线性回归的优缺点:
优点:结果易于理解,计算上不复杂
缺点:对非线性的数据拟合不好
使用数据类型:数值型和标称型数据。
回归的目的是预测数值型的目标值。最直接的办法是依据输入写出一个目标值的计算公式。例如预测汽车的功率大小,可能会这么计算:
HorsePower=0.0015*annualSalary-0.99*hoursListeningToPublicRadio
这就是所谓的回归方程,其中的0.0015和-0.99称作回归系数,求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数城西输入值,再将结果全部加在一起,就得到了预测值。
回归一般都是指线性回归。线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。
需要注意的是,存在另一种称为分线性回归的回归模型,该模型不认同上面的做法,比如认为输出可能是输入的乘积。这样,上面的功率计算公式也可以写做:
HorsePower=0.0015*annualSalary/hoursListeningToPublicRadio
这就是一个非线性回归的例子。
回归的一般方法:
1、收集数据:采用任意方法收集数据
2、准备数据:回归需要数值型数据,标称型数据将被转成二值型数据
3、分析数据:绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归数据之后,可以将新拟合线绘在图上作为对比
4、训练数据:找到回归系数
5、测试算法:使用
或者预测值和数据的拟合度,来分析模型的效果
6、使用算法:使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续性数据而不仅仅是离散的类别标签
假定输入数据存放在矩阵X中,而回归系数存放在矩阵w中。那么,对于给定的数据X,预测结果将会通过
平方误差可以写做:

用矩阵表示还可以写做


w上方的小标记表示,这是当前可以估计出的w的最优解。从现有数据上估计出的w可能并不是数据中的真实w值,所以这里使用了一个“帽”符号来表示它仅仅是w的一个最佳估计。
指的注意的是,上述公式中包含
上述的最佳w求解是统计学中的常见问题,除了矩阵方法外还有很多其他方法可以解决。通过调用NumPy库里的矩阵方法,我们可以仅使用几行代码就完成所需功能。该方法也称作OLS,意思是“普通最小二乘法”。
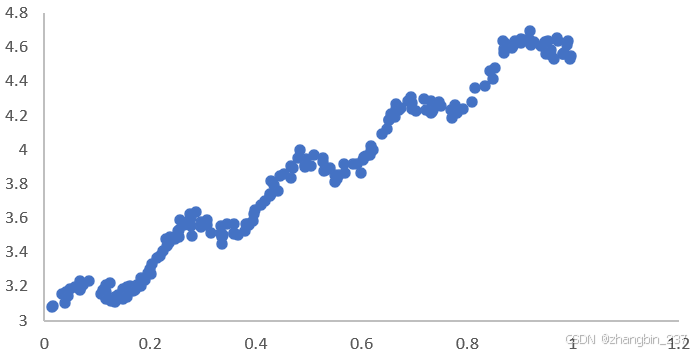
针对下面的数据,试验怎样找到最佳拟合直线。
代码实现:
from numpy import *
def loadDataSet(fileName):
numFeat=len(open(fileName).readline().split('\t'))-1
dataMat=[]
labelMat=[]
fr=open(fileName)
for line in fr.readlines():
lineArr=[]
curLine=line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
def standRegres(xArr,yArr):
xMat=mat(xArr)
yMat=mat(yArr).T
xTx=xMat.T*xMat
if linalg.det(xTx)==0.0:
print('行列式为0')
return
ws=xTx.I*(xMat.T*yMat)
return ws代码中,第一个函数loadDataSet()用于打开一个用tab分隔的文本文件,默认文件每行的最后一个值是目标值。
第二个函数standRegres()用于计算最佳拟合直线。该函数首先读入x和y并将它们保存到矩阵中;然后计算
NumPy的线性代数库还提供一个函数来解未知矩阵,如果使用该函数,那么代码ws=xTx.T*(xMat.T*yMat)应该写成ws=linalg.solve(xMat,xMat.T*yMat.T)。
查看实际运行效果:
xArr,yArr=loadDataSet('ex0.txt')
print(xArr[0:2])
ws=standRegres(xArr,yArr)
print(ws)
变量ws存放的就是回归系数。在用内积来预测y的时候,第一维将乘以前面的常数X0,第二维将乘以输入变量X1.因为前面假定了X0=1,所以最终会得到y=ws[0]+ws[1]*X1。这里的y实际是预测出的,为了和真实的y值区分开来,我们将它记为yHat。下面使用新的ws值计算yHat:
xMat=mat(xArr)
yMat=mat(yArr)
yHat=xMat*ws绘出数据集散点图和最佳拟合直线图:
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0])
xCopy=xMat.copy()
xCopy.sort(0)
yHat=xCopy*ws
ax.plot(xCopy[:,1],yHat)
plt.show()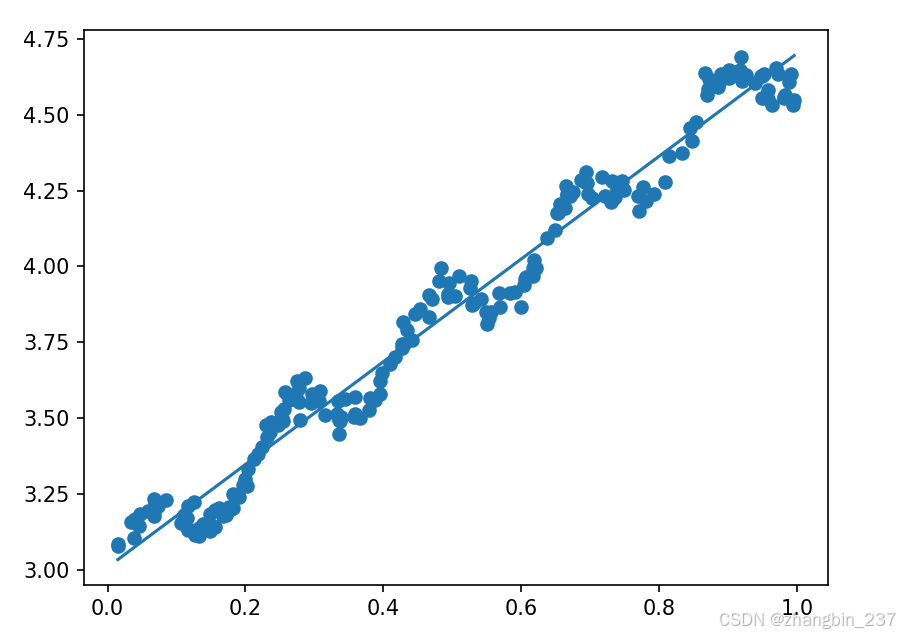
几乎任意数据集都可以用上述方法建立模型。
为了评估模型的好坏,有一种方法可以计算预测值yHat序列和真实值y序列的匹配程度,那就是计算这两个序列的相关系数。
在Python中,NumPy库提供了相关系数的计算方法:可以通过命令corrcoef(yEstimate,yActual)来计算预测值和真实值的相关性:
yHat=xMat*ws
print(corrcoef(yHat.T,yMat))
该矩阵包含所有两两组合的相关系数。可以看到对角线上的数据为1.0,因为yMat和自己的匹配是最完美的,而yHat和yMat的相关系数为0.985。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Python机器学习】回归——用线性回归找到最佳拟合直线

发表评论 取消回复