
个人主页:Weraphael
作者简介:目前正在学习c++和算法
️专栏:Linux
希望大家多多支持,咱一起进步!
如果文章有啥瑕疵,希望大佬指点一二
如果文章对你有帮助的话
欢迎 评论 点赞 收藏 加关注
一、线程ID
pthread_self函数是POSIX线程库(pthread)提供的一个函数,用于获取当前线程的线程ID。
【函数原型】
#include <pthread>
pthread_t pthread_self(void);
说明:
- 功能:
pthread_self函数返回调用线程的线程ID,类型为pthread_t。线程ID是一个唯一标识符,用于区分不同的线程。 - 返回值:返回当前线程的线程
ID。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <string>
using namespace std;
void *thread_task(void *)
{
while (true)
{
cout << "new thread say: My id is " << pthread_self() << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, thread_task, nullptr);
cout << "main thread say: new thread id is " << tid << endl;
pthread_join(tid, nullptr);
return 0;
}
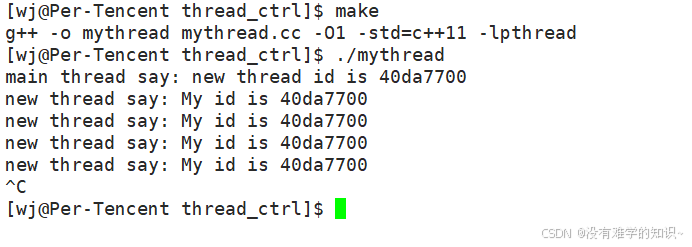
【程序结果】

奇怪?打印出来的pthread_t对象的值怎么和ps -aL命令显示的LWP值不一样?
打印出来默认是一个十进制数字,如果用十六进制打印又会是什么结果呢?
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <string>
using namespace std;
void *thread_task(void *)
{
while (true)
{
printf("new thread say: My id is %x\n", pthread_self());
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, thread_task, nullptr);
printf("main thread say: new thread id is %x\n", tid);
pthread_join(tid, nullptr);
return 0;
}
【程序结果】
我们发现:打印结果很像地址。所以这个pthread_t对象到底是什么东西呢?
【正文开始】
我们知道,Linux操作系统没有真正意义上的线程(用的是进程的数据结构来模拟的),只有轻量级进程的概念,所以操作系统不会直接提供线程的系统调用,只会提供轻量级进程的系统调用。
具体来说,Linux中的轻量级进程通过clone()系统调用来创建。clone()系统调用允许创建一个新的进程,可以共享某些资源(如内存空间),同时也可以选择不共享其他资源(如文件描述符),从而实现了轻量级进程的创建。

但是我们一般不会使用轻量级进程的系统调用,你看看上面的接口参数就知道了,clone()系统调用的参数非常复杂。所以,为了更方便地使用轻量级进程(即线程),开发者们开发了线程库(pthread),来提供更易用的接口。该库底层封装了clone()调用,隐藏了复杂的系统级细节,使得另一批开发者可以很简单的使用线程了。
但你不得会发现几个细节:
- 第一个参数
int (*fn)(void *):是一个函数指针。指向新进程(或轻量级进程)所要执行的函数,和pthread_create()的第三个参数是一样的。 - 第二个参数
void *child_stack:是新线程的栈空间。通常需要在调用clone()之前先为新进程分配一段栈空间,并将这个栈的起始地址传递给child_stack参数。 - 其他参数不关心。
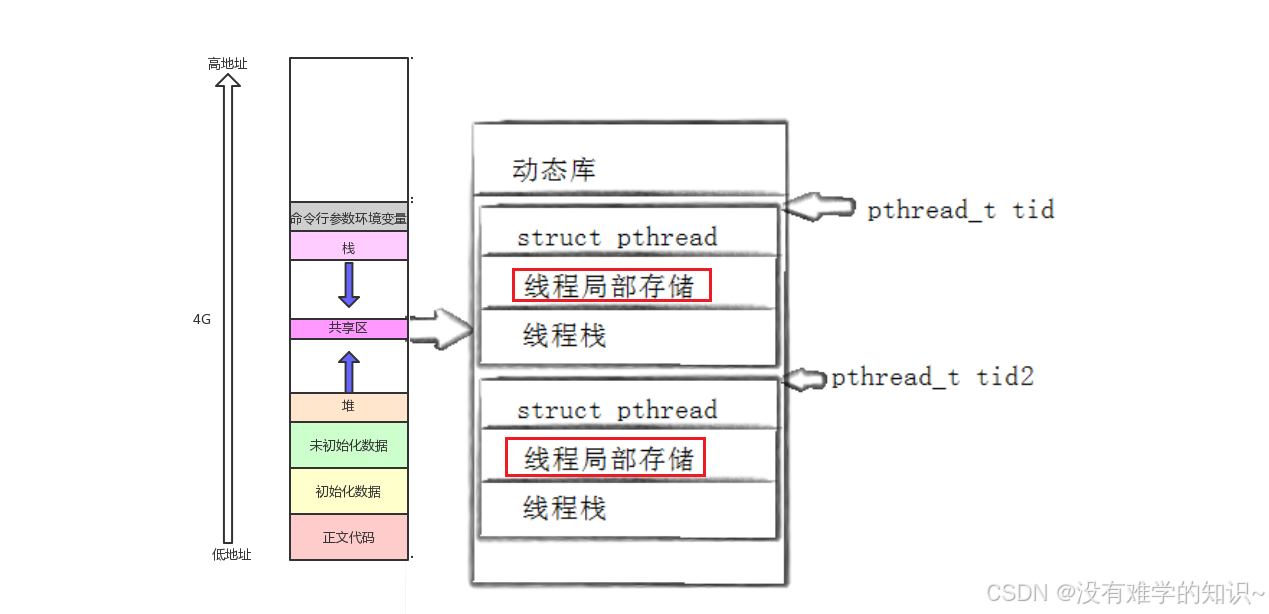
因为pthread库在Linux中是一个动态库,当我们调用此库的API时,操作系统要把它从磁盘加载到内存,然后通过页表映射到进程的地址空间的共享区中。此时该进程内的所有线程都是能看到这个动态库。
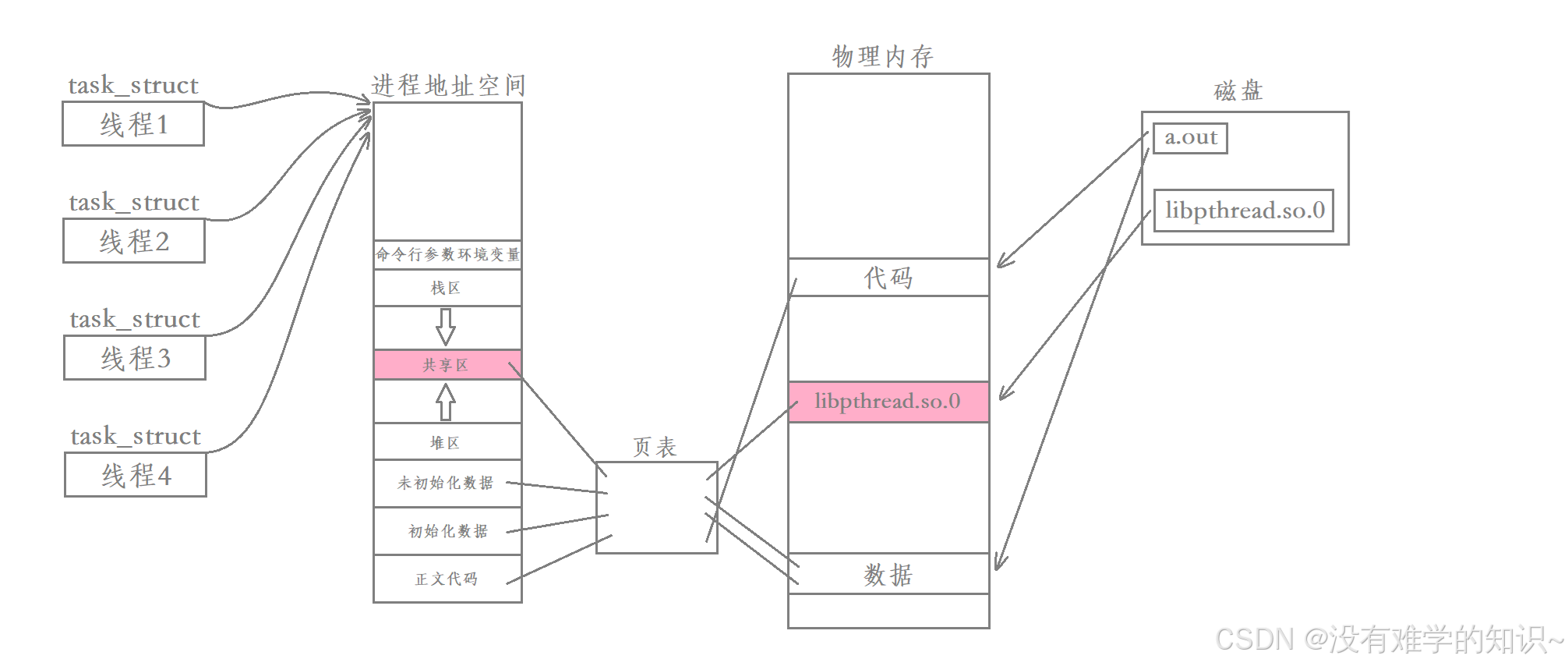
我们说每个线程都有自己私有的栈,其中主线程采用的栈是进程地址空间中原生的栈,而其余线程采用的栈就是在pthread库中开辟的,也就是在共享区中开辟的。而用户可能会创建多个线程,那么pthread库中就有多个回调函数、私有栈、线程标识符等属性。因此,为了区分这些属性属于哪个线程,pthread库也要对这些线程进行管理,即先描述再组织。
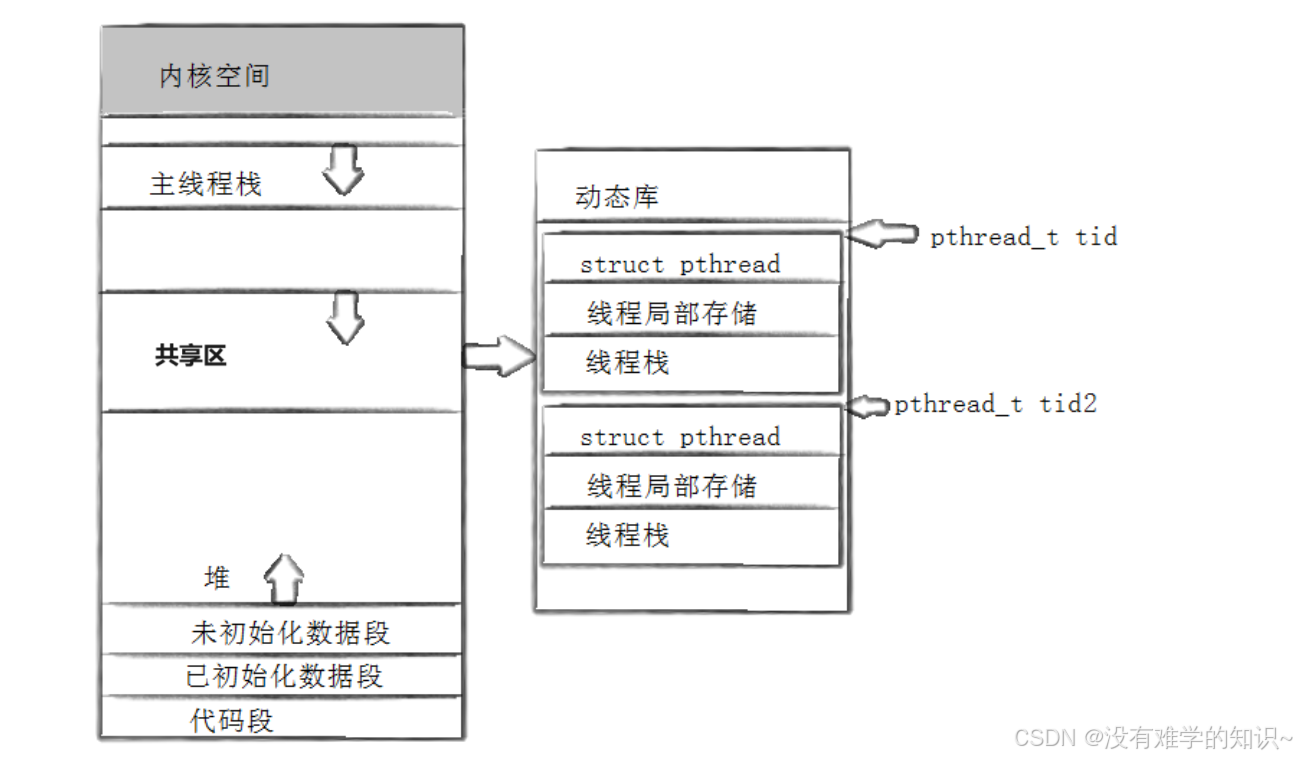
所以,除了主线程以外,我们每创建一个线程,在线程库当中就要为该线程创建用户层的线程控制块TCB(包含线程的属性)。而这种由用户空间的线程库(pthread库)管理和调度的线程我们称之为用户级线程。
回过头来,因此我们要找到一个用户级线程只需要找到该线程在进程地址空间中共享区的起始地址,然后就可以获取到该线程的各种信息。 所以说,pthread_t对象本质就是进程地址空间的共享区上的一个虚拟地址。因为同一个进程中所有的虚拟地址都是不同的,因此可以用它来唯一区分每一个线程。
另外,ps -aL命令显示的LWP值可以理解为:LWP是Linux内核管理轻量级进程的标识符。因为不管是进程还是线程,都由相同的数据结构task_struct表示;又因为线程是轻量级进程,是操作系统调度的基本单位。因此,LWP值属于内核进程调度的范畴,确保线程能够有效地被调度。
总结:
Linux线程的概念是由pthread库来维护和实现的。即Linux的线程 = 用户级线程 + 内核的LWP。- 线程可以分为用户级线程和内核级线程,而
Linux就属于用户级线程。
二、线程独立栈
线程之间存在独立的栈结构,并且栈是由库给我们提供的(上面说过),这可以保证彼此之间执行任务时不会相互干扰。
验证方式:创建5个线程调用同一个函数,并打印该函数中的临时变量的地址。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
using namespace std;
void *thread_task(void *)
{
int stack_tmp = 1;
printf("线程id: 0x%x, 变量stack_tmp的地址: %p\n", pthread_self(), &stack_tmp);
return nullptr;
}
int main()
{
vector<pthread_t> tids;
for (int i = 1; i <= 5; i++)
{
pthread_t tid;
/*
注:不要给pthread_create的第四个参数传对传for循环中的对象。
因为当第一次for循环结束后,for循环内的对象销毁,
那么第一个线程参数的指针就会指向已经销毁的对象,造成野指针!
如果真的想要在传循环中的对象,可以现在堆上创建对象
*/
pthread_create(&tid, nullptr, thread_task, nullptr);
tids.push_back(tid);
sleep(1);
}
for (int i = 0; i < tids.size(); i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}
【程序结果】
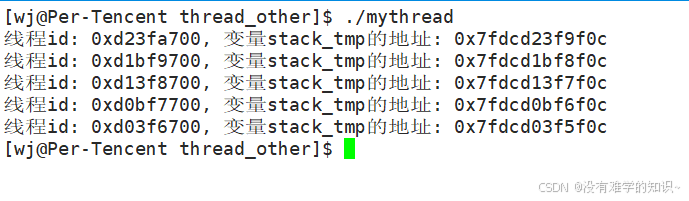
可以看到5个线程调用同一个函数threadRun,打印的 “同一个” 变量stack_tmp的地址都是不相同的,说明线程在调用threadRun函数使用的是自身的栈结构,这足以证明线程独立栈的存在。
但如果我们主线程就想要访问上面任意一个线程的变量,可以做到吗?
当然可以做到,因为主线程和其他线程共享地址空间,其他线程的栈是由共享区中的库为线程创建的,因此主线程一定是能做到的。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
using namespace std;
int *p = nullptr; // 获取第一个线程中的变量stack_tmp
string toHex(pthread_t t)
{
char buffer[64];
snprintf(buffer, sizeof(buffer), "0x%x", t);
return buffer;
}
struct threadData
{
string threadname;
};
void InitThreadData(threadData *td, int number)
{
td->threadname = "thread-" + to_string(number);
}
void *thread_task(void *args)
{
threadData *td = (threadData *)args;
int stack_tmp = 1;
if (td->threadname == "thread-2")
{
p = &stack_tmp;
}
int cnt = 3;
while (cnt--)
{
cout << "线程名字:" << td->threadname
<< ", 变量stack_tmp的地址: " << &stack_tmp
<< ", stack_tmp = " << stack_tmp << endl;
sleep(1);
}
return nullptr;
}
int main()
{
vector<pthread_t> tids;
for (int i = 1; i <= 3; i++)
{
pthread_t tid;
threadData *td = new threadData;
InitThreadData(td, i);
pthread_create(&tid, nullptr, thread_task, (void *)td);
tids.push_back(tid);
sleep(1);
}
sleep(1);
cout << "main thread get a thread_two local value, val: " << *p
<< ", &val: " << p << endl;
for (int i = 0; i < tids.size(); i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}
【程序结果】
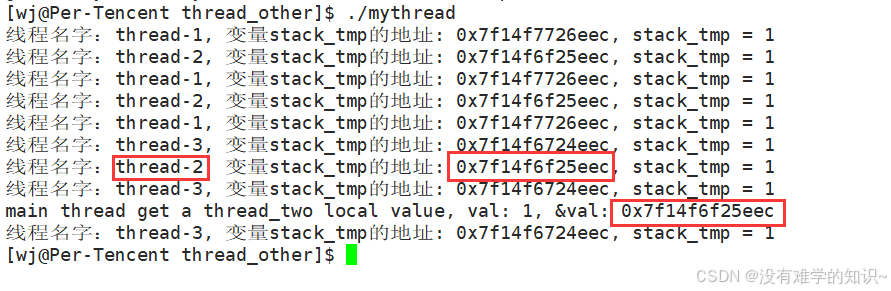
线程和线程当中没有秘密,只不过我们要求每一个线程有自己独立的栈,但是线程是共享地址空间的,线程的栈上的数据,也是可以被其他线程看到并且访问的。如果我们一个线程想要访问另一个线程的值,当然可以访问,只不过我们平时禁止这样做。因此我们说线程之间的栈是独立的,而不是私有的!
总结
- 所有线程都要有自己独立的栈结构(独立栈),其中主线程采用的栈是进程地址空间中原生的栈,而其余线程采用的栈就是在
pthread库中开辟的。- 线程和线程当中没有秘密。
三、线程局部存储
线程之间共享全局变量,对全局变量 进行操作时,会影响其他线程
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <vector>
using namespace std;
int cnt = 1;
void *thread_task(void *)
{
printf("thread: 0x%x, cnt = %d, &cnt = %p\n", pthread_self(), cnt, &cnt);
++cnt;
return nullptr;
}
int main()
{
vector<pthread_t> tids;
for (int i = 1; i <= 3; i++)
{
pthread_t tid;
pthread_create(&tid, nullptr, thread_task, nullptr);
tids.push_back(tid);
sleep(1);
}
for (int i = 0; i < tids.size(); i++)
{
pthread_join(tids[i], nullptr);
}
return 0;
}
【程序结果】

从以上结果看出,三个线程使用的全局变量cnt是一个共享资源,即全局变量是被所有的线程看到并同时访问的。
如何让全局变量私有化呢?即每个线程看到的全局变量不同。
可以用 __thread修饰,修饰之后,全局变量不再存储至全局数据区,而且存储至线程的局部存储区中。注意:__thread是编译器提供的特性,只能定义内置类型,不能用来修饰自定义类型。
__thread int cnt = 1;

如上,修饰之后,每个线程确实看到了不同的 “全局变量”。但此时的 “全局变量” 的地址变大了。
这是因为被__thread修饰后的变量不再存储在全局数据区 中,而是存储在线程的局部存储区中。线程的局部存储区位于 共享区,而共享区(处于堆栈之间)的地址是天然大于全局数据区的。
用
__thread修饰变量有什么好处呢?
- 线程安全性:每个线程都有自己独立的变量实例,不同线程之间互不干扰。这种方式避免了多线程并发访问全局变量时可能出现的竞态条件和数据污染问题。
- 效率提高:线程局部变量的访问速度通常比全局变量更快。因为线程局部变量存储在每个线程自己的内存空间中,线程可以直接访问自己的变量实例,而不需要加锁或者进行其他同步操作。
四、代码
Gitee链接:点击跳转
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Linux】深入理解线程

发表评论 取消回复