模型评估
划分数据集为训练集、验证集、测试集
60%训练集、20%测试集和验证集
x_train,x_,y_train,y_=train_test_split(X_train,y_train,test_size=0.4)
x_cv,x_test,y_cv,y_test=train_test_split(x_train,y_train,test_size=0.5)
交叉验证-模型选择
使用交叉验证计算模型的损失 J c v ( w , b ) J_{cv}(w,b) Jcv(w,b)来评估和选择表现最好的模型。
不能使用测试集来选择模型:因为测试集是对模型效果的乐观估计!
模型选择
偏差和方差
回归问题:不是从预测数据和原始数据来看,而主要指的是训练集和验证集的损失
分类问题:分类错误的比例
偏差和方差客观反映了模型的拟合情况:欠拟合和过拟合
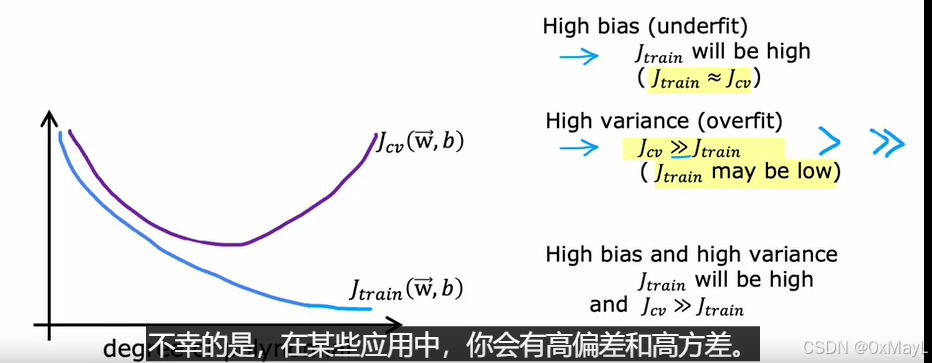
高偏差bias
J t r a i n = J c v 且 J t r a i n 较大 J_{train}=J_{cv}且J_{train}较大 Jtrain=Jcv且Jtrain较大
大小上训练集和验证集差不多,但是训练集的损失较大
高方差variance
J t r a i n < < J c v J_{train}<<J{cv} Jtrain<<Jcv
验证集与训练集的损失有较大出入,且验证集明显大于训练集
正则化
正则化系数 λ \lambda λ越大,拟合曲线就越趋于平缓,偏差越大。
学习曲线

模型改进
模型改进主要思路是:高偏差就改进拟合的模型,高方差就增多训练集
高偏差
- 增加训练集大小无用,模型欠拟合
- 增加更多特征:多项式化数据
- 减小正则化参数 λ \lambda λ
高方差
- 增加训练集大小有效减少过拟合情况
- 减小特征大小
- 增大正则化参数 λ \lambda λ
神经网络的改进
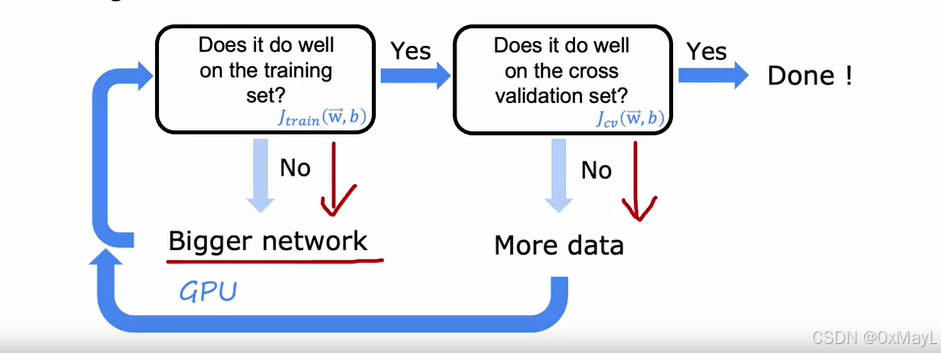
高偏差
- 更大的神经网络
高方差
- 更多的训练集
迁移学习

套用别人训练的参数,改进自己的输出层,可以在自己的数据量小的情况下有良好表现
要求输入层特征数二者保持一致,输出层可以改变
*分类评估指标
准确率Accuracy
略
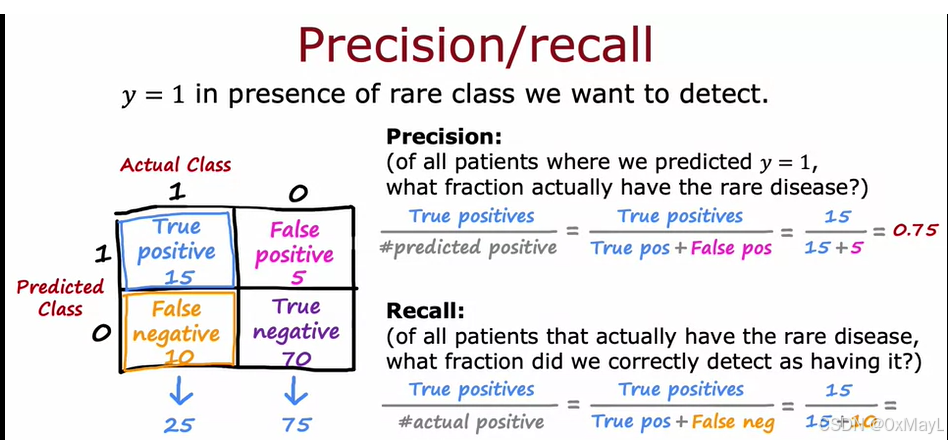
精确率precision和召回率recall
精确率表征的是预测的准确性
召回率表征的是实际的准确性
F1-score
一种准确率和召回率的权衡方法,用于评估不同分类模型的效果

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习·L2W3-模型评估

发表评论 取消回复