1.数据库约束
数据库自动对数据的合法性进行校验检查的一系列机制,目的是为了保证数据库中能够避免被插入或者修改一些非法数据。
(1)mysql中提供了以下的约束:
a.NOT NULL:指定某列不能为null
b.UNIQUE:该列不能重复的值(唯一)
通过UNIQUE这个约束,会让后续插入,修改数据时都会先进行一次查询,通过该次查询看数据是否存在,从而这个操作就会影响执行效率(Mysql数据库是比较吃资源的,是一个比较慢的系统(相对其他数据库而言))。
c.PRIMARY KEY:主键,是NOT NULL和UNIQUE的结合,代表某列既不能为null,且是唯一的
一张表中只有一个主键。主键一般会搭配auto_increment(自增)来进行使用,在进行插入数据的时候,就不需要手动去赋值,mysql会根据当前主键的值自动分配一个值(从1开始),用来表示主键的唯一性。
使用auto_increment(主键一般是int/bigint类型)时需要注意:
如果此时里面已经有1,2,3,4这几个主键,此时插入一个主键:9,此时后续在进行插入数据时,会从9开始往后加,中间主键没用到的地方,只能通过手动插入的方式来进行设置。
eg:现有一张表student(create table student values(id int primary key auto_increment,name varchar(20)); ),里面有id(主键)和name属性,此时插入数据(insert into student values(null,"lisi"),(null,"zhangsan");),可以看到这里的主键在添加auto_increment对id传null表示交给mysql去处理,给我们自动分配一个值,而不是表示null值;如果没有这个auto_increment的话就会报错,主键不能为null。
d.FOREIGN KEY:外键,保证一个表中的数据匹配另一个表中的值的参照完整性
ps:
外部约束的那一列必须是主键/UNIQUE(唯一),被外部约束的键放在前面,外部进行约束的键放在最后。两张表此时相当于建立了一个父子关系。如果外键创建成功,那么每一次插入/修改数据的时候,都会先去父表中查询一下是否存在,这个过程也会一定程度上影响执行效率。
eg:class表(父):create table class values(classid int primary key, classname varchar(20);)
student表(子):create table student values(id int,name varchar(20), foreign key(id) references class(classid);)
如果class中classid不是主键,创建student表时不会创建成功。如果创建成功,student表中id属性将会被class中classid属性给约束,id属性进行插入时,只能插入classid中有的值,没有的插入不成功(父类约束子类);如果想对class中的classid属性进行修改,如果在student中被用了,此时修改不会成功(子类在一定程度上也会约束父类)。
不能直接删除父表,如果要删除需要先删除子表,然后再进行删除父表。
e.CHECK:保证列中的值符合指定条件,对于Mysql数据库,忽略CHECK字句
f.DEFAULT:某列在没有赋值的时候的默认值,没有进行修改这个dafault就默认为null
以上约束都是在表创建时所加的约束,一旦表已经创建好了,就不可在进行约束的更改,除非删表重新创建表。
2.查询(进阶)
(1)查询搭配插入使用
eg:insert into s1 select * from s2; 将s2中的所有数据插入到s1中,前提:两个表中的数据类型,个数,顺序要一致。
(2)聚合查询
前面的表达式查询是针对列与列之间的查询,而聚合查询是针对行与行之间的查询。
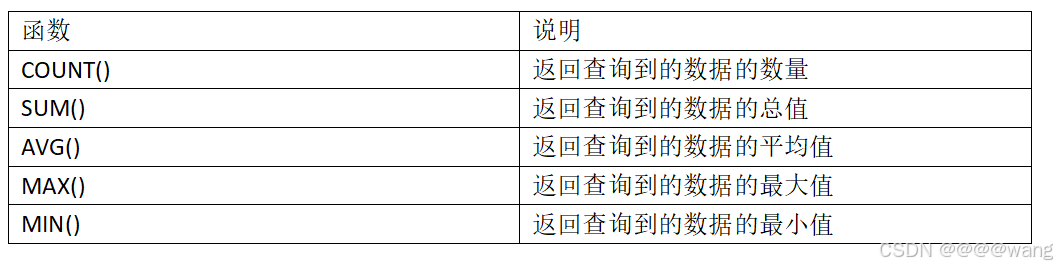
a.count
eg:select count(*) from s1; ( 假如s1表中有8条数据,其中有一条为null)
select count(distinct english) from s1;( s1表中有个english属性,english属性中一条null记录,两条重复的记录)
此时得到的结果为8(count(*)这个操作会包含null这条记录,且不会进行去重),但单单用count计算某一列的数量(如果没加distinct的话,此时也是计算的总行数,加了去重的话就不一定了),不会将null计算进去(在这里得到的结果也就是7),
b.sum
数字类型求和:
eg:select sum(english) from s1; (计算s1表中所有english加起来的成绩)
字符窜类型求和:
eg:select sum(name) from s1;(这个操作,mysql会尝试把字符串转化成double类型的数据,如果转化失败,会报错;否则可以正常进行运算)结果为0,并且会报警告(可以通过show warnings; 操作进行警告的查看)
如果有这样的规则,那么插入数据:insert into s1 values("006",95);(以"数字"的这种形式) ,此时对name进行求和就可以得到6;
表达式求和:
eg:select sum(english+chinese) from s1;(s1表中还有个chinese属性,此时结果为整个表中chinese和english的总和)
其他使用方式大多相似,不一一进行列举,参考上述两种方式。
(3)group by
主要有两种用法:
加where:分组之前的的条件,在group by 之前
加having:分组之后的条件,在group by 之后
eg:现有一张工资表(一个公司各个职位的工资)s(有name,role,salary属性),现要查询除了张三以外所有员工(分职位)的平均工资,应该执行的操作为:select name avg(salary) from s where name != "张三" group by role; 很明显这个条件应该是在分组之前被执行,所以用where。现还要查询每个岗位的工资,除了工资超过2w的岗位,应该执行的操作为:select name,avg(salary) group by role having avg(salary) < 20000;
(4)联合查询
前面的查询都是针对一个表进行查询,而在实际开发过程中,经常可能会对多个表进行查询,此时就需要用到联合查询。
关键思路:笛卡尔积。笛卡尔积是简单无脑的排列组合,把所有情况都列举了一遍,需要通过连接条件来筛选出有意义的数据。笛卡尔积的行数是多个表的行数相乘,列数是多个表的列数相加。
a.内连接
语法:select 列名 from 表1 as 别名1,表2 as 别名2 where 连接条件 and 连接条件;
select 列名 from 表1 as 别名1 [inner] join 表2 as 别名2 on 连接条件 and 连接条件;
b.外连接
分为左外连接和右外连接。左侧的表(表1)完全显示出来就是左外连接,右侧的表(表2)完全显示出来就是有外连接,另一侧表不存在的用null/default填充。
语法:select 列名 from 表1 as 别名1 left join 表2 as 别名2 on 连接条件 and 连接条件;
select 列名 from 表1 as 别名1 rightjoin 表2 as 别名2 on 连接条件 and 连接条件;
内连接和外连接的关系:
如果两张表中的数据是一一对应的,则内连接与外连接没有区别;
如果不是一一对应的,则内外连接所查询到的结果不同。
(5)自连接
一张表,自己与自己进行笛卡尔积,通过此方式可以实现一张表中行与行之间的比较。mysql本身只能进行列与列之间的比较。
(6)子查询
本质是套娃,会把多个简单的sql语句变成一个复杂的sql语句,违背了编程设计的一贯原则,在实际开发中不建议使用,但是还是需要了解一下。
eg:现在有stutdent表(里面有name,classid等属性),现在要查询“张三”(假设张三所在班编号为1)的同班同学,应该执行的操作:select classid from student where name = “张三”; select name,classid from student where classid = 1 and name != "张三"; 而用子查询的话sql语句:select name,classid from student where classid = (select classid from student where name = “张三”) and name != "张三";
(7)合并查询
使用union关键字,把多个sql查询的结果集合,合并在一起。合并的前提是两个表的列属性参数类型,个数和顺序(列名可以不同)要相同。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » mysql操作(进阶)

发表评论 取消回复