爬虫
- 1.什么是爬虫
- 2.基础入门之简单的页面设计
- 3.urllib基本使用,一个类型六个方法
- 4.urllib下载
- 5. 请求对象的定制
- 6.get请求的quote方法
- 7. get请求urlencode方法
- 8.urllib_post请求百度翻译
- 9.百度翻译详细版
- 10.urllib_ajax的get请求豆瓣电影的第一页
- 11.get请求豆瓣电影的前十页
- 12.ajax_post请求肯德基官网
- 13.异常
- 14.微博的cookie登录
- 15.handler处理器的基本使用
- 16.urllib代理
- 17.代理池
- 18.xpath的基本使用
- 19.解析_百度一下
- 20.站长素材
- 21.jsonpath
- 22.用jsonpath解析淘票票
- 23.BeautifulSoup
- 24.bs4获取星巴克数据
- 25.Selenium
- 26.selenium元素定位
- 27.举例Selenium邓紫棋
- 28.Selenium 其他操作
- 29.selenium-phantomjs
- 30.selenium-handless
- 31.request基本使用
- request中的get请求
- 32.request中的post请求
- 33.request_代理
- 34.request免验证登录古诗词网
- 35.scrapy基本使用
- 36.58同城实例
- 37.汽车之家
- 38.当当网
- 39.电影天堂
- 40.crawlspider
1.什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
2.基础入门之简单的页面设计
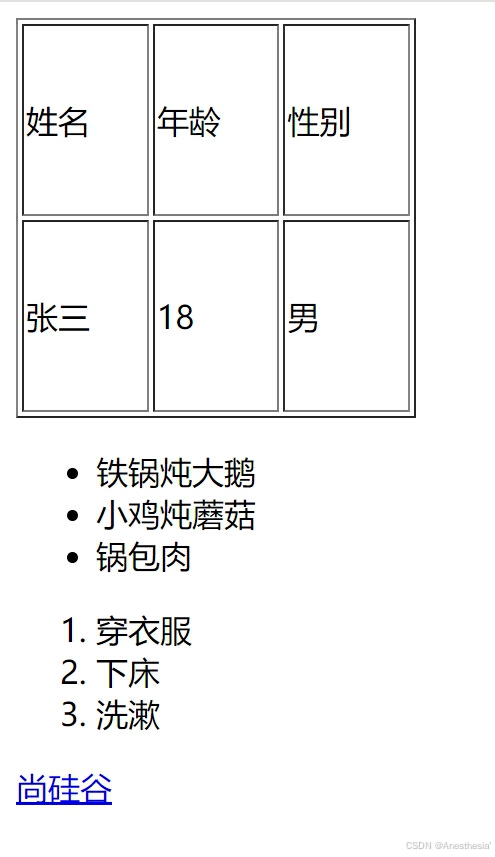
这一部分主要是为了展示怎样在爬虫中寻找网页中信息,在这些代码中展示的是一个列表,
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- table 表格
tr 行
td 列
-->
<table width = "200px" height = "200px" border = "1px">
<tr>
<td>
姓名
</td>
<td>
年龄
</td>
<td>
性别
</td>
</tr>
<tr>
<td>
张三
</td>
<td>
18
</td>
<td>
男
</td>
</tr>
</table>
<!-- ul li (无序列表) 爬虫使用很多-->
<ul>
<li>铁锅炖大鹅</li>
<li>小鸡炖蘑菇</li>
<li>锅包肉</li>
</ul>
<!-- ol li (有序列表) 更少一点-->
<ol>
<li>穿衣服</li>
<li>下床</li>
<li>洗漱</li>
</ol>
<!-- 超链接-->
<a href="http://www.atguigu.com/">尚硅谷</a>
</body>
</html>
3.urllib基本使用,一个类型六个方法
首先引用urllib,其中url代表我们想访问的网站网址,接下来我们要模拟一个浏览器向服务器发送请求,
使用
responce = urllib.request.urlopen(url)
来向服务器发送请求,用urllib来接收,从而我们就接收到了来自网站的源码,之后我们使用read()方法来读取,但是read()返回的是字节形式的二进制数据,我们无法读取,这时我们就可以解码,把二进制数据解码为字符串,使用decode(‘UTF-8’),这样我们就可以读取了。
** 一个类型六个方法 **
一个类型指的是我们上面提到的responce,也就是从服务器返回的数据,是HTTPResponce类型的。
六个方法:
content = responce.read(5) # 读取五个字节
# read读取时是按照字节去读取的,括号中是5说明读取5个字节
content = responce.readline()
# 读取一行
content = responce.readlines()
# 读取所有行,一行一行读,直到读完
print(responce.getcode())
# 一个小知识 ,返回状态码,如果是200,说明没问题
print(responce.geturl())
# 获取网站的地址,url指向的网站
print(responce.getheaders())
# 获取headers,也就是模拟的浏览器的信息
# 基本使用
# 使用urllib获取百度首页的源码
import urllib.request
# (1)定义一个url 就是要访问的地址
url = 'http://www.baidu.com'
# (2)模拟浏览器向服务器发送请求,responce就是响应
responce = urllib.request.urlopen(url)
# (3)获取响应中的原码
# read 方法,返回的是字节形式的二进制数据
# 要将二进制数据转换成字符串
# 二进制 -> 字符串 解码 decode('编码的格式')
# content = responce.read().decode('UTF-8')
# 一个类型和六个方法
# responce 是HTTPResponce类型
print(type(responce))
# 按照一个字节一个字节去读
# content = responce.read(5) # 读取五个字节
# print(content)
# (4)打印数据
# print(content)
# 读取一行
# content = responce.readline()
# 一行一行地读直到读完
# content = responce.readlines()
# print(content)
# 返回状态码 如果是200,证明我们没有错
# print(responce.getcode())
# 返回url地址
print(responce.geturl())
# 获取的一些状态信息
print(responce.getheaders())
# 一个类型HTTPresponce
# 六个方法read readline readlines getcode geturl getheaders
4.urllib下载
下载需要使用
urllib.request.urlretrieve(url = url,filename = 'filename')
其中url代表一个下载的网页,filename代表文件的名字,其中文件名字后要加文件格式,例如jpg,mp4等
# 下载
import urllib.request
# 下载一个网页
# url_page = 'http://www.baidu.com'
# url代表下载的路径,filename代表文件的名字
# 在python中,可以变量的名字,也可以直接写值
# urllib.request.urlretrieve(url_page,'baidu.html')
# 下载图片
url_img = 'https://img2.baidu.com/it/u=260402465,3171771956&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=889'
urllib.request.urlretrieve(url = url_img,filename='you.jpg')
# 下载视频
url_video = 'https://vdept3.bdstatic.com/mda-mhej5kskcde2e1e3/cae_h264_nowatermark/1629034712771677277/mda-mhej5kskcde2e1e3.mp4?v_from_s=hkapp-haokan-hbe&auth_key=1721966751-0-0-d761b7436e0f490614a8f1832a35f960&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=0351188068&vid=3964562110483450965&klogid=0351188068&abtest='
urllib.request.urlretrieve(url_video,'ban.mp4')
5. 请求对象的定制
有些网站中的开头为https://,说明在其中加入了ssl,这也是一种反爬虫的手段。
https://www.baidu.com/s?tn=15007414_15_dg&ie=utf-8&wd=邓紫棋
分析这个网址,其中有协议https://,有主机www.baidu.com,有路径s , 参数wd
# http/https www.baidu.com 80/443 s wd = 邓紫棋 #
# 协议 主机 端口号 路径 参数 锚点
# http 端口号 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mongodb 27017
我们需要构建一个请求对象来访问
在这里我们可以获得User-Agent的信息,来假借这一信息来向服务器发送信息,又因为urlopen中不能存放字典,所以我们可以通过request = urllib.request.Request(url = url1,headers=headers)来接收headers和url,并且由于参数顺序问题我们只能通过关键字传参的方式
import urllib.request
url1 = 'https://www.baidu.com'
# url的组成
# https 中加入了 ssl
# https://www.baidu.com/s?tn=15007414_15_dg&ie=utf-8&wd=邓紫棋
# http/https www.baidu.com 80/443 s wd = 邓紫棋 #
# 协议 主机 端口号 路径 参数 锚点
# http 端口号 80
# https 443
# mysql 3306
# oracle 1521
# redis 6379
# mongodb 27017
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 请求对象的定制
# 因为urlopen中不能储存字典,所以headers不能传递出去
# 因为参数顺序问题,不能直接写url和headers
request = urllib.request.Request(url = url1,headers=headers)
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
print(content)
# 第一个反爬 : UA
6.get请求的quote方法
当我们访问https://www.baidu.com/s?tn=15007414_15_dg&ie=utf-8&wd=%E9%82%93%E7%B4%AB%E6%A3%8B这个网站时,我们看不懂后面的这些乱码,所以我们改为
https://www.baidu.com/s?wd=邓紫棋
可是这时却报错,因为浏览器不认识中文,这时我们就应该把‘邓紫棋’换成unicode编码的形式,使用:
name = urllib.parse.quote('邓紫棋')
这样我们就可以获取到邓紫棋三个字的unicode编码了。然后把之前的url和name结合起来就可以获取网址了。
# https://www.baidu.com/s?tn=15007414_15_dg&ie=utf-8&wd=%E9%82%93%E7%B4%AB%E6%A3%8B
import urllib.request
import urllib.parse
# 需求 获取https://www.baidu.com/s?wd=邓紫棋 的网页源码
url = ' https://www.baidu.com/s?wd='
# 请求对象的定制,是为了解决反爬的第一种手段
headers = {
'User-Agent' : 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 127.0.0.0Safari / 537.36'
}
# 将邓紫棋三个字变成unicode编码的格式
# 我们依赖urllib.parse
name = urllib.parse.quote('邓紫棋')
url = url + name
# 请求对象的定制
request = urllib.request.Request(url = url,headers=headers)
# 模拟浏览器向服务器发送请求
responce = urllib.request.urlopen(request)
# 获取相应的内容
content = responce.read().decode('UTF-8')
print(content)
7. get请求urlencode方法
上面的实例中只有‘邓紫棋’一个中文,当我们有多个中文检索词时,还用quote就比较麻烦了,这是我们有一个更好的方法:
data = {
'wd' : '周杰伦',
'sex': '男',
'location':'中国台湾'
}
new_data = urllib.parse.urlencode(data)
这样我们就可以把这些元素都融合在一起了,这时我们就可以获取到想要的带有中文检索字的网址了,然后再定制请求对象想服务器发送请求就可以了。
# urlencode应用场景:多个参数的时候
# import urllib.parse
# https://www.baidu.com/s?wd=周杰伦&sex=男
# data = {
# 'wd' : '周杰伦',
# 'sex':'男'
# }
# a = urllib.parse.urlencode(data)
# print(a)
import urllib.request
import urllib.parse
base_url = 'https://www.baidu.com/s?'
data = {
'wd' : '周杰伦',
'sex': '男',
'location':'中国台湾'
}
new_data = urllib.parse.urlencode(data)
print(new_data)
# 路径
url = base_url + new_data
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers=headers)
# 模拟浏览器向服务器发送请求
responce = urllib.request.urlopen(request)
# 获取网页源码的数据
content = responce.read().decode('UTF-8')
print(content)
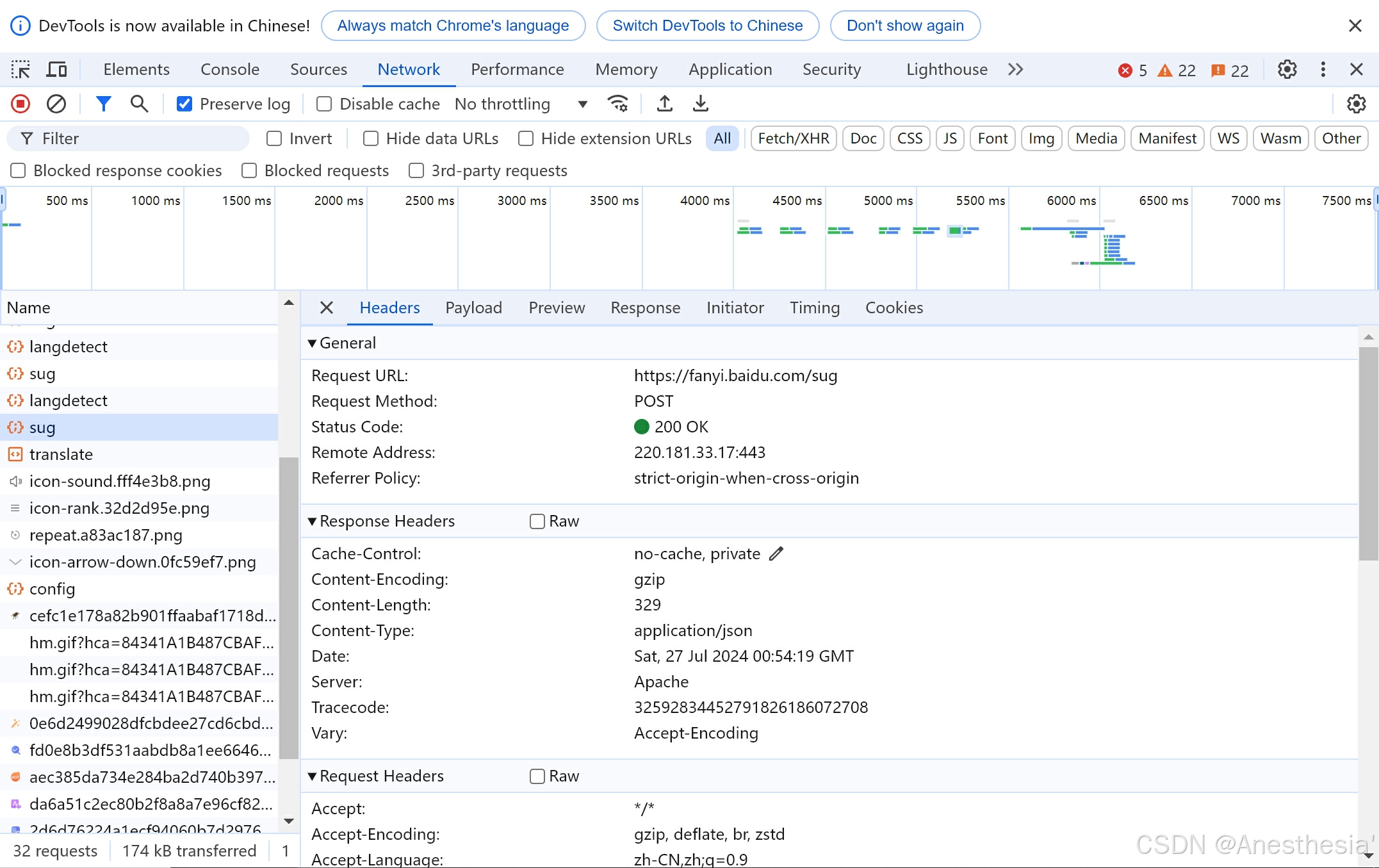
8.urllib_post请求百度翻译
我们在对百度翻译进行爬虫时,需要先找到网址'https://fanyi.baidu.com/sug'
然后我们可以在图中发现Request Method是POST,我们需要知道post的请求参数必须要进行编码,我们在图中得知一个字典类型的数据,这就是我们要在网站中查找的内容,我们用data来接收它,然后用urlencode编码一下:
data = urllib.parse.urlencode(data)
但是这样得到的是字符串,我们传入的是字节码,所以说post传入的参数需要编码,data = urllib.parse.urlencode(data).encode('UTF-8'),而且post传入的参数不会拼接到url后面,而是放到请求对象定制的参数中,
request = urllib.request.Request(url = url,data = data,headers=headers)
之后模拟浏览器向服务器发送请求,得到的数据我们看不懂,所以我们要对其进行改变,把字符串变成json数据,
import json
obj = json.loads(content)
print(obj)

# post请求
import urllib.parse
import urllib.request
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
data = {
'kw':'spider'
}
# post的请求参数必须要进行编码
# data = urllib.parse.urlencode(data) <- 这样是字符串,而传入的是字节码
data = urllib.parse.urlencode(data).encode('UTF-8')
# post请求的参数不会拼接在url后面,而是需要放到请求对象定制的参数中
# post请求的参数必须要进行编码
request = urllib.request.Request(url = url,data = data,headers=headers)
# print(request)
# 模拟浏览器向服务器发送请求
responce = urllib.request.urlopen(request)
# 获取相应的数据
content = responce.read().decode('UTF-8')
print(content)
# post请求方式的参数 必须编码 data = urllib.parse.urlencode(data).encode('UTF-8')
# 编码之后必须调用encode方法
# 参数放在请求对象定制的方法中
# 字符串变成json数据
import json
obj = json.loads(content)
print(obj)
9.百度翻译详细版
由于反爬手段的提升我找不到之前的v2文件,所以这一段没有爬取成功…
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
# 'cookie'最重要,但是我找不到
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
data = {
'from' : 'en',
'to' : 'zh',
'query' : 'love',
'transtype':'realtime',
'simple_means_flag':'3',
'sign':'198772.518981',
'token':'5483bfa652979b41f9c90d91f3de875d',
'domain':'common'
}
# post请求的参数必须编码
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象的定制
request = urllib.request.Request(url = url,data=data,headers=headers)
# 模拟浏览器向服务器发送请求
responce = urllib.request.urlopen(request)
# 获取相应的数据
content = responce.read().decode('utf-8')
import json
obj = json.loads(content)
print(obj)
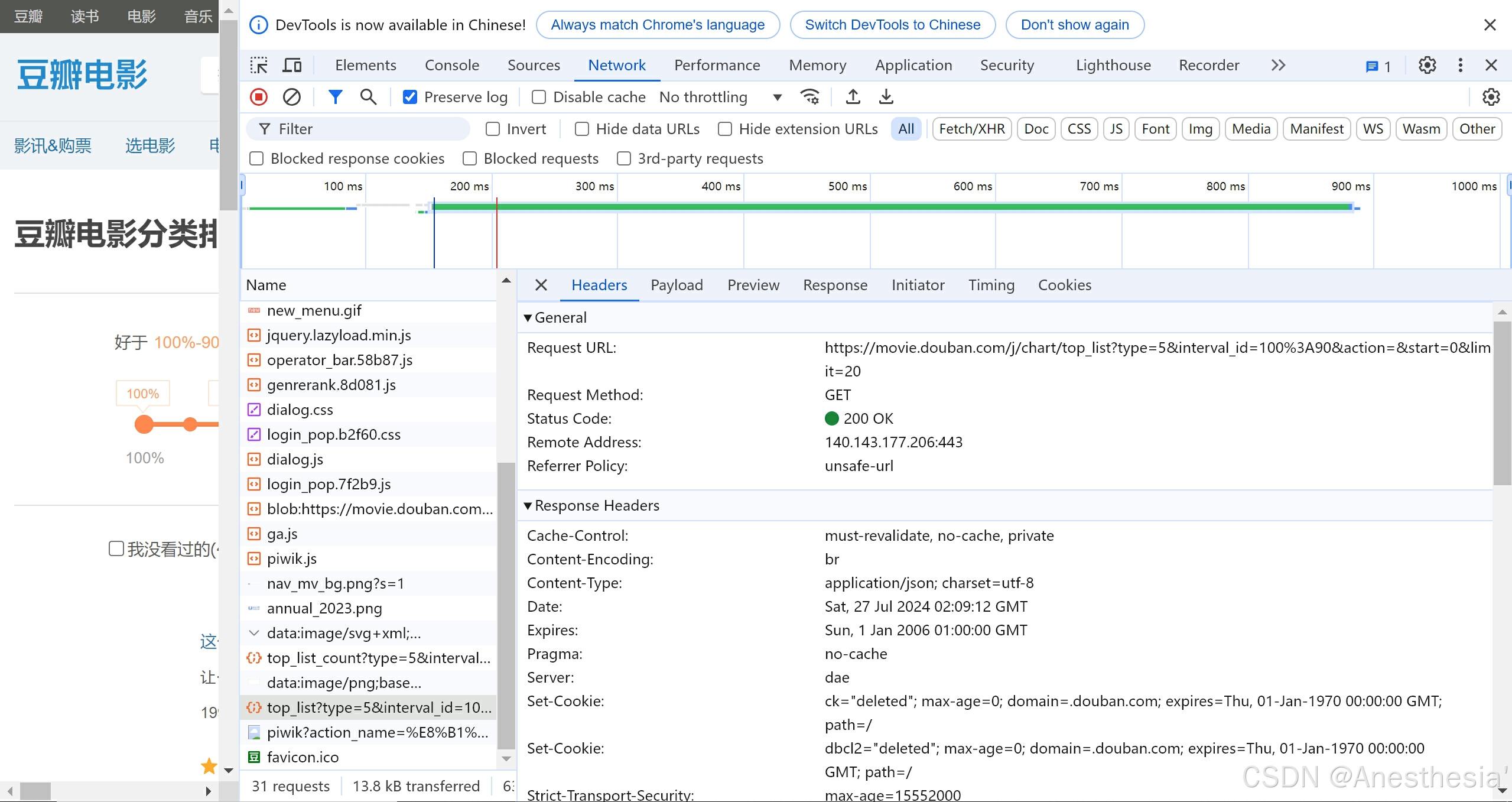
10.urllib_ajax的get请求豆瓣电影的第一页
我们在检查中发现类型是get
网址为:https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
之后我们构建请求对象,模拟浏览器向服务器传递信息,接收到content后,我们想把它下载到本地,可以使用open方法,open方法默认情况下是使用gbk编码,如果我们想保存汉字,那么需要我们在open格式中指定编码格式为‘UTF-8’
with open('douban1.json','w',encoding = 'utf-8') as fp:
fp.write(content)
11.get请求豆瓣电影的前十页
如果我们想下载多页数据时,一次一次输入网址会很麻烦,我们登录网站发现这些网址都是有规律的,通过分析可知start = (page-1) * 20,这样我们就想到可以使用for循环来为我们下载,首先在程序入口处输入起始页和终止页,然后通过for循环,找到每一页,每一页中都有自己的请求对象,
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action='
data = {
'start' : (page-1)*20,
'limit' : '20'
}
data = urllib.parse.urlencode(data)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
url = base_url + data
request = urllib.request.Request(url = url,headers=headers)
return request
其他的就和访问一页的数据是相同的,在最后下载时:
def down_load(page,content):
with open ('douban'+str(page)+'.json','w',encoding = 'utf-8') as fp:
fp.write(content)
有一个小坑,就是page必须要强制类型转换为str才能和文件名结合起来。
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=60&limit=20
# page 1 2 3 4
# start 0 20 40 60
# start = (page-1) * 20
# 下载豆瓣电影前十页的数据
# (1)请求对象定制
# (2)获取相应的数据
# (3)下载数据
import urllib.request
import urllib.parse
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action='
data = {
'start' : (page-1)*20,
'limit' : '20'
}
data = urllib.parse.urlencode(data)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
url = base_url + data
request = urllib.request.Request(url = url,headers=headers)
return request
def get_content(request):
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
return content
def down_load(page,content):
with open ('douban'+str(page)+'.json','w',encoding = 'utf-8') as fp:
fp.write(content)
# 程序入口:
if __name__ == '__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页码'))
for page in range(start_page,end_page+1):
# 每一页都有自己请求的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(page,content)
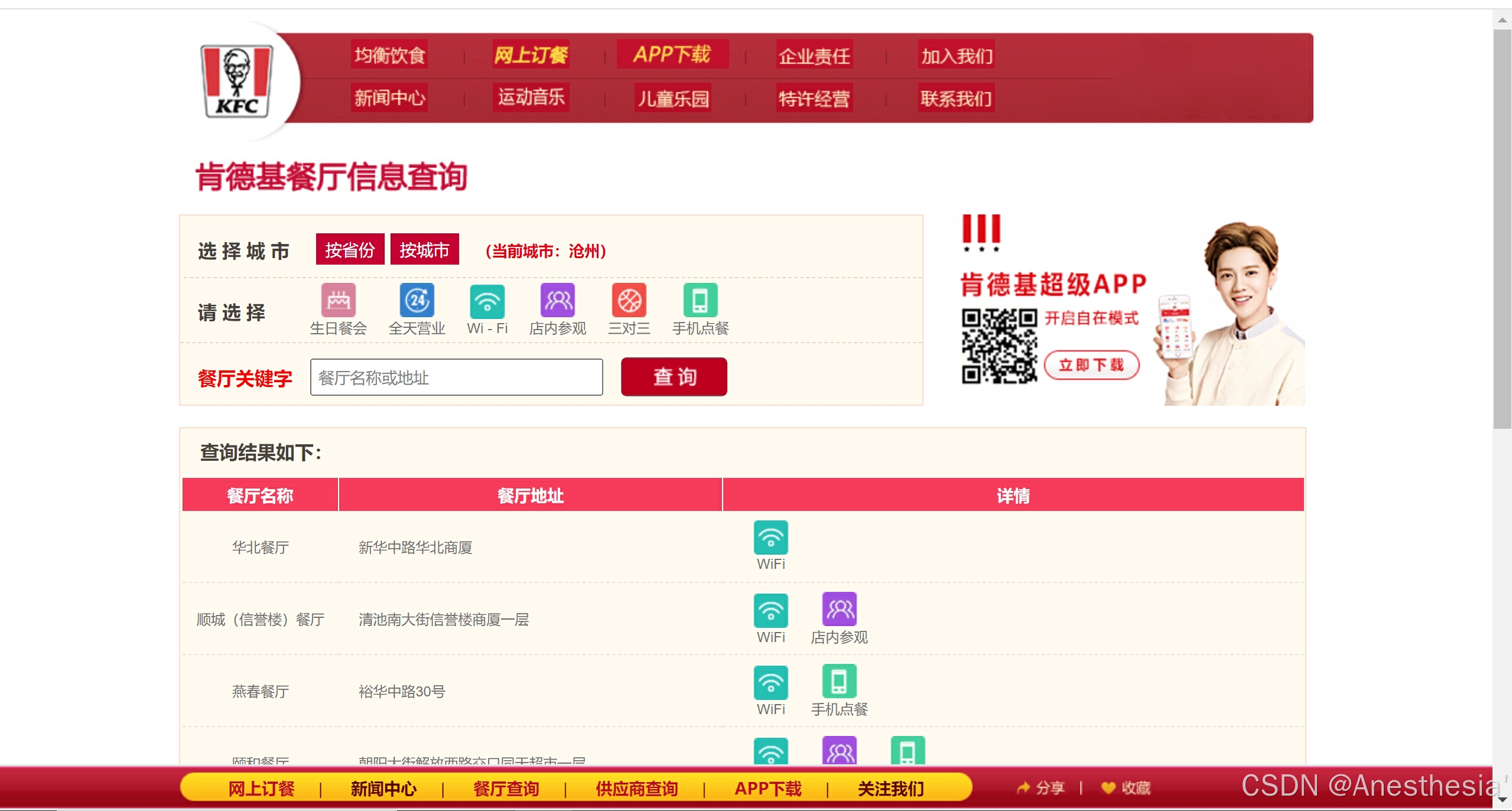
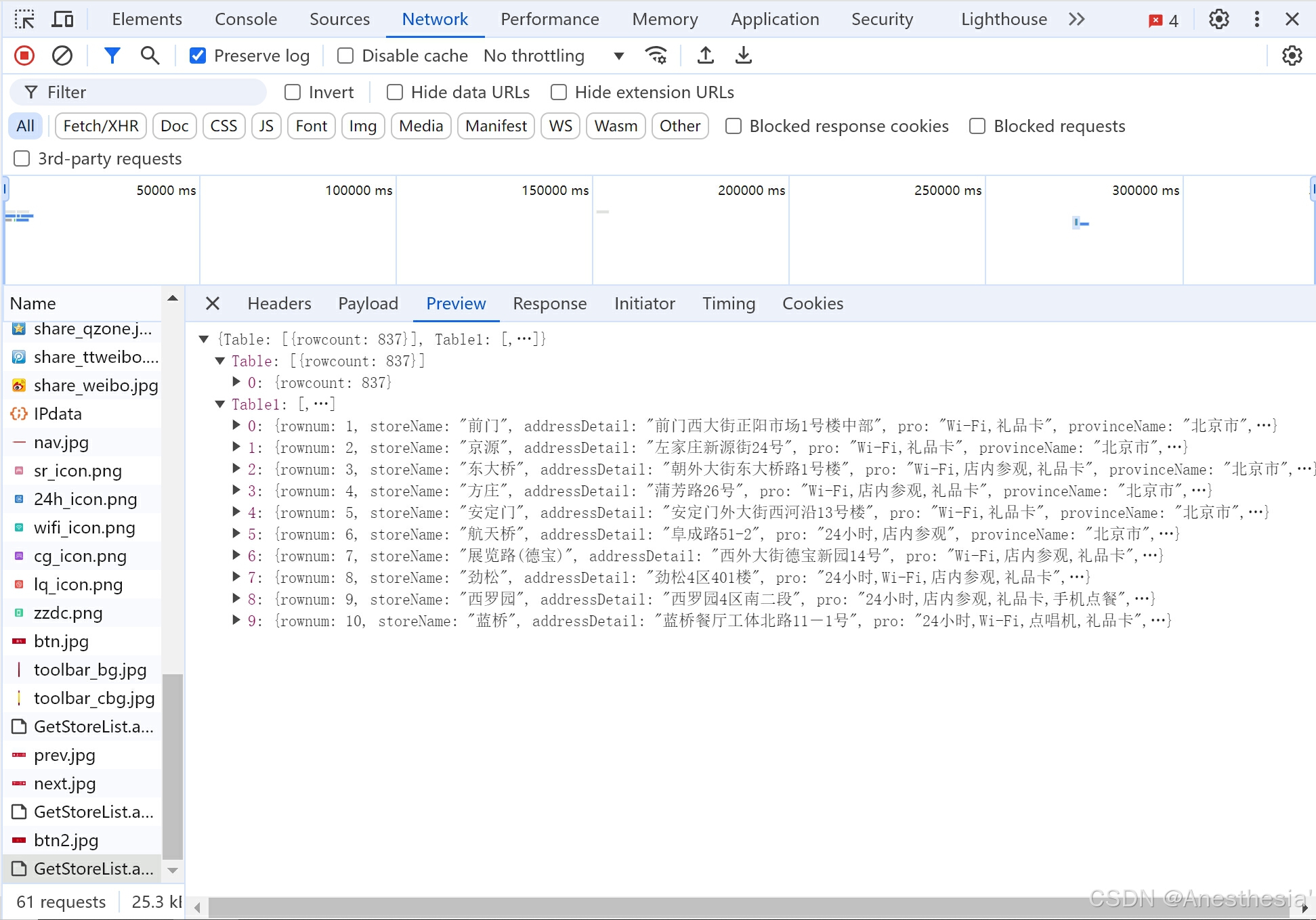
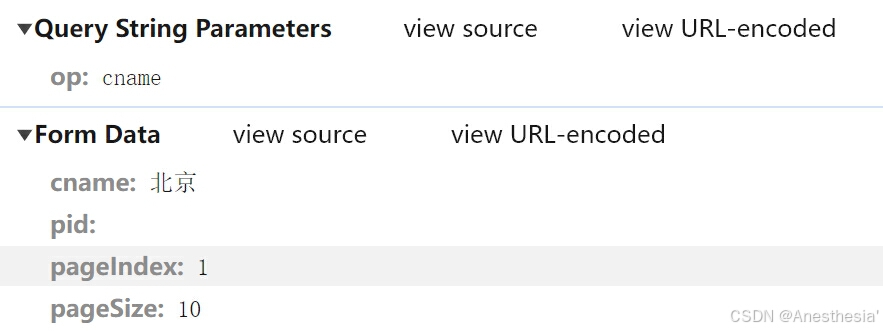
12.ajax_post请求肯德基官网
当我们想在肯德基官网获取餐厅信息时,我们可以使用ajax_post方法,首先我们在官网中获取一些信息:
我们在不同页面中发现这些网址只有page是不同的,那么我们还是可以利用一个for循环,分别记录每一页,然后构建针对不同page的请求对象来模拟访问就可以了。
# 2页
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post请求
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
# 1页
# https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
import urllib.request
import urllib.parse
def create_request(page):
base_url = 'https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url = base_url,data=data,headers=headers)
return request
def get_content(request):
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
return content
def download(page,content):
with open('kfc_'+ str(page) +'.json','w',encoding = 'utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('输入起始页码'))
end_page = int(input('输入结束页码'))
for page in range(start_page,end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载
download(page,content)
13.异常
当我们有时访问失败时,可以使用try_except来确保程序稳定运行,而且我们也可以通过try_except来分析出是哪一种错误,例如有HTTPError,URLError等
# URLError / HTTPError
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/sulixu/article/details/1198189491'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
try:
request = urllib.request.Request(url = url,headers=headers)
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级...')
except urllib.error.URLError:
print('系统正在升级...')
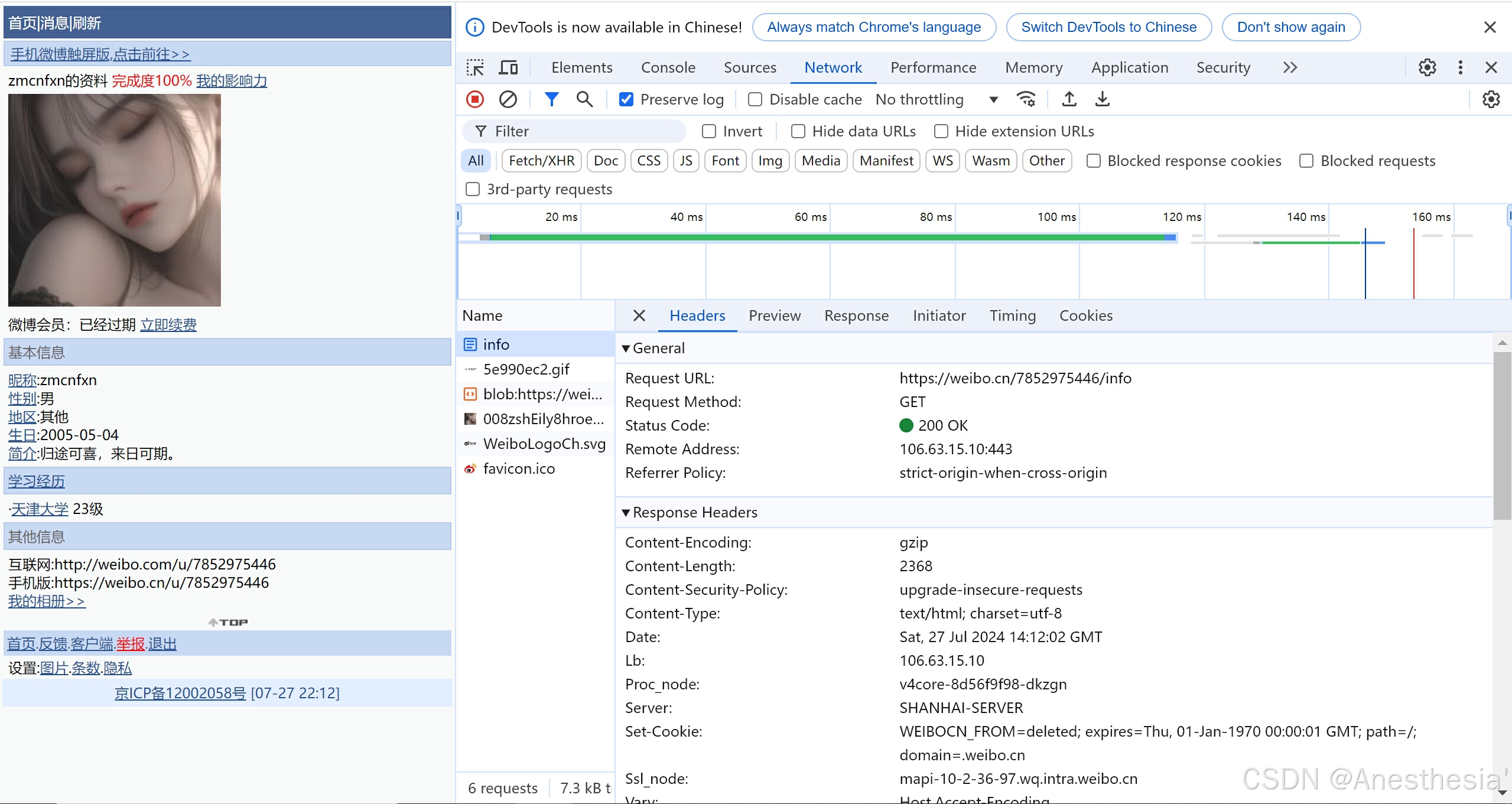
14.微博的cookie登录
在访问微博时,我们是需要登录的,如果想要跳过登录,我们可以借助UA和cookie值进入,有时还会需要referer,它是判断你的访问是从哪一个网站来的,如果不是它规定的网站,就会报错,不会给你返回值,此外还要判断个人信息页面是否是utf-8类型,否则也会出错。
# 适用场景;数据采集时,需要绕过登录,然后进入到某个页面
import urllib.request
# 个人信息页面是utf-8,但是还是报了错,因为并没有进入到个人信息页面,而是跳转到了登录页面
# 那么登录页面不是utf-8
url = 'https://weibo.cn/78529754/info'
# 访问不成功是因为请求头信息不够
headers = {
# refer 判断当前路径是不是由上一个路径进来的,一般情况下做图片防盗链
'referer':'https://weibo.cn/',
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/5.36',
# cookie中携带有你的登录信息,如果登陆之后有cookie
'cookie' : '_T_WM=d2f35cbdfece6f640ede045818da88d5; SCF=Alr8vNiruaP9jRc7fqN_u9cTZn_1GmCjtpbbrJMiFLUWPKB-jG35pMkTSbEq70HhKEFgJCW78xgnIpPa7lHcw2o.; SUB=_2A25LoMf-DeRhGeFG7lAY9yvIzzqIHXVo3EU2rDV6PUJbktANLRHYkW1NeUVJpU0UhBUoxjmFEWVW38OwxCHmgCDg; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WF2wIbYV-gP9mnBVAM.0zdv5NHD95QN1h-E1KMfShBcWs4DqcjGwJfodJ9Rdntt; SSOLoginState=17220708; ALF=1724662958'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers=headers)
# 模拟浏览器向服务器发送请求
responce = urllib.request.urlopen(request)
# 获取相应的数据
content = responce.read().decode('utf-8')
# 将数据保存到本地
with open ('weibo.html','w',encoding='utf-8')as fp:
fp.write(content)
15.handler处理器的基本使用
在上述例子中,cookie值都是不变的,但是当cookie随着我们的访问一直变化我们应该怎么办呢?这是我们就可以使用handler,下面我们使用访问百度来举例子:
我们需要三个方法:
handler build_opener open
和之前不同的是,我们构建完请求对象后,我们不能用urlopen来模拟浏览器访问服务器,而是通过:
# handler build_opener open
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
responce = opener.open(request)
来获取responce。
# 动态cookie和代理不能简单使用请求对象的定制
# 使用handler来访问百度,获取网页源码
import urllib.request
url = 'https://www.baidu.com'
headlers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
# handler build_opener open
# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
responce = opener.open(request)
content = responce.read().decode('utf-8')
print(content)
16.urllib代理
当我们不想让服务器知道我们的ip地址,或者在访问一些国外网站需要国外ip是时,可以使用代理服务器,我们不再用responce = urllib.request.urlopen(request),而是通过一个代理ip来模拟浏览器,而且要注意proxies是一个字典类型的,要注意格式,使用:
proxies = {
'http':'118.24.219.151:16817'
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
responce = opener.open(request)
来获取responce。
# 代理服务器
# 访问国外站点,访问一些单位或团体内部资源,提高访问速度,隐藏真实ip
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 请求对象
request = urllib.request.Request(url = url,headers=headers)
# 模拟浏览器:
# responce = urllib.request.urlopen(request)
proxies = {
'http':'118.24.219.151:16817'
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
responce = opener.open(request)
# 获取相应信息
content = responce.read().decode('utf-8')
# 保存
with open('daili.html','w',encoding='utf-8') as fp:
fp.write(content)
17.代理池
当我们使用代理ip访问时,访问次数多了也会被封,所以我们可以使用多个ip分别随机访问,这样就不会被检测到了,我们需要引入import random,然后将proxies随机一下,这样就可以每次使用不同的ip了,然后就像代理ip一样输入就好了。
# 代理池
import urllib.request
proxies_pool = [
{'http':'118.24.219.151:16811111'},
{'http':'118.24.219.151:16822222'},
{'http':'118.24.219.151:16833333'},
{'http':'118.24.219.151:16844444'}
]
import random
proxies = random.choice(proxies_pool)
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url = url,headers=headers)
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
responce = opener.open(request)
content = responce.read().decode('utf-8')
with open('daili.html','w',encoding='utf-8') as fp:
fp.write(content)
18.xpath的基本使用
xpath可以用来获取网页源码中的部分数据,这样我们就可以在其中添加条件,来获取我们需要的特定的数据,下面是一个html文件我们在其中查找特定的元素
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id = "l1" class = "c1">北京</li>
<li id = "l2">上海</li>
<li id = "c1">武汉</li>
<li id = "c2">深圳</li>
</ul>
<ul>
<li>河北</li>
<li>东北</li>
</ul>
</body>
</html>
首先我们要先调用from lxml import etree,然后我们用xpath来解析本地文件,tree = etree.parse('XPATH.html') 然后就可以个根据不同的需求获取不同的信息。
# 获取网页源码部分数据的一种方式
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应文件 responce.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('XPATH.html')
# 1.路径查询:
# //:查找所有子孙节点,不考虑层级关系
# / : 查找子节点
# tree.xpath('xpath路径')
# lilist = tree.xpath('//body//ul')
# 判断列表的长度
# print(len(lilist))
# 2.谓词查询
# //div[@id]
# //div[@id = "maincontent"]
# test()获取标签的内容
lilist = tree.xpath('//ul/li[@id]')
print(lilist)
# 找到标签为l1的标签
li_list = tree.xpath('//ul/l1[@id = "l1"]')
print(len(li_list))
# 查找到id为l1标签的class属性值
# 3.属性查询://@class
li = tree.xpath('//ul/li[@id = "l1"]/@class')
print(li)
# 4.模糊查询
# //div[contains(@id,"he")] id包含he
# //div[starts-with(@id,"he")] id以he开头
li__list = tree.xpath('//ul/li[contains(@id,"l")]')
print(li__list)
# 查询id的值以l开头的li标签
liilist = tree.xpath('//ul/li[starts-with(@id,"l")]')
print(liilist)
# 查询id为l1并且class为c1的
li_list = tree.xpath('//ul/li[@id = "l1" and @class = "c1"]')
print(li_list)
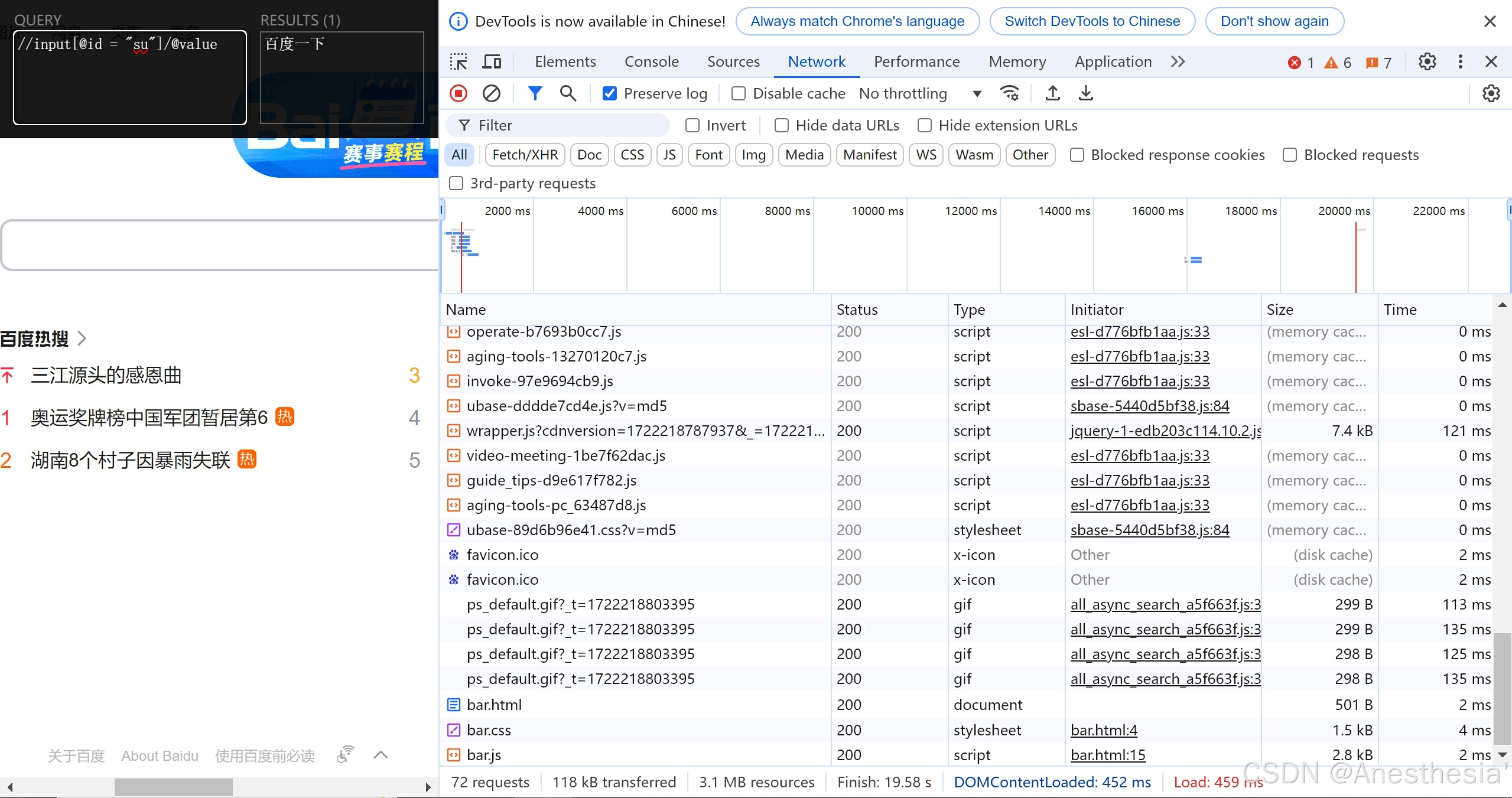
19.解析_百度一下
当我们想象获取“百度一下”这四个字时,用到了xpath工具
import urllib.request
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url = url,headers=headers)
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
# 获取我们想要的
from lxml import etree
# 解析服务器相应的文件
tree = etree.HTML(content)
result = tree.xpath('//input[@id = "su"]/@value')[0]
print(result)
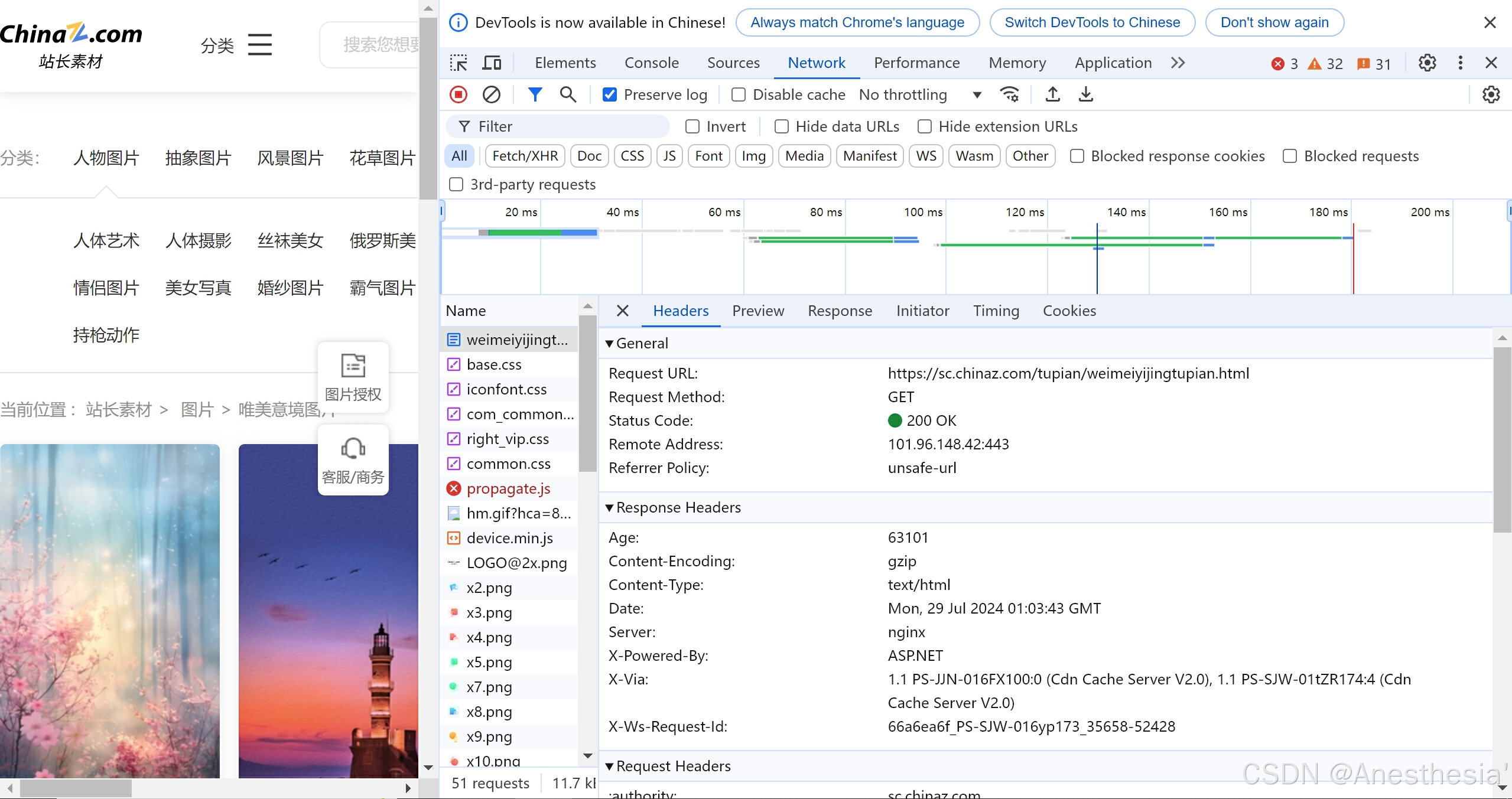
20.站长素材
当我们在站长素材这个网站上下载图片时,首先我们要找到图片的网址,我们发现第一页和其他页不同,第一页是没有page的,所以我们用if-else语句来分别提取出第一页和其他页,然后模拟浏览器向服务器发送请求,并且根据获得的源码在其中找到图片名字和网址所在的子孙类,下载就可以了。
import urllib.request
from lxml import etree
# 需求:前十页图片,第一页和其他页的数据不同
# https://sc.chinaz.com/tupian/weimeiyijingtupian.html
# https://sc.chinaz.com/tupian/weimeiyijingtupian_2.html
# 请求对象的定制
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/weimeiyijingtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/weimeiyijingtupian_' + str(page) +'.html'
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 127.0.0.0Safari / 537.36'
}
request = urllib.request.Request(url = url,headers=headers)
return request
# 获取网页源码
def get_content(request):
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
return content
# 下载
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件名字')
tree = etree.HTML(content)
namelist = tree.xpath('//div[@class = "container"]//img//@alt')
# 一般图片网站都会懒加载
srclist = tree.xpath('//div[@class = "container"]//img//@data-original')
for i in range(len(namelist)):
name = namelist[i]
src = srclist[i]
url = 'https:'+src
urllib.request.urlretrieve(url = url,filename = './lovlmg/'+name+'.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载
down_load(content)
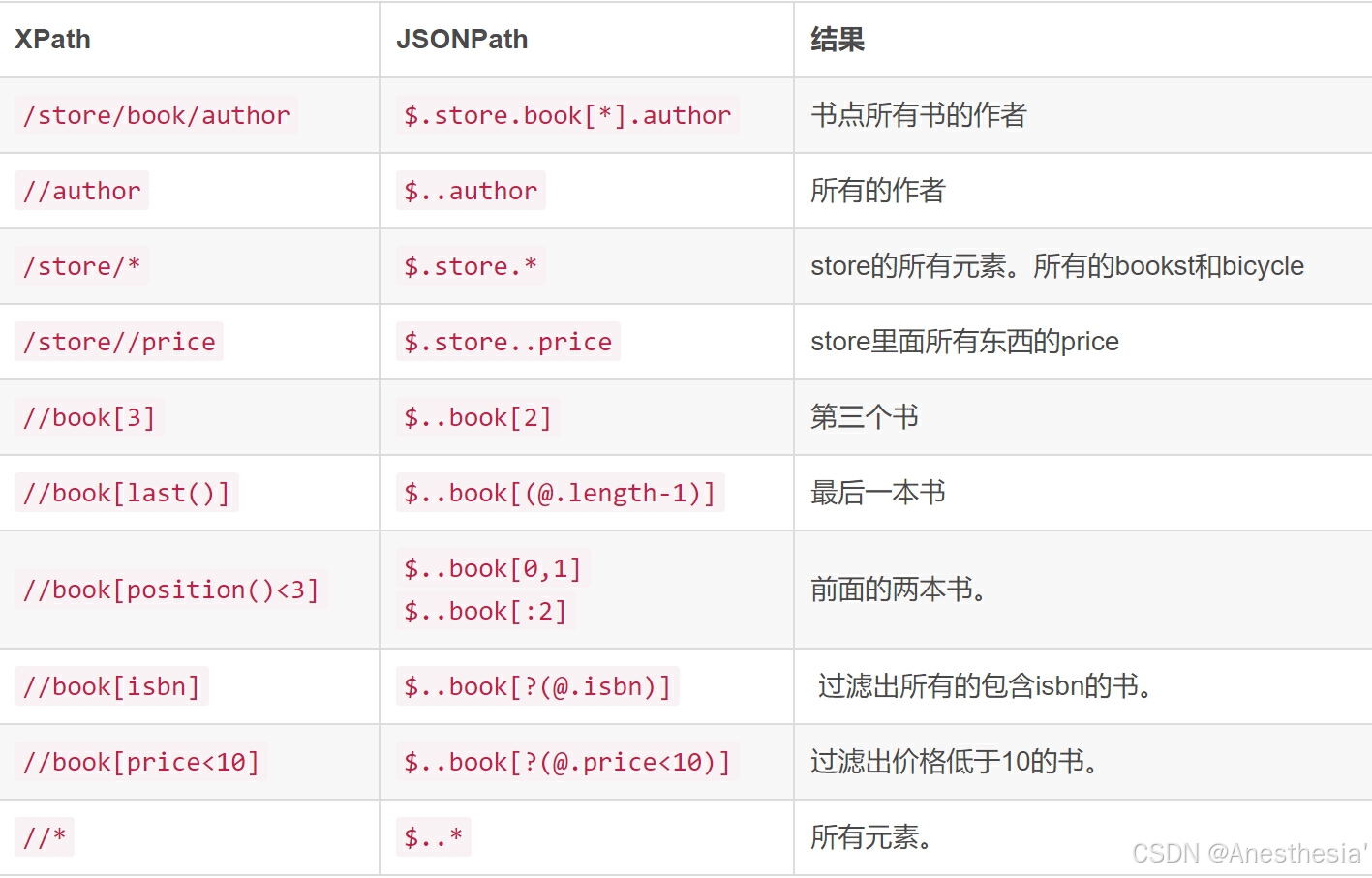
21.jsonpath
下面是一个json文件,我们使用jsonpath来查找我们想要的元素。在此之前我们都要提前下载jsonpath,在json库中就可以下载

{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
import json
import jsonpath
obj = json.load(open('解析jsonpath.json','r',encoding = 'utf-8'))
# print(obj)
# 书店所有书的作者
author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
# print(author_list)
# 所有的作者
author_list = jsonpath.jsonpath(obj,'$..author')
# print(author_list)
# store下面的所有元素
tag_list = jsonpath.jsonpath(obj,'$.store.*')
# print(tag_list)
# store里所有的钱
price_list = jsonpath.jsonpath(obj,'$.store..price')
print(price_list)
# 第三个书
book = jsonpath.jsonpath(obj,'$..book[2]')
print(book)
# 最后一本书
book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
print(book)
# 前面的两本书
book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
print(book_list)
# 条件过滤需要在()前面加一个?号
# 过滤出所有含有isbn的书
book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
print(book_list)
# 哪本书超过了十块钱
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
print(book_list)
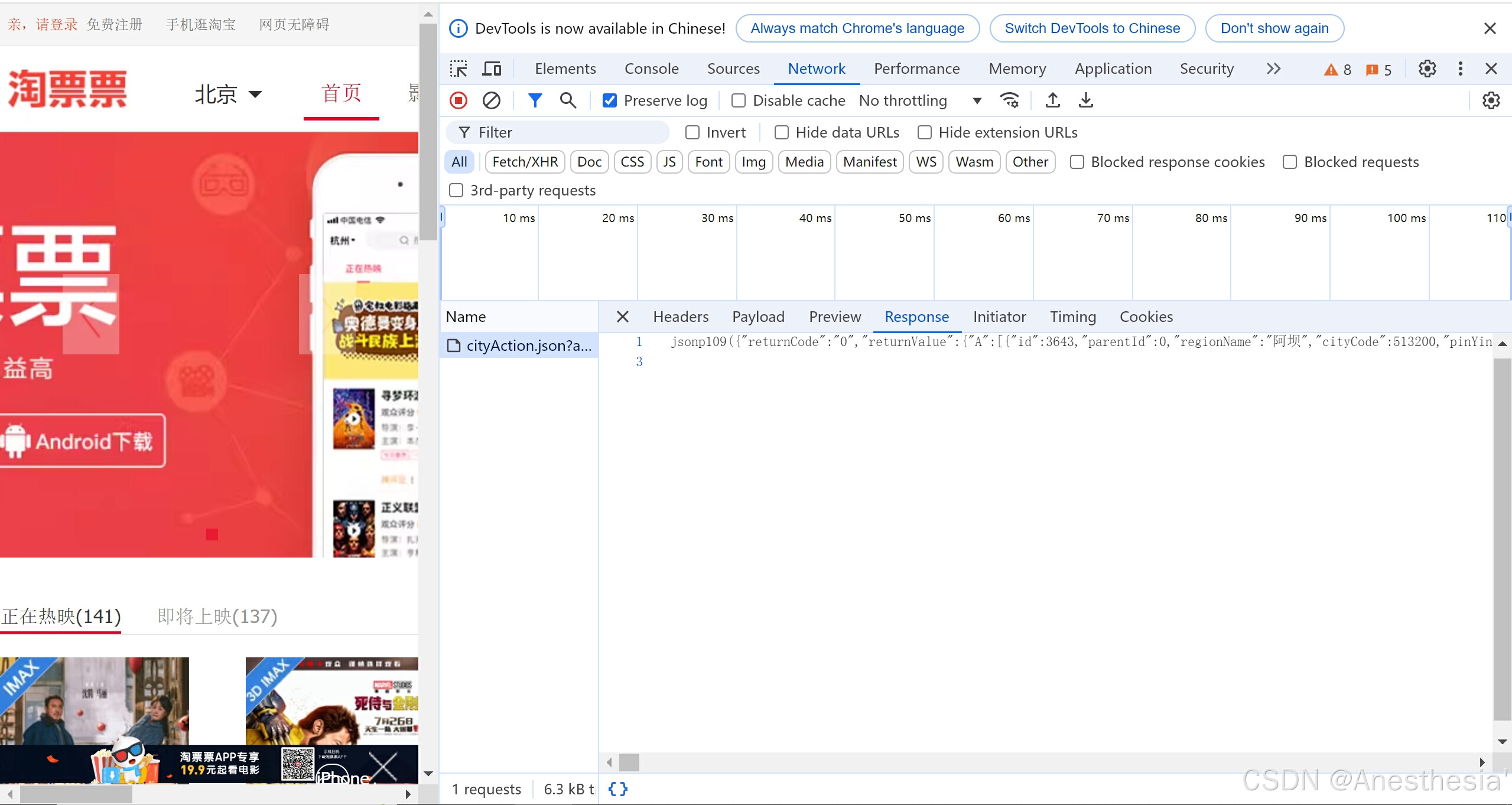
22.用jsonpath解析淘票票
这一节我们要在淘票票网站中获取城市信息,首先我们找到网站和城市的json文件,在其中我们要进行切割来获取我们想要的部分。
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1722168119996_108&jsoncallback=jsonp109&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
'accept':'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
'accept-language':'zh-CN,zh;q=0.9',
'bx-v':'2.5.14',
'cookie':
't=164d761e0b05d3b06cdd6bf1f9b678a7; cookie2=18db62f7815a4ae14ef8d13a956326d3; v=0; _tb_token_=fbe3708e067b3; cna=u/MsH/Vh8XoCAXzuRuYVHkpC; xlly_s=1; isg=BJCQTO2mwrV1Gp6xP-s5jLwjYd7iWXSjvRF2bIpgH-u-xTFvMmnmM167nY0lECx7',
'priority':
'u=1, i',
'referer':
'https://dianying.taobao.com/',
'sec-ch-ua':
'"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile':
'?0',
'sec-ch-ua-platform':
'"Windows"',
'sec-fetch-dest':
'empty',
'sec-fetch-mode':
'cors',
'sec-fetch-site':
'same-origin',
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
'x-requested-with':
'XMLHttpRequest'
}
request = urllib.request.Request(url = url ,headers=headers)
responce = urllib.request.urlopen(request)
content = responce.read().decode('utf-8')
# 切割
content = content.split('(')[1].split(')')[0]
with open('淘票票.json','w',encoding='utf-8') as fp:
fp.write(content)
import json
import jsonpath
obj = json.load(open('淘票票.json','r',encoding='utf-8'))
city_list = jsonpath.jsonpath(obj,'$..regionName')
print(city_list)
23.BeautifulSoup
BeautifulSoup是一种解析HTML和XML的第三方库,可以查找文件中的特定标签的元素。
比如以下的HTML文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id = "l1">张三</li>
<li id = "l2">李四</li>
<li>王五</li>
<a href="" id = "" class = "a1">哈哈哈</a>
<span>嘿嘿嘿嘿</span>
</ul>
</div>
<a href="" title = "a2">百度</a>
<div id = "d1">
<span>
哈哈哦好啊
</span>
</div>
<p id = "p1" class = "p1" >呵呵呵</p>
</body>
</html>
from bs4 import BeautifulSoup
# 通过解析本地文件来讲解bs4的基础语法
# 默认打开文件格式是gbk
soup = BeautifulSoup(open('BeautifulSoup.html',encoding='utf-8'),'lxml')
# print(soup)
# bs4基本语法
# (1)根据标签名字来查找节点
# 找到的是第一个符合条件的数据
# print(soup.a)
# print(soup.a.attrs) # 获取标签的属性和属性值
# bs4的一些函数
# (1) find 返回的是第一个符合条件的数据
# print(soup.find('a'))
# 使用title标签来找到相应的对象
# print(soup.find('a',title = "a2"))
# 可以加一个_来代表html中的class,因为class是python中的类
# print(soup,find('a',class_ = "a1"))
# (2) find_all 返回的是一个列表并且返回了所有的a标签
# print(soup.find_all('a'))
# 如果想获取多个标签的数据,那么需要在find_all的参数中添加的是列表的数据
# print(soup.find_all(['a','span']))
# limit作用是查找前几个数据
# print(soup.find_all('li',limit = 2))
# (3) select(推荐)
# select方法返回的是一个列表,并且会返回多个数据
print(soup.select('a'))
# 可以通过 . 代表class,我们把这种操作叫做类选择器
print(soup.select('.a1'))
# id
# id = l1 ,用 # 代替
print(soup.select('#l1'))
# 属性选择器
# 查找到li标签中有id的标签
print(soup.select('li[id]'))
# 找到id为l2的标签
print(soup.select('li[id = "l2"]'))
# 层级选择器
# 后代选择器
# 找到div下面的li
print(soup.select('div li'))
# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中如果不加空格不会输出内容,但是在bs4中不会报错
print(soup.select('div > ul > li'))
# 找到a标签和li标签的所有对象
print(soup.select('a,li'))
# 节点信息
# 获取节点内容
obj = soup.select('#d1')[0]
# 如果标签对象中只有内容,但是如果标签对象中除了内容还有标签,那么string中获取不到数据,而get_text()是可以获取的
print(obj.string)
print(obj.get_text())
# 节点的属性
# 通过id来获取p标签
obj = soup.select('#p1')[0]
# name 是标签的名字
print(obj.name)
# 将属性值作为一个字典返回
print(obj.attrs)
# 获取节点的属性
opj = soup.select('#p1')[0]
print(obj.attrs.get('class'))
print(obj.get('class'))
print(obj['class'])
24.bs4获取星巴克数据
当我们想获取星巴克中咖啡种类的数据时,首先我们找到官网,然后获取到返回数据,使用name_list = soup.select('ul[grid padded-3 product] strong')来获取咖啡名
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
headers = {
}
responce = urllib.request.Request(url = url)
content = responce.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class = "grid padded-3 product"]//strong/text()
name_list = soup.select('ul[grid padded-3 product] strong')
for name in name_list:
print(name.string)
25.Selenium
Selenium是一个
from selenium import webdriver
# Chrome浏览器
driver = webdriver.Chrome()
driver.get('https://www.jd.com')
# 获取网页源码
content = driver.page_source
print(content)
26.selenium元素定位
(1)id 可以唯一定位到一个元素(全局唯一)find_element(By.ID, "id名")
(2)name 要确保是全局唯一的find_element(By.NAME, "name名")
(3)class name 相当于样式容易重复find_element(By.CLASS_NAME, "class名)"
(4)link text 有时候不是一个输入框也不是一个按钮,而是一个文字链接,例如百度搜索界面左上角的新闻,可能重复。find_element(By.LINK_TEXT, "link_text名称")
(5)partial link text 部分链接定位,链接的部分名称,会有重复的可能。find_element(By.PARTIAL_LINK_TEXT, "名称")
(6)tag name 标签(很多),类似<div模块,<a,<link,<span,<input,非常容易重复。find_element(By.TAG_NAME, "input") find_element(By.TAG_NAME, "名称") find_element(By.TAG_NAME, "标签")
(7)xpath 全局唯一
获取xpath:右击鼠标-检查,定位到元素,在弹出的elements选中的地方鼠标右击-copy-copyxpath
xpath格式注意事项:双引号之间有双引号的时候,把里面的双引号改成单引号。
//* 省略了前面的路径find_element(By.XPATH, "名称")
(8)css selector 元素样式
获取css selector:右击鼠标-检查,定位到元素,在弹出的elements选中的地方鼠标右击-copy-copyselectorfind_element(By.CSS_SELECTOR, "名称")
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# id定位
# <input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
driver.find_element(By.ID,"toolbar-search-input")
# driver.find_element_by_id
# name 定位
# <meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">
driver.find_element(By.NAME,"keywords")
# driver.find_element_by_name
# class 定位
# <div class="toolbar-search-container">
driver.find_element(By.CLASS_NAME,"toolbar-search-container")
27.举例Selenium邓紫棋
from selenium import webdriver #获得浏览器驱动
import time
from selenium.webdriver.common.by import By
#获得谷歌浏览器驱动,注意一定要大写浏览器名称
driver=webdriver.Chrome()
#输入要打开的网址
url="https://www.baidu.com/"
driver.get(url)
time.sleep(3)
#用id来定位百度搜索框,定位一个是element,定位多个是elements
#kw和su都是名字,框中输入名字,点击百度一下
#driver.find_elements_by_id("kw").send_keys("邓紫棋")写法已经被弃用
driver.find_element(By.ID, "kw").send_keys("邓紫棋")
time.sleep(3)
driver.find_element(By.ID, "su").click()
#太快看不到添加sleep
time.sleep(3)
# 滑到底部
js_buttom = 'document.documentElement.scrollTop=100000'
driver.execute_script(js_buttom)
time.sleep(2)
# 获取下一页的按钮
next = driver.find_element(By.XPATH,"//a[@class='n']")
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
driver.back()
time.sleep(3)
#quit在关闭的同时还能进行清理,close只是关闭
driver.quit()
28.Selenium 其他操作
元素定位好之后进行
(1)click 点击对象
click()
#点击百度一下
driver.find_element(By.ID, "su").click()
(2)send_keys 在对象上模拟按键输入
send_keys(" 要输入的内容")
#搜索框中输入邓紫棋
driver.find_element(By.ID, "kw").send_keys("邓紫棋")
(3)clear 清除对象的内容
clear()
#清除搜索框中的内容
driver.find_element(By.ID, "kw").clear()
(4)submit 提交表单
如果出现type=“submit”的情况submit 可以替换click操作,效果一样。
.submit()
#点击百度一下
driver.find_element(By.ID, "su").submit()
(5)text 用于获取元素的文本信息
.text
#获取百度界面上的信息(之后用print打印出来)
text=driver.find_element(By.ID, "s-top-left").text
浏览器的操作
(1)浏览器最大化
maximize_window()
driver.maximize_window()
(1)设置浏览器宽、高
set_window_size(宽,高)
driver.set_window_size(600,600)
(1)操作浏览器的前进、后退
#后退
back()
driver.back()
#前进
forward()
driver.forward()
(4)控制浏览器滚动条
用js语言,数值为0滚动条往顶端拉,数值越大滚动条往下端拉。
js1="var q=documentElement.Scro1lTop=数值"
#滚动条往顶端拉
js1="var q=documentElement.Scro1lTop=0"
#滚动条往下拉
js1="var q=documentElement.Scro1lTop=10000"
#执行操作
driver.execute_script(js1)
6.键盘事件
以一些常用键举例
(1)enter键
from selenium.webdriver import Keys
send_keys(Keys.ENTER)
以禅道的登录为例
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
#导入键盘包
from selenium.webdriver import Keys
driver = webdriver.Chrome()
time.sleep(3)
url = "复制禅道登录界面的地址"
driver.get(url)
#浏览器最大化
driver.maximize_window()
#输入自己的用户名和密码,输完密码后在密码框中点击enter键登录
driver.find_element(By.ID, "account").send_keys("用户名")
driver.find_element(By.NAME, "password").send_keys("密码")
driver.find_element(By.NAME, "password").send_keys(Keys.ENTER)
time.sleep(6)
driver.quit()
(2)Tab键
切换焦点
from selenium.webdriver import Keys
send_keys(Keys.TAB)
from selenium import webdriver
import time
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
time.sleep(3)
url = "输入自己的禅道登录的地址"
driver.get(url)
driver.maximize_window()
#把光标从登录框切换到密码框
driver.find_element(By.ID, "account").send_keys("admin")
driver.find_element(By.ID, "account").send_keys(Keys.TAB)
time.sleep(6)
driver.quit()
(3)键盘组合用法
#ctrl+a 全选输入框内容
send_keys(Keys.CONTROL,'a')
#ctrl+x 剪切输入框内容
send_keys(Keys.CONTROL,'x')
7.鼠标事件
模拟鼠标
(1)常用鼠标事件
from selenium.webdriver import Keys, ActionChains
#右击
.context_click()
#双击
double_click()
#拖动
drag_and_drop()
#移动,把鼠标移动到相应位置
move_to_element()
(2)举例
#导包
from selenium.webdriver import Keys, ActionChains
#假设已经处于禅道登录界面,输入用户名
su=driver.find_element(By.ID, "account").send_keys("admin")
#ActionChains首先要知道要操作的是哪个浏览器
#右击登录输入框
#perform执行
ActionChains(driver).context_click(su).perform()
29.selenium-phantomjs
由于phantomjs已经被很多公司淘汰不再使用,所以这里不做赘述
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Phantomjs()
driver.get('http://www.baidu.com')
print(driver.page_source.encode("utf-8"))
driver.quit()
# 已经弃用
30.selenium-handless
Chrome Headless是一个无界面的浏览器环境,它是Google Chrome浏览器在59版本之后新增的一种运行模式。与传统的浏览器不同,Chrome Headless可以在后台执行网页操作,而无需显示可见的用户界面。
Chrome Headless提供了一种方便的方式来进行自动化测试、网络爬虫和数据抓取等任务。它通过模拟用户在浏览器中的行为,实现了对网页的自动化操作和交互。在执行过程中,Chrome Headless可以访问和操纵网页的DOM结构、执行JavaScript代码、提交表单、点击按钮等。
由于没有可见的界面,Chrome Headless相比传统浏览器具有一些优势。首先,它更轻量级,节省了系统资源,并且执行速度更快。其次,它稳定性高,不受弹窗、广告或其他干扰因素的影响。此外,Chrome Headless还提供了丰富的调试工具和API,方便开发者进行调试和监控。
使用Selenium框架结合Chrome Headless可以实现自动化测试和网页爬虫等应用场景。开发人员可以利用Selenium的API来编写脚本,控制Chrome Headless执行各种操作,并获取网页内容和处理结果。
# from selenium import webdriver
# from selenium.webdriver.chrome.options import Options
# chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
# path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
# chrome_options.binary_location = path
# browser = webdriver.Chrome(options = chrome_options)
# url = 'https://www.baidu.com'
# browser.get(url)
# 封装
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path是Google浏览器的位置
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(options = chrome_options)
return browser
browser = share_browser()
url = 'https://www.baidu.com'
31.request基本使用
request类似于urllib,但是request是python中独有的库,能用更简短的代码写出和urllib同样的效果,request中有一个类型和六个属性,和urllib是相似的
import requests
url = 'https://www.baidu.com'
responce = requests.get(url = url)
# 一个类型和六个属性
# responce类型
print(type(responce))
# 设置编码格式
responce.encoding = 'utf-8'
# 以字符串的形式返回了网页源码
print(responce.text)
# 返回一个url地址
print(responce.url)
# 返回的是二进制的数据
print(responce.content)
# 返回相应的状态码
print(responce.status_code)
# 返回的是响应头
print(responce.headers)
request中的get请求
首先分析一下urllib和request的区别,然后我们在request中只需要
responce = requests.get(url = url,params=data,headers=headers)
content = responce.text
这两行代码就可以搞定,还是很便捷的。再传入时,在get中有一个param参数,是可以传入输入参数的。
# urllib
# (1)一个类型和六个方法
# (2)get请求
# (3)post请求,百度翻译
# (4)ajax 的 post请求
# (5)ajax 的 post请求
# (6)cookie登录 微博
# (7)代理
# request
# (1)一个类型和六个属性
# (2)get请求
# (3)post请求
# (4)代理
# (5)cookie验证码
import requests
# 问号也可以不加
url = 'https://www.baidu.com/s?'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
data = {
'wd' : '北京'
}
# url叫做请求资源路径,params叫做参数,kwargs是字典
responce = requests.get(url = url,params=data,headers=headers)
content = responce.text
print(content)
# 参数无需urlencode编码
# 参数需要params传递
# 不需要请求对象定制
32.request中的post请求
在request中post请求中,我们还是据百度翻译的例子,这次post请求中的data也是传入的参数,由于content返回的是字符串类型,我们通过json编码为字典,这样我们就可以看懂了。
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
'cookie' :
'BAIDUID_BFESS=7AD549AF735289E0C107221311EA1BE0:FG=1; BIDUPSID=7AD549AF735289E0C107221311EA1BE0; PSTM=1722243178; ZFY=:Aw39gqGc9br6vsj:BXTHad0qWcTvm9FKwjHVw648DZCg:C; BA_HECTOR=01040k8ga405052l0405a12l9ostdu1jajvkn1u; BDRCVFR[V3EOV_cRy1C]=mk3SLVN4HKm; H_PS_PSSID=60453_60470_60492_60500_60519_60552_60566_60554; delPer=0; PSINO=1; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; ab_sr=1.0.1_NTU5NjJiZTkxMGQ4YWM4YzkzODU2YzIwMGE1MmIxNTg3MDc5ODIxZGI2YWY4NDY1YmZlOWY2ZmNjNjc2MjdmZTdmMTRkMjdkZjJkZGM3MjBhZDI5MWM0NzMzODVkYjkwYzZiNTcxNDk3YjZjZjQ3NmYyNDE1OWNkYzU3NzBjODg5NWNjYWM3YzY3ZTcyMGQxMTgzY2QwMTI5ZDRmZTZiZQ==; RT="z=1&dm=baidu.com&si=24cae920-18e9-4b5b-8bb3-c1f662e67412&ss=lz9u6d1w&sl=1&tt=l0&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=1d0"'
}
data = {
'kw' : 'eye'
}
# url请求地址,data请求参数,kwargs字典
responce = requests.post(url = url,headers=headers,data=data)
content = responce.text
import json
obj = json.loads(content)
print(obj)
33.request_代理
这个也就是多个ip传入防止被查封,只要把proxy代理ip传入就可以了
import requests
url = 'https://www.baidu.com/s?'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
data = {
'wd' : 'ip'
}
proxy = {
'https' : '121.230.210.31:3256'
}
responce = requests.get(url = url,params=data,headers=headers,proxies=proxy)
content = responce.text
with open('daili2.html','w',encoding = 'utf-8') as fp:
fp.write(content)
34.request免验证登录古诗词网
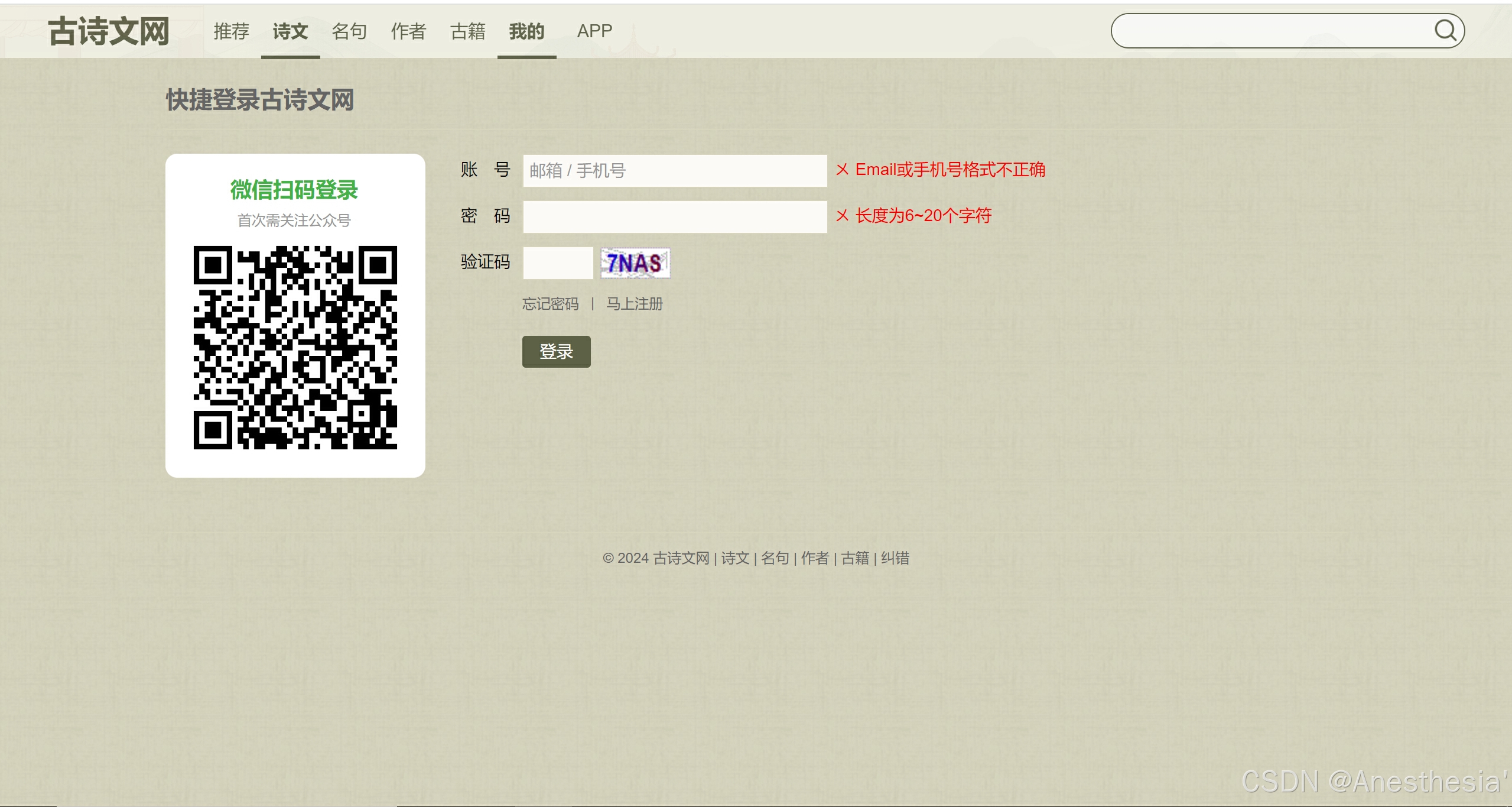
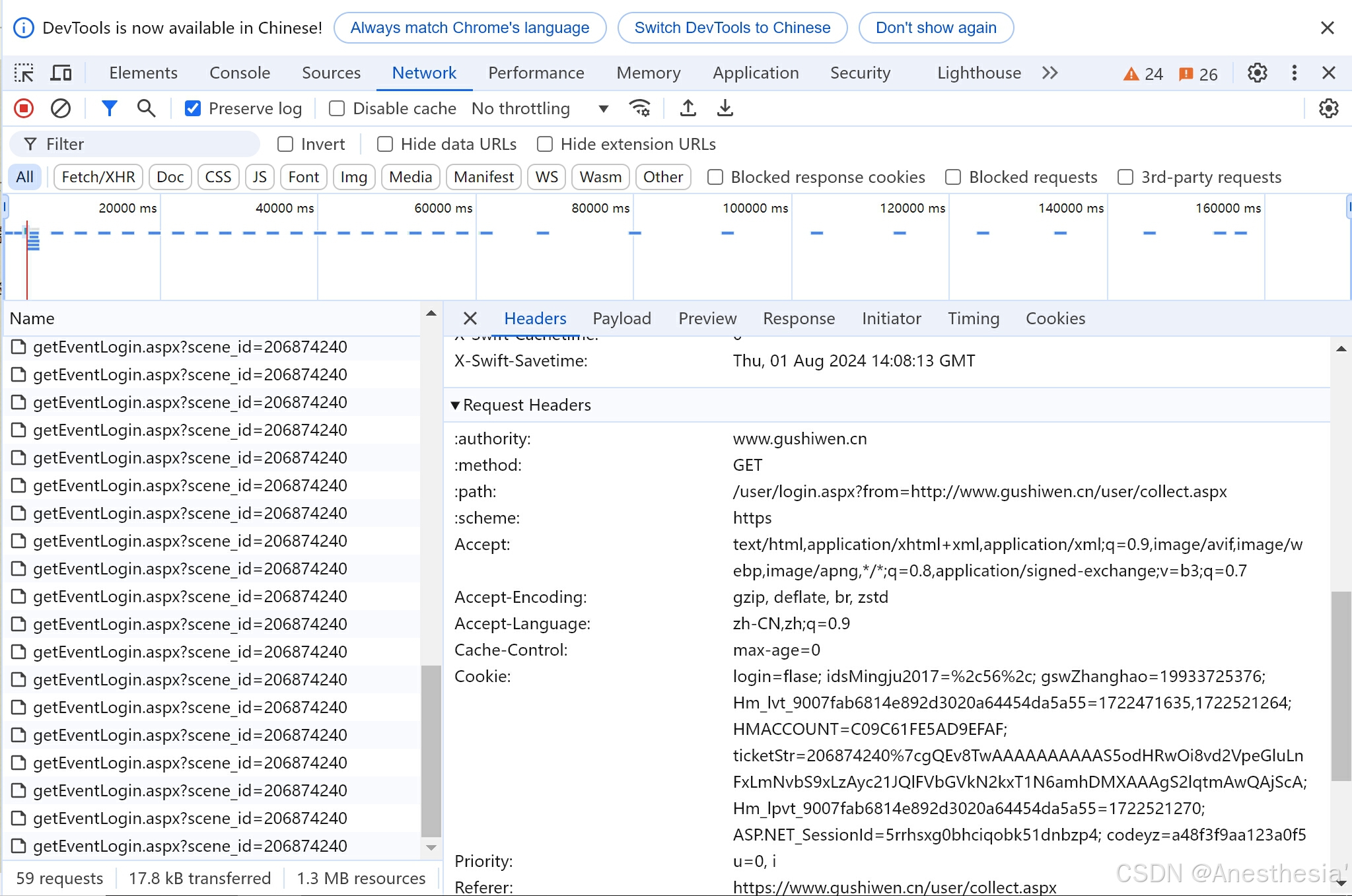
在这其中我们也不知道那些数据是有用的,所以我们先观察:
在这些数据中由两个我们没有找到的# __VIEWSTATE: vmkHKKt/kQxZnU3DdbFiulx/YaTER7m22csaKd4SZSS8an8DiKnioUZXZti28v5Kj7ouFNngtqLop5buxudkBNq5I+0NvucbIfDZjyUxRs5l5Iv7EY/tkDhCR0Ez21N/6JCIXHwPhAy055YerBP/kY98yi8= __VIEWSTATEGENERATOR: C93BE1AE,这时我们在源码中找到:
这里显示这两个Hidden的数据,说明这两个我们是无法查看的,之后我们用request获取网页源码,并用bs4来获取这两个数据,之后我们又在登录页面找到了验证码的相关图片,我们把它下载下来,通过session的工具来表示我们这两次登录(我们下一次还要登陆),是相同的,然后利用ddddocr 来读取图片中的信息,

import ddddocr # 导入 ddddocr
ocr = ddddocr.DdddOcr(show_ad=False) # 实例化
with open('code.jpg', 'rb') as f: # 打开图片
img_bytes = f.read() # 读取图片
res = ocr.classification(img_bytes) # 识别
这样我们就可以获取到所有的信息了,之后通过data传入后我们就可以登录进页面了。
# 古诗词网
# 通过登录然后进入到主页面
# 通过找登录接口发现登录的时候需要的参数很多
# __VIEWSTATE: vmkHKKt/kQxZnU3DdbFiulx/YaTER7m22csaKd4SZSS8an8DiKnioUZXZti28v5Kj7ouFNngtqLop5buxudkBNq5I+0NvucbIfDZjyUxRs5l5Iv7EY/tkDhCR0Ez21N/6JCIXHwPhAy055YerBP/kY98yi8=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://www.gushiwen.cn/user/collect.aspx
# email: 19933725376
# pwd: jijiji
# code: ZVMZ
# denglu: 登录
# 我们观察到__VIEWSTATE,__VIEWSTATEGENERATOR,不认识
# code是一个变化的量
# 难点(1):__VIEWSTATE,__VIEWSTATEGENERATOR
# 通过源码可以知道我们找到了这两个值,所以只要我们获取源码,再解析就可以了
# 难点(2):验证码
import requests
# 登录页面
url = 'https://www.gushiwen.cn/user/login.aspx?from=http://www.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
# 获取页面源码
responce = requests.get(url = url,headers=headers)
content = responce.text
# 解析页面源码,然后获取__VIEWSTATE,__VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取__VIEWSTATE
viewstate = soup.select("#__VIEWSTATE")[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# session()方法 使请求对象变成一个对象
session = requests.session()
responce_code = session.get(code_url)
# 注意此时要使用二进制数据
content_code = responce_code.content
# wb的模式就是将二进制数据写入文件
with open('code.jpg','wb')as fp:
fp.write(content_code)
# 把图片下载到本地之后,观察验证码
import ddddocr # 导入 ddddocr
ocr = ddddocr.DdddOcr(show_ad=False) # 实例化
with open('code.jpg', 'rb') as f: # 打开图片
img_bytes = f.read() # 读取图片
res = ocr.classification(img_bytes) # 识别
# 点击登录
url_post = 'https://www.gushiwen.cn/user/login.aspx?from=http://www.gushiwen.cn/user/collect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR':viewstategenerator,
'from': 'http://www.gushiwen.cn/user/collect.aspx',
'email': '19933725376',
'pwd': 'Ylp197419',
'code': res,
'denglu': '登录'
}
responce_post = session.post(url = url,headers=headers,data=data_post)
content_post = responce_post.text
with open('gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(content_post)
35.scrapy基本使用
scrapy项目的建立
1.创建爬虫的项目 scrapy startproject 项目的名字
注意:项目的名字不允许使用数字开头 也不能包含中文
2.创建爬虫文件:
要在spider文件夹中去创建爬虫文件
cd 项目的名字\项目的名字\spiders
cd scrapy_baidu_001\scrapy_baidu_001\spiders
创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取的网页
eg : scrapy genspider baidu www.baidu.com
一般不需要添加https://
因为文件中自动添加https://
3.运行爬虫代码
scrapy crawl 爬虫的名字
eg: scrapy crawl baidu
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于使用爬虫的时候使用的值
name = "baidu"
# 允许访问的域名
allowed_domains = ["www.baidu.com"]
# 起始的url地址 指的是第一次访问的域名 也就是在allowed_domains的前面加了https://
start_urls = ["https://www.baidu.com"]
# 运行start_urls之后执行的方法,方法中的responce就是返回的对象
# 相当于responce = urllib.request.urlopen()
# 也相当于responce = requests.get()
def parse(self, response):
print("苍茫的天涯是我的爱")
36.58同城实例
1.scrapy项目的结构
项目名字
项目名字
spiders文件夹(存储的是爬出文件)
init
自定义的爬虫文件
init
items 定义数据结构的地方,爬取的内容都包含哪些
middlewares 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 一般robot协议,ua定义等
2.responce的属性和方法
responce.text 获取相应的字符串
responce.body 获取的是二进制数据
responce.xpath(’ 这里写xpath路径 ') 直接用xpath方法来解析responce中的内容
responce.extract() 提取seletor对象的data属性值
responce.extract_first() 提取列表的第一个数据
import scrapy
class TcSpider(scrapy.Spider):
name = "tc"
allowed_domains = ["cangzhou.58.com"]
start_urls = ["https://cangzhou.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91"]
def parse(self, response):
content = response.text
print("====================")
print(content)
37.汽车之家
import scrapy
class CarSpider(scrapy.Spider):
name = "car"
allowed_domains = ["car.autohome.com.cn"]
# 后面是html时,后面不能加/
start_urls = ["https://car.autohome.com.cn/price/brand-15.html"]
def parse(self, response):
name_list = response.xpath('//div[@class = "main-title"]/a/text()')
price_list = response.xpath('//div[@class = "main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i]
price = price_list[i]
print(name,price)
BOT_NAME = "scrapy_carhome_003"
SPIDER_MODULES = ["scrapy_carhome_003.spiders"]
NEWSPIDER_MODULE = "scrapy_carhome_003.spiders"
38.当当网
当当网爬取书名,图片和价格
import scrapy
from scrapy_dangdang_004.items import ScrapyDangdang004Item
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["https://category.dangdang.com/cp01.01.02.00.00.00.html"]
base_url = 'https://category.dangdang.com/pg'
page = 1
def parse(self, response):
# pipeline 下载数据
# item 定义数据结构
# src = '//ul[@id="component_59"]/li//img/@data-original'
# alt = '//ul[@id="component_59"]/li//img/@alt'
# price = '//ul[@id="component_59"]/li//p[@class = "price"]/span[1]/text()'
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
# 第一张图片和其他的不一样
src = li.xpath('.//img/@data-original').extract_first()
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class = "price"]/span[1]/text()').extract_first()
book = ScrapyDangdang004Item(src = src,name = name ,price=price)
# yield就是返回一个值,有一个book就交给pipelines
yield book
# 每一页的爬取的业务逻辑都是一样的,所以我们只需要将执行的那个页面的请求再次调用parse方法就可以了
if self.page < 100:
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# 怎么去调用parse方法
# scrapy.Request就是scrapy的get请求
# url就是请求地址,callback就是你要执行的那个函数,parse不允许加圆括号
yield scrapy.Request(url = url,callback=self.parse)
items:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdang004Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 通俗的说就是你要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
pipelines:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想使用管道的话,就必须在settings中开启管道
class ScrapyDangdang004Pipeline:
# 在爬虫文件执行之前就执行
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# items 就是yield 后面的 book 对象
def process_item(self, item, spider):
# with open('book.json','a',encoding='utf-8') as fp:
# write方法必须要写一个字符串,而不能是其他的对象
# w模式会每一个对象都打开一次文件,之后覆盖之前的数据
# fp.write(str(item))
self.fp.write(str(item))
return item
# 在爬虫文件结束之后执行的方法
def close_spider(self,spider):
self.fp.close()
import urllib.request
# 多条管道同时下载
# 定义管道类
# 在settings中开启管道
# "scrapy_dangdang_004.pipelines.DangDangDownload":301
class DangDangDownload:
def process_item(self, item, spider):
url = 'https:'+ item.get('src')
filename = './books/' + item.get('name')
urllib.request.urlretrieve(url = url,filename=filename)
return item
settings:
BOT_NAME = "scrapy_dangdang_004"
SPIDER_MODULES = ["scrapy_dangdang_004.spiders"]
NEWSPIDER_MODULE = "scrapy_dangdang_004.spiders"
ITEM_PIPELINES = {
# 管道可以有很多个,管道是有优先级的,优先级是1到1000,值越小优先级越高
"scrapy_dangdang_004.pipelines.ScrapyDangdang004Pipeline": 300,
"scrapy_dangdang_004.pipelines.DangDangDownload":301
}
39.电影天堂
import scrapy
from scrapy_movie_099.items import ScrapyMovie099Pipeline
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dytt8.net"]
start_urls = ["https://www.dytt8.net/html/gndy/china/index.html"]
def parse(self, response):
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二页的地址
url = 'https://www.dytt8.net' + href
yield scrapy.Request(url = url,callback=self.parse_second,meta = {'name' : name})
def parse_second(self,responce):
# 注意:如果拿不到数据,一定要检查xpath语法是否正确
src = responce.xpath('//div[@id = "Zoom"]//img/@src').extract_first()
name = responce.meta['name']
movie = ScrapyMovie099Pipeline(src = src,name=name)
yield movie
piplines:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyMovie099Pipeline:
def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
40.crawlspider
CrawlSpider
Spider是爬虫文件中爬虫类的父类,CrawlSpider是它的子类。多被用作于专业实现全站数据爬取,将一个页面下所有页码对应的数据进行爬取。
创建项目
创建scrapy工程: scrapy startproject ProjectName
进入工程:cd ProjectName
创建crawlspider项目:scrapy genspider -t crawl SpiderName www.xxx.com
回顾 创建普通爬虫项目:scrapy genspider SpiderName www.xxx.com
crawlspider默认生成的内容
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class FutureSpider(CrawlSpider):
name = 'future'
allowed_domains = ['www.xxx.com/']
start_urls = ['https://www.xxx.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
crawlspider中没有parse函数
LinkExtractors 链接提取器
链接提取器:根据指定规则(参数:allow = ‘正则’ 提取链接的规则)在页面中进行链接(URL)的提取。每个LinkExtractors有唯一的公共方法extract_links(),它接收一个Response对象,并返回一个scrapy.link.Link对象。链接提取器,要实例化一次和extract_links方法会根据不同的响应调用多次提取链接。
常用参数
以下都包含str or list
allow:allow = ‘re’,满足括号中正则的值会被提取,如果为空(allow = r’')则会全部匹配,提取所有
deny:URL必须匹配才能被排除(即,未提取)的单个正则表达式(或正则表达式列表)。它优先于allow参数。如果未给出(或为空),则不会排除任何链接。
allow_domains:该domains(URL范围)会被提取的,如[‘www.baidu.com’,‘www.sogou.com’]
deny_domains:该domains(URL范围)不会被提取的
strict_xpaths:是一个XPath(或XPath的列表),和allow共同过滤URL,只有xpath满足的范围内的URL会被提取
rules(Rule 规则解析器)
接收链接提取器提取到的所有链接,对其发送请求,并根据指定规则(callback)解析数据。rules中可以有1个或多个Rule对象,每个Rule定制特定操作,如有重复,则按序使用。
常用参数
rules是一个元组或列表,包含Rule参数
LinkExtractor:链接提取器,通过正则或xpath进行页面URL匹配
callback:通过LinkExtractor提取的URL返回的响应数据的回调函数,没有则表示不会对响应数据进行回调函数的处理
follow:LinkExtractor提取的URL对应的响应数据是否还会继续被rules中的规则进行提取
That’s all.
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python爬虫

发表评论 取消回复