题目
以数组 intervals 表示若干个区间的集合,其中单个区间为intervals[i] = [starti, endi],且endi大于starti。请合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3], [2,6], [8,10], [15,18]]
输出:[[1,6], [8,10], [15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6]示例 2:
输入:intervals = [[1,4], [4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间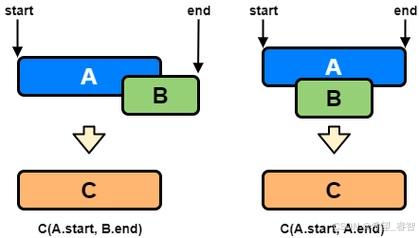
分治法
使用分治法来解决本题的基本思想是:将整个问题划分为更小的子问题,并递归地解决这些子问题,最后将子问题的解合并起来形成最终的解决方案。使用分治法求解本题的主要步骤如下。
1、排序。首先,对输入的区间按起始位置进行排序。
2、递归划分。将排序后的区间列表递归地分为两半,直到每个子问题只包含一个或零个区间。
3、合并区间。在递归返回的过程中,逐步合并相邻的区间。如果两个相邻的区间有重叠部分,则合并它们。如果没有重叠,则直接将它们添加到结果中。
根据上面的算法步骤,我们可以得出下面的示例代码。
def merge_intervals_by_divide_conquer(intervals):
if not intervals:
return []
# 对区间按起始位置进行排序
intervals.sort(key=lambda x: x[0])
# 使用分治策略合并区间
def merge_intervals(intervals):
if len(intervals) <= 1:
return intervals
mid = len(intervals) // 2
left_intervals = merge_intervals(intervals[:mid])
right_intervals = merge_intervals(intervals[mid:])
return merge_sorted_intervals(left_intervals, right_intervals)
# 合并两个已排序的区间列表
def merge_sorted_intervals(left, right):
merged = []
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i][1] < right[j][0]:
merged.append(left[i])
i += 1
elif right[j][1] < left[i][0]:
merged.append(right[j])
j += 1
else:
start = min(left[i][0], right[j][0])
end = max(left[i][1], right[j][1])
merged.append([start, end])
i += 1
j += 1
# 添加剩余的区间
while i < len(left):
merged.append(left[i])
i += 1
while j < len(right):
merged.append(right[j])
j += 1
return merged
# 合并操作
return merge_intervals(intervals)
intervals = [[1,3], [2,6], [8,10], [15,18]]
print(merge_intervals_by_divide_conquer(intervals))
intervals = [[4,5], [1,4]]
print(merge_intervals_by_divide_conquer(intervals))排序+遍历法
使用排序+遍历法解决区间合并问题的基本思想是:先对区间按照起始位置进行排序,然后遍历排序后的区间列表,并在遍历过程中合并重叠的区间。使用排序+遍历法求解本题的主要步骤如下。
1、排序。首先,对输入的区间按起始位置进行排序。
2、遍历。从第一个区间开始遍历,检查当前区间是否与前一个区间有重叠部分。如果有重叠,则合并这两个区间。如果没有重叠,则将当前区间添加到结果列表中。
3、合并。当发现重叠区间时,更新当前区间的结束位置为两个区间结束位置的最大值。
根据上面的算法步骤,我们可以得出下面的示例代码。
def merge_intervals_by_sort_traversal(intervals):
if not intervals:
return []
# 对区间按起始位置进行排序
intervals.sort(key=lambda x: x[0])
merged = []
for interval in intervals:
if not merged or merged[-1][1] < interval[0]:
# 如果结果列表为空,或者当前区间的起始位置大于前一个区间的结束位置
merged.append(interval)
else:
# 更新前一个区间的结束位置为两个区间结束位置的最大值
merged[-1][1] = max(merged[-1][1], interval[1])
return merged
intervals = [[1,3], [2,6], [8,10], [15,18]]
print(merge_intervals_by_sort_traversal(intervals))
intervals = [[4,5], [1,4]]
print(merge_intervals_by_sort_traversal(intervals))总结
如果需要处理大量的区间,并且希望在处理过程中保持较高的效率,那么分治法可能不是一个最佳的选择。这主要是基于以下几点:一是分治算法涉及递归调用,这会导致额外的函数调用开销,尤其是在递归层数较多的情况下;二是分治算法在递归返回时需要合并子问题的解,这可能涉及到多个区间的比较和合并操作;三是分治算法的实现需要递归逻辑和合并操作,对于初学者来说可能不够直观,调试也相对困难。
对于此类问题,通常的做法是直接使用排序+遍历的方法。排序+遍历法的时间复杂度主要由排序决定,为O(n*log(n)),其中n是区间的数量。其空间复杂度为O(n),用来存储合并后的区间。排序+遍历法是解决区间合并问题最常用且最有效的方法之一,适用于大多数场景。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python面试宝典第28题:合并区间

发表评论 取消回复