首先呢,我们知道MySQL的数据结构为B+tree,那么其结构究竟是什么样的,为什么选择B+tree,而不选择Btree。下面我们从其结构分析
1.Btree平衡多路查找树
B-tree结构的数据可以让系统高效的找到数据所在的磁盘块。为了描述B-Tree,首先定义一条记录为一个二元组(key,data),key记录键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同
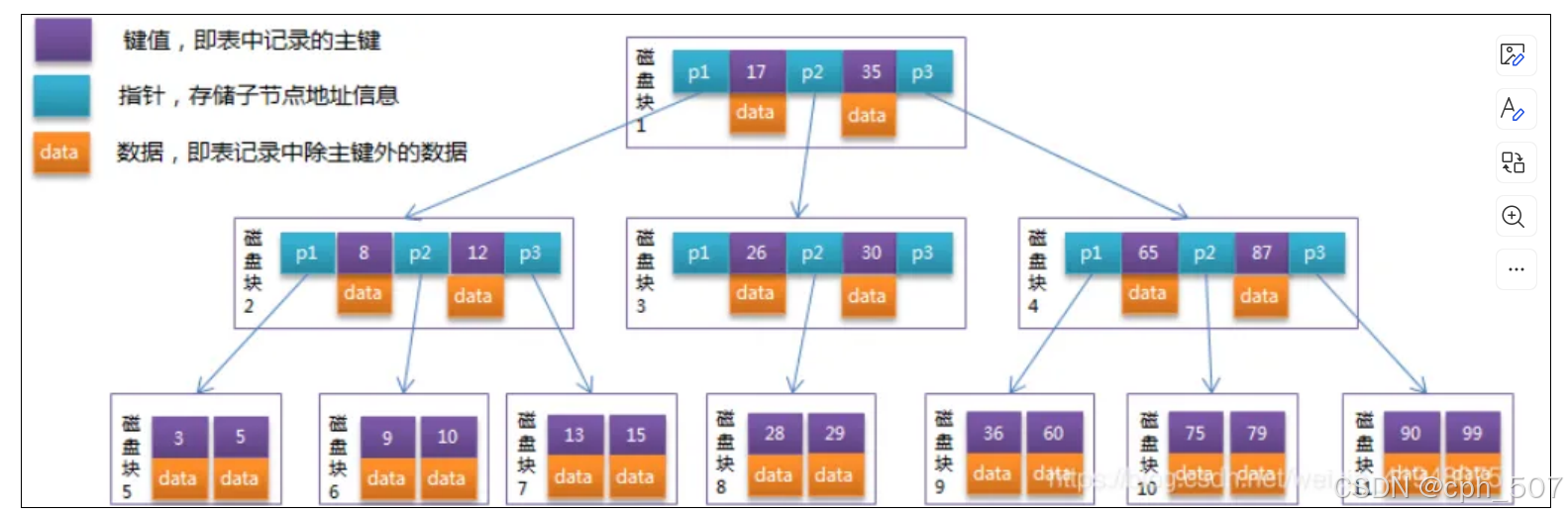
仔细观察:B-Tree的每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的字数的范围域。
以图中根节点为例:p1:指向小于17的范围域
p2:指向大于17,小于35的范围域
p3:指向大于35的范围域
其,查找数据时,需要多次将数据读取到内存。
2.B+Tree
所有的叶子节点中包含可全部关键字的信息,非叶子节点只存储键值信息,及指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大的顺序链接,所有的非终端节点可以看成是索引部分,节点中仅含有其子树根节点中最大(或最小)关键字。(而B树的非重点节点也包含需要查找的有效信息)
1.所有叶子节点之间都有一个链指针
2.数据记录都存放在叶子节点中
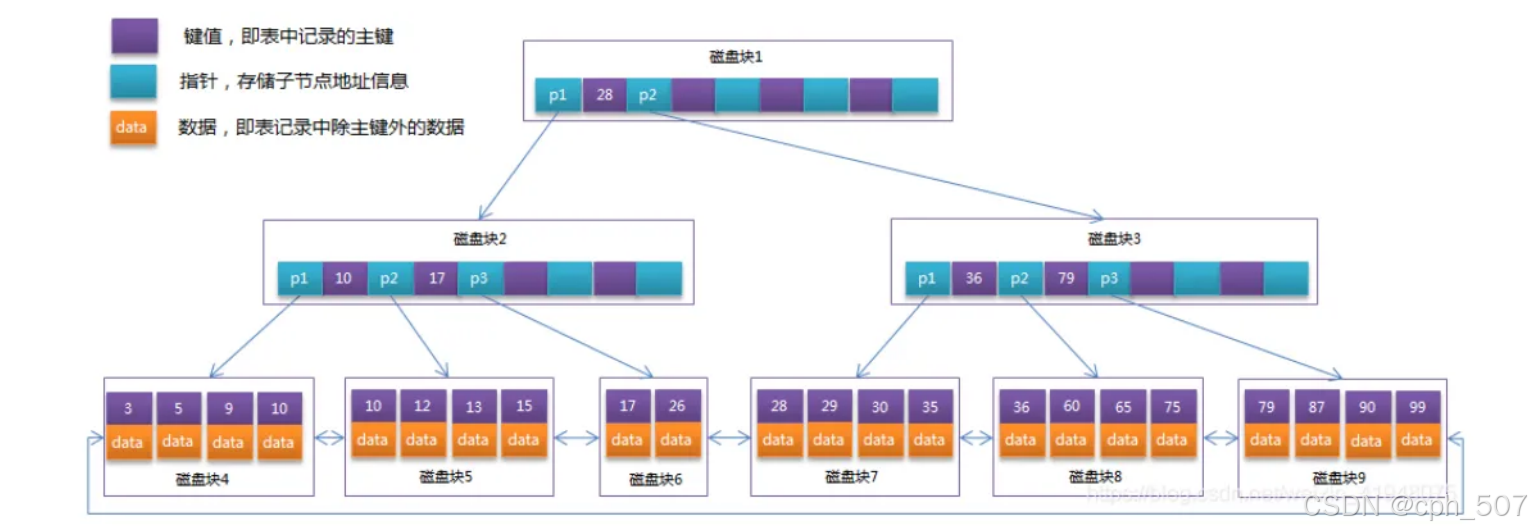
仔细观察:B+Tree和B-Tree结构差异,其所有的叶子节点包含了全部关键字信息,非叶子节点只存储键值信息,及指向含有这些关键字记录的指针。并且叶子节点本身依照关键字的大小,自小而大的顺序链接,所有的非终端节点可以看成索引部分,结点中仅含有其子树根节点中最大或最小的关键字(B-Tree的非终结点也包含需要查找的有效信息)
1.所有的叶子节点之间都有一个链指针。
2.数据记录都存放在叶子节点中
3.B+Tree 和B-Tree的区别?
1.数据存储位置:
B+Tree:所有的数据记录都存储在叶子节点。非叶子节点仅包含键值,用于指导搜索路径
B-Tree:数据可以存储在非叶子节点和叶子节点。每个节点包含一组键值对,这些键值对按顺序排列
2.节点结构:
B+Tree:每个非叶子节点包含多个键值和相同数量的子节点指针,叶子节点除了包含数据记录外,还包含指向相邻叶子节点的指针
B-Tree:每个节点包含多个键值对和多个子节点指针。节点内的键值对和节点指针数量之间存在一定的关系,以保持平衡
3.搜索性能:
B+Tree:搜索性能只需要访问叶子节点,由叶子节点形成一个链表,搜索过程中可快速遍历所有值
B-Tree:搜索操作可能需要访问非叶子节点,搜索路径上的每个界定都需要比较和跳转。
4.插入和删除操作:
B+Tree:插入和删除更新键值和指针信息操作仅影响叶子节点,非叶子节点仅需要
B-Tree:插入和删除可能会导致节点分裂或合并,维护树的平衡
5.应用场景:
B+Tree:适合需要频繁搜索,插入和删除操作的场景,如数据库索引。由于所有数据都在叶子节点,B+Tree在范围查询和排序方面更有优势
B-Tree:适合需要快速访问中间节点数据的场景,如文件系统中的目录结构
SQL优化 的优化策略:
1.三大范式:
第一范式:强调列的原子性。即数据库每列都是不可分割的原子数据项
第二范式:要求实体的属性完全依赖主键,即在满足第一范式的基础上
第三范式:要求实体的属性和主键直接相关依赖,而不是间接
设计数据库表的原则:
1.数据表的个数越少越好
2.数据表中的字段个数越少越好
3.数据表中联合主键的字段个数越少越好
4.使用主键和外键越多越好
优化原则:
SQL语句编写的优化:
1.【强制】:程序段select语句必须指定具体字段名称,禁止携程*
【建议】:
1.程序段insert语句指定具体字段名称,不要写成insert into t1 values(...)
2.除静态表或小表(100行以内),DML语句必须有where条件,且使用索引查找
3.insert into t1 values(...),(....)... , 多条数据插入时,建议值不要超过500个,值过多,虽然上线快,但会引起主从同步延迟
4.select 语句不要使用union,推荐使用union all 并且union子句个数限制在5个以内
5.线上环境,多表了连查join,不要超过5个表
6.减少使用order by ,和业务沟通,尽量将排序放到程序段去做,Order by group by, distinct 这些语句较为耗费CPU,数据库的CPU资源及其宝贵
7.包含order by ,group by,distinct这些查询语句,where 条件过滤出来的结果集请保持在1000行以内,否则sql会很慢
8.对单表的多次alter 操作必须合并为一次
对于超过100w 行的大表进行alter table 必须经过DBA 审核,并在业务低峰期执行,多个alter 需整合在一起,因为alter table会产生表锁,期间阻塞对于该表的所有写入,对于业务可能会产生极大影响
9.批量操作数据时,需要控制事务处理间隔时间,进行必要的sleep
10.事务里包含SQL语句不超过5个
因为过长的事务会导致锁数据较久,MySQL内部缓存,连接消耗过多等问题
11. 事务里更新语句尽量基于主键或Unique key,如update。。。。where id=xxx;
否则会产生间隙锁,内部扩大锁定范围,导致系统性能下降,产生死锁。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » MySQL的数据结构B+tree以及SQL优化

发表评论 取消回复