一、引言
论文: BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
作者: Salesforce Research
代码: BLIP-2
特点: 该方法分别使用冻结的图像编码器(ViT-L/14、 ViT-g/14)和大语言模型(OPT、FlanT5)进行图像特征提取和文本特征提取与生成;提出Q-Former连接图像编码器和大语言模型;提出两阶段预训练策略分别提升模型特征学习和视觉到语言的生成学习能力。
二、详情
BLIP-2的整体结构图如下:
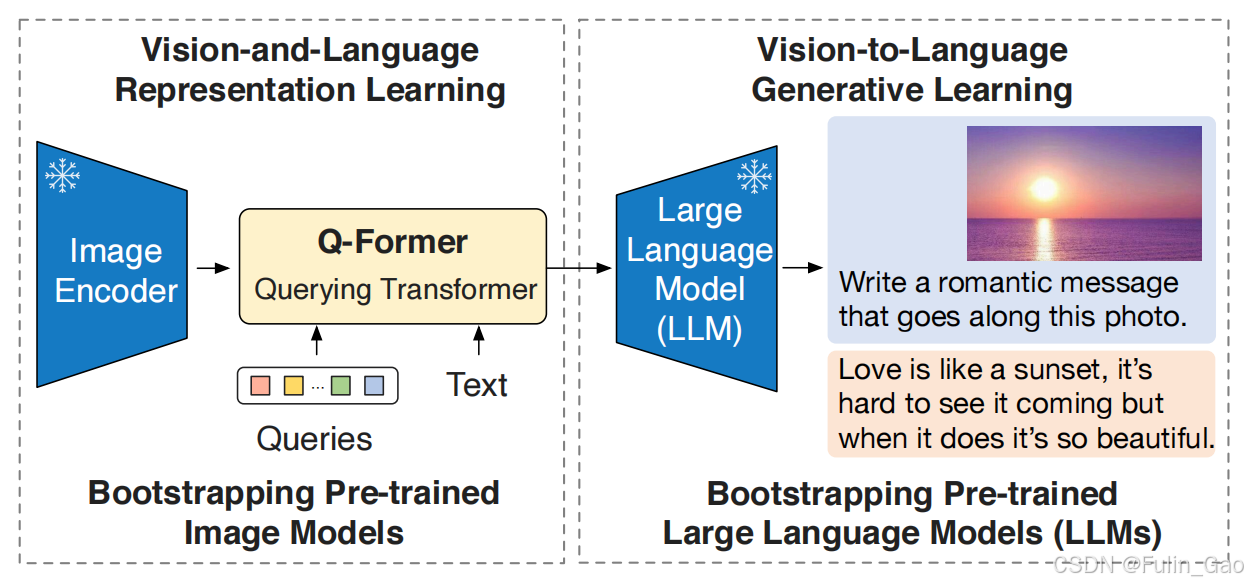
可见,它的图像编码器和大语言模型都是冻结的,作为一种预训练方法Q-Former起着至关重要的作用。左右两边则分别是预训练的两个阶段,第一个阶段致力于提升模型表征学习能力使查询token与文本token能够对齐并提取出与文本最相关的视觉特征,第二个阶段致力于提升模型视觉到语言的生成学习能力,使查询token能够被大语言模型理解。
2.1 Q-Former
Q-Former的整体结构图如下:
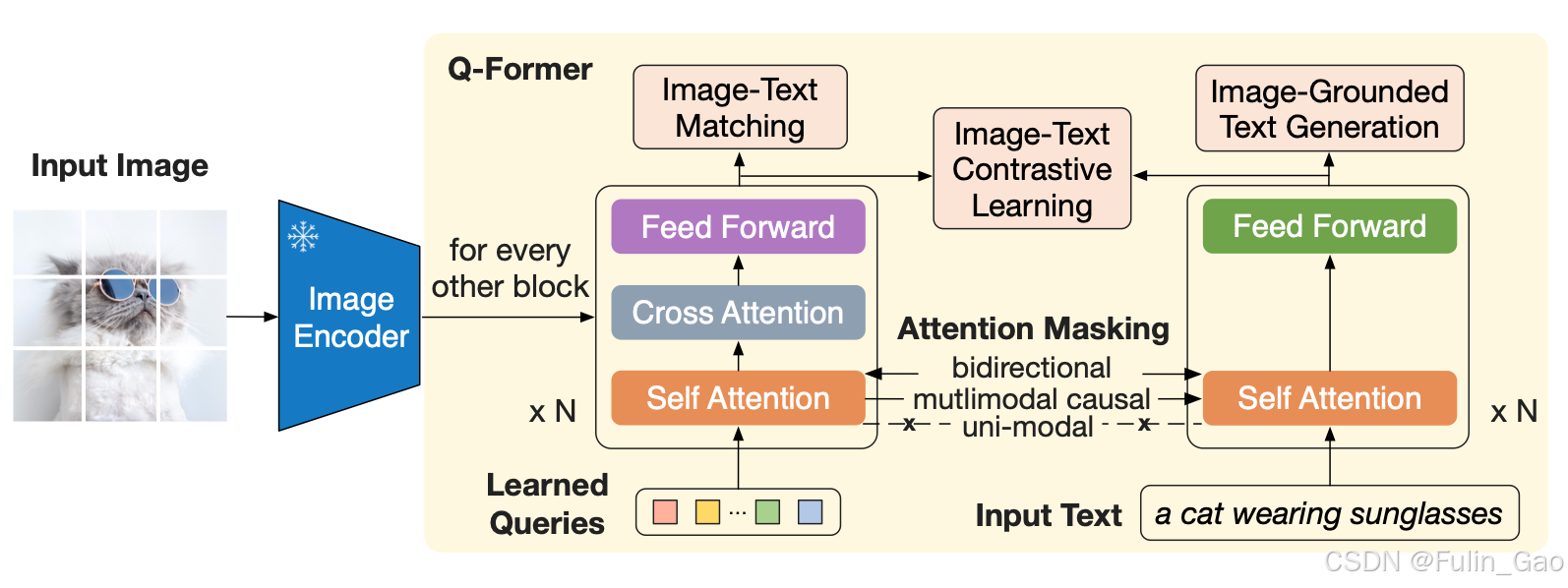
可见,它包括两个N层的transformer结构(N=12),分别为图像transformer和文本transformer。
图像transformer和文本transformer的自注意力和FFN都由BERT base _{\textbf{base}} base初始化。图像transformer和文本transformer的自注意力在forward时参数共享。图像transformer额外增加了被随机初始化的交叉注意力。
图像transformer的输入有两个,分别是查询token和图像编码器输出的图像token。查询token是由nn.Embedding随机初始化的30个长度为768的可学习参数。图像编码器输出的图像token在交叉注意力模块与查询token交互。
文本transformer的输入只有一个,即与图像配对的文本经Tokenizer得到的文本token。
2.2 表征学习阶段
第一阶段表征学习的目的是使Q-Former学习图像token中与文本token最相关的部分,相关内容由查询token表征。
表征学习的示意图如下:
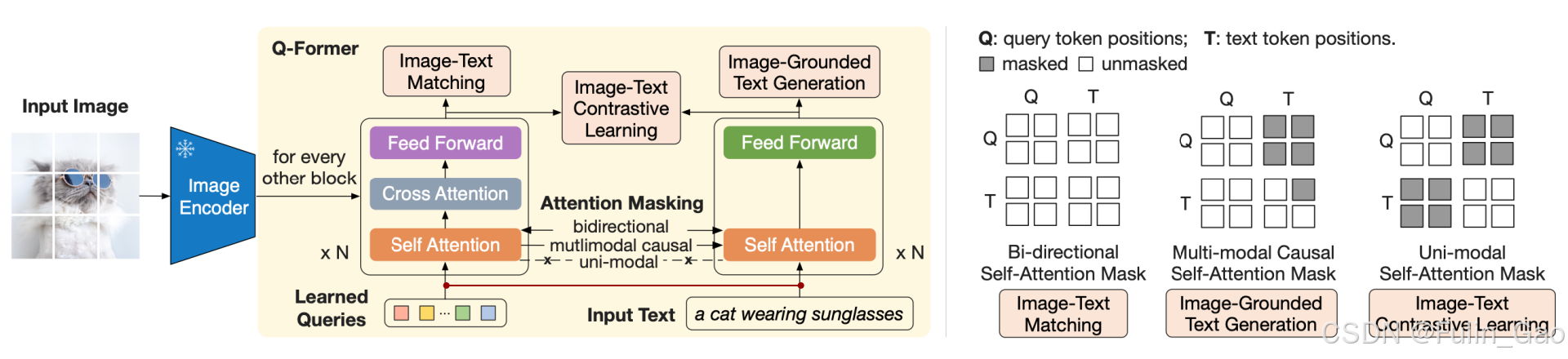
可见,表征学习主要涉及3项损失,包括image-text contrastive learning (ITC)损失、image-text matching (ITM)损失、Language Modeling (LM)损失;此外,Q-Former具有独特的输入形式。
2.2.1 独特的输入
Q-Former具有独特的输入形式,查询token和文本token被拼接到了一起,图像transformer和文本transformer使用相同的拼接后的token进行forward,但不同的损失使用不同的mask来阻挡查询token和文本token之间不期望的交互。
为方便理解,我在图中增加了一条红线,表示
图像transformer和文本transformer中输入自注意力的token是相同的,即查询token和文本token拼接在一起形成的新token。
2.2.2 ITC损失与mask
ITC损失旨在对齐查询token和文本token,即使成对的token更相似,反之更不相似。
ITC损失不允许两个模态token间有任何交互,因此其mask被称为单模态自注意力掩码,如下图:
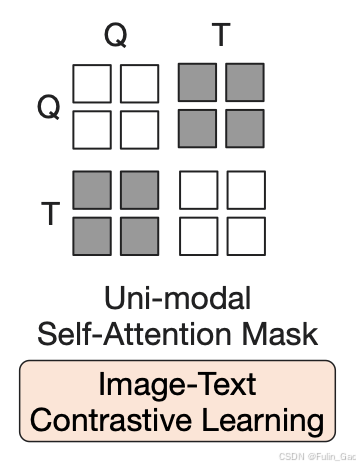
- 文本在Tokenizer之前需要在最前面扩充一个
[CLS],用来表达对当前文本的总结。例如,原文本是“I am very happy today.”,则新文本应为“[CLS]I am very happy today.”- 查询token会在交叉注意力模块与图像编码器输出的图像token交互,可以理解为最后输出的查询token是图像token的加权和,所以对齐查询token和文本token就是对齐图像特征和文本特征。
对于一个图像-文本对,ITC损失使用图像transformer输出的30个查询token和文本transformer输出的1个[CLS]token计算相似度。首先,30个查询token均与该[CLS]token计算相似度;然后,取最高的相似度作为该图像-文本对的相似度。 对于该图片,可以以类似的方法计算其与当前批次下其它文本的相似度,所有相似度形成一个logits,对应的one-hot标签在原图像-文本对的位置上取1,其余取0,即可计算交叉熵损失。同样地,该文本也可以计算其与当前批次下其它图像的相似度形成logits进而计算损失。
由于BLIP-2的图像编码器是始终冻结的,所以BLIP-2有更多的显存来支持更大的batchsize,所以负图像-文本对只需要在当前批次中寻找和计算。然而,ALBEF和BLIP的图像编码器也需要预训练,无法支持大的batchsize,因此只能额外引入动量模型和队列来补充负图像-文本对。
2.2.3 ITM损失与mask
ITM损失旨在更细粒度地使图像和文本特征对齐。它是一个二分类任务,判断当前图像-文本对是否匹配。
ITM损失完全允许两个模态token间的交互,因此其mask被称为双向自注意力掩码,如下图:
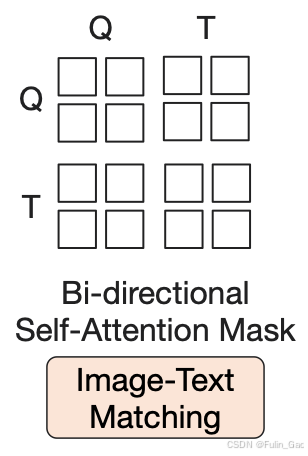
由于独特的输入形式、mask、自注意力参数共享,
ITM损失下的查询token会在自注意力模块与文本token发生交互并在交叉注意力模块与图像token交互,因此最后输出的查询token虽然仍是图像token的加权和,但其权重是综合了图像和文本信息的,因此能够实现更细粒度的特征对齐。
对于一个图像-文本对,ITM损失仅使用图像transformer输出的30个查询token进行二分类预测。首先,将所有的查询token送入一个全连接+softmax的二分类线性分类器获取logits,然后,对30个logits求平均作为最终的预测。 对于该图像,在计算ITC损失时已经计算了它与同批次内其它文本的相似度,因此可以选取其中相似度最高的作为hard的负文本,与图像形成负图像-文本对。原配图像-文本对应预测为匹配。负图像-文本对应预测为不匹配。对于该文本,也可以找到对应的hard的负图像,形成另一个负图像-文本对进而计算损失。
2.2.4 LM损失与mask
LM损失旨在进一步建立图像token和文本token之间的联系,使输出的查询token能够提取出图像token中与文本token相关的部分并表达出来。
LM损失不允许查询获取文本信息,但允许文本获取查询信息(因为要在图像的指导下生成文本,如果提前获取文本信息预测会变得异常简单),因其是一个文本生成任务,所以文本token只能与自身之前的文本token交互(即因果mask),如下图:
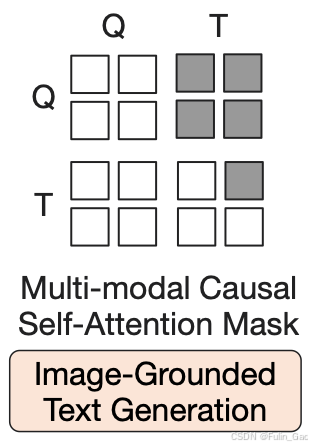
- 关于
LM损失的计算和因果mask的详情,请参考我之前的博客BLIP in ICML 2022的2.2.3节。LM损失需要一个token作为文本开始的标志,这里使用[DEC],即将ITC损失引入的[CLS]替换为了[DEC]。
2.3 生成学习阶段
第二阶段生成学习的目的是使Q-Former输出的查询token能够被大语言模型所理解。
生成学习的示意图如下:

可见,连接Q-Former和大语言模型的是1层全连接,它将Q-Former的token维度转至与大语言模型输入维度一致;BLIP-2提供了两个版本的大语言模型,仅包含Decoder的和同时包含Encoder和Decoder的。
对于仅包含Decoder的大语言模型,Q-Former输出的查询token会直接作为输入,也被称为soft visual prompts。然后使用LM损失进行生成预测预训练。
对于同时包含Encoder和Decoder的大语言模型,还允许增加一个前缀提示,Tokenizer之后会拼接在Q-Former输出的查询token后面输入Encoder。然后使用LM损失进行生成后缀的预训练。
在第二阶段的预训练过程中,输入图像输入
Q-Former经图像transformer输出查询token(不再与文本token拼接),经全连接后送入大语言模型并进行预测,因此生成学习时图像transformer也会得到更新,Q-Former中文本transformer的FFN是唯一得不到更新的。
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
BLIP2-图像文本预训练论文解读
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【多模态大模型】 BLIP-2 in ICML 2023

发表评论 取消回复