文章目录
引言
在网络的世界里,浏览器是我们与互联网沟通的桥梁。当我们在浏览器地址栏输入一个网址或点击一个链接时,浏览器就会向服务器发起一个HTTP请求。服务器接收到请求后,会处理并返回相应的数据,这通常是一个HTML页面、一张图片或一段视频。这些数据随后会被浏览器解析并展示给我们。
然而,在自动化测试或数据抓取的场景中,我们可能需要用程序模拟浏览器的行为,这就是Python的Urllib库大显身手的地方。Urllib是一个强大的内置库,它允许我们用代码来发送请求、接收响应,就像浏览器一样。
Urllib库简介
Python的Urllib库是一个用于处理URL的库,它提供了一系列丰富的功能来帮助我们与互联网进行交互。Urllib库主要由以下四个模块组成:
- request:用于发起网络请求。
- error:包含定义和处理请求错误的异常类。
- parse:用于解析URL以及URL的各个组成部分。
- robotparser:用于解析网站的robots.txt文件,以确定哪些页面可以被爬虫访问。
Request模块详解
Request模块是Urllib中使用最频繁的模块之一。它允许我们构造请求并发送到服务器。以下是一些常用方法和语法:
urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, *, cafile=None, capath=None, cadefault=False, context=None):发送GET或POST请求。url:请求的URL地址。data:发送的数据,通常用于POST请求。timeout:请求的超时时间。
代码示例:
import urllib.request
# 发起GET请求
response = urllib.request.urlopen('http://www.example.com')
print(response.read().decode('utf-8'))
# 发起POST请求
data = bytes(urllib.parse.urlencode({'key': 'value'}).encode('utf-8'))
response = urllib.request.urlopen('http://www.example.com', data)
print(response.read().decode('utf-8'))
Error模块与异常处理
Error模块提供了一些异常类,用于处理网络请求过程中可能遇到的错误。常见的异常有:
urllib.error.URLError:所有URL错误的基类。urllib.error.HTTPError:HTTP错误,包含状态码和错误信息。
异常处理示例:
try:
response = urllib.request.urlopen('http://www.example.com')
except urllib.error.URLError as e:
print('Failed to reach a server:', e.reason)
Parse模块与URL解析
Parse模块提供了一些函数来解析URL和构造URL。常用函数包括:
urllib.parse.urlparse(url):将URL分解为6个组件:scheme, netloc, path, params, query, fragment。urllib.parse.urlencode(query, doseq=False, encoding='utf-8'):将字典或列表字典编码成x-www-form-urlencoded格式的数据。
URL解析示例:
from urllib.parse import urlparse, urlencode
url = 'http://www.example.com/path?arg=value#anchor'
parsed_url = urlparse(url)
print(parsed_url.scheme, parsed_url.netloc, parsed_url.path)
data = {'key1': 'value1', 'key2': 'value2'}
encoded_data = urlencode(data)
print(encoded_data)
Robotparser模块
Robotparser模块用于解析网站的robots.txt文件,这个文件用来告诉爬虫哪些页面可以访问,哪些不可以。Robotparser模块的常用方法包括:
urllib.robotparser.RobotFileParser().set_url(url):设置robots.txt文件的URL。urllib.robotparser.RobotFileParser().can_fetch(user_agent, url):判断指定的爬虫是否可以访问某个URL。
Robotparser使用示例:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url('http://www.example.com/robots.txt')
if rp.can_fetch('*', 'http://www.example.com/somepage'):
print('This page can be fetched.')
else:
print('This page cannot be fetched.')
通过这些模块和方法,我们可以使用Python的Urllib库来构建复杂的网络请求,模拟浏览器行为,进行自动化测试或数据抓取。
模拟浏览器请求
在网络请求中,服务器可以通过请求头(Headers)来获取发起请求的客户端信息,例如使用的浏览器类型、操作系统、语言偏好等。通过模拟这些请求头信息,我们可以欺骗服务器,让它认为请求来自于一个真实的浏览器或移动设备,这对于某些需要特定用户代理(User-Agent)才能访问的网站尤其有用。
使用Request方法添加请求头信息
urllib.request.Request 方法允许我们自定义请求的各个方面,包括URL、请求方法、数据以及请求头。以下是构造请求头信息的基本步骤:
-
构造请求头字典:定义一个字典,包含所有需要的请求头信息,如
User-Agent、Accept-Language、Referer等。 -
创建Request对象:使用
urllib.request.Request构造函数创建一个请求对象,传入URL、数据(如果有)、请求头以及请求方法。 -
发送请求:使用
urllib.request.urlopen方法发送请求,并获取响应。
代码示例
以下是一个构造请求头信息并发起自定义GET请求的示例:
import urllib.request
import urllib.parse
# 构造请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept-Language': 'en-US,en;q=0.5',
'Referer': 'http://www.example.com/'
}
# 创建请求对象
url = 'http://www.example.com/somepage'
request = urllib.request.Request(url, headers=headers)
# 发送请求并获取响应
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
对于POST请求,除了设置请求头,我们还需要传递数据:
# 构造POST请求的数据
data = {'key1': 'value1', 'key2': 'value2'}.items()
data = urllib.parse.urlencode(data).encode('utf-8')
# 创建请求对象,指定POST方法
request = urllib.request.Request(url, data=data, headers=headers, method='POST')
# 发送请求并获取响应
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
通过这种方式,我们可以模拟浏览器或手机的请求,绕过一些简单的客户端验证,获取服务器的响应数据。然而,需要注意的是,某些网站可能使用更复杂的机制来验证请求的合法性,仅仅修改请求头可能不足以成功模拟请求。
- 实战演练:模拟登录操作
-
选择一个具体网站(如百度)作为示例。
-
抓取登录页面的请求参数和请求头信息。
-
这里的具体方法就是打开fiddler,然后打开百度的网页,选择登录,提交表单后抓取到这个表单信息,如下
-
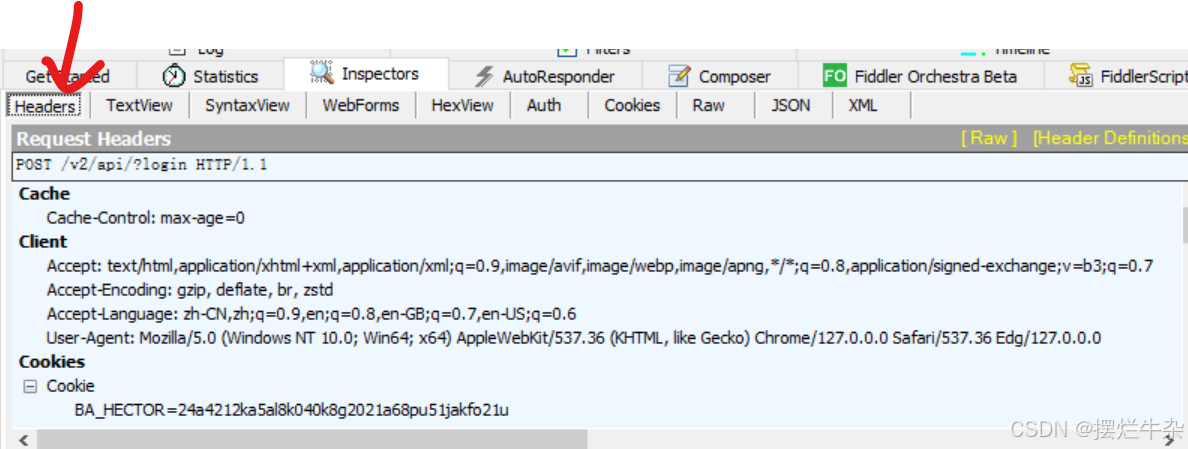
接着是我们的请求头信息:
-
-
编写代码模拟登录过程:
根据您的要求,下面是按照指定顺序组织的代码示例:
-
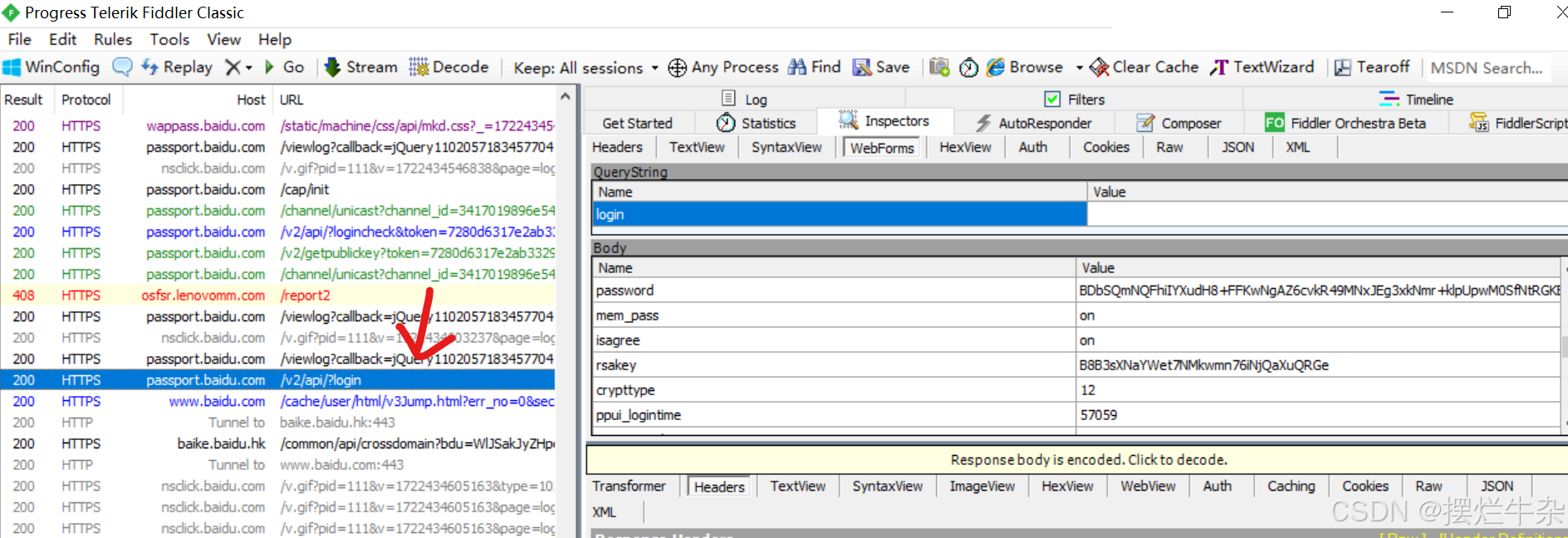
1. 设置请求URL和请求头
import urllib.parse
import urllib.request
import ssl
import json
# 创建SSL上下文
context = ssl.create_default_context()
# 设置请求URL(请替换为实际的登录API URL)
url = "https://www.baidu.com/some_actual_login_api"
# 设置请求头,模拟浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0"
}
2. 定义请求参数并转换为适当的格式
# 定义请求参数字典
params = {
"username": "your_username", # 替换为您的用户名
"password": "your_password", # 替换为您的密码
# 其他参数根据API要求添加
}
# 对参数字典进行URL编码
encoded_params = urllib.parse.urlencode(params).encode('utf-8')
3. 使用Request方法封装请求
# 使用Request方法封装请求
request = urllib.request.Request(
url,
data=encoded_params, # 发送编码后的参数
headers=headers, # 设置请求头
method='POST' # 指定请求方法为POST
)
4. 发送请求并获取响应
try:
# 发送请求并获取响应
with urllib.request.urlopen(request, context=context) as response:
response_data = response.read().decode('utf-8')
print("Response from server:", response_data)
except urllib.error.HTTPError as e:
print(f"HTTPError: {e.code} - {e.msg}")
except urllib.error.URLError as e:
print(f"URLError: {e.reason}")
except Exception as e:
print(f"An unexpected error occurred: {e}")
常用使用方法总结
- 使用
urlopen方法:进行基本的GET请求,获取网页内容。 - 自定义请求头:通过构造
Request对象,模拟浏览器或移动设备的请求头,以绕过一些简单的客户端验证。 - 异常处理:使用
error模块中的异常类来处理请求过程中可能出现的错误。 - URL解析:利用
parse模块解析和构造URL,处理查询字符串。 - 遵守Robot协议:使用
robotparser模块来检查爬虫是否被允许访问特定的页面。
模拟请求的重要性和实用性
使用Urllib进行模拟请求在多个领域都有其重要性和实用性:
- 自动化测试:自动化测试脚本可以模拟用户行为,测试网站的功能和性能。
- 数据抓取:爬虫程序可以通过模拟浏览器请求来获取网页数据,进行信息收集和分析。
- API交互:与Web API进行交互时,Urllib可以用来发送请求并接收响应。
- 跨平台兼容性:由于Urllib是Python的内置库,它在不同的操作系统上都能保持一致的行为,这使得编写跨平台的网络应用程序变得更加容易。
结语
虽然Urllib提供了丰富的功能来处理网络请求,但在实际应用中,我们还需要考虑到请求的效率、网站的反爬虫策略以及数据的合法使用等问题。合理利用Urllib库,不仅可以提高开发效率,还可以帮助我们更好地理解和使用网络资源。随着技术的不断进步,我们也应该持续学习新的库和框架,以适应不断变化的网络环境。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python爬虫入门03:用Urllib假装我们是浏览器

发表评论 取消回复