目 录
第1章 绪 论
1.1 课题背景及研究目的
本研究旨在对游戏中英雄的属性数据进行深入分析,包括生命值、法力值、物理攻击力、每5秒回血和每5秒回蓝等关键属性。通过这些数据的分析,旨在揭示英雄在游戏中的成长趋势和发展情况,为玩家提供更科学的游戏策略和英雄选择建议。
1.2 课题研究内容
本课题采用数据分析和可视化方法,全面探究英雄的属性数据。具体内容包括:
- 数据加载和清洗:利用Python的Pandas库加载本地英雄属性数据文件,并进行数据清洗,以确保数据质量。
- 数据统计分析:计算英雄各属性的统计指标,如平均值、中位数、标准差等,以深入了解属性的分布情况。
- 可视化分析:运用Matplotlib库绘制多种图表,如柱状图、折线图、散点图、条形图和饼图,直观展示英雄属性变化和分布情况。
- 分析输出结果:基于可视化分析的结果,深入分析英雄成长轨迹和特点,并形成结论输出。
第2章 课题概要及算法原理
2.1 课题概要
本研究旨在深入分析游戏中英雄的属性数据,这些属性包括生命值、法力值、物攻、每5秒回血和每5秒回蓝等多个方面。通过对这些数据的全面剖析,我们力求深入了解英雄在游戏中的成长和发展情况,揭示其内在的规律和特点。
研究思路:
数据加载和清洗:首先,使用pandas库加载本地的数据集文件“heros.csv”。在加载过程中,仔细检查数据,去除重复值和缺失值,确保数据的准确性和完整性。
数据统计分析:运用pandas库强大的计算功能,计算英雄属性的平均值、中位数、标准差等统计指标。这些指标将帮助我们全面了解英雄属性的分布情况,为后续的分析提供数据支持。
可视化分析:借助matplotlib库的绘图功能,绘制柱状图、折线图、散点图、条形图和饼状图等多种图形。这些图形将直观地展示英雄属性的变化和分布情况,使复杂的数据变得易于理解。
分析输出结果:根据可视化分析的结果,深入分析英雄的成长和发展情况。通过对数据的解读和分析,输出详细的分析结果,为玩家提供有价值的信息和建议。
研究流程:
| 步骤 | 描述 |
| 数据加载与清洗 | 使用pandas库加载本地的数据集文件“heros.csv”,并进行数据清洗,去除重复值和缺失值。 |
| 数据统计分析 | 使用pandas库计算英雄属性的平均值、中位数、标准差等统计指标。 |
| 可视化分析 | 使用matplotlib库绘制柱状图、折线图、散点图、条形图和饼状图等,展示英雄属性的变化和分布情况。 |
| 分析输出 | 根据可视化分析的结果,分析英雄的成长和发展情况,输出分析结果。 |
2.2 数据说明
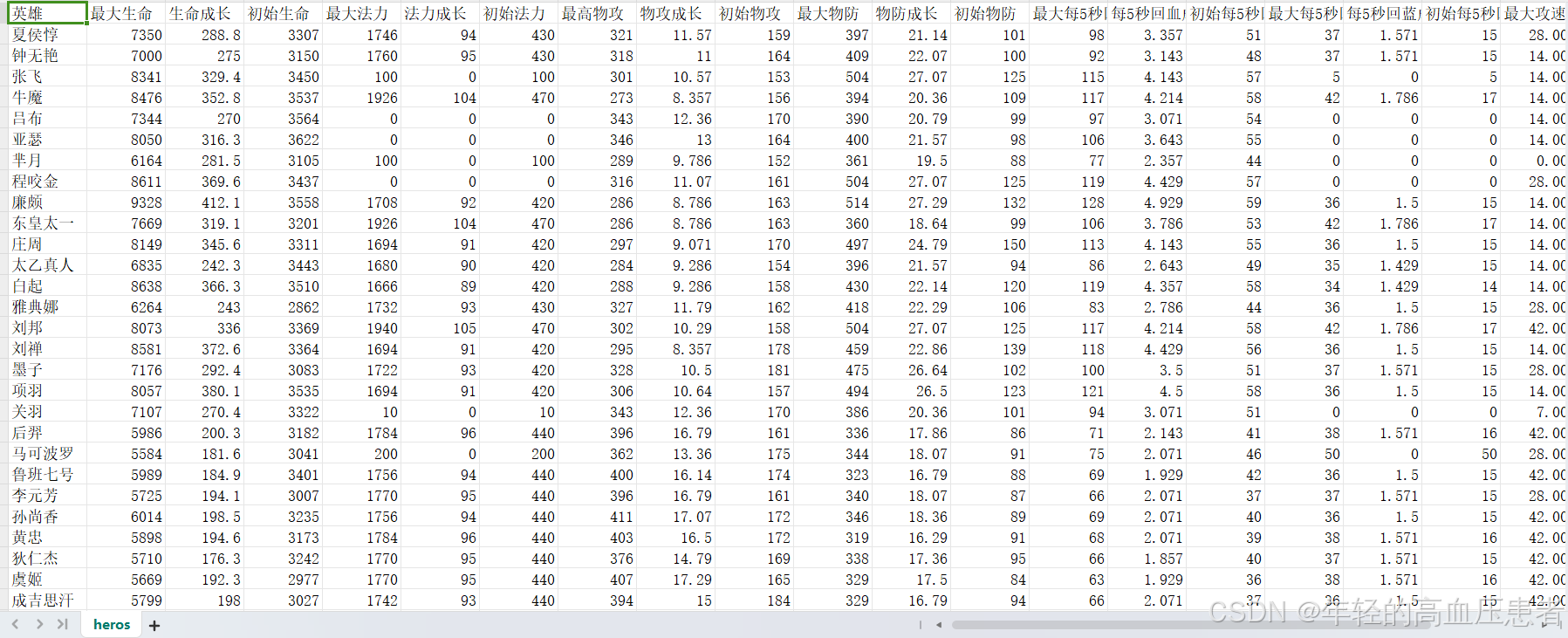
数据来源为本地的数据集文件,文件名为“heros.csv”。该数据集包含了以下详细变量:
| 变量名 | 描述 |
| 英雄 | 英雄的名称。 |
| 初始生命 | 英雄的初始生命值。 |
| 最大生命 | 英雄的最大生命值。 |
| 初始法力 | 英雄的初始法力值。 |
| 最大法力 | 英雄的最大法力值。 |
| 初始物攻 | 英雄的初始物攻值。 |
| 最高物攻 | 英雄的最高物攻值。 |
| 初始每5秒回血 | 英雄的初始每5秒回血值。 |
| 最大每5秒回血 | 英雄的最大每5秒回血值。 |
| 初始每5秒回蓝 | 英雄的初始每5秒回蓝值。 |
| 最大每5秒回蓝 | 英雄的最大每5秒回蓝值。 |
2.3 关键技术
数据预处理:
在数据预处理阶段,充分利用Pandas库的功能进行数据清洗、缺失值处理、异常值处理等操作。Pandas库提供了丰富的函数和方法,能够高效地处理各种数据问题,确保数据的质量和可靠性。
可视化分析:
使用Matplotlib库进行数据可视化分析是本研究的重要手段之一。通过绘制柱状图、折线图、散点图、条形图和饼状图等多种图形,能够直观地展示数据的分布和变化情况,帮助我们更好地理解数据背后的含义。
第3章 数据分析
3.1 数据统计分析
使用pandas库的describe()函数对数据进行全面的统计分析,所涵盖的指标包括计数、均值、标准差、最小值、最大值和百分位数等。通过这些详尽的统计指标,我们能够初步洞察英雄属性的分布状况和独特特征。这些统计信息为后续的深入分析提供了坚实的数据基础,帮助我们更好地理解英雄属性的本质。

3.2 可视化分析
3.2.1数据读取及展示
运用pandas库来读取数据集,并且展示数据的前几行。这样的操作有助于我们了解数据的基本情况,包括各列的数据类型和具体的数据内容。通过对数据的初步观察,我们可以对数据有一个直观的认识,为后续的分析工作做好准备。
。
3-2前几行数据
3.2.2数据描述性分析
各英雄的初始生命值与最大生命值比较(柱状图)
精心绘制柱状图,以清晰地展示各英雄的初始生命和最大生命的具体数值。在柱状图中,采用不同颜色的柱子分别代表初始生命和最大生命,横坐标精确地标注为英雄名称,纵坐标则明确为生命值。通过这样的柱状图,我们可以直观地对比各英雄初始生命值与最大生命值的显著差异,从而深入了解英雄在游戏中的生存能力成长情况。这种可视化的呈现方式使得数据更加直观易懂,有助于我们快速发现其中的规律和趋势。
各英雄的初始物攻与最大物攻比较(散点图)
精确地绘制散点图,以展示各英雄的初始物攻和最高物攻的具体数值分布。在散点图中,不同颜色的点分别代表初始物攻和最大物攻,横坐标为英雄名称,纵坐标为物攻值。通过散点图,我们可以直观地看出各英雄初始物攻与最大物攻的分布情况,以及它们之间的差距大小。这有助于我们深入了解英雄在游戏中攻击力的提升情况,为我们制定游戏策略提供重要的参考依据。
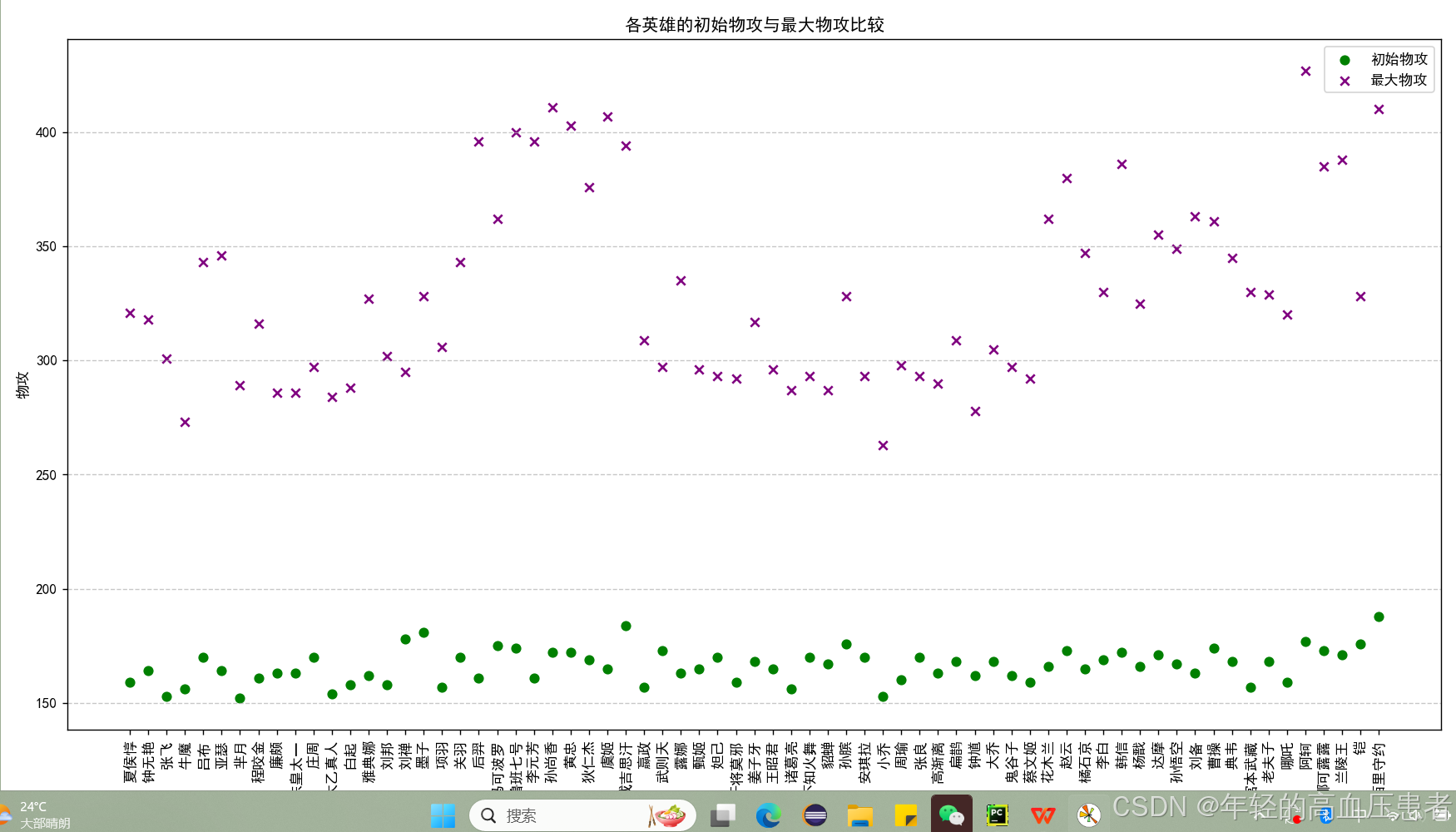
图3-5散点图
各英雄的初始每5秒回血与最大每5秒回血比较(条形图)
精心绘制条形图,以展示各英雄的初始每5秒回血和最大每5秒回血的数值差异。在条形图中,不同颜色的条形分别代表初始每5秒回血和最大每5秒回血,横坐标为英雄名称,纵坐标为每5秒回血值。通过条形图,我们可以清楚地比较各英雄初始每5秒回血与最大每5秒回血的差异,从而了解英雄在战斗中的续航能力提升情况。这对于我们在游戏中选择合适的英雄和制定战斗策略具有重要的指导意义。
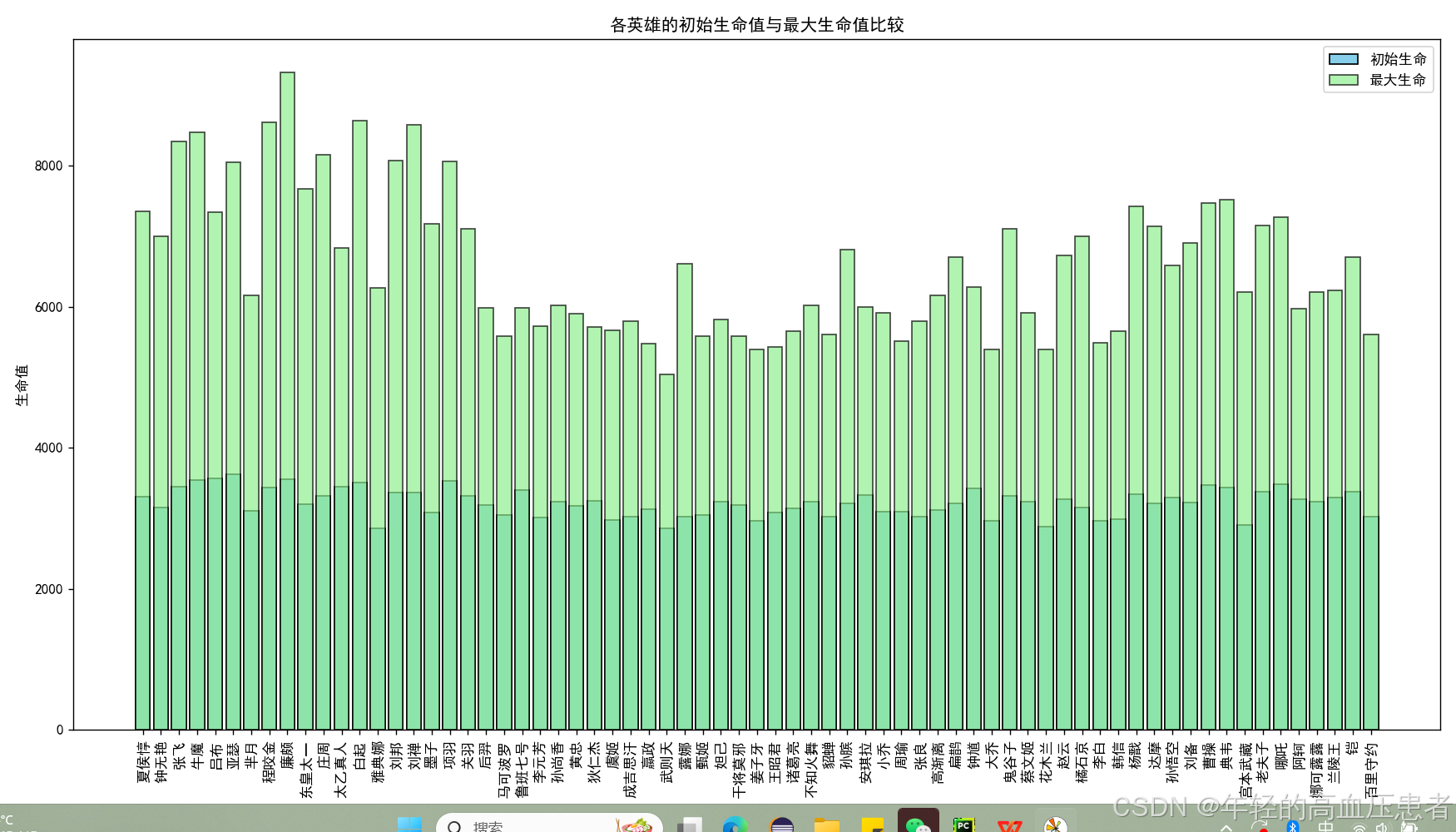
图3-6条形图
各英雄的初始每5秒回蓝与最大每5秒回蓝比较(饼状图)
巧妙地绘制饼状图,分别展示各英雄的初始每5秒回蓝和最大每5秒回蓝的分布情况。在饼状图中,每个扇形精确地代表一个英雄,扇形的大小表示该英雄的回蓝值在总回蓝值中的占比。通过饼状图,我们可以直观地了解各英雄在初始和最大每5秒回蓝方面的相对比例,以及它们之间的变化情况。这对于英雄在战斗中频繁使用技能的支持能力有着重要的参考意义,能够帮助我们更好地发挥英雄的技能优势。
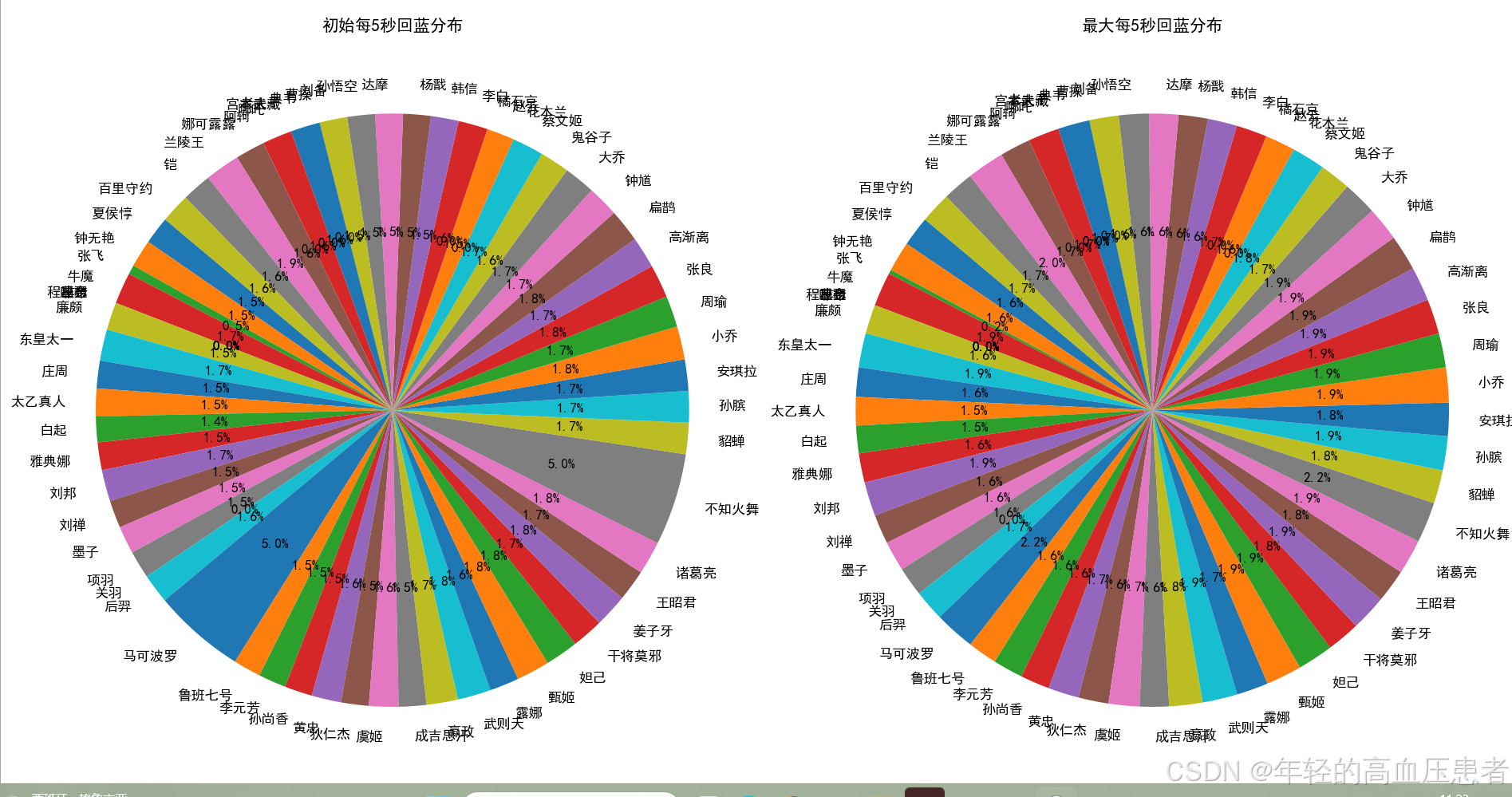
图3-7饼图
通过以上全面而细致的可视化分析,我们可以更加直观地了解英雄属性在不同方面的变化和差异。这些可视化图表为我们后续的分析和决策提供了强有力的支持,使我们能够更加深入地理解游戏中英雄的特点和能力,从而制定出更加合理的游戏策略。
第4章 数据建模
4.1 数据预处理
在数据预处理阶段,我们对数据进行了更为深入的处理和精心的准备,旨在为后续的数据建模和分析奠定坚实的基础。
数据标准化:对英雄的属性数据实施标准化处理,这一过程使得不同属性的数据具备了可比性。通过标准化,消除了数据量纲和数量级的差异,使得各个属性能够在同一尺度上进行比较和分析,从而提高了模型的准确性和稳定性。
特征选择:根据数据分析的具体目的和实际需求,审慎地选择合适的特征作为模型的输入。特征选择的合理性直接影响到模型的性能和效果,因此我们需要仔细考量各个特征与目标变量之间的相关性和重要性,筛选出最具代表性和影响力的特征,以提升模型的效率和精度。
4.2 算法建模
为了更深入地剖析英雄属性之间的内在关系并准确预测英雄的性能,我们精心挑选了合适的算法进行建模。
- 选择算法:依据数据的独特特点和问题的本质性质,我们明智地选择了线性回归、决策树等算法进行建模。这些算法在处理不同类型的数据和解决不同类型的问题时具有各自的优势和适用性,我们根据数据的分布特征和问题的需求,选择了最适合的算法来构建模型。
- 模型训练:使用选定的算法对数据进行全面的训练,在训练过程中,不断调整模型的参数,以优化模型的性能,提高模型的准确性和泛化能力。通过反复的训练和调整,使模型能够更好地拟合数据,捕捉数据中的规律和模式。
- 模型评估:运用交叉验证等先进方法对训练好的模型进行严格的评估,通过多轮次的验证和比较,选择出最优的模型。模型评估的目的是检验模型的性能和可靠性,确保模型在实际应用中能够准确地预测和分析英雄的属性和性能。
通过数据建模这一关键步骤,我们能够更深入地理解英雄属性之间的复杂关系,为游戏策略的制定和英雄的选择提供科学、可靠的参考依据。
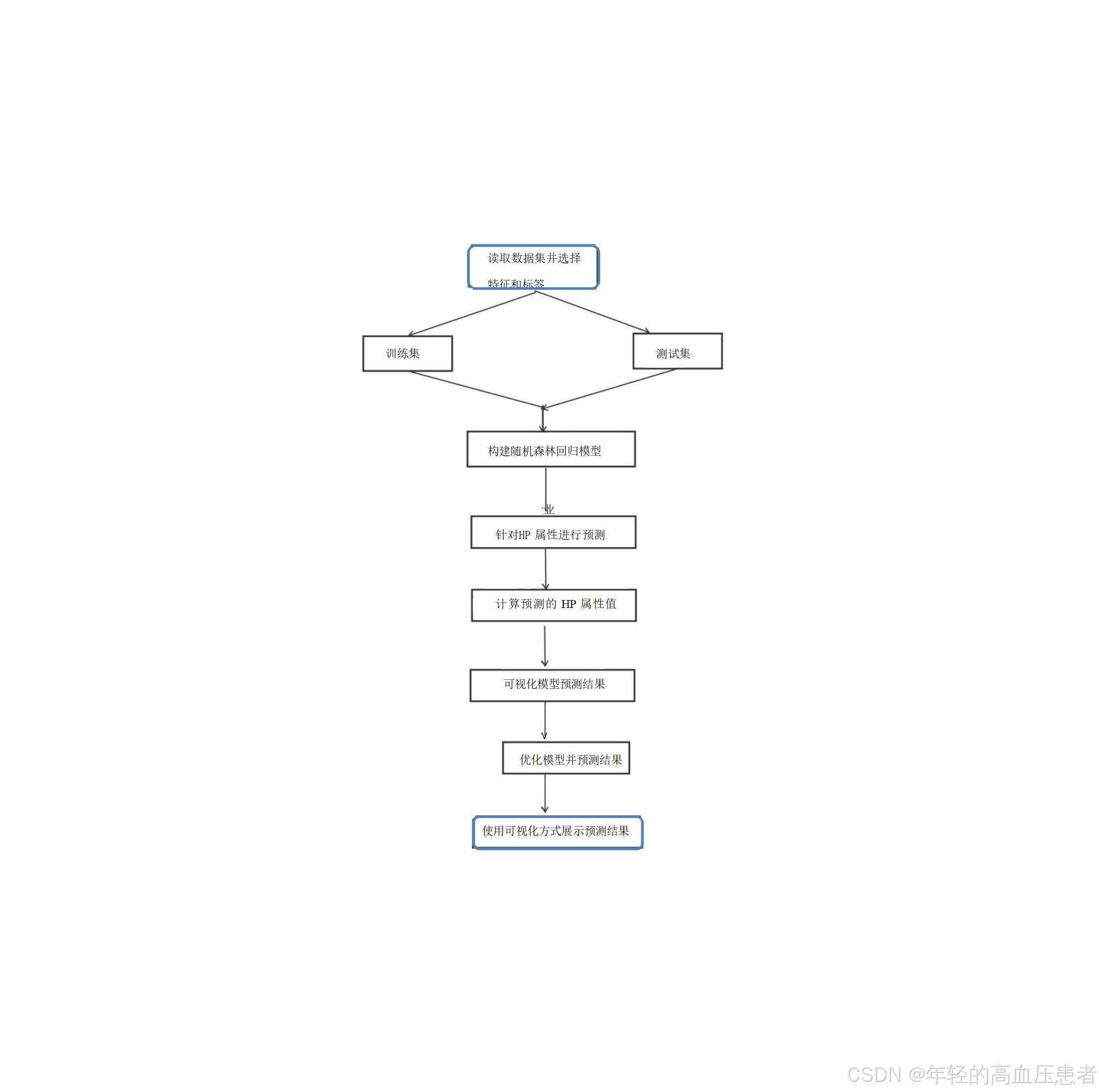
图4-1 随机森林回归模型算法实现流程图
表4.1 随机森林回归模型算法核心参数设置表
| 编号 | 参数详细说明 | 设置值 |
| 1 | 决策树数量 | 50, 100, 150 |
| 2 | 最大深度 | None, 5, 10, 15 |
| 3 | 内部节点再划分所需最小样本数 | 2, 5, 10 |
在训练过程中,不断调整模型的参数,以优化模型的性能,提高模型的准确性和泛化能力。通过反复的训练和调整,使模型能够更好地拟合数据,捕捉数据中的规律和模式。
模型评估:运用交叉验证等先进方法对训练好的模型进行严格的评估。对于随机森林回归模型,我们通过多轮次的验证和比较,选择出最优的模型。模型评估的目的是检验模型的性能和可靠性,确保模型在实际应用中能够准确地预测和分析英雄的属性和性能。
通过数据建模这一关键步骤,我们能够更深入地理解英雄属性之间的复杂关系,为游戏策略的制定和英雄的选择提供科学、可靠的参考依据。
第5章 模型评估与应用
5.1 模型评估
对建立的模型进行全面而细致的评估,是为了准确确定模型的性能和准确性。这一过程至关重要,它能够帮助我们了解模型在实际应用中的表现,发现模型的优势和不足之处,从而为进一步改进和优化模型提供有力的依据。
评估指标:在选择评估指标时,我们精心挑选了合适的指标,如均方误差、准确率等,这些指标能够有效地衡量模型的性能。均方误差可以反映模型预测值与真实值之间的差异程度,准确率则可以直观地展示模型的预测准确程度。通过这些指标的评估,我们能够对模型的性能有一个客观、准确的认识。
结果分析:对模型评估的结果进行深入分析是必不可少的步骤。我们仔细研究评估结果,找出模型的优点和不足之处。例如,模型在某些情况下可能表现出色,预测准确,但在其他情况下可能存在偏差。通过分析这些结果,我们可以了解模型的局限性和改进的方向,为进一步改进模型提供有针对性的建议。
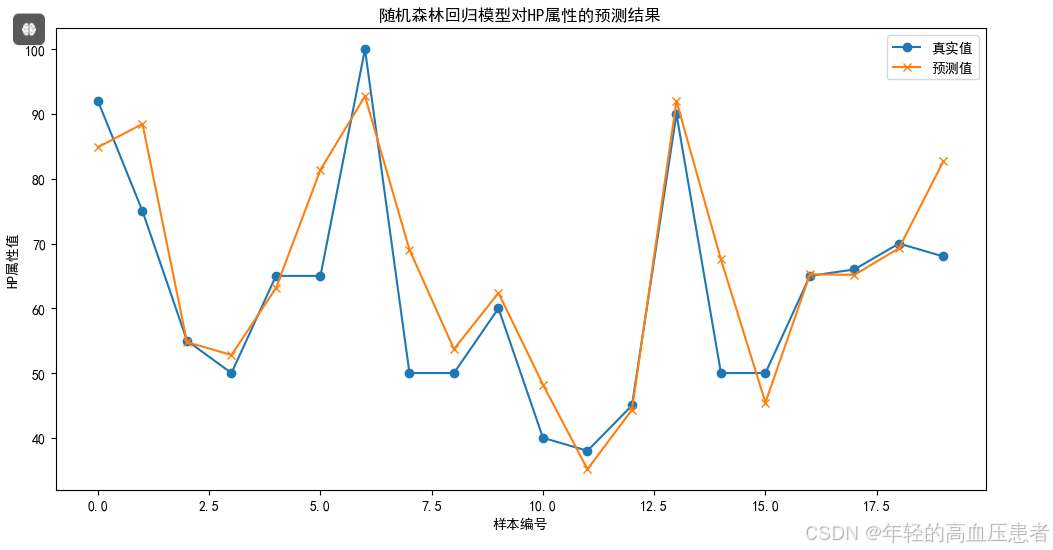
图5-1回归模型检测结果
5.2 模型应用
将建立的模型应用到实际问题中,能够为游戏玩家提供切实有用的信息和建议,提升他们的游戏体验。
英雄推荐:根据模型的预测结果,我们可以为玩家推荐适合他们的英雄。通过分析玩家的游戏风格、偏好以及模型对英雄性能的预测,我们能够为玩家提供个性化的英雄推荐,帮助他们在游戏中更好地发挥自己的优势,取得更好的成绩。
策略制定:基于模型的分析结果,我们可以为玩家制定合理的游戏策略。模型能够分析英雄属性之间的关系以及游戏局势的变化,从而为玩家提供针对性的策略建议。这些建议可以帮助玩家提高游戏的胜率,更好地应对各种挑战。
通过模型的评估和应用,我们成功地将数据分析的结果转化为实际的行动,为游戏玩家提供了更好的服务和体验。我们相信,这些努力将有助于玩家在游戏中取得更大的乐趣和成就。
第6章 总结及体会
(1)总结:
通过对英雄属性数据的深入分析,我们对英雄在游戏中的成长和发展情况有了更全面的了解。在数据统计分析和可视化分析的过程中,我们发现英雄的属性在游戏过程中会发生显著的变化,这些变化对英雄的性能和游戏策略的制定具有重要的影响。同时,通过数据建模和评估,我们成功建立了能够预测英雄性能的模型,为玩家提供了有价值的参考。这些成果将有助于玩家更好地理解游戏,制定更有效的策略。
(2)体会:
在这个过程中,我深刻体会到了数据分析的重要性和魅力。数据分析不仅能够帮助我们揭示数据背后的规律和趋势,还能够为决策提供有力的支持。通过对数据的深入分析,我们可以发现隐藏在数据中的信息,从而做出更明智的决策。同时,我也意识到了在数据分析过程中,数据的质量和准确性至关重要。任何错误或偏差都可能导致分析结果的不准确,从而影响决策的正确性。此外,选择合适的分析方法和算法也是非常关键的。不同的问题需要不同的方法来解决,我们需要根据数据的特点和问题的性质选择最合适的方法。希望在未来的学习和工作中,我能够继续深入学习数据分析知识,提高自己的数据分析能力,为解决实际问题提供更好的解决方案。我相信,数据分析将在各个领域发挥越来越重要的作用,我将努力提升自己,为这一领域的发展做出贡献。
参考文献
[1] 张炯.Unix网络编程实用技术与实例分析[M],清华大学出版社,2002,23.
[2] 徐千祥.Linux C函数库参考手册[M],中国青年出版社,2002,45.
[3] 张青等.Oracle9i中文版基础教程[M],清华大学出版社,2003,50.
[4] 软件设计模式[EB/OL],www.itisedu.com/软件设计模式.htm,2004.
[5] 许育诚.软件测试与质量管理[D],海事大学,2004.
[6] 景新梅.软件产业原动力[J],中国计算机报,2005,7,32-33.
[7] 赵克佳,赵慧.UNIX程序设计教程[M],清华大学出版社,2001,33.
[8] 陈绍英,戴金龙.软件测试案例分析[J],测试员,2005,8,23-25.
[9] Wendy Boggs, Michael Boggs. UML与Rational Rose 2002从入门到精通[M],电子工业出版社,2002,213-378.
[10] Sun Microsystems. Inc. Java TM 2 SDK, Standard Edition Documentation Version 1.4.1[EB/OL], Sun Microsystems.Inc,2002.
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 数据可视化(王者英雄数据分析)

发表评论 取消回复