点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(正在更新…)
章节内容
上节我们完成了如下的内容:
- Java添加POM依赖
- Java操作Kafka的API、SpringBoot
- 实现对Kafka消息发送和消息消费

基本流程
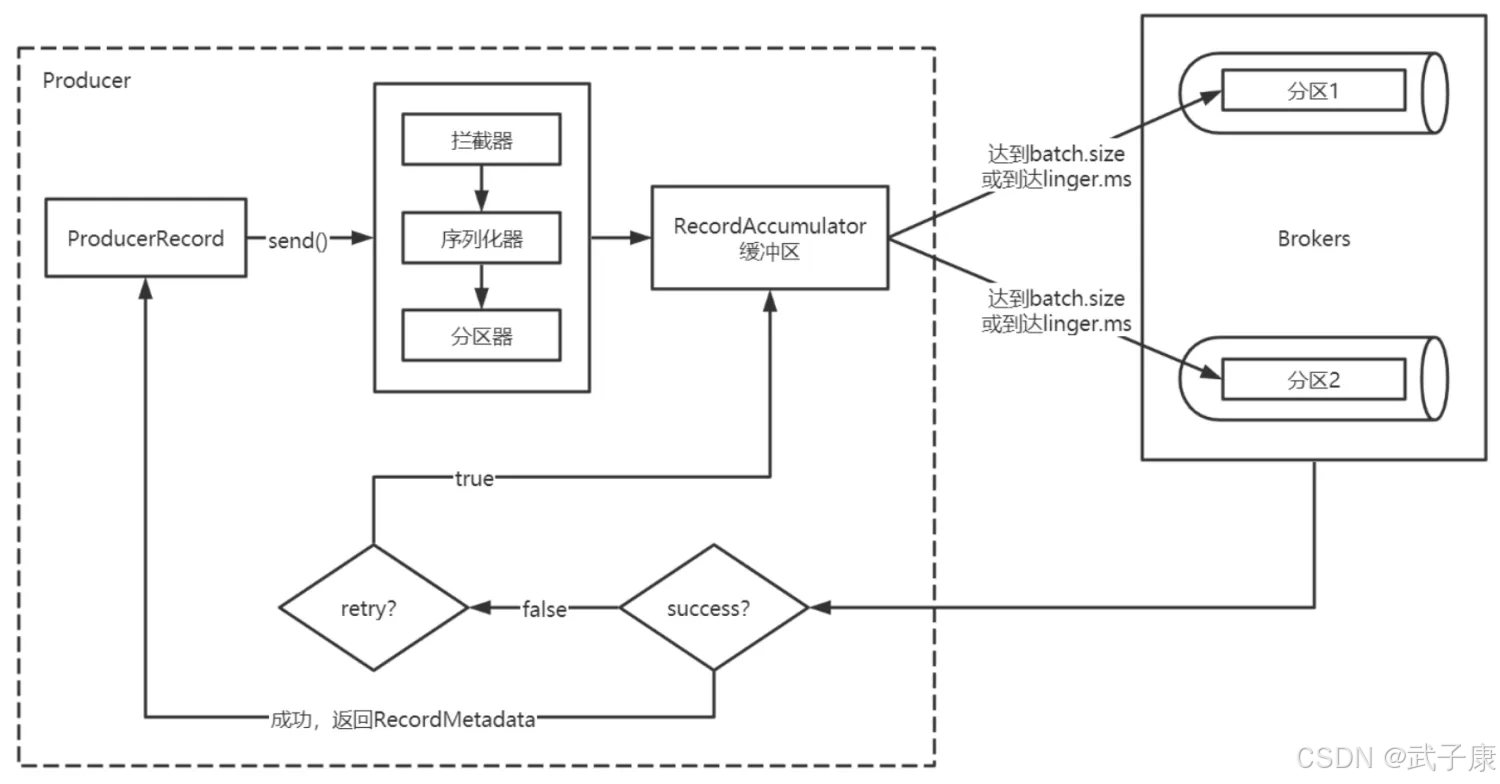
- Producer创建时,会创建一个Sender线程并设置为守护进程
- 生产消息时,内部其实是异步流程,生产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建)
- 批次发送的条件是:缓冲区的大小达到batch.size或者linger.ms达到上限,哪个先到达就算哪个
- 批次发送后,发往指定的分区后,然后落盘到broker
- 如果生产者配置了retrires参数大于0并且失败原因允许重试,那么客户端内部会对该消息进行重试
- 落盘到Broker成功 返回生产元数据给生产者
- 元数据返回的两种方式:一种是通过阻塞直接返回,另一种是通过回调返回
Broker配置
这里是Broker的常见配置:

bootstrap.servers
生产者客户端与broker集群建立初始链接需要Broker的地址列表,由该初始连接发现Kafka集群中其他的所有Broker,该地址列表不需要写全部的Kafka集群地址,但也不要只写一个防止宕机不可用。
key.serializer
实现了 org.apache.kafka.common.serialization.Serializer 的key序列化类
value.serializer
实现了 org.apache.kafka.common.serialization.Serializer的value序列化类
acks
该项控制着已发消息的持久性。
- acks=0,生产者不等待Broker的任何消息确认。
- acks=1,Leader将记录写到它本地的地址,就相应客户端的消息,而不等待Follower的副本的确认。
- acks=all,Leader等待所有有同步副本消息的确认,保证了只要有一个同步副本存在,消息就不会丢失。
- acks=-1,等价于 acks=all
默认值为1
compression.type
生产者生成数据的压缩格式,默认是none(无压缩)。
可选:
- none
- gzip
- snappy
- lz4
默认是none
Broker配置补充
额外的配置还有下图的这些内容:
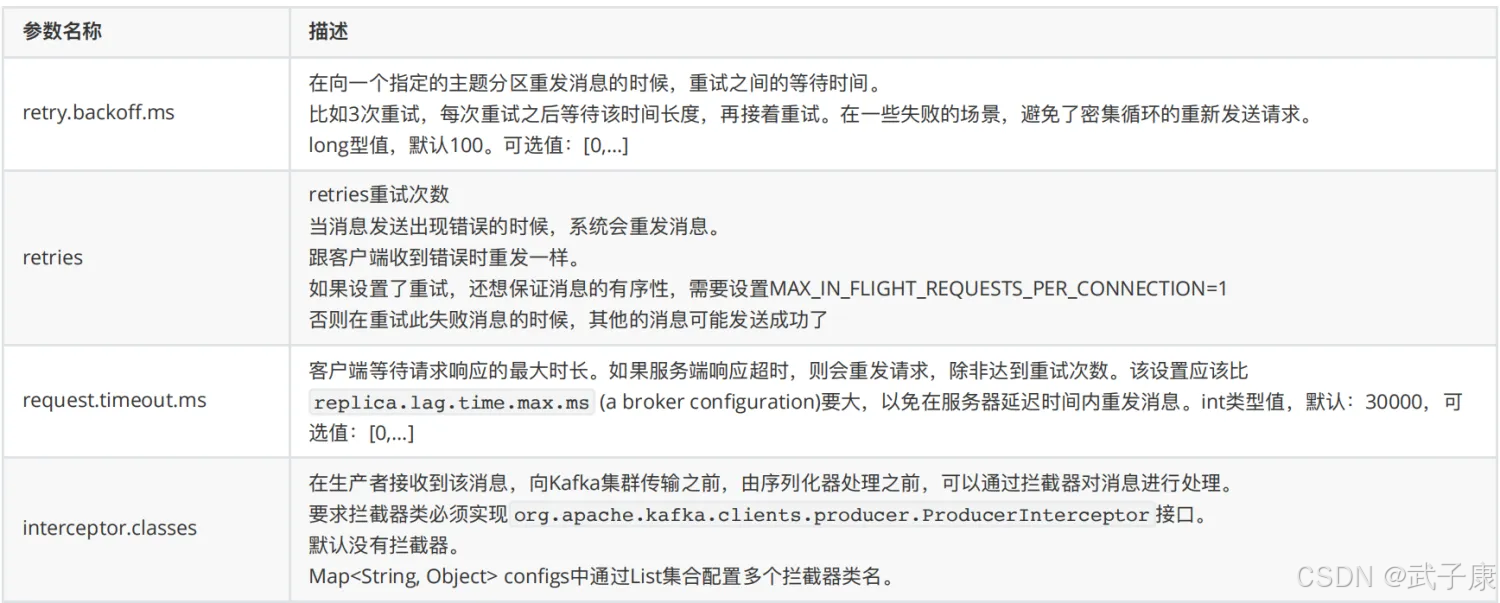


retry.backoff.ms
在向一个指定的主题分区重发消息的时候,重试之间的等待时间。
比如三次重试,每次重试之后等待时间长度,再接着重试。long型 默认 100
retries
retries 重试次数
- 当消息发送出现错误的时候,系统会重新发送消息,跟客户端收到错误重新发送一样。
- 如果设置了重试,还要保证消息有序,则需要设置 MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1
request.timeout.ms
客户端等待请求响应时长,如果服务器端响超时,则会请求重试,除非达到重试次数。
设置应该要大于:replica.lag.time.max.ms,以免服务器延迟时间内重发消息。
int型 默认 30000
interceptor.classes
在生产者接收到该消息,向Kafka集群传输之前,由序列化处理之前,可以通过拦截器对消息进行处理。
- 要求实现:org.apache.kafka.clients.producer.ProducerInterceptor 接口
- Map[String, Object] configs 中通过 List集合配置多个拦截器
默认没有拦截器
acks
同上,不介绍了。
batch.size
当多个消息发送到同一个分区时候,生产者尝试将多个记录作为一个批处理,批处理提高了客户端和副武器的处理效率。该配置项以字节为单位控制默认批的大小。
- 所有批小于等于该值
- 发送给Broker的请求将包含多个批次,每个分区一个,并包含可发送的数据
- 如果该值设置的较小,会限制吞吐量(设置为0会完全关闭批处理);若很大则会浪费内存
client.id
- 生产者发送请求的时候传递给Broker的id字符串
- 用于在Broker的请求日志中追踪什么应用发送什么消息
- 一般该ID跟业务有关的字符串
compression.type
同上,不介绍了。
send.buffer.bytes
TCP发送数据的时候用的缓冲区的大小,若设置为0,则用操作系统默认的。
buffer.memory
生产者可以用来缓存等待发送到服务器的记录的总内存字节,如果记录的发送速度超过了将记录发送到服务器的速度,则生产者将阻塞 max.block.ms 的时间,此后将引发异常。
此设置应大致对应于生产者将使用的总内存,但并非生产者使用的所有内存都用于缓冲。
connections.max.idle.ms
当连接空闲时间达到这个值,就关闭连接。long型 默认 540000
linger.ms
生产者发送请求传输间隔会对需要发送的消息进行累积,然后作为一个批次发送,一般情况是消息的发送速度比消息积累的速度要慢。
有时候客户端需要减少请求次数,即使在负载不大的情况下。该配置设置了一个延迟,生产者消息不会立即将消息送到Broker,而是等待这么一段时间以积累消息,然后将这段消息之类的消息作为一个批次发送,该设置是批处理的另一个上限,一旦此消息达到了batch.size指定的值,消息批会立即发送,如果积累的消息字节数达不到batch.size的值,可以设置该毫秒值,等待这么长时间之后,也会发送消息批。默认值是0
max.block.ms
控制KafkaProducer.send()和KafkaProducer.partitionFor()阻塞时长,当缓存满了或元数据不可用的时候,这些方法阻塞。在用户提供的序列化器和分区器的阻塞时间不计入。
long型值,默认60000
max.request.size
单个请求的最大字节数,该设置会限制单个请求总消息批的个数,以免单个请求发送太多的数据,服务器有自己的限制批大小的设置,与该配置可能不一样int 型 默认 1048576
partitioner.class
实现了接口 org.apache.kafka.clients.producer.Partitioner 的分区器实现类。默认值:org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytes
TCP接收缓存(SO_RECVBUF),设置为01,则使用操作系统默认的值。int型 默认32768
security.protocol
跟 Broker 通信的协议:PLAINTEXT、SSL、SASL_PLAINTEXT、ASAL_SSLString型 默认 PLAINTEXT
max.in.flight.requests.per.connection
单个连接上未确认请求的最大数量,达到这个数量,客户端阻塞。
如果该值大于1,则存在失败的请求,在重试的时候消息顺序不能保证。int型 默认5
reconnect.backoff.max.ms
对于每个连续的连接失败,每台主机退避将成倍增加,直到达到此最大值。
reconnect.backoff.ms
尝试重连指定主机的基础等待时间,避免该主机的密集重连。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-57 Kafka 高级特性 消息发送相关01-基本流程与原理剖析

发表评论 取消回复