目录
在日常工作和学习中,我们常常需要处理各种PDF文件。其中对文字内容进行查找和高亮是非常常见的需求。以工作场景为例,我们可能需要快速检索一份长篇报告中的关键信息。利用PDF的查找功能,我们能够迅速定位到相关内容,大幅提高工作效率。同时,通过高亮标注重要信息,我们能够方便地进行日后复习和回顾。这篇博客将探讨如何使用Python实现在PDF中查找和高亮文字,主要涵盖以下内容:
- Python在PDF中查找和高亮文字并统计出现次数和页码
- Python在PDF的特定页面区域中查找和高亮文字
- Python使用正则表达式在PDF中查找和高亮文字
- Python在PDF中查找文字并获取它的坐标位置
- 其他查找条件设置
使用工具
要在Python应用程序中查找和高亮PDF中的文字,可以使用Spire.PDF for Python库。它支持在Python应用程序中创建、读取、操作和转换PDF文档。
你可以通过在终端运行以下命令来从PyPI安装Spire.PDF for Python:
pip install Spire.PDFPython在PDF中查找和高亮文字并统计出现次数和页码
Spire.PDF for Python提供了PdfTextFinder类,用于查找PDF页面上的文字。使用该类的Find() 方法,你可以搜索特定的文字或句子。找到后,你可以为其设置高亮颜色,同时还能获取该文字在PDF文档中出现的次数以及所在的页码信息。
下面是在PDF中查找和高亮文字的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 初始化一个计数器来跟踪文本出现的次数以及一个列表来存储文本出现的页码。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 使用PdfTextFinder.Find()方法查找特定文本。该方法将返回一个PdfTextFragment对象列表,其中每个对象代表该文本在文档中的一个实例。
- 遍历列表中的PdfTextFragment对象,使用PdfTextFragment.Highlight()方法高亮每个实例,同时递增文本出现的次数并将当前页码添加到列表。
- 使用PdfDocument.SaveToFile()方法保存结果文档。
- 打印文本在PDF中出现的次数和页码。
下面是在PDF中查找和高亮文字的Python代码:
from spire.pdf.common import *
from spire.pdf import *
# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")
# 初始化一个计数器来跟踪文本出现的次数
occurrence_count = 0
# 初始化一个列表来存储页码
page_numbers = []
# 遍历文档中的页面
for i in range(doc.Pages.Count):
page = doc.Pages[i]
# 创建 PdfTextFinder 实例
finder = PdfTextFinder(page)
# 查找特定文本
results = finder.Find("Python")
# 遍历找到的所有实例
for text in results:
# 设置高亮颜色
text.HighLight(Color.get_Yellow())
# 递增文本出现次数
occurrence_count += 1
# 将页码添加到列表中
page_numbers.append(i+1)
# 保存结果文档
doc.SaveToFile("查找和高亮文本.pdf")
doc.Close()
# 打印出现次数和页码
print(f"文本 'Python' 在 PDF 中出现了 {occurrence_count} 次。")
print(f"该文本出现在以下页码: {', '.join(map(str, page_numbers))}")

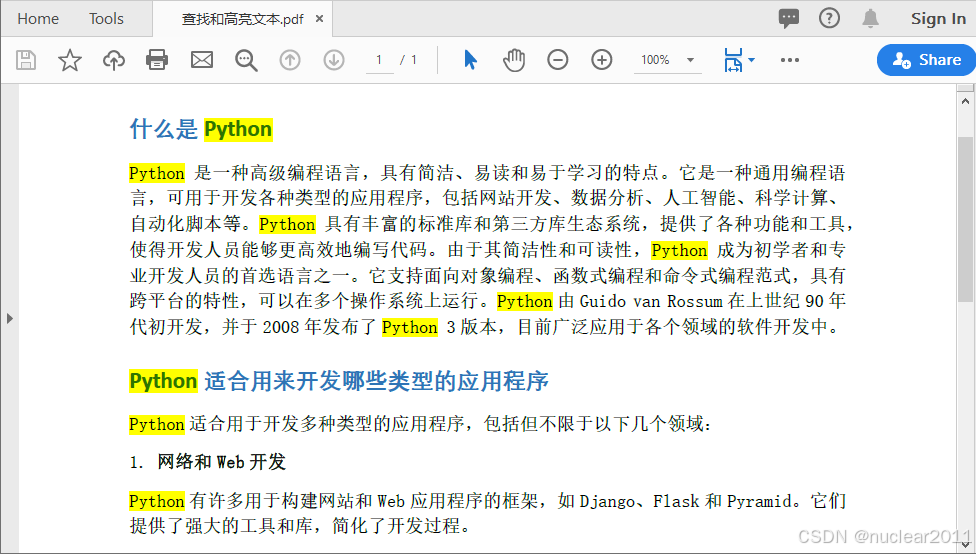
Python在PDF的特定页面区域中查找和高亮文字
除了在PDF文档的所有页面或特定页面中查找和高亮文字(见以上例子)以外,你还可以在特定的页面区域中查找和高亮文字。使用PdfTextFinder.Options.Area属性,你可以指定查找的页面区域。
下面是在PDF的特定页面区域中查找和高亮文字的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 通过PdfTextFinder.Options.Area属性指定查找的页面区域。
- 使用PdfTextFinder.Find()方法查找特定文本。
- 使用PdfTextFragment.Highlight()方法高亮每个找到的实例。
- 使用PdfDocument.SaveToFile()方法保存结果文档。
下面是在PDF的特定页面区域中查找和高亮文字的Python代码:
from spire.pdf.common import *
from spire.pdf import *
# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")
# 遍历文档中的页面
for i in range(doc.Pages.Count):
page = doc.Pages[i]
# 创建 PdfTextFinder 实例
finder = PdfTextFinder(page)
# 指定查找的页面区域
finder.Options.Area = RectangleF(0.0, 0.0, 300.0, 300.0)
# 查找特定文本
results = finder.Find("Python")
# 遍历找到的所有实例
for text in results:
# 设置高亮颜色
text.HighLight(Color.get_Yellow())
# 保存结果文档
doc.SaveToFile("在页面区域中查找和高亮文本.pdf")
doc.Close()
Python使用正则表达式在PDF中查找和高亮文字
要在PDF中使用正则表达式查找和高亮文字,你首先需要将PdfTextFinder.Options.Parameter属性设置为TextFindParameter.Regex,以启用正则表达式查找。然后,你需要将正则表达式作为参数传递给Find()方法来实现基于正则表达式查找文字。
下面是使用正则表达式在PDF中查找和高亮文字的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 将PdfTextFinder.Options.Parameter属性设置为TextFindParameter.Regex以启用正则表达式文本查找模式。
- 将正则表达式传递给PdfTextFinder.Find()方法来实现基于正则表达式查找特定文本。
- 使用PdfTextFragment.Highlight()方法高亮每个匹配到的实例。
- 使用PdfDocument.SaveToFile()方法保存结果文档。
下面是使用正则表达式在PDF中查找和高亮文字的Python代码:
from spire.pdf.common import *
from spire.pdf import *
# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("示例.pdf")
# 遍历文档中的页面
for i in range(doc.Pages.Count):
page = doc.Pages[i]
# 创建 PdfTextFinder 实例
finder = PdfTextFinder(page)
# 设置文本查找条件为使用正则表达式查找
finder.Options.Parameter = TextFindParameter.Regex
# 查找以符号 “#” 开头的文本
results = finder.Find("""\\#\\w+\\b""")
# 遍历找到的所有实例
for text in results:
# 设置高亮颜色
text.HighLight(Color.get_Yellow())
# 保存结果文档
doc.SaveToFile("使用正则表达式查找和高亮文本.pdf")
doc.Close()
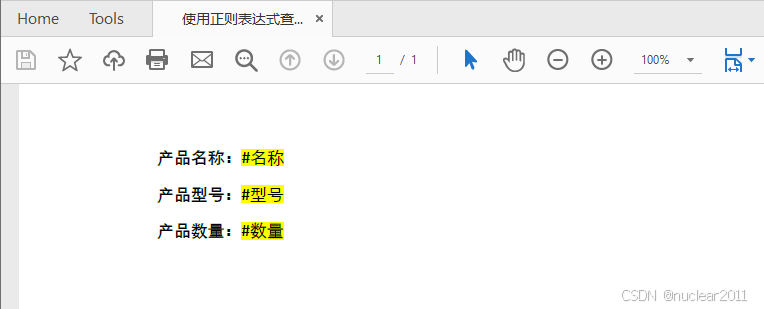
Python在PDF中查找文字并获取它的坐标位置
在找到特定的文字后,你还可以获取它的相关信息,例如它的坐标位置。下面是在PDF中查找文字并获取它的坐标信息的具体步骤:
- 创建PdfDocument类的实例并使用PdfDocument.LoadFromFile()加载PDF文档。
- 遍历PDF中的页面。
- 为每个页面创建一个PdfTextFinder实例并将当前页面对象作为参数传入该类的构造函数。
- 使用PdfTextFinder.Find()方法查找特定文本。
- 使用PdfTextFragment.Positions[0].X和PdfTextFragment.Positions[0].Y属性获取每个找到的实例的X和Y坐标。
下面是在PDF中查找文字并获取它的坐标位置的Python代码:
from spire.pdf.common import *
from spire.pdf import *
# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")
# 遍历文档中的页面
for i in range(doc.Pages.Count):
page = doc.Pages[i]
# 创建 PdfTextFinder 实例
finder = PdfTextFinder(page)
# 查找特定文本
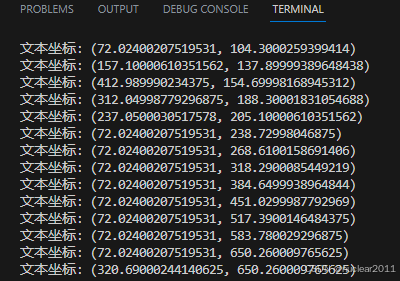
results = finder.Find("Python")
# 遍历找到的所有实例
for text in results:
# 打印当前实例的坐标信息
print(f"文本坐标: ({text.Positions[0].X}, {text.Positions[0].Y})")
doc.Close()
其他查找条件设置
Spire.PDF for Python还支持设置其他查找条件,如不区分大小写或全词匹配。具体代码如下:
from spire.pdf.common import *
from spire.pdf import *
# 创建 PdfDocument 类的对象
doc = PdfDocument()
# 加载 PDF 文件
doc.LoadFromFile("什么是python.pdf")
# 遍历文档中的页面
for i in range(doc.Pages.Count):
page = doc.Pages[i]
# 创建 PdfTextFinder 实例
finder = PdfTextFinder(page)
# 设置文本查找条件为不区分大小写和全词匹配
finder.Options.Parameter = TextFindParameter.IgnoreCase
finder.Options.Parameter = TextFindParameter.WholeWord
# 查找特定文本
results = finder.Find("Python")
# 遍历找到的所有实例
for text in results:
# 设置高亮颜色
text.HighLight(Color.get_Yellow())
# 保存结果文档
doc.SaveToFile("其他查找条件.pdf")
doc.Close()
这篇文章介绍了使用Python在PDF中查找和高亮文字的多种不同的场景,你需要根据自己的实际情况对代码中的文档路径、待查找的文字、页面区域、或正则表达式等内容进行相应的修改。
本文完结。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python PDF文本处理技巧 - 查找和高亮文字

发表评论 取消回复