前言
之前写了一篇文章,使用国内通义千问作为llm,结合langchain框架实现文本向量化检索和使用chainlit实现网页界面交互,实现一个本地知识问答的机器人。原文链接《使用Chainlit接入通义千问快速实现一个本地文档知识问答机器人》。本次基于上个版本做了增强优化,重要改动是:
- 处理txt文本以外支持pdf文档的知识问答
- 使用流式响应提升用户体验
下面是文章教程
教程
文档问答机器人实现示例
在此示例中,我们将构建一个聊天机器人 QA 应用。我们将学习如何:
- 上传文件
- 从文件创建向量嵌入
- 创建一个聊天机器人应用程序,能够显示用于生成答案的来源
先决条件
安装项目所需依赖。
在项目根目录下创建 requirements.txt 文件,配置需要的依赖内容如下:
chainlit~=1.1.306
openai~=1.37.0
langchain~=0.2.11
chromadb~=0.4.24
tiktoken~=0.7.0
dashscope~=1.20.3
使用命令公爵切换到项目执行以下命令安装:
pip install -r .\requirements.txt
然后,您需要去这里创建一个 OpenAI 密钥。没有可以使用国内的通义千问或者百度文心一言的。具体文章看之前的《使用Chainlit接入通义千问快速实现一个多模态的对话应用》。
使用 LangChain 进行对话式文档 QA
项目根目录下创建文件pdf_qa.py
import chainlit as cl
from chainlit.types import AskFileResponse
from langchain.callbacks.base import AsyncCallbackHandler
from langchain.chains import (
ConversationalRetrievalChain,
)
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyPDFLoader, TextLoader
from langchain.embeddings.dashscope import DashScopeEmbeddings
from langchain.memory import ChatMessageHistory, ConversationBufferMemory
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=50)
index_name = "langchain-demo"
# Create a Chroma vector store
embeddings = DashScopeEmbeddings()
author = "Tarzan"
def process_file(file: AskFileResponse):
loader = None
if file.type == "text/plain":
loader = TextLoader(file.path, encoding="utf-8")
elif file.type == "application/pdf":
loader = PyPDFLoader(file.path)
documents = loader.load()
docs = text_splitter.split_documents(documents)
for i, doc in enumerate(docs):
doc.metadata["source"] = f"source_{i}"
return docs
def get_docsearch(file: AskFileResponse):
docs = process_file(file)
# Save data in the user session
cl.user_session.set("docs", docs)
docsearch = Chroma.from_documents(
docs, embeddings, collection_name=index_name
)
return docsearch
@cl.on_chat_start
async def on_chat_start():
files = None
# Wait for the user to upload a file
while files is None:
files = await cl.AskFileMessage(
content="Please upload a text file to begin!",
accept=["text/plain", "application/pdf"],
max_size_mb=20,
timeout=180,
).send()
file = files[0]
msg = cl.Message(content=f"Processing `{file.name}`...")
await msg.send()
docsearch = await cl.make_async(get_docsearch)(file)
message_history = ChatMessageHistory()
memory = ConversationBufferMemory(
memory_key="chat_history",
output_key="answer",
chat_memory=message_history,
return_messages=True,
)
# Create a chain that uses the Chroma vector store
chain = ConversationalRetrievalChain.from_llm(
ChatOpenAI(model_name="qwen-turbo", temperature=0, streaming=True),
chain_type="stuff",
retriever=docsearch.as_retriever(),
memory=memory,
return_source_documents=True,
)
# Let the user know that the system is ready
msg.content = f"Processing `{file.name}` done. You can now ask questions!"
await msg.update()
cl.user_session.set("chain", chain)
class AsyncLangchainCallbackHandler(AsyncCallbackHandler):
def __init__(self, message: cl.Message):
self.message = message
async def on_llm_new_token(self, token: str, **kwargs) -> None:
await self.message.stream_token(token)
@cl.on_message
async def main(message: cl.Message):
msg = cl.Message(content="", elements=[], author=author)
await msg.send()
chain = cl.user_session.get("chain")
# 创建回调处理器实例
cb = AsyncLangchainCallbackHandler(msg)
res = await chain.acall(message.content, callbacks=[cb])
source_documents = res["source_documents"]
text_elements = []
if source_documents:
for source_idx, source_doc in enumerate(source_documents):
source_name = f"source_{source_idx}"
# Create the text element referenced in the message
text_elements.append(
cl.Text(content=source_doc.page_content, name=source_name, display="side")
)
source_names = [text_el.name for text_el in text_elements]
if source_names:
await msg.stream_token(f"\nSources: {', '.join(source_names)}")
msg.elements = text_elements
else:
await msg.stream_token("\nNo sources found")
await msg.update()
代码解释
这段代码是一个使用 Chainlit 库构建的交互式文档问答应用。
导入必要的库和模块
首先,导入了必要的库和模块,例如 Chainlit 中用于处理用户交互的功能,LangChain 用于构建文档问答系统的组件,以及文件加载器、文本分割器等工具。
定义文本分割器和索引名称
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=50)
index_name = "langchain-demo"
这里定义了一个递归字符文本分割器,用于将长文档拆分成更小的块,以便于处理和索引。同时定义了向量数据库的集合名称。
定义作者变量
author = "Tarzan"
这个变量用于设置消息的发送者名称。
文件处理函数
def process_file(file: AskFileResponse):
...
此函数根据上传文件的类型(纯文本或 PDF)加载文档,并使用前面定义的文本分割器对文档进行分割。然后更新每个文档元数据中的源信息,并返回分割后的文档列表。
向量数据库创建函数
def get_docsearch(file: AskFileResponse):
...
该函数调用 process_file 函数来处理文件,并将处理后的文档存储到 Chroma 向量数据库中。此外,它还会将这些文档保存在用户的会话中。
对话开始时触发的函数
@cl.on_chat_start
async def on_chat_start():
...
当对话开始时,这个函数会被触发。它等待用户上传一个文件,然后调用 get_docsearch 函数来创建向量数据库,并初始化一个对话检索链,准备回答用户的问题。
异步回调处理器类
class AsyncLangchainCallbackHandler(AsyncCallbackHandler):
...
这是一个自定义的回调处理器类,用于处理来自 LangChain 的流式输出。每当模型生成一个新的令牌,它就会调用 on_llm_new_token 方法,将生成的文本流式发送给用户。
消息处理函数
@cl.on_message
async def main(message: cl.Message):
...
当收到用户的消息时,这个函数会被调用。它从用户的会话中获取之前初始化的对话检索链,然后调用这个链来回答问题。同时,它也会将相关的源文档以文本元素的形式展示给用户。
总的来说,这段代码实现了一个简单的问答系统,能够处理用户上传的文档,并针对这些文档回答用户提出的问题。它利用了 LangChain 和 Chainlit 的功能,使得整个交互过程流畅且易于使用。
环境变量
项目根目录下,创建.env文件,配置如下:
OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
OPENAI_API_KEY="通义千文API-KEY"
DASHSCOPE_API_KEY="通义千文API-KEY"
启动命令
- 命令行工具,项目根目录下执行
chainlit run pdf_qa.py
启动UI示例
- txt文件
- pdf文件
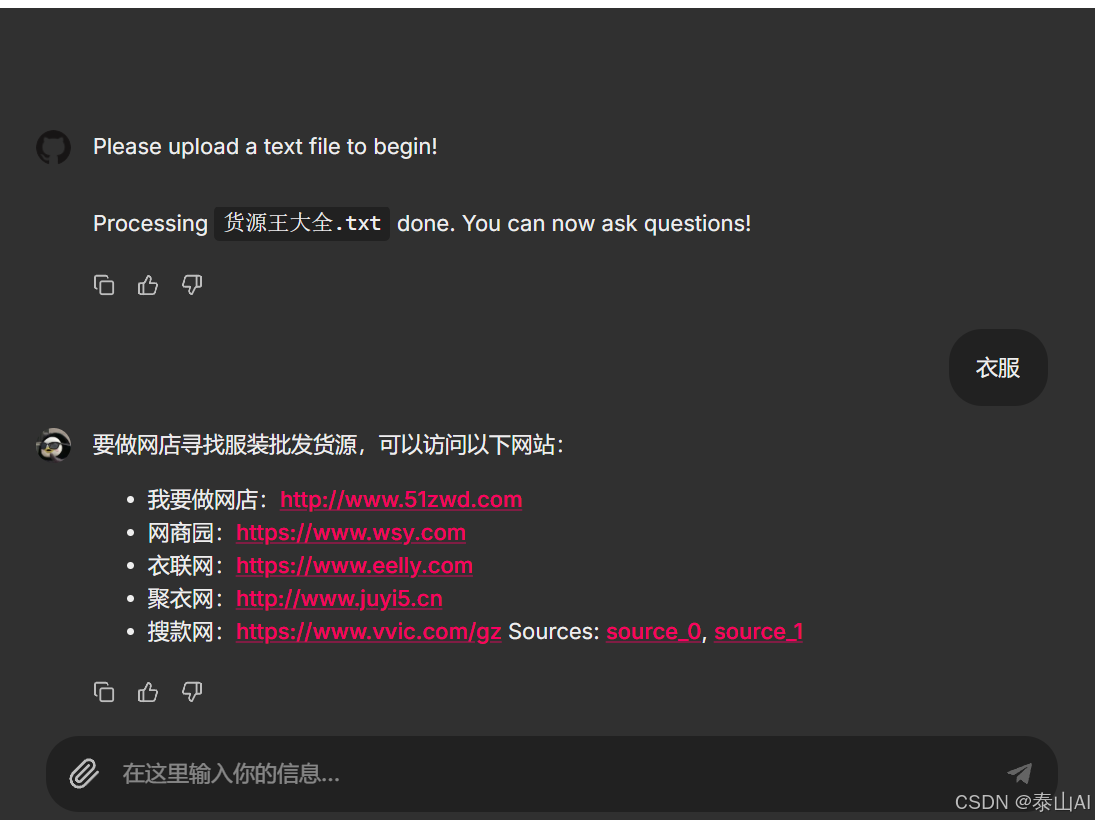
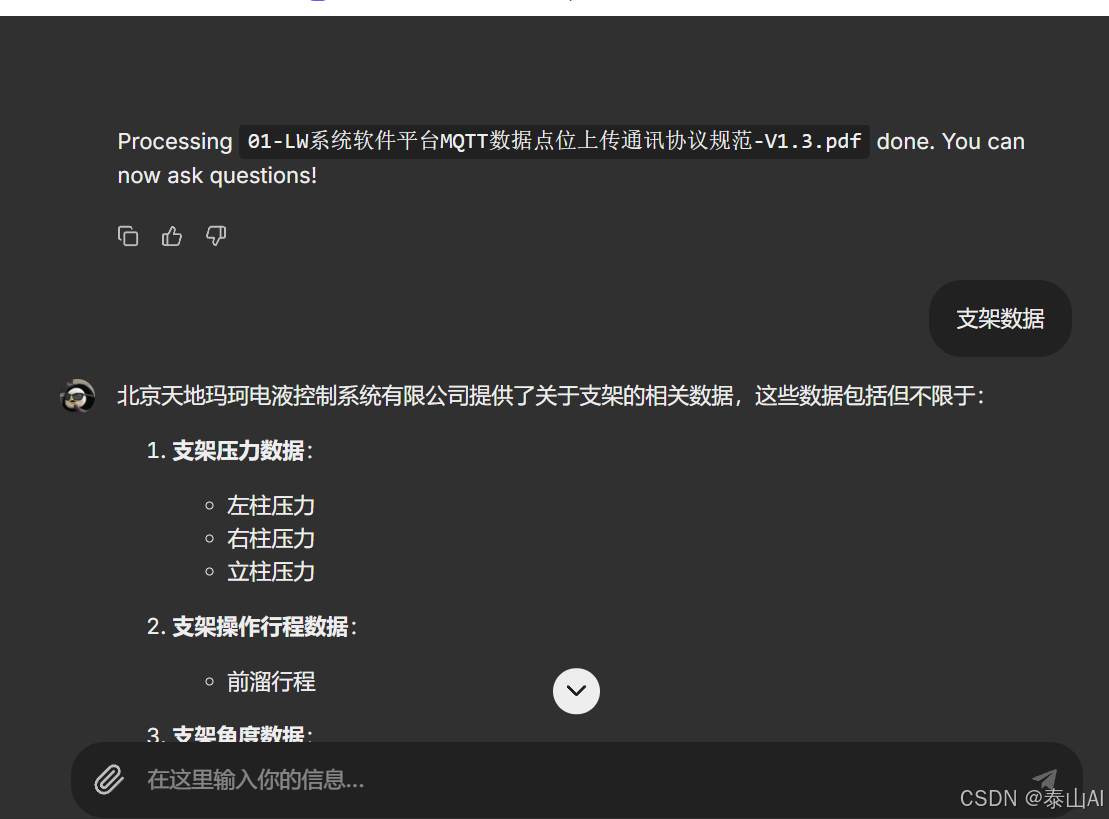
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 使用Chainlit接入通义千问快速实现一个本地文档知识问答机器人增强版

发表评论 取消回复