发表时间:cvpr2024
论文链接:https://readpaper.com/pdf-annotate/note?pdfId=2357936887983293952¬eId=2426262228488986112
作者单位:University of Wisconsin–Madison
Motivation:现在的多模态模型都关注整张图像的理解,它们缺乏在复杂场景中处理特定区域信息的能力。
解决方法:为了应对这一挑战,我们引入了一种新的多模态模型,能够解码任意(自由形式)的视觉提示。这允许用户直观地标记图像并使用“红色边界框”或“指向箭头”等自然线索与模型交互。

本文主要贡献是:
-
我们引入了一种新的多模态模型,用于使用自然语言和任意视觉提示与图像的直观交互,增强了用户可访问性和模型灵活性。
-
我们开发了一种visual referal approach(视觉引导方法),将视觉提示直接叠加到图像上,在不影响性能的情况下简化模型架构。
-
我们的模型 ViP-LLAVA 在已建立的基准上在区域理解任务上取得了最先进的结果,surpassing specialized region encoding models。
-
我们介绍了 ViP-Bench,用于评估多模态模型具有任意视觉提示的区域理解能力。
实现方式:模型架构:在将视觉提示通过Alpha混合叠加(Alpha混合指的是一种图像处理技术,用于将两个或多个图像合成在一起,同时考虑每个图像的透明度(Alpha通道))到原始图像后,将生成的图像输入到视觉编码器中以获取multi-level visual features。这些特征被concat起来并输入到LayerNorm和MLP层以形成visual token。然后,visual token和文本指令标记被输入到大型语言模型中,通过自回归的方式得到输出。
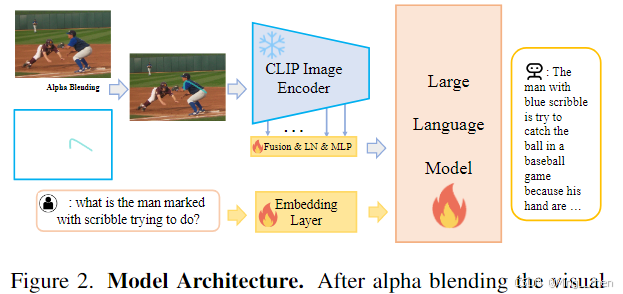
具体结构:
-
visual model, we choose CLIP-336px
-
Vicuna v1.5 [31] as the language encoder
-
a 2-layer MLP is utilized。
-
该架构与 llava 架构类似,只是多模态投影器采用一组Fusion+LN+MLP的映射。
通过CLIP做视觉提示词嵌入:

视觉提示词设计:
文中也提出了一个视觉指令微调数据集,数据集包含了520K的图像-文本对,源数据都是一些开源的数据集,比如RefCOCOg、PointQA-LookTwice、Visual Genome、Flicker 30k Entities、Visual Commonsense Reasoning和Visual7W。作者对源数据的图片用各种形式的视觉提示词做了自动化标注。
对于只包含bounding box标注的图像来说,视觉提示可以是矩形框、椭圆和箭头中的一种。对于箭头来说,需要保证其落在图像范围之内。
对于包含像素级别的mask标注的图像来说,视觉提示可以是 矩形框、椭圆、点、三角形、mask、mask边缘、箭头、涂鸦等。

Fig 3 可视化视觉提示类型,从左上到右下依次是:掩膜轮廓、椭圆、边界框、三角形、涂鸦、点、箭头和掩膜。请注意,提示不仅形状多样,而且颜色、透明度值、宽度、比例和方向也各不相同
ViP-LLaVA uses 8 visual prompts: rectangles, ellipses, points, scribbles, triangles, masks, mask contours, and arrows. 每种提示随机颜色,随机位置。 For referencing specific regions, we replace the <region> text with the color and shape description, such as red scribble.
可选择的区域级别的指令微调数据:
文中用到的训练数据包括上面介绍的region-level的视觉提示数据,也包括图像级别的视觉提示数据,主要来自于LLaVA v1.5的数据。本文还借助于GPT-4V生成了区域级别的指令微调数据集,主要做法如下:
-
原图和绘制了视觉提示的图片作为GPT-4V的输入,同时也提供了数据集原本自带的ground-truth的标注还有系统提示词,模型会返回<visual prompt, text prompt, text output>的triplets。
-
为了让GPT-4V识别对应的物体或者区域,作者提供了一些文本描述,比如针对单物体的<within red mask>或者多物体的(<within red box>,<within blue box>)。在训练的时候,会把这些位置用Fig 3所示的8种视觉提示中的一种来填充。一共得到了13k高质量的区域级别的视觉指令微调数据,包括7k单物体区域和6k多物体区域的。
训练方式:三个阶段训练
第一阶段:第一步使用558k BLIP caption的图像-文本对数据 预训练多模态的connector。
第二阶段:第二步用LLaVA 1.5的指令微调数据和本文提到的区域级别的指令微调数据训练模型,两个阶段都训了1个epoch,采用了8个Nvidia A100 GPU;
第三阶段:第三步用到了13K高质量指令微调数据集以及从stage 2训练所用数据集中采样的13k数据集,对模型做微调,也是采用了8个A100 GPU。
第二阶段和第三阶段是按照fig2的结构进行微调(只有Clip image encoder是冻住的)。
实验:Evaluation on Region Reasoning Benchmarks,ViP-Bench Evaluation Results
结论:ViP-LLAVA 的直观设计利用了自然语言交互和视觉标记,简化了图像注释过程,同时增强了visual references的清晰度(可以使用很多形式的visual references)。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts

发表评论 取消回复