文章目录
前言
本项目是解读开源github的代码,该项目基于Meta最新发布的新一代开源大模型Llama-3开发,是Chinese-LLaMA-Alpaca开源大模型相关系列项目(一期、二期)的第三期。而本项目开源了中文Llama-3基座模型和中文Llama-3-Instruct指令精调大模型。这些模型在原版Llama-3的基础上使用了大规模中文数据进行增量预训练,并且使用精选指令数据进行精调,进一步提升了中文基础语义和指令理解能力,相比二代相关模型获得了显著性能提升。因此,我是基于该项目解读训练与推理相关原理与内容,并以代码形式带领读者一步一步解读,理解其大语言模型运行机理。而该博客首先给出如何运行文件配置与需要使用的相关知识。
我也写了huggingface的generate函数可参考博客:这里
我也写了llama3的推理博客与准备写一个训练博客。
一、launch.json文件配置
我们更希望使用vscode编译器来运行llama3代码,以便可以更好地调试我们的代码。可以参考博客这里。这里,我直接给出launch.json配置文件,如下:
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "infer",
"type": "python",
"request": "launch",
"python": "/home/miniconda3/envs/llama3/bin/python", // 指定python解释器
"program": "/home/language_model/Chinese-LLaMA-Alpaca-3-main/scripts/inference/inference_hf.py",
"console": "integratedTerminal",
"justMyCode": false,
"args": [
//"--include","localhost:0,1",
//"--hostfile","./hostfile.txt",
//"${file}",
"--base_model","/home/language_model/llama3_8b_weight",
"--tokenizer_path","/home/language_model/llama3_8b_weight",
"--gpus","1"
],
// "env": {
// "CUDA_VISIBLE_DEVICES": "1"
// },
},
{
"name": "run_pt",
"type": "python",
"request": "launch",
// "python": "/home/miniconda3/envs/llama3/bin/python", // 指定python解释器
"program": "/home/miniconda3/envs/llama3/bin/torchrun",
"console": "integratedTerminal",
"justMyCode": false,
"args": [
// "--include","localhost:0",
"--nnodes", "1",
"--nproc_per_node", "1",
"/home/language_model/Chinese-LLaMA-Alpaca-3-main/scripts/training/run_clm_pt_with_peft.py",
"--model_name_or_path","/home/language_model/llama3_8b_weight",
"--tokenizer_name_or_path","/home/language_model/llama3_8b_weight",
"--dataset_dir","/home/language_model/Chinese-LLaMA-Alpaca-3-main/data",
"--data_cache_dir","temp_data_cache_dir",
"--validation_split_percentage","0.001",
"--per_device_train_batch_size","1",
"--do_train",
"--low_cpu_mem_usage",
// "--seed"," $RANDOM",
"--bf16",
"--num_train_epochs","1",
"--lr_scheduler_type", "cosine",
"--learning_rate","1e-4",
"--warmup_ratio","0.05",
"--weight_decay","0.01",
"--logging_strategy","steps",
"--logging_steps","10",
"--save_strategy","steps",
"--save_total_limit","3",
"--save_steps","200",
"--gradient_accumulation_steps","8",
"--preprocessing_num_workers","8",
"--block_size","1024",
"--output_dir","output_dir",
"--overwrite_output_dir",
"--ddp_timeout","30000",
"--logging_first_step","True",
"--lora_rank","64",
"--lora_alpha","128",
"--trainable","q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj",
"--lora_dropout","0.05",
"--modules_to_save","embed_tokens,lm_head",
"--torch_dtype","bfloat16",
"--load_in_kbits","16",
"--ddp_find_unused_parameters","False",
],
"env": {
"CUDA_VISIBLE_DEVICES": "1"
},
},
]
}
二、相关知识内容
我后面解读llama3会遇到相关基础,我这先给出来。
1、理解softmax内容
llama3使用到该函数示列:
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
llama3在输出部分需要用到,其公式如下:
曲线图如下:
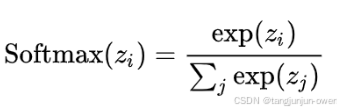
2、torch相关函数
nn.Embedding函数
llama3使用示列:
if inputs_embeds is None:
inputs_embeds = self.embed_tokens(input_ids)
而self.embed_tokens函数是:
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
nn.Embedding是用于实现词嵌入(Word Embedding)的模块,通常用于将离散的词语或token映射为密集的实数向量。在给定参数的情况下,nn.Embedding的语法通常是 nn.Embedding(num_embeddings, embedding_dim, padding_idx),其中各参数含义如下:
num_embeddings:表示词汇表的大小,即不同词语或token的总数。
embedding_dim:表示词嵌入向量的维度,即每个词语或token被映射为一个多少维度的实数向量。
padding_idx:表示用于填充的token在词汇表中的索引,通常用于在序列处理中指定填充token的词嵌入为零向量。
因此,nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)这段代码表示创建了一个词嵌入层,其中:
config.vocab_size表示词汇表的大小;
config.hidden_size表示词嵌入向量的维度;
self.padding_idx表示填充token在词汇表中的索引,用于指定填充token的词嵌入为零向量。
torch.nn.functional.scaled_dot_product_attention
llama3使用示列:
# In case we are not compiling, we may set `causal_mask` to None, which is required to dispatch to SDPA's Flash Attention 2 backend, rather
# relying on the `is_causal` argument.
attn_output = torch.nn.functional.scaled_dot_product_attention(
query_states,
key_states,
value_states,
attn_mask=causal_mask,
dropout_p=self.attention_dropout if self.training else 0.0,
is_causal=causal_mask is None and q_len > 1,
)
基本就是transformer的一个注意力机制结构了,我们解释如下。
在这段代码中,torch.nn.functional.scaled_dot_product_attention函数被用于实现自注意力机制(self-attention)的计算,这在大语言模型中是一个重要的组成部分。下面是对这段代码的解释:
query_states、key_states和value_states分别代表查询(query)、键(key)和值(value)的状态张量,它们是自注意力机制中的输入。
attn_mask=causal_mask用于指定注意力机制中的掩码,比如在语言模型中常用的掩码方式是掩盖未来时刻的信息,以确保模型在预测某个时刻的单词时只能依赖于当前时刻及之前的信息。
dropout_p=self.attention_dropout if self.training else 0.0表示在训练过程中使用self.attention_dropout概率的dropout,而在评估过程中则不使用dropout。
is_causal=causal_mask is None and q_len > 1用于指定是否使用因果(causal)注意力机制,即只依赖于当前及之前时刻的信息,通常在序列生成任务中使用。
该函数的作用是计算自注意力机制的输出,通过对查询、键和值进行加权求和来产生最终的注意力输出。自注意力机制在大语言模型中被广泛应用,能够有效地捕捉输入序列中不同位置之间的依赖关系,并提高模型在处理长距离依赖时的性能。
而该函数参数如下:
q: 查询向量(query),形状为(batch_size, num_queries, embed_dim)。
k: 键向量(key),形状为(batch_size, num_keys, embed_dim)。
v: 值向量(value),形状为(batch_size, num_keys, value_dim)。
mask: 一个可选的mask张量,用于指定哪些位置的注意力权重应该被屏蔽(masked)。
dropout: 一个可选的dropout概率,用于在计算注意力权重时进行随机失活以防止过拟合。
该函数会计算输入query和key之间的点积,然后进行缩放处理以控制梯度大小,接着应用softmax函数得到注意力权重,最后将值向量v按照这些权重进行加权求和,得到最终的输出。
总之,torch.nn.functional.scaled_dot_product_attention函数是一个用于实现缩放点积注意力机制的函数。在深度学习中,注意力机制被广泛应用于各种任务,如机器翻译、语音识别等。
torch.multinomial函数
llama3使用该函数示列:
# sample
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
torch.multinomial(probs, num_samples=1): 这部分代码使用torch.multinomial函数根据概率分布probs从中抽取一个样本,返回的结果是一个包含抽样索引的张量。
这行代码在语言模型中通常用于生成下一个词的预测。让我来解释一下这行代码的含义:
probs: 这是一个包含词汇表中每个单词概率的张量,表示语言模型在给定上下文后,预测下一个单词为每个单词的概率分布。
num_samples=1: 这里指定了要从概率分布中抽取的样本数量,这里是1,即从概率分布中抽取一个样本。
.squeeze(1): 这一步是将张量的维度为1的维度压缩掉,使得最终得到的next_tokens张量是一维的,其中包含了模型预测的下一个单词的索引。
总的来说,这行代码的含义是在给定当前上下文后,从模型预测的下一个单词概率分布中抽取一个样本,即生成下一个预测单词的索引。
特别说明:概率越大抽样机会越大!
三、llama3相关内容说明
1、llama3的权重文件夹
下载地址:
https://huggingface.co/hfl/llama-3-chinese-8b-instruct-v3/tree/main
2、模型文件对比
左边是官方meta的llama3而右边是我解读的模型,存在不对应,但llama3原理一样。之所以没有使用左边源码解读,是其权重不太好获取。而我们只需理解其原理,因此就用了右边的中文llama3模型。
四、huggingface相关内容
1、huggingface的generate方法
该方法是huggingface集成的推理方法,该方法实现推理,而在llama3被使用源码如下:
generation_output = model.generate(
input_ids = inputs["input_ids"].to(device),
attention_mask = inputs['attention_mask'].to(device),
eos_token_id=terminators,
pad_token_id=tokenizer.eos_token_id,
generation_config = generation_config
)
generate方法说明:
生成具有语言建模头的模型的token id序列。
大多数控制生成的参数都在generation_config中设置,如果未传递,将设置为模型的默认生成配置。您可以通过传递相应参数给generate()来覆盖任何generation_config,例如.generate(inputs, num_beams=4, do_sample=True)。
有关生成策略和代码示例的概述,请查看以下指南。
参数:
-
inputs(torch.Tensor,根据模态性质而变的形状,可选):用作生成提示或作为输入传递给编码器的序列。如果为
None,则该方法将使用bos_token_id和批量大小为1进行初始化。
对于仅解码器模型,inputs应该是input_ids格式。
对于编码器-解码器模型,inputs可以表示任何input_ids、input_values、input_features或pixel_values。 -
generation_config(~generation.GenerationConfig,可选):要用作生成调用的基本参数化的生成配置。传递给generate的
**kwargs与generation_config的属性匹配将对其进行覆盖。如果未提供generation_config,将使用默认值,其加载优先级如下:
1)从generation_config.json模型文件中,如果存在;
2)从模型配置中。请注意,未指定的参数将继承[~generation.GenerationConfig]的默认值,应检查其文档以参数化生成。 -
logits_processor(LogitsProcessorList,可选):自定义logits处理器,用于补充从参数和生成配置构建的默认logits处理器。如果传递了已使用参数或生成配置创建的logit处理器,则会引发错误。此功能适用于高级用户。
-
stopping_criteria(StoppingCriteriaList,可选):自定义停止标准,补充了从参数和生成配置构建的默认停止标准。如果传递了已使用参数或生成配置创建的停止标准,则会引发错误。如果您的停止标准取决于输入的
scores,请确保将return_dict_in_generate=True, output_scores=True传递给generate。此功能适用于高级用户。 -
prefix_allowed_tokens_fn(Callable[[int, torch.Tensor], List[int]],可选):如果提供,此函数会限制每一步的beam搜索仅允许的token。如果未提供,则不应用任何约束。此函数接受2个参数:批量ID
batch_id和input_ids。它必须返回一个列表,其中包含下一代步所允许的token,条件是批量IDbatch_id和先前生成的tokeninputs_ids。此参数对于受前缀约束的生成很有用,如Autoregressive Entity Retrieval中所述。 -
synced_gpus(bool,可选):是否继续运行while循环直到max_length。除非被覆盖,否则在DeepSpeed ZeRO Stage 3多GPU环境中将设置为
True,以避免一个GPU在其他GPU之前完成生成时挂起。否则将设置为False。 -
assistant_model(PreTrainedModel,可选):可用于加速生成的助理模型。助理模型必须具有完全相同的分词器。当使用助理模型进行候选token预测比使用调用generate的模型运行生成要快得多时,可以实现加速。因此,助理模型应该要小得多。
-
streamer(BaseStreamer,可选):将用于流式传输生成序列的Streamer对象。生成的token通过
streamer.put(token_ids)传递,并且streamer负责任何进一步处理。 -
negative_prompt_ids(torch.LongTensor,形状为
(batch_size, sequence_length),可选):一些处理器(如CFG)需要的负向提示。批量大小必须与输入批量大小匹配。这是一个实验性功能,在未来版本中可能会发生破坏性API更改。 -
negative_prompt_attention_mask(torch.LongTensor,形状为
(batch_size, sequence_length),可选):用于negative_prompt_ids的Attention_mask。 -
kwargs(Dict[str, Any],可选):对
generation_config进行临时参数化和/或将转发给模型的forward函数的其他特定于模型的kwargs。如果模型是编码器-解码器模型,则不应该加前缀编码器特定kwargs,并且应该使用*decoder_*前缀进行解码器特定kwargs。
返回:
- [
~utils.ModelOutput]或torch.LongTensor:[~utils.ModelOutput](如果return_dict_in_generate=True或当config.return_dict_in_generate=True)或一个torch.LongTensor。
如果模型不是编码器-解码器模型(model.config.is_encoder_decoder=False),可能的[~utils.ModelOutput]类型有:
- [
~generation.GenerateDecoderOnlyOutput], - [
~generation.GenerateBeamDecoderOnlyOutput]。
如果模型是编码器-解码器模型(model.config.is_encoder_decoder=True),可能的[~utils.ModelOutput]类型有:
- [
~generation.GenerateEncoderDecoderOutput], - [
~generation.GenerateBeamEncoderDecoderOutput]
2、tokenizer.decode(s, skip_special_tokens=True)方法
llama在解码需用到tokenizer.decode(s, skip_special_tokens=True),源码如下:
s = generation_output[0]
output = tokenizer.decode(s,skip_special_tokens=True)
我将以llama3使用格式来解释,如下:
tokenizer.decode(s, skip_special_tokens=True) 函数是 Hugging Face 库中 Tokenizer 类的一个方法,用于将模型生成的 token 序列 s 解码为人类可读的文本。
参数解释:
s: 表示待解码的 token 序列,通常是一个整数列表或张量,代表模型生成的 token 序列。skip_special_tokens=True: 这个参数指示在解码过程中是否跳过特殊 token。特殊 token 通常是用来表示句子的起始、结束或填充位置的 token。如果设置为True,解码时会自动跳过这些特殊 token,只保留文本内容;如果设置为False,则会保留所有 token,包括特殊 token。
函数功能:
- 将 token 序列
s转换为文本序列。 - 根据 tokenizer 对应的词汇表,将 token 序列中的每个 token 解码为对应的文本单词或符号。
- 可选地跳过特殊 token,在最终的文本输出中去除这些特殊 token。
通过调用这个函数,您可以将模型生成的 token 序列转换为可读的文本,方便理解和展示模型生成的结果。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » llama3源码解读之准备

发表评论 取消回复