data, transform, trans_params):
# 初始化函数,传入数据路径、转换函数和转换参数
pass
def __len__(self):
# 返回数据集的大小
return len(self.labels)
def __getitem__(self, idx):
# 根据索引获取数据集中的一个样本
pass
# 返回调整后的图像和标签
return image_new,label_new
def __init__(self, path2data, transform, trans_params):
# 获取标签文件路径
path2labels=os.path.join(path2data,"Training400","Fovea_location.xlsx")
# 读取标签文件
labels_df=pd.read_excel(path2labels,engine='openpyxl',index_col="ID")
# 获取标签数据
self.labels = labels_df[["Fovea_X","Fovea_Y"]].values
# 获取图片名称
self.imgName=labels_df["imgName"]
# 获取图片ID
self.ids=labels_df.index
# 获取图片全路径
self.fullPath2img=[0]*len(self.ids)
for id_ in self.ids:
# 根据图片名称判断图片类型
if self.imgName[id_][0]=="A":
prefix="AMD"
else:
prefix="Non-AMD"
# 获取图片全路径
self.fullPath2img[id_-1]=os.path.join(path2data,"Training400",prefix,self.imgName[id_])
# 获取数据转换函数
self.transform = transform
# 获取数据转换参数
self.trans_params=trans_params
def __getitem__(self, idx):
# 打开指定索引的图像
image = Image.open(self.fullPath2img[idx])
# 获取指定索引的标签
label= self.labels[idx]
# 对图像和标签进行变换
image,label = self.transform(image,label,self.trans_params)
# 返回变换后的图像和标签
return image, label
#重写
AMD_dataset.__init__=__init__
AMD_dataset.__getitem__=__getitem__
path2data="./data/"
#验证参数
trans_params_val={
"target_size" : (256, 256),
"p_hflip" : 0.0,
"p_vflip" : 0.0,
"p_shift" : 0.0,
"p_brightness": 0.0,
"p_contrast": 0.0,
"p_gamma": 0.0,
"gamma": 0.0,
"scale_label": True,
}
amd_ds2=AMD_dataset(path2data,transformer,trans_params_val)
from sklearn.model_selection import ShuffleSplit
sss = ShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
indices=range(len(amd_ds2))
for train_index, val_index in sss.split(indices):
print(len(train_index))
print("-"*10)
print(len(val_index))
from torch.utils.data import Subset
# 创建一个Subset对象,将amd_ds2数据集按照val_index索引进行划分,得到验证集val_ds
val_ds=Subset(amd_ds2,val_index)
from torch.utils.data import DataLoader
# 创建一个DataLoader对象,用于加载验证集数据
val_dl = DataLoader(val_ds, batch_size=16, shuffle=False)
搭建模型
详细参照前文【PyTorch】单目标检测项目
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self, params):
super(Net, self).__init__()
def forward(self, x):
return x
def __init__(self, params):
super(Net, self).__init__()
C_in,H_in,W_in=params["input_shape"]
init_f=params["initial_filters"]
num_outputs=params["num_outputs"]
self.conv1 = nn.Conv2d(C_in, init_f, kernel_size=3,stride=2,padding=1)
self.conv2 = nn.Conv2d(init_f+C_in, 2*init_f, kernel_size=3,stride=1,padding=1)
self.conv3 = nn.Conv2d(3*init_f+C_in, 4*init_f, kernel_size=3,padding=1)
self.conv4 = nn.Conv2d(7*init_f+C_in, 8*init_f, kernel_size=3,padding=1)
self.conv5 = nn.Conv2d(15*init_f+C_in, 16*init_f, kernel_size=3,padding=1)
self.fc1 = nn.Linear(16*init_f, num_outputs)
def forward(self, x):
identity=F.avg_pool2d(x,4,4)
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = torch.cat((x, identity), dim=1)
identity=F.avg_pool2d(x,2,2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = torch.cat((x, identity), dim=1)
identity=F.avg_pool2d(x,2,2)
x = F.relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = torch.cat((x, identity), dim=1)
identity=F.avg_pool2d(x,2,2)
x = F.relu(self.conv4(x))
x = F.max_pool2d(x, 2, 2)
x = torch.cat((x, identity), dim=1)
x = F.relu(self.conv5(x))
x=F.adaptive_avg_pool2d(x,1)
x = x.reshape(x.size(0), -1)
x = self.fc1(x)
return x
Net.__init__=__init__
Net.forward=forward
params_model={
"input_shape": (3,256,256),
"initial_filters": 16,
"num_outputs": 2,
}
model = Net(params_model)
model.eval()
if torch.cuda.is_available():
device = torch.device("cuda")
model=model.to(device)
部署模型
path2weights="./models/weights.pt"
# 加载模型权重
model.load_state_dict(torch.load(path2weights))
# 定义设备为GPU
device = torch.device("cuda")
# 定义一个函数,用于计算模型在数据集上的损失和指标
def loss_epoch(model,loss_func,dataset_dl,sanity_check=False,opt=None):
# 初始化运行损失和运行指标
running_loss=0.0
running_metric=0.0
# 获取数据集的长度
len_data=len(dataset_dl.dataset)
# 遍历数据集
for xb, yb in dataset_dl:
# 将标签堆叠成一维张量
yb=torch.stack(yb,1)
# 将标签转换为浮点型,并移动到GPU上
yb=yb.type(torch.float32).to(device)
# 将输入数据移动到GPU上,并获取模型输出
output=model(xb.to(device))
# 计算当前批次的损失和指标
loss_b,metric_b=loss_batch(loss_func, output, yb, opt)
# 累加损失
running_loss+=loss_b
# 如果指标不为空,则累加指标
if metric_b is not None:
running_metric+=metric_b
# 如果是进行sanity check,则只计算一个批次
if sanity_check is True:
break
# 计算平均损失
loss=running_loss/float(len_data)
# 计算平均指标
metric=running_metric/float(len_data)
# 返回平均损失和平均指标
return loss, metric
# 将中心点坐标和宽高转换为边界框坐标
def cxcy2bbox(cxcy,w=50./256,h=50./256):
# 创建一个与cxcy形状相同的张量,每个元素都为w
w_tensor=torch.ones(cxcy.shape[0],1,device=cxcy.device)*w
# 创建一个与cxcy形状相同的张量,每个元素都为h
h_tensor=torch.ones(cxcy.shape[0],1,device=cxcy.device)*h
# 将cxcy的第一列提取出来,并增加一个维度
cx=cxcy[:,0].unsqueeze(1)
# 将cxcy的第二列提取出来,并增加一个维度
cy=cxcy[:,1].unsqueeze(1)
# 将cx、cy、w_tensor、h_tensor按列拼接起来
boxes=torch.cat((cx,cy, w_tensor, h_tensor), -1)
# 将boxes的第一列和第二列分别减去w_tensor和h_tensor的一半,然后将结果按行拼接起来
return torch.cat((boxes[:, :2] - boxes[:, 2:]/2,boxes[:, :2] + boxes[:, 2:]/2), 1)
# 定义一个函数metrics_batch,用于计算输出和目标之间的交并比
def metrics_batch(output, target):
# 将输出和目标转换为边界框格式
output=cxcy2bbox(output)
target=cxcy2bbox(target)
# 计算输出和目标之间的交并比
iou=torchvision.ops.box_iou(output, target)
# 返回交并比的和
return torch.diagonal(iou, 0).sum().item()
# 定义一个函数,用于计算损失函数、输出和目标之间的损失值
def loss_batch(loss_func, output, target, opt=None):
# 计算输出和目标之间的损失值
loss = loss_func(output, target)
# 计算输出和目标之间的度量值
metric_b = metrics_batch(output,target)
# 如果opt不为空,则执行反向传播和优化
if opt is not None:
opt.zero_grad()
loss.backward()
opt.step()
# 返回损失值和度量值
return loss.item(), metric_b
# 定义损失函数,使用SmoothL1Loss,reduction参数设置为sum
loss_func=nn.SmoothL1Loss(reduction="sum")
# 在不计算梯度的情况下,计算模型在验证集上的损失和指标
with torch.no_grad():
loss,metric=loss_epoch(model,loss_func,val_dl)
# 打印损失和指标
print(loss,metric)
from PIL import ImageDraw
import numpy as np
import torchvision.transforms.functional as tv_F
np.random.seed(0)
import matplotlib.pylab as plt
%matplotlib inline
def show_tensor_2labels(img,label1,label2,w_h=(50,50)):
# 将label1和label2按照img的shape进行缩放
label1=rescale_label(label1,img.shape[1:])
label2=rescale_label(label2,img.shape[1:])
# 将img转换为PIL图像
img=tv_F.to_pil_image(img)
# 获取w_h的宽度和高度
w,h=w_h
# 获取label1的坐标
cx,cy=label1
# 在img上绘制一个绿色的矩形
draw = ImageDraw.Draw(img)
draw.rectangle(((cx-w/2, cy-h/2), (cx+w/2, cy+h/2)),outline="green",width=2)
# 获取label2的坐标
cx,cy=label2
# 在img上绘制一个红色的矩形
draw.rectangle(((cx-w/2, cy-h/2), (cx+w/2, cy+h/2)),outline="red",width=2)
# 显示img
plt.imshow(np.asarray(img))
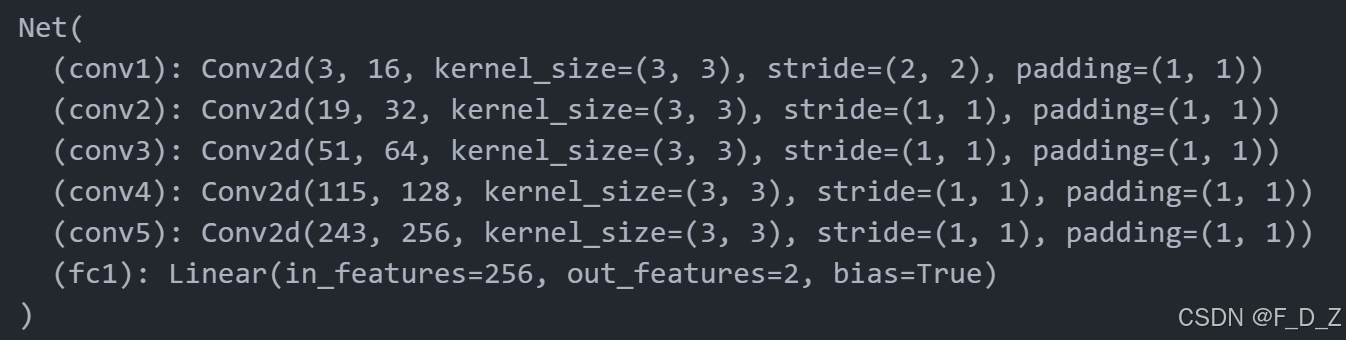
# 生成一个长度为10的随机整数数组,数组中的元素为0到len(val_ds)之间的随机整数
rndInds=np.random.randint(len(val_ds),size=10)
# 打印生成的随机整数数组
print(rndInds)
# 设置图像大小
plt.rcParams['figure.figsize'] = (15, 10)
# 调整子图之间的间距
plt.subplots_adjust(wspace=0.0, hspace=0.15)
# 遍历随机索引
for i,rndi in enumerate(rndInds):
# 获取图像和标签
img,label=val_ds[rndi]
# 获取图像的宽度和高度
h,w=img.shape[1:]
# 不计算梯度
with torch.no_grad():
# 获取模型预测的标签
label_pred=model(img.unsqueeze(0).to(device))[0].cpu()
# 绘制子图
plt.subplot(2,3,i+1)
# 显示图像和标签
show_tensor_2labels(img,label,label_pred)
# 将标签转换为边界框
label_bb=cxcy2bbox(torch.tensor(label).unsqueeze(0))
# 将模型预测的标签转换为边界框
label_pred_bb=cxcy2bbox(label_pred.unsqueeze(0))
# 计算IOU
iou=torchvision.ops.box_iou(label_bb, label_pred_bb)
# 设置标题
plt.title("%.2f" %iou.item())
# 如果索引大于4,则跳出循环
if i>4:
break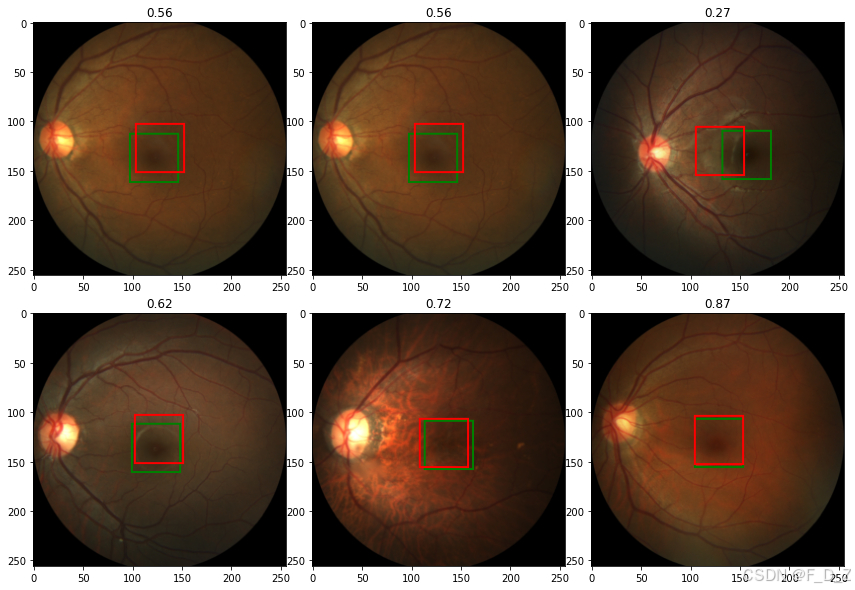
# 定义一个函数,用于加载图片和标签
def load_img_label(labels_df,id_):
# 获取图片名称
imgName=labels_df["imgName"]
# 判断图片名称是否以"A"开头
if imgName[id_][0]=="A":
# 如果是,则前缀为"AMD"
prefix="AMD"
else:
# 否则,前缀为"Non-AMD"
prefix="Non-AMD"
# 拼接图片路径
fullPath2img=os.path.join(path2data,"Training400",prefix,imgName[id_])
# 打开图片
img = Image.open(fullPath2img)
# 获取图片中心点坐标
x=labels_df["Fovea_X"][id_]
y=labels_df["Fovea_Y"][id_]
# 返回图片和中心点坐标
label=(x,y)
return img,label
# 定义标签文件路径
path2labels=os.path.join(path2data,"Training400","Fovea_location.xlsx")
# 读取标签文件,使用openpyxl引擎,将ID列作为索引
labels_df=pd.read_excel(path2labels,engine='openpyxl',index_col="ID")
# 加载图片和标签,使用标签文件中的第一行数据
img,label=load_img_label(labels_df,1)
# 打印图片和标签的大小
print(img.size, label)
# 调整图片和标签的大小为256x256
img,label=resize_img_label(img,label,target_size=(256,256))
# 打印调整后的图片和标签的大小
print(img.size, label)
# 将图片转换为张量
img=TF.to_tensor(img)
# 将标签缩放到256x256
label=scale_label(label,(256,256))
# 打印转换后的图片的形状
print(img.shape)
# 在不计算梯度的情况下,使用模型对图片进行预测
with torch.no_grad():
label_pred=model(img.unsqueeze(0).to(device))[0].cpu()
# 显示图片和标签以及预测结果
show_tensor_2labels(img,label,label_pred)
import time
# 定义一个空列表,用于存储每次推理的时间
elapsed_times=[]
# 不计算梯度,进行推理
with torch.no_grad():
# 循环100次
for k in range(100):
# 记录开始时间
start=time.time()
# 对输入图片进行推理,并获取预测结果
label_pred=model(img.unsqueeze(0).to(device))[0].cpu()
# 计算推理时间
elapsed=time.time()-start
# 将每次推理的时间添加到列表中
elapsed_times.append(elapsed)
# 打印每次推理的平均时间
print("inference time per image: %.4f s" %np.mean(elapsed_times))

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【PyTorch】单目标检测项目部署

发表评论 取消回复