ReLu和Sigmoid的区别。
ReLU在正数区域提供线性响应,有助于加速训练并减少梯度消失问题,而Sigmoid在所有区域都是非线性的,输出范围是0到1,适用于二分类问题,但在深网络中容易造成梯度消失。
Softmax函数的作用。
Softmax函数将模型的输出转化为概率分布,适用于多分类问题,并确保所有类别的概率之和为1。
交叉熵损失函数的工作原理。
交叉熵损失函数衡量模型预测的概率分布与实际标签之间的差异,它鼓励模型对正确的类别分配更高的概率,对错误的类别分配更低的概率。
其中,y 是实际的概率分布(通常是one-hot编码,注意PyTorch的nn.CrossEntropyLoss会自动进行编码,不需要自己手动对数据的标签进行one-hot编码),而 p 是模型预测的概率分布。此损失函数度量了预测分布 p 和真实分布 y 之间的“距离”
假设我们正在处理一个三分类问题,模型的输出在经过Softmax函数处理后得到的概率分布为:
假设这个样本的真实标签是第二个类别,因此one-hot编码的标签y为:
计算过程如下:
,最后结果为:
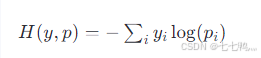
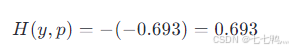
在什么情况使用MAE而不是MSE?
MAE(L1损失)对异常值不太敏感,因此在数据中有许多异常值或离群点的情况下,使用MAE可能更好。MSE(L2损失)对较大的误差更敏感,这可能导致模型过度关注异常值。
激活函数的作用
激活函数为网络引入非线性,使神经网络能够学习和逼近复杂的函数。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 深度学习中常用的激活函数和损失函数

发表评论 取消回复