文本和数据挖掘(text and data mining, TDM)使用计算工具和技术来分析大型文本数据集,从学术论文、期刊和其他科学出版物中的大量科学数据里提取有价值的见解,旨在识别通过传统人工分析难以或无法发现的模式、关联和趋势,近年来已逐渐发展成为一种强大的工具。
如何将这一强大的工具引入到企业的研发架构中,让研究人员无需为了获取有用信息而研读数百篇文章?
信息资深人士Mary Ellen Bates对话TDM专家——施普林格·自然数据解决方案及战略主管Prathik Roy,分享了他对TDM领域的独到见解,带领我们深入探究这一领域。
Roy在为企业客户开发数据传递机制、借助TDM驱动变革性发现等方面拥有丰富的经验,在访谈中他阐明了TDM的潜力,相关工具对于研究人员的重要性所在,并分享了有关知识产权和授权许可考量的宝贵知识以及探讨了企业与学术TDM项目之间的协同效应。

Q:什么是TDM?为何它对研究人员如此重要?
A:TDM是指利用机器来阅读文本(如科学出版物和文档)、提取信息,并将其用于机器学习和人工智能。TDM对研究人员极为重要,因为它开辟了药物发现、老药新用,以及用于命名实体识别的信息增强等多种用例。此外,它使得不同行业的公司都能利用科技文献中的宝贵见解,以改善运营并取得变革性发现。
Q:这些年来TDM是如何发展的?未来又会走向何方?
A:过去5年来,TDM已经实现了从“人类辅助AI”到“AI辅助人类”的转变,自动化比重日益加深。这一转变带来了更高的F1分数,表明机器学习模型的准确率、精确率和召回率都有所提升。另外,TDM也从利用spaCy一类的开源模型,发展到利用现存的内容集来创建新内容。展望未来,许多中小型公司有望能为更大的企业填补TDM分析的空缺,优化运营并驱动创新。
Q:在TDM的实施过程中,尤其是在制造业、化工和半导体等行业中存在哪些挑战?
A:TDM的实施需要大量资源,在机器学习和算力方面尤其如此。不过,AI平台训练框架(如谷歌的BERT)有助于解决部分问题。尽管基于transformer的模型产出的结果更优,但人工智能幻觉等挑战依然存在,而且对传统机器学习模型的依赖度仍然很高。
Q:关于TDM中的知识产权和授权许可,有哪些需要考虑的关键因素?
A:虽然底层数据集属于许可供应商,但通过TDM分析所产生的知识产权属于客户。研究人员必须咨询其法律团队,充分理解其中的法律问题和过程。关键在于遵守许可协议,合理使用数据集。倘若许可中断,研究人员则需清除或停用部分数据,以遵守条款和条件。
Q:企业界和学术界对TDM的使用有何不同?
A:在企业中,TDM项目都是围绕着特定目的(如药物发现)而搭建的。而学术研究人员旨在开发出适用于多种用例的通用模型。然而,企业界与学术界的合作和资助安排已模糊了这一界线,使双方都能受益于行业洞察与宝贵的研究成果。
Q:研究人员在着手一个TDM项目时,应该采取什么步骤?
A:研究人员应当确定他们的需求和所需要的具体内容。研究人员有必要联系出版机构,了解访问选项,例如开放获取内容API或数据馈送(data feeds)。然而,并非所有出版机构都提供这些选项,因此研究人员应当阅读并理解条款、条件、许可,以及与数据相关的隐私政策。他们应当知晓版权和许可限制,对于订阅式或付费内容尤其如此。建议研究人员向图书馆员或信息专家寻求帮助,以获得遵守版权限制方面的指导,因为团队合作对于实现TDM项目的产出和社会效益最大化至关重要。
Q:拥抱知识的未来:释放文本和数据挖掘的力量
A:不可否认的是,TDM拥有变革性力量,能让研究人员和企业在广袤的知识海洋中发现隐藏的瑰宝。TDM实践从“人类辅助AI”到“AI辅助人类”的发展展现了其不断成长和创新的潜力。尽管未来可能会出现诸多挑战,但研究人员、行业内专业人士,以及数据科学家的共同努力必将为更大的进步铺平道路。
不论您是瞄准具体结果的产业界专业人士,还是寻求通用模型的学术人员,TDM都是一种不受限制的强大工具。学术界和产业界通力合作,发掘文本和数据的巨大潜力,就能推动知识进步和社会改善。
Prathik Roy博士简介
Prathik Roy博士是一位经验丰富的专业人士,对数据驱动的解决方案和变革性技术充满热情。作为施普林格·自然数据解决方案及战略主管,他长期活跃在尖端传递机制(包括API和数据馈送)开发的最前沿,以满足企业的多样化需求,促进突破性发现。
Prathik Roy博士拥有强大的TDM专业背景,在驱动各个行业——尤其是制药和生物技术行业创新的过程中发挥着重要作用。他已经借助TDM技术领导了多个项目,涉及药物发现、老药新用以及用于命名实体识别的信息增强。Prathik Roy博士凭借其专业知识和全身心投入,成为了TDM领域中一股持续存在的驱动力,激励着研究人员和行业专业人士踏上知识发现的变革之旅。
文本和数据挖掘(TDM)
文本和数据挖掘(Text and Data Mining, TDM)是指对大量的文本或数据资源进行自动选择和分析的过程,它能产出研究和研究项目所需的有用信息。开展TDM的目的包括检索内容、寻找模式、发现关系、语义分析和了解内容与概念和需求之间的关联等等。
TDM的创新之处在于,研究人员就算不知道具体要问什么,也能对数据集进行分析。如今,AI已基本成熟——它不单能呈递信息,还能提供建议、做出决策并生成内容。
施普林格·自然开发了各种工具,旨在方便研究人员对我们的出版物进行文本和数据挖掘。
最重要的TDM工具包括:
· Meta API:在线文档的新版元数据(带有额外字段)以及源内容链接
· 用于开放获取内容的全文API:施普林格·自然开放获取XML格式的全文内容(如有)
· 用于付费订阅内容的全文API:施普林格·自然所有XML格式的全文内容(如有)
施普林格·自然TDM的四种使用场景示例:
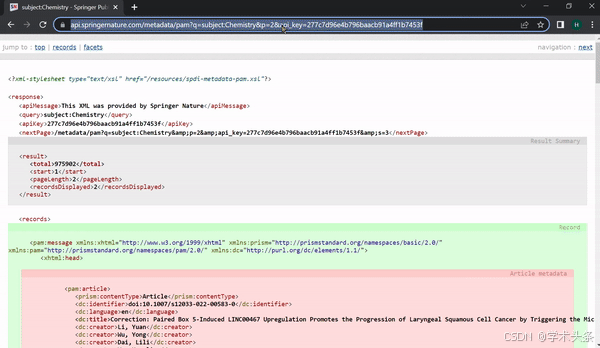
-
接入API和密钥(api_key=**********)在Metadata中搜索化学(Chemistry)相关数据;
-
搜索关键词“患者(patients)”相关数据;
-
搜索1993年相关数据;
-
展示pam格式数据和json格式数据(我们同时支持jat、xml等多种数据格式输出)
版权声明:
本文由施普林格∙自然上海办公室负责整理翻译,中文内容仅供参考。欢迎转发分享。
© 2024 Springer Nature Limited. All Rights Reserved
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » AI时代,让文献主动找上门——揭开文本和数据挖掘的变革性力量

发表评论 取消回复