大家好,今天给大家分享的是一款一站式、开源、高质量的数据提取工具MinerU,主要包含以下功能:
-
Magic-PDF PDF 文档提取
-
Magic-Doc 网页与电子书提取

项目介绍
Magic-PDF
简介
Magic-PDF 是一款将 PDF 转化为 markdown 格式的工具。支持转换本地文档或者位于支持 S3 协议对象存储上的文件。
主要功能包含:
- 自动识别 PDF 文档的语言,并选择合适的语言模型进行处理,提高转换准确率
- 准确识别并处理 PDF 中的引用、脚注、参考文献等
- 保留原文档的结构和格式,包括标题、段落、列表等
- 智能识别各种复杂的表格、图表、代码块等,并将其准确转换为 Markdown 格式
- 支持多种前端模型输入、公式转换、乱码识别等
- 支持 CPU 和 GPU 加速,提升转换速度
- 多平台支持: 兼容 Windows、Linux、Mac 等主流操作系统
复杂布局版面分析

多模态信息转换
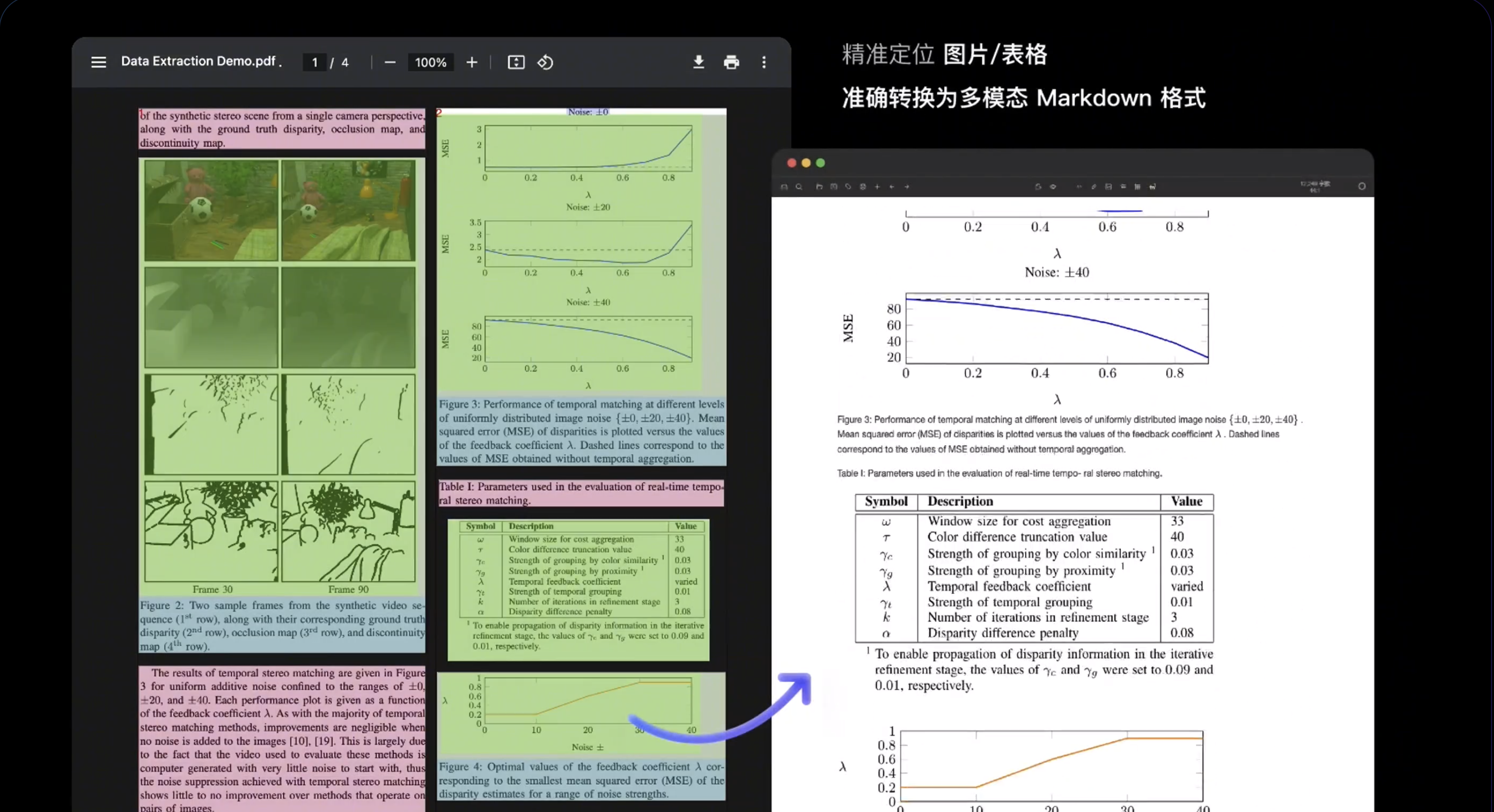
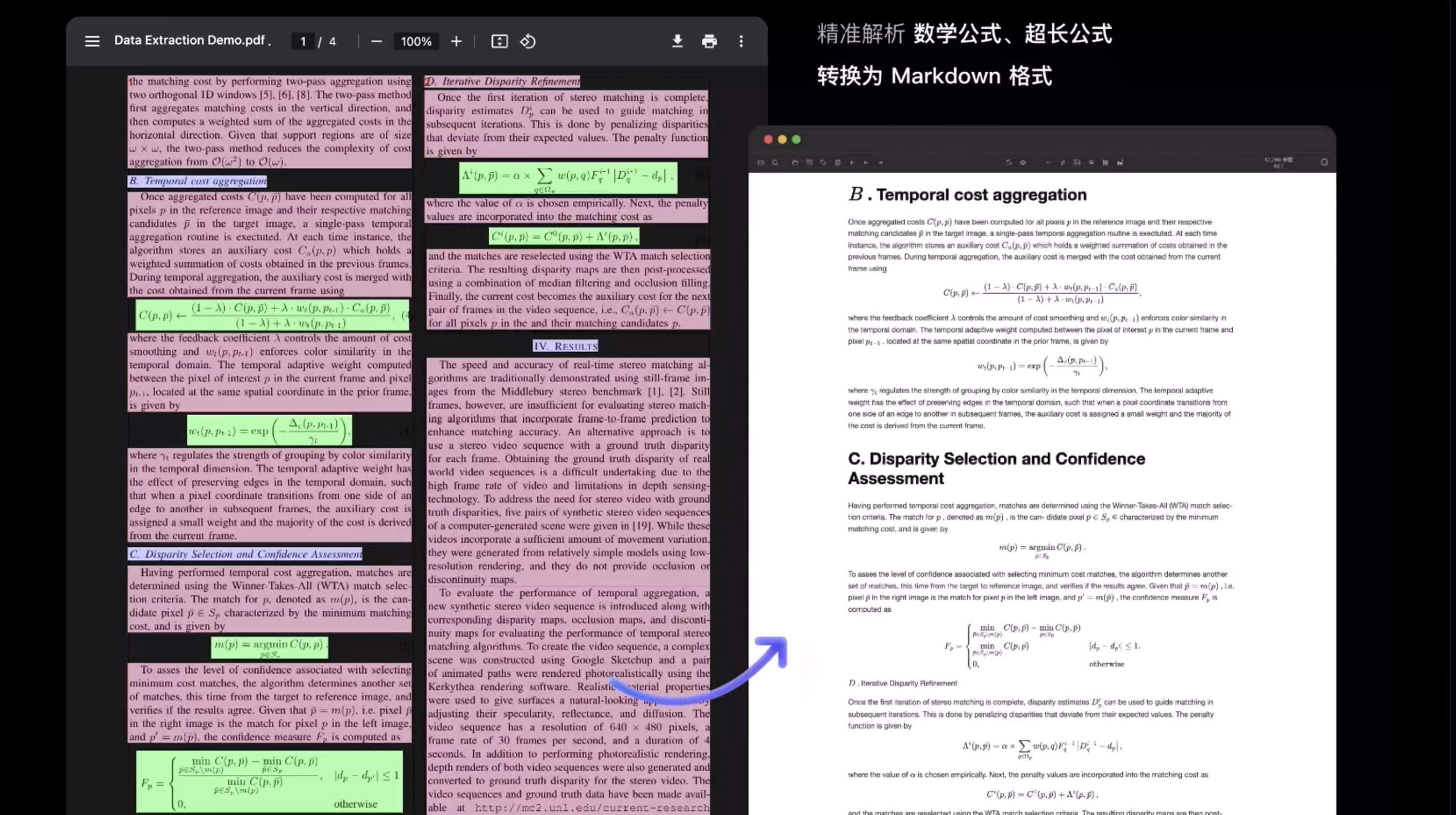
数学及超长公式准确解析
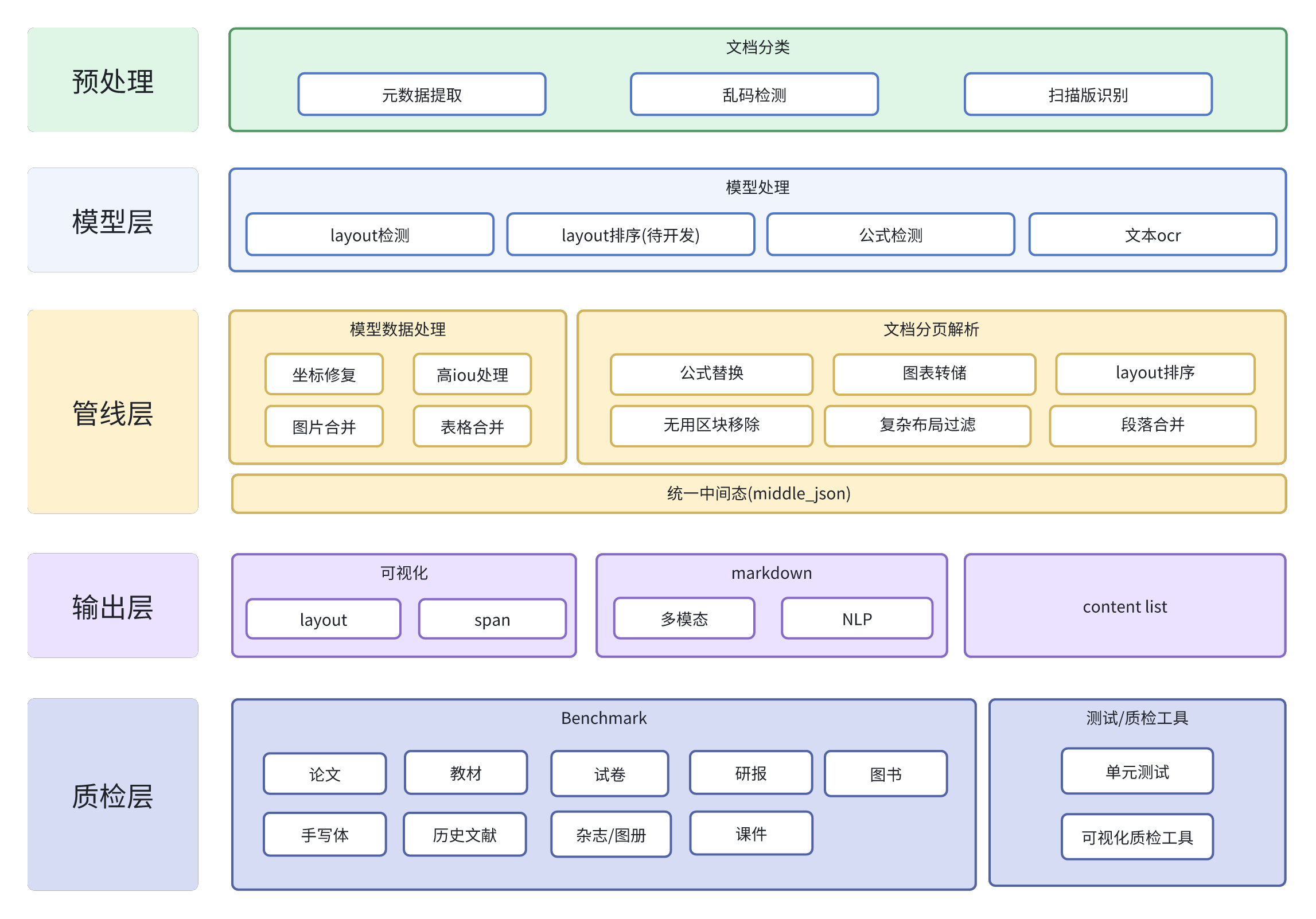
项目架构
流程图

Magic-Doc
简介
Magic-Doc 是一款支持将网页或多格式电子书转换为 markdown 格式的工具。
主要功能包含:
- Web 网页提取,跨模态精准解析图文、表格、公式信息

- 电子书文献提取,支持 epub,mobi 等多格式文献,文本图片全适配

- 语言类型鉴定,支持 176 种语言的准确识别
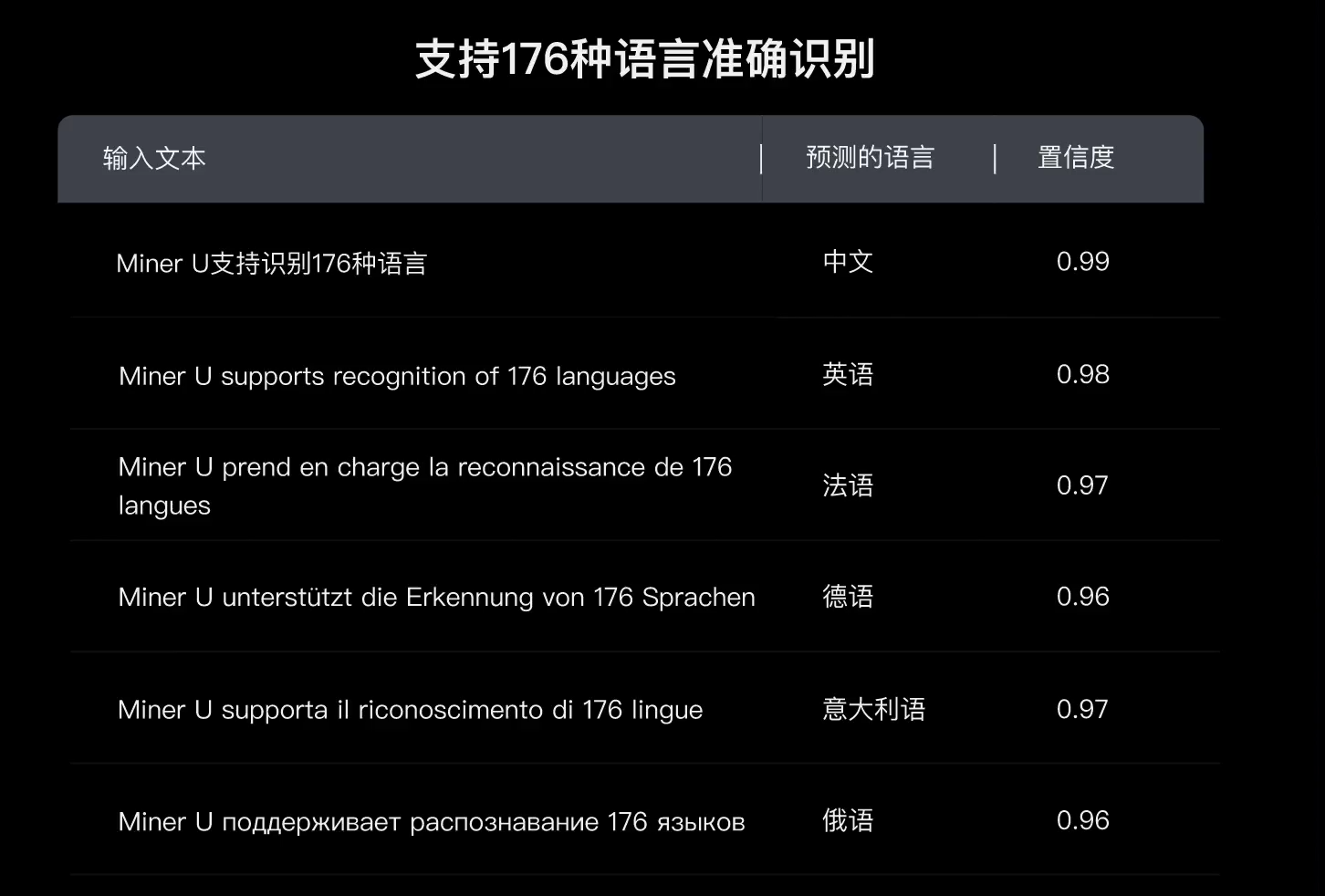
安装使用
Magic-PDF
1. 安装 Magic-PDF
使用 pip 安装完整功能包:
受 pypi 限制,pip 安装的完整功能包仅支持 cpu 推理,建议只用于快速测试解析能力。
如需在生产环境使用 CUDA/MPS 加速请参考
使用 CUDA 或 MPS 加速推理
pip install magic-pdf[full-cpu]️ 已收到多起由于镜像源和依赖冲突问题导致安装了错误版本软件包的反馈,请务必安装完成后通过以下命令验证版本是否正确
magic-pdf --version如版本低于 0.6.x,请提交 issue 进行反馈。
完整功能包依赖 detectron2,该库需要编译安装,如需自行编译,请参考:detectron2 自行编译说明。
或是直接使用我们预编译的 whl 包:
️ 预编译版本仅支持 64 位系统(windows/linux/macOS)+pyton 3.10 平台;不支持任何 32 位系统和非 mac 的 arm 平台,如系统不支持请自行编译安装。
pip install detectron2 --extra-index-url https://myhloli.github.io/wheels/2. 下载模型权重文件
详细参考 如何下载模型文件
下载后请将 models 目录移动到空间较大的 ssd 磁盘目录
3. 拷贝配置文件并进行配置
在仓库根目录可以获得 magic-pdf.template.json 配置模版文件
️ 务必执行以下命令将配置文件拷贝到用户目录下,否则程序将无法运行
cp magic-pdf.template.json ~/magic-pdf.json在用户目录中找到 magic-pdf.json 文件并配置”models-dir”为下载模型权重文件中下载的模型权重文件所在目录
️ 务必正确配置模型权重文件所在目录,否则会因为找不到模型文件而导致程序无法运行
{
"models-dir": "/tmp/models"
}4. 使用 CUDA 或 MPS 加速推理
如您有可用的 Nvidia 显卡或在使用 Apple Silicon 的 Mac,可以使用 CUDA 或 MPS 进行加速
CUDA
需要根据自己的 CUDA 版本安装对应的 pytorch 版本
以下是对应 CUDA 11.8 版本的安装命令,更多信息请参考 Start Locally | PyTorch
pip install --force-reinstall torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu118同时需要修改配置文件 magic-pdf.json 中”device-mode”的值
{
"device-mode":"cuda"
}MPS
使用 macOS(M 系列芯片设备)可以使用 MPS 进行推理加速
需要修改配置文件 magic-pdf.json 中”device-mode”的值
{
"device-mode":"mps"
}5. 通过命令行使用
直接使用
magic-pdf pdf-command --pdf "pdf_path" --inside_model true程序运行完成后,你可以在”/tmp/magic-pdf”目录下看到生成的 markdown 文件,markdown 目录中可以找到对应的 xxx_model.json 文件
如果您有意对后处理 pipeline 进行二次开发,可以使用命令
magic-pdf pdf-command --pdf "pdf_path" --model "model_json_path"这样就不需要重跑模型数据,调试起来更方便
更多用法
magic-pdf --help6. 通过接口调用
本地使用
image_writer = DiskReaderWriter(local_image_dir)
image_dir = str(os.path.basename(local_image_dir))
jso_useful_key = {"_pdf_type": "", "model_list": model_json}
pipe = UNIPipe(pdf_bytes, jso_useful_key, image_writer)
pipe.pipe_classify()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")在对象存储上使用
s3pdf_cli = S3ReaderWriter(pdf_ak, pdf_sk, pdf_endpoint)
image_dir = "s3://img_bucket/"
s3image_cli = S3ReaderWriter(img_ak, img_sk, img_endpoint, parent_path=image_dir)
pdf_bytes = s3pdf_cli.read(s3_pdf_path, mode=s3pdf_cli.MODE_BIN)
jso_useful_key = {"_pdf_type": "", "model_list": model_json}
pipe = UNIPipe(pdf_bytes, jso_useful_key, s3image_cli)
pipe.pipe_classify()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")Magic-Doc
1. 安装
前置依赖: python3.10
安装依赖
linux/osx
apt-get/yum/brew install libreofficewindows
安装 libreoffice
添加 "install_dir\LibreOffice\program" to 环境变量 PATH安装 Magic-Doc
pip install fairy-doc[cpu] # 安装 cpu 版本
或
pip install fairy-doc[gpu] # 安装 gpu 版本2. 使用示例
# for local file
from magic_doc.docconv import DocConverter, S3Config
converter = DocConverter(s3_config=None)
markdown_content, time_cost = converter.convert("some_doc.pptx", conv_timeout=300)# for remote file located in aws s3
from magic_doc.docconv import DocConverter, S3Config
s3_config = S3Config(ak='${ak}', sk='${sk}', endpoint='${endpoint}')
converter = DocConverter(s3_config=s3_config)
markdown_content, time_cost = converter.convert("s3://some_bucket/some_doc.pptx", conv_timeout=300)项目地址
https://github.com/opendatalab/MinerU一款一站式、开源、高质量的数据提取工具,支持:PDF 文档、网页和电子书提取 - BTool博客 - 在线工具软件,为开发者提供方便
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 一款一站式、开源、高质量的数据提取工具,支持:PDF 文档、网页和电子书提取

发表评论 取消回复