1 计算机系统概述
计算机系统由硬件和软件两部分组成,而软件又进一步由系统软件和应用软件组成。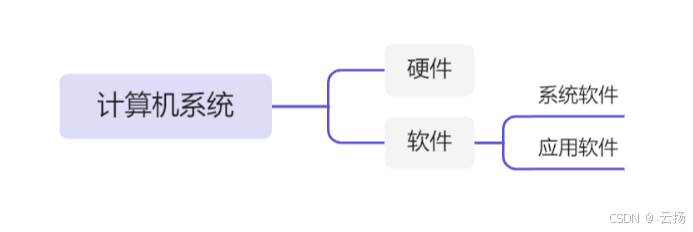
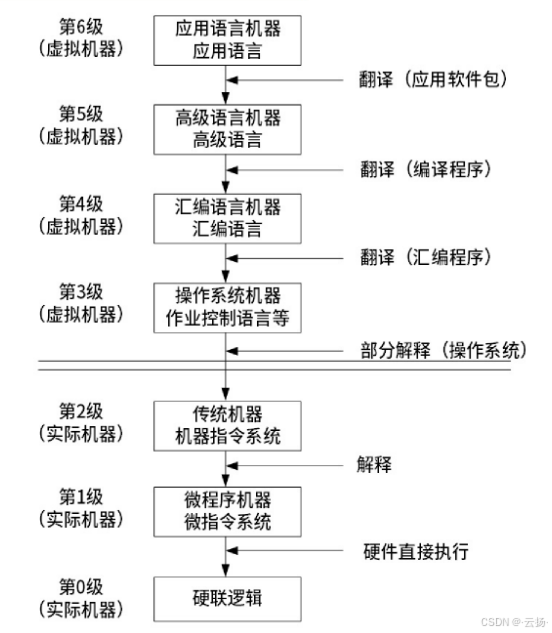
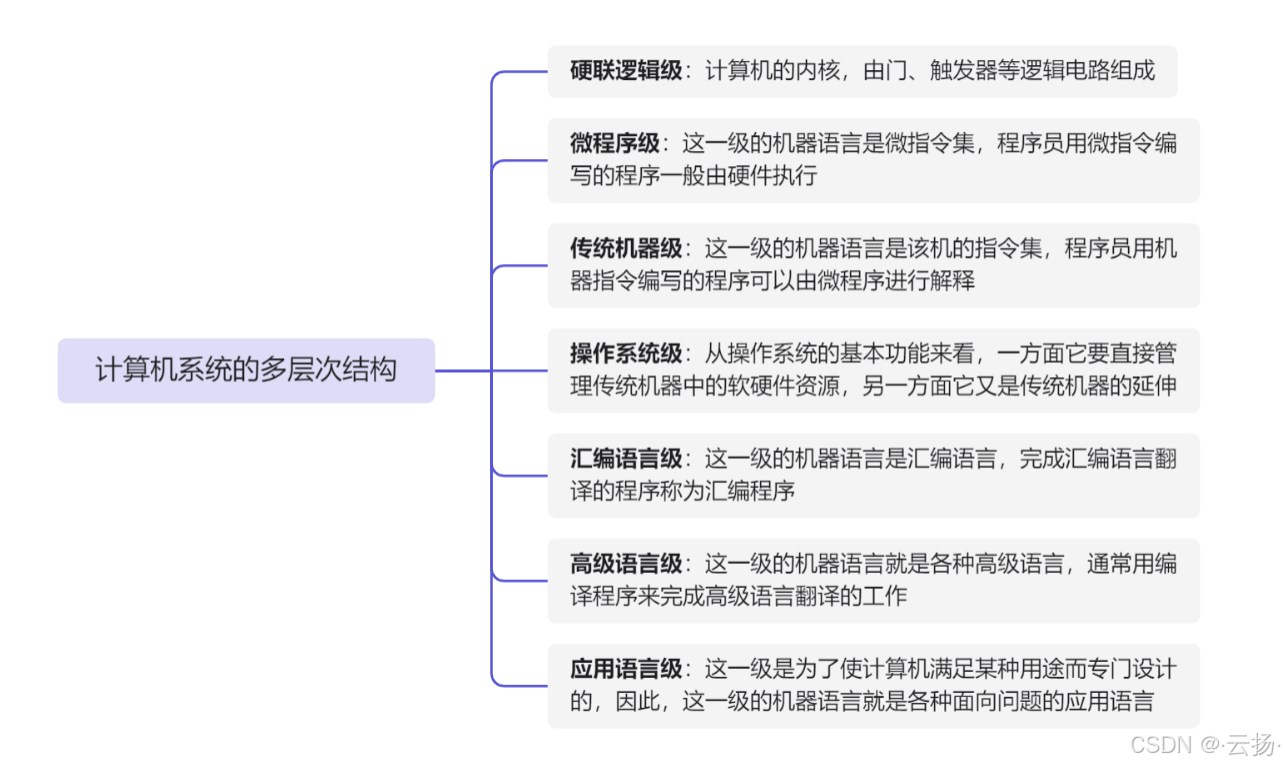
1.2 冯诺依曼体系结构
冯·诺依曼体系结构包括:
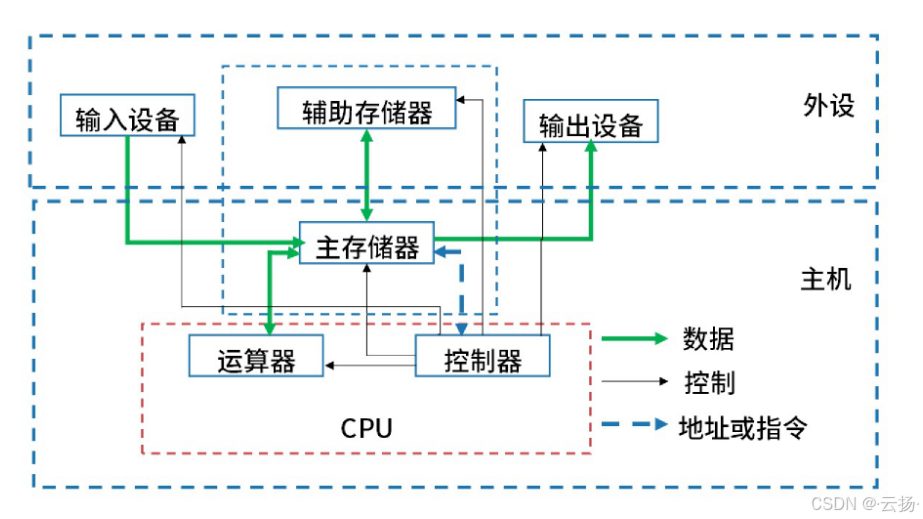
- 中央处理单元(CPU):负责执行指令和处理数据。CPU内部通常包含算术逻辑单元(ALU)、控制单元(CU)和一组寄存器。
- 存储器:用于存储数据和程序指令。存储器通常分为两种类型:主存储器(如RAM)和辅助存储器(如硬盘)
- 输入设备:用于向计算机输入数据和指令,常见的输入设备包括键盘、鼠标和扫描仪等
- 输出设备:用于从计算机输出处理结果,常见的输出设备包括显示器、打印机和扬声器等
- 总线系统:用于在各个组件之间传输数据、地址和控制信号。
特点:
- 存储程序:冯·诺依曼体系结构的核心特点是“存储程序”概念,即计算机程序和数据都以二进制形式存储在同一存储器中。这意味着程序可以像数据一样被读取、修改和执行。
- 顺序执行:CPU按照存储器中指令的顺序依次执行程序,除非遇到跳转或分支指令,这使得程序的执行具有一定的线性逻辑。
- 层次化存储:冯·诺依曼体系结构中的存储器通常分为多个层次,包括高速缓存(Cache)、主存储器(RAM)和辅助存储器(如硬盘),以满足不同速度和容量的需求。
2 存储系统
2.1 层次化存储体系
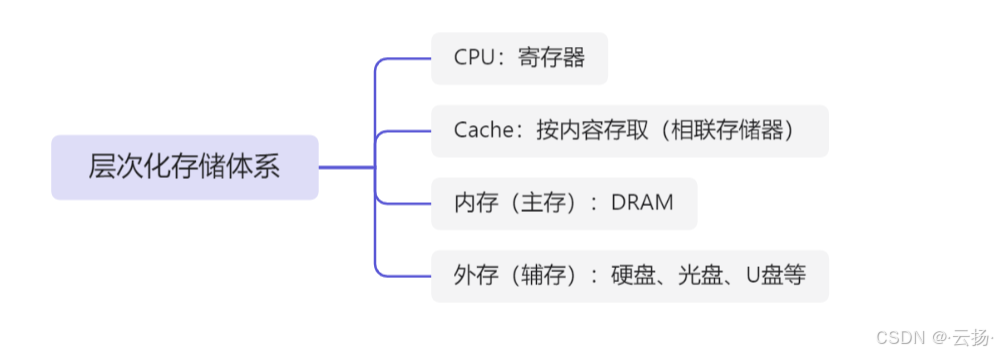
- 层次的速度、容量、成本的对比
离CPU越远,速度越慢,成本越低,容量越大- 特殊的存储器
- 相联存储器:按内容存取;用在Cache上
- DRAM
- RAM,随机存取器:掉电数据会丢失
- ROM,只读存储器:掉电数据不丢失
- DRAM,动态RAM:会周期性刷新
- 用在内存上
- Cache
解决CPU和主存之间速度容量不匹配的问题- 局部性原理的支撑
- 时间局部性:指程序中的某条指令一旦执行,不久以后该指令可能再次执行,典型原因是由于程序中存在着大量的循环操作
- 空间局部性:指一旦程序访问了某个存储单元,不久以后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址可能集中在一定的范围内,其典型情况是程序顺序执行
- 工作集理论:工作集是进程运行时被频繁访问的页面集合。
2.2 Cache
2.2.1 基本概念
Cache的功能:提高CPU数据输入输出的速率,突破冯·诺依曼瓶颈,即CPU与存储系统间数据传送带宽限制
在计算机的存储系统体系中,Cache是除寄存器以外,访问速度最快的层次
Cache对程序员来说是透明的
使用Cache改善系统性能的依据是程序的局部性原理
- 时间局部性
- 空间局部性
Cache的内容是对主存内容的复制
系统的平均周期:

假设:命中率90%,Cache存取时间1ms,内存存取时间100ms,则系统的平均周期为:
t3 = h * t1 + (1 - h ) * t2 = 90% * 1 + (1- 90%) *100 = 0.9+10 = 10.9ms
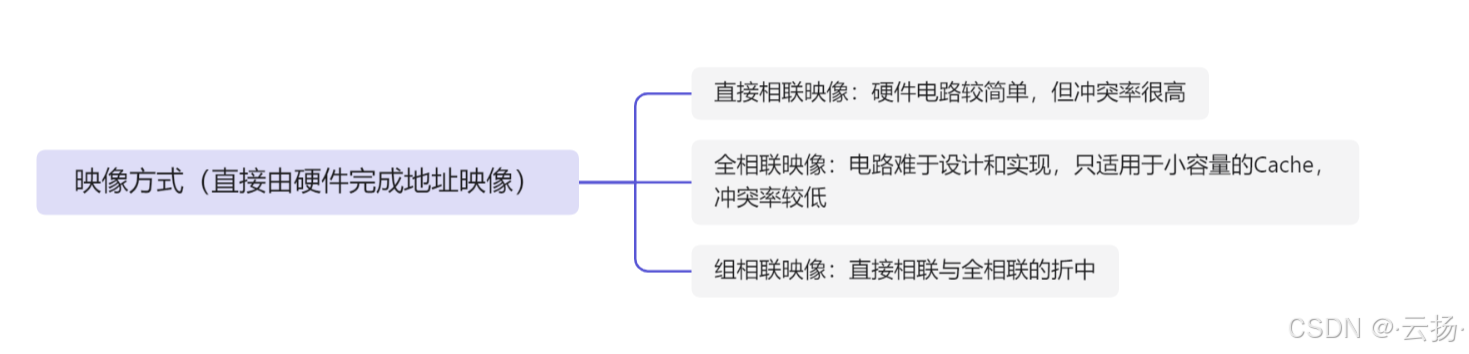
2.2.2 映像方式
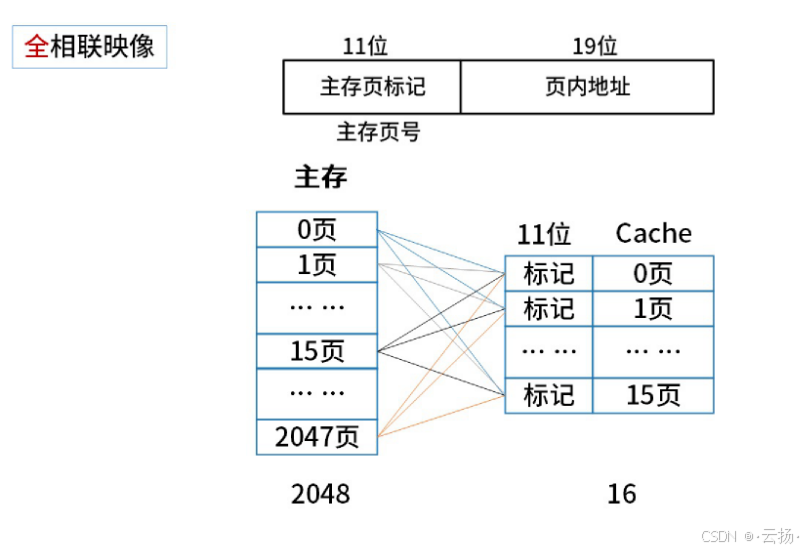
地址映像是将主存与Cache的存储空间划分为若干大小相同的页(或称为块)。
例如,某机的主存容量为1GB,划分为2048页,每页512KB;Cache容量为8MB,划分为16页,每页512KB。
2.2.2.1 直接相联映像
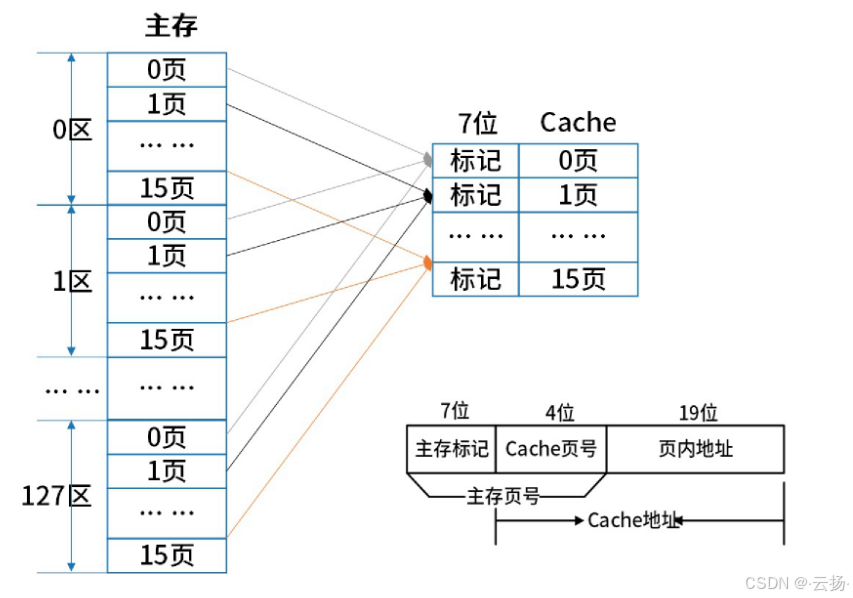
- 固定映射:每个主存储器块都有一个固定的缓存位置。这种映射是通过使用主存储器地址的一部分来确定缓存行(Cache Line)的位置来实现的。例如,如果缓存有N行,主存储器地址的低M位(2^M = N)可以用来选择缓存行。
- 简单快速:直接相联映像的实现相对简单,硬件开销小,查找速度快。因为每个主存储器块只有一个可能的缓存位置,所以不需要复杂的查找机制。
- 冲突缺失:由于每个缓存位置只能存储一个主存储器块,当多个主存储器块映射到同一个缓存位置时,就会发生冲突缺失(Conflict Miss)。这意味着即使缓存未满,也可能因为位置冲突而导致数据无法被缓存。
- 有限的灵活性:直接相联映像的灵活性有限,因为它不允许数据块存储在缓存的任意位置。这可能导致缓存利用率不高,尤其是在程序访问模式不规则的情况下。
- 标签比较:在直接相联映像中,当需要检查缓存是否包含某个数据时,CPU需要比较地址的高位部分(标签)和缓存中的标签,以确定是否命中。
2.2.2.2 全相联映像
全相联映像(Fully Associative Cache)是一种缓存映射技术,它允许主存储器中的任何数据块存储在缓存中的任何位置。这种映射方式提供了最大的灵活性,但也带来了一些特点和挑战:
-
灵活存储:在全相联映像中,主存储器中的数据块可以放置在缓存的任何位置,没有固定的映射关系。这提供了最大的灵活性,可以减少冲突缺失(Conflict Miss)的可能性。
-
复杂的查找机制:由于任何数据块都可以存储在任何缓存位置,因此需要一个复杂的查找机制来确定缓存中是否有所需的数据。这通常涉及并行比较所有缓存行的标签,以检查是否命中。
-
高硬件成本:全相联映像需要更多的硬件资源来实现并行查找和标签比较。这包括更多的比较器和更复杂的控制逻辑,因此成本较高。
-
高命中率:由于数据块可以存储在缓存的任何位置,全相联映像通常能提供较高的缓存命中率,尤其是在访问模式不规则或数据局部性较低的情况下。
-
替换策略:当缓存满时,需要一个替换策略来决定哪个缓存行将被替换。常见的替换策略包括最近最少使用(LRU)、先进先出(FIFO)和随机替换等。
-
适用于小缓存:由于硬件成本和复杂性,全相联映像通常用于较小的缓存,如一级缓存(L1 Cache)或缓存中的某些特殊区域。
全相联映像提供了最佳的缓存利用率和最低的冲突缺失率,但它的实现成本和复杂性限制了它在大型缓存中的应用。
2.2.2.3 组相联映像
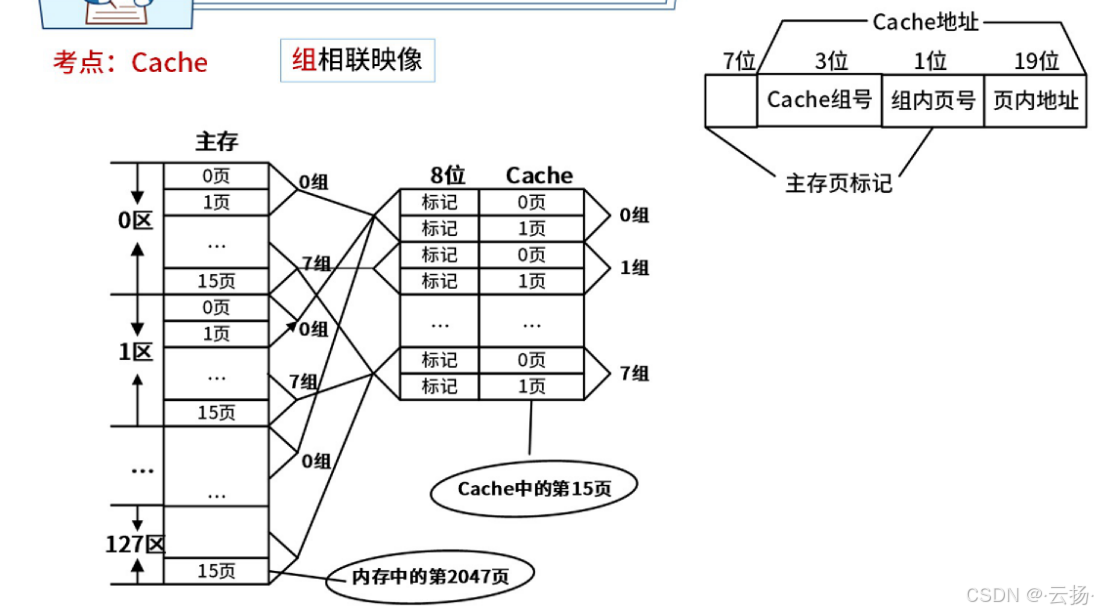
组相联映像(Set Associative Cache)是一种介于直接相联映像和全相联映像之间的缓存映射技术。在这种映射方式中,缓存被划分为多个组(sets),每个组包含多个缓存行(cache lines)。主存储器中的数据块可以映射到特定组中的任何一个缓存行,但只能映射到该组,不能跨组映射。组相联映像的特点如下:
-
分组映射:缓存被划分为多个组,每个组包含一定数量的缓存行。主存储器地址的一部分用于选择组,另一部分用于在组内选择具体的缓存行。
-
灵活性与效率的平衡:组相联映像提供了比直接相联映像更高的灵活性,因为它允许一个主存储器块映射到一组内的多个位置,从而减少了冲突缺失的可能性。同时,它也比全相联映像更高效,因为它不需要并行比较所有缓存行的标签。
-
硬件复杂度适中:组相联映像的硬件复杂度介于直接相联映像和全相联映像之间。它需要多个比较器来并行检查组内的缓存行,但不需要检查整个缓存。
-
替换策略:当一个组内的所有缓存行都被占用时,需要一个替换策略来决定哪个缓存行将被替换。常见的替换策略包括最近最少使用(LRU)、先进先出(FIFO)和随机替换等。
-
常见的组相联映像配置:组相联映像通常以“N路组相联”来描述,其中N表示每个组包含的缓存行数量。例如,2路组相联意味着每个组包含2个缓存行,4路组相联意味着每个组包含4个缓存行。
-
适用于各种规模的缓存:组相联映像适用于各种规模的缓存,从小型的一级缓存(L1 Cache)到大型的高速缓存(Cache)。
组相联映像是一种广泛采用的缓存设计,因为它在硬件成本、复杂性和性能之间提供了良好的平衡。通过调整组的大小(即每组的缓存行数量),可以优化缓存的性能,以适应不同的应用需求和访问模式。
2.2.2.4 例题
组相联映射是常见的Cache映射方法。如果容量为64块的Cache采用组相联方式映射,每块大小为128个字,每4块为一组,即Cache分为()组。若主存容量为4096页,且以字编址。根据主存与Cache块的容量需一致,即每个内存页的大小是()个字,主存地址需要()位,主存组号需()位。
我们逐步解决这个问题,首先从Cache的组数开始:
- Cache的组数:
- Cache总容量为64块。
- 每4块为一组。
- 因此,Cache的组数为:64/4 = 16 组。
- 主存页的大小:
- Cache每块大小为128个字。
- 主存与Cache块的容量需一致,因此每个内存页的大小也是128个字。
- 主存地址的位数:
- 主存容量为4096页。
- 每页大小为128个字。
- 因此,主存总容量为:4096 * 128个字。
- 计算主存地址的位数: log 2 ( 4096 × 128 ) = log 2 ( 4096 ) + log 2 ( 128 ) = 12 + 7 = 19 \log_2(4096 \times 128)= \log_2(4096) + \log_2(128) = 12 + 7 = 19 log2(4096×128)=log2(4096)+log2(128)=12+7=19位。
- 主存组号的位数:
- Cache分为16组。
- 主存地址需要标识组号的部分,用于确定数据在Cache中的组位置。
- 16组需要 log 2 ( 16 ) = 4 \log_2(16) = 4 log2(16)=4位来表示组号。
总结以上计算结果:
- Cache分为16组。
- 每个内存页的大小是128个字。
- 主存地址需要19位。
- 主存组号需4位。
2.2.3 Cache页面淘汰算法
在高速缓存(Cache)-主存储器构成的存储系统中,主存地址到Cache地址的变换由硬件完成,以提高速度
Cache命中率随着容量的增大而提高,但这种提高不是线性的,而是遵循边际收益递减的原则。
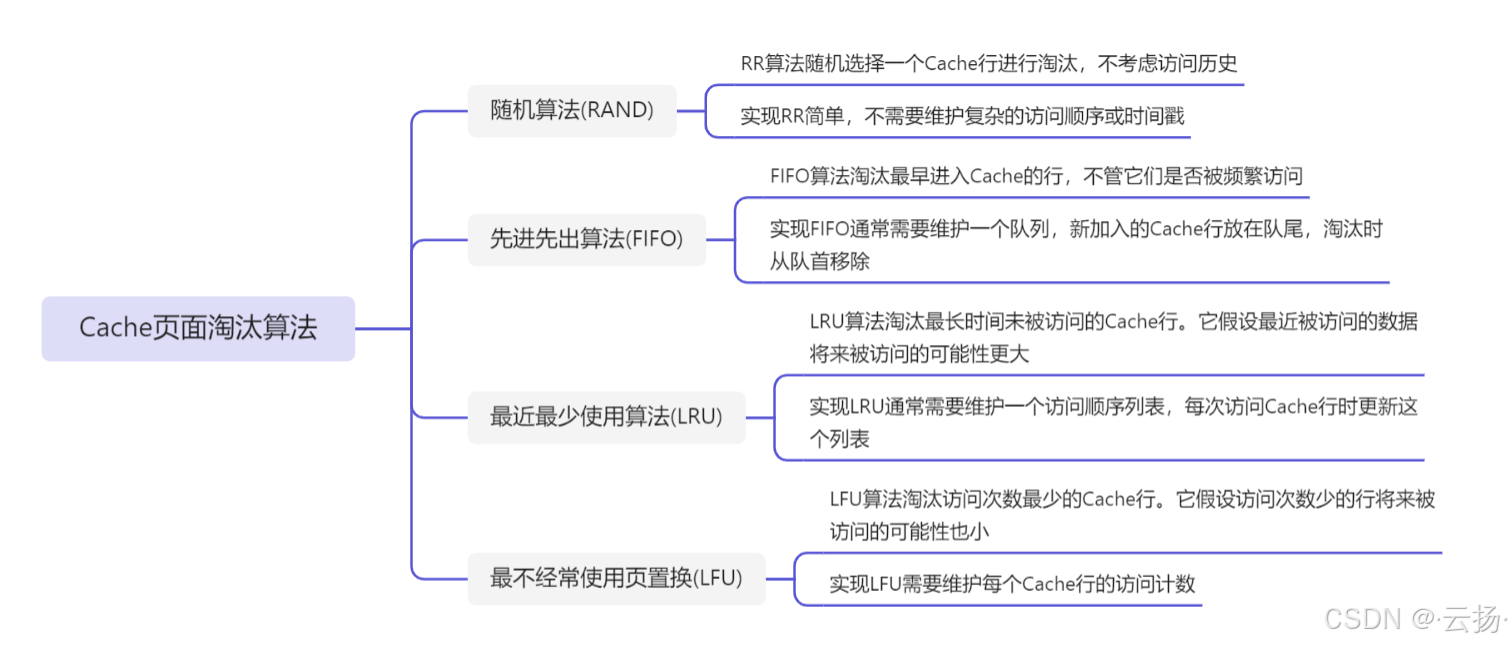
2.2.4 Cache的读写过程

2.3 磁盘管理
读取磁盘数据的时间应包括以下三个部分
- 找磁道的时间
- 找块(扇区)的时间,即旋转延迟时间
- 传输时间
2.3.1 例题
某磁盘磁头从一个磁道移至另一个磁道需要10ms。文件在磁盘上非连续存放,逻辑上相邻数据块的平均移动距离为10个磁道,每块的旋转延迟时间及传输时间分别为100ms和2ms,则读取一个100块的文件需要( )ms时间。
读取磁盘数据时间 = 寻道时间 + 旋转延迟时间 + 传输时间
读取一个100块的文件需要时间:((10*10)+100+2)*100 )= 20200 ms
2.3.2 磁盘寻道算法
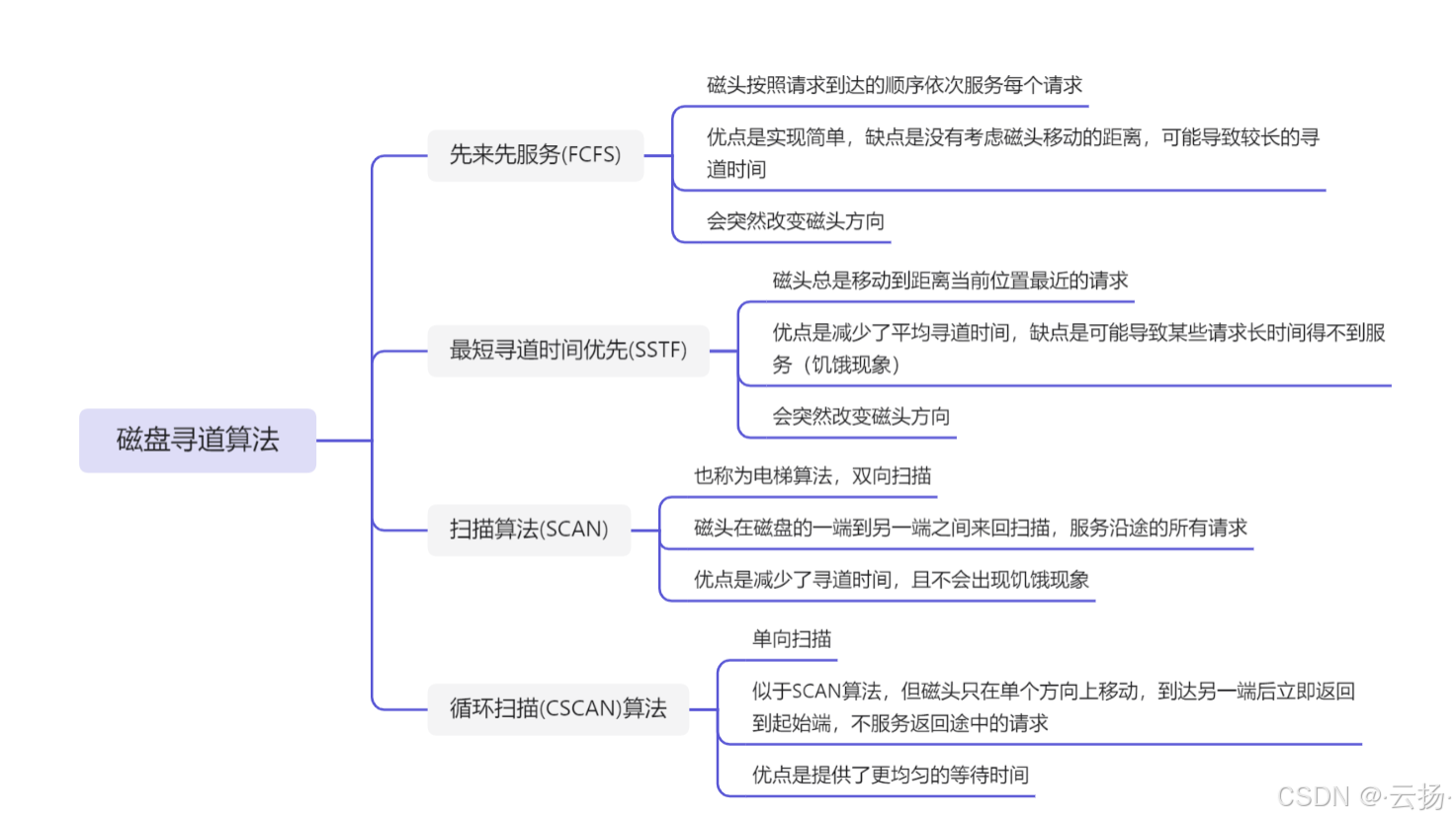
2.3.2.1 例题
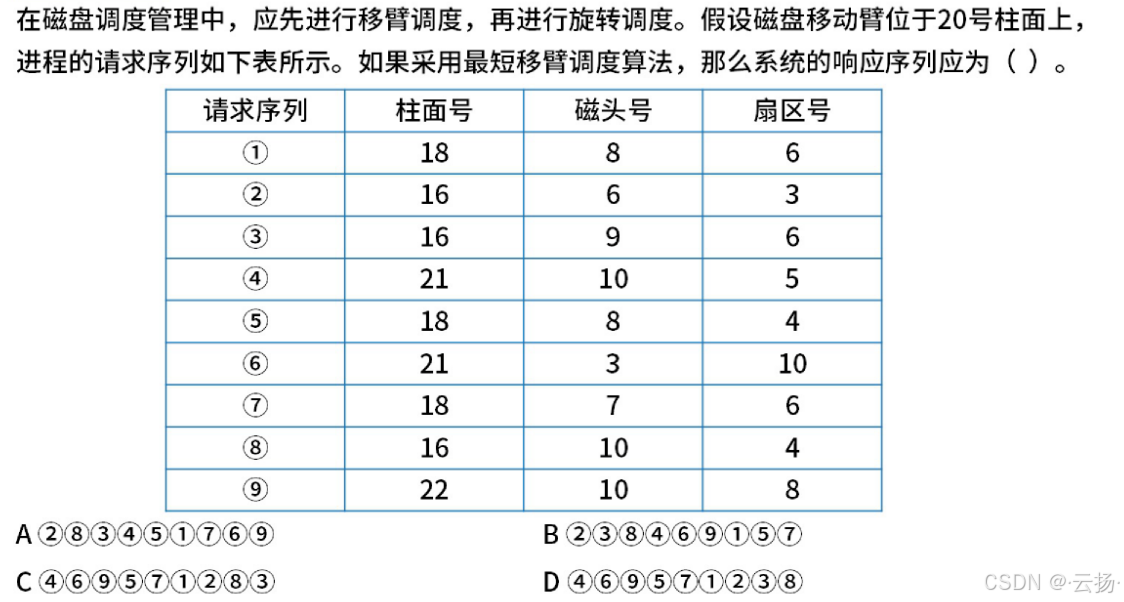
解题思路:
- 大部分只考虑磁道号/柱面号不考虑扇区;
- 扇区号从小到大
解题过程:
柱面号18对应请求序号:①⑤⑦
柱面号16对应请求序号:②③⑧
柱面号21对应请求序号:④⑥
柱面号22对应请求序号:⑨
最短移臂调度算法:先根据柱面号20->21->18->16
此时请求序号:④⑥⑨①⑤⑦
柱面号16的按照扇区号从小到大排序:②⑧③
结果:④⑥⑨①⑤⑦②⑧③,选C选项。

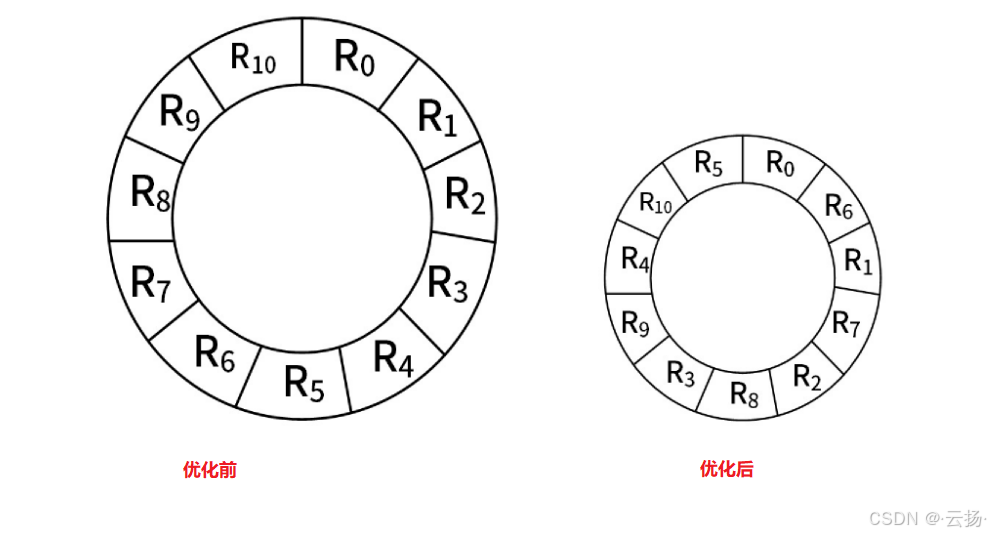
解题思路:
- 逻辑顺序一定是连续的,即R0-R1-R2-……R10
- 物理顺序看实际存储
- 单缓冲区:一次只能让一个进程用
- 对信息存储进行优化分布,即计算时去掉旋转延迟时间
解题过程:
1个磁道分了11个物理块,磁盘一圈33ms,旋转过1个物理块的时间是多少?即读取1个块数据的时间:33/11=3ms
每块处理耗时:
R0:读取时间+ 处理时间=3+3= 6ms
R1:旋转延迟时间+读取时间+ 处理时间=30+3+3=36ms
……
R10:旋转延迟时间+读取时间+ 处理时间=30+3+3=36ms
共耗时10 *(30+3+3) +3+3 = 366ms对信息存储进行优化分布后,共耗时11*(3+3) = 66ms,或33 * 2 = 66ms
答案:选择C、B选项
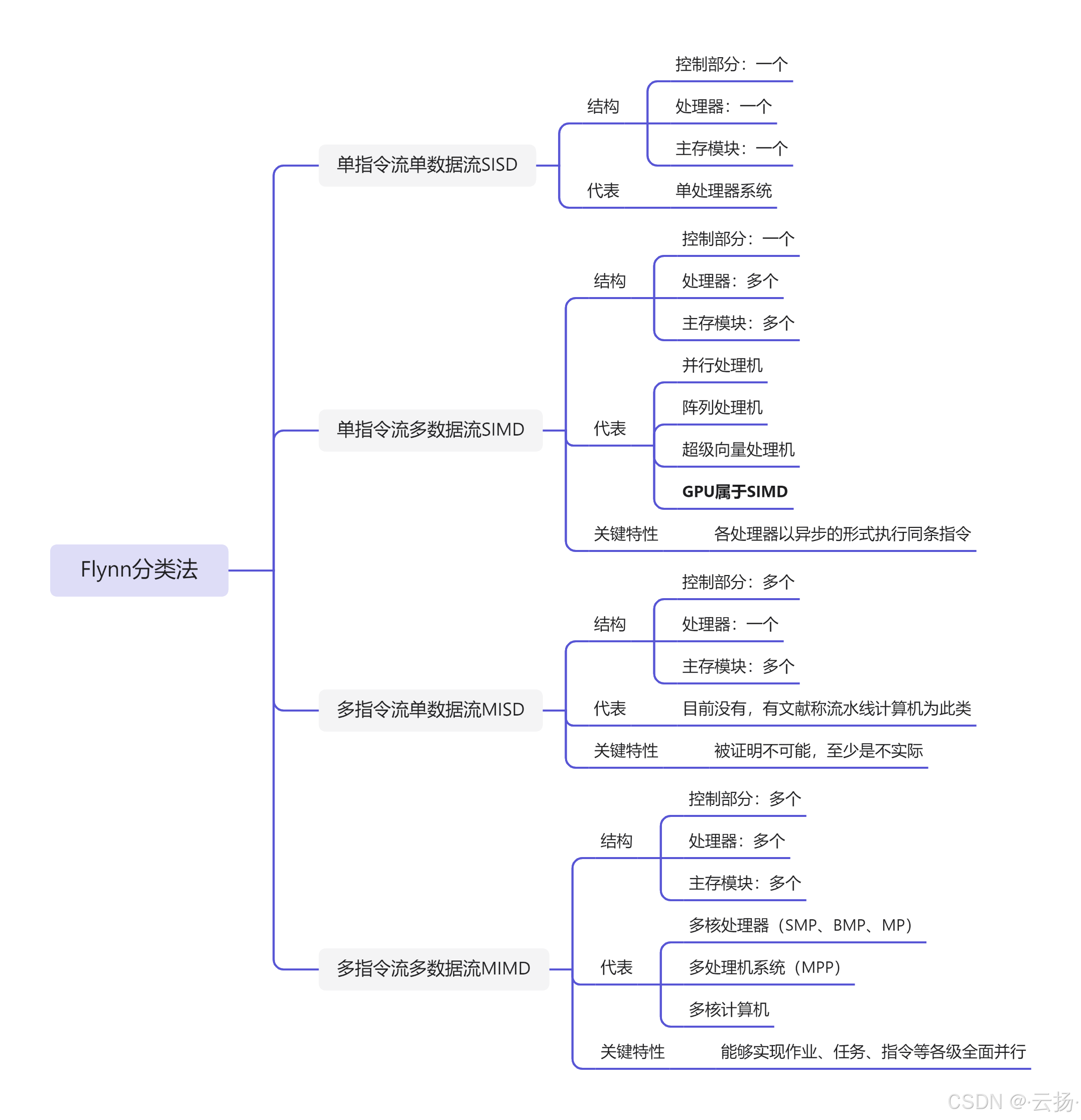
2.4 Flynn分类法
Flynn分类法是一种用于对计算机体系结构进行分类的方法,由美国计算机科学家Michael J. Flynn在1972年提出。Flynn分类法基于指令流和数据流的并行度,将计算机体系结构分为以下四类:
-
单指令流单数据流(SISD, Single Instruction stream, Single Data stream):
- SISD体系结构是最传统的计算机体系结构,其中单个处理器执行单个指令流来操作单个数据流。
- 这种体系结构的代表是早期的串行计算机,如早期的冯·诺依曼型计算机。
-
单指令流多数据流(SIMD, Single Instruction stream, Multiple Data streams):
- SIMD体系结构中,单个指令流控制多个处理单元,每个处理单元同时对不同的数据流执行相同的操作。
- 这种体系结构适用于数据级并行处理,如向量处理器和图形处理单元(GPU)。
-
多指令流单数据流(MISD, Multiple Instruction streams, Single Data stream):
- MISD体系结构中,多个指令流同时对单个数据流进行操作。
- 这种体系结构在实际中很少见,可能的应用场景包括容错系统中的冗余处理。
-
多指令流多数据流(MIMD, Multiple Instruction streams, Multiple Data streams):
- MIMD体系结构中,多个独立的处理器或处理单元同时执行不同的指令流,每个处理器操作不同的数据流。
- 这种体系结构适用于任务级并行处理,如多核处理器、集群和大多数现代并行计算机系统。
2.4.1 例题
以下关于CPU和GPU的叙述中,错误的是( ) 。
A CPU适合于需要处理各种不同的数据类型、大量的分支跳转及中断等场合
B CPU利用较高的主频、高速缓存(Cache)和分支预测等技术来执行指令
C GPU采用MISD (Multiple Instruction Single Data)并行计算架构
D GPU的特点是比CPU包含更多的计算单元和更简单的控制单元
C:GPU采用SIMD单指令流多数据流并行计算架构,故C错误。
2.5 CISC与RISC

2.5.1 例题
RISC-V是基于精简指令集计算原理建立的开放指令集架构,以下关于RISC-V的说法中,不正确的是( ) 。
A RISC-V架构不仅短小精悍,而且其不同的部分还能以模块化的方式组织在一起,从而试图通过一套统一的架构满足各种不同的应用场景
B RISC-V基础指令集中只有40多条指令,加上其他模块化扩展指令总共也就几十条指令
C RISC-VISA可以免费使用,允许任何人设计、制造和销售RISC-V芯片和软件
D RISC-V也是X86架构的一种,它和ARM架构之间存在很大区别
选D,ARM使用的是精简指令集(RISC),而RISC-V就是RISC的一个代表,而X86架构使用的是复杂指令集(CISC),故D错误。
2.6 流水线技术
2.6.1 基本概念
流水线是指在程序执行时多条指令重叠进行操作的一种准并行处理实现技术。各种部件同时处理是针对不同指令而言的,它们可同时为多条指令的不同部分进行工作,以提高各部件的利用率和指令的平均执行速度。
流水线执行时间计算公式
1条指令执行时间+(指令条数-1)* 流水线周期- 流水线周期为执行时间最长的一段tmax
- 理论公式:
(t1+t2+...+tk)+(n-1) * tmax - 实践公式:
k*tmax +(n-1) * tmax
流水线吞吐率
- 流水线的吞吐率(Through Put rate,TP)是指在单位时间内流水线所完成的任务数量或输出的结果数量。
- 计算流水线吞吐率的最基本的公式:
TP = 指令条数 / 流水线执行时间 - 流水线最大吞吐率:
TPmax = 1 / tmax
流水线加速比
- 完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比称为流水线的加速比
- 计算流水线加速比的基本公式如下:
S = 不使用流水线执行时间/ 使用流水线执行时间
2.6.2 例题
- 一条指令的执行过程可以分解为取指、分析和执行三步,在取指时间t1=3△t、分析时间t2=2△t、执行时间t3=4△t的情况下,若按串行方式执行,则10条指令全部执行完需要()△t;若按流水线的方式执行,流水线周期为()△t,则10条指令全部执行完需要()△t
解题思路:
①按串行方式执行:(t1+t2+t3)*n;
②按流水线方式执行:(t1+t2+t3)+(n-1)*tmax;
解题过程:
①按串行方式执行:(t1+t2+t3)*n=(3+2+4)*10=90Δt
②按流水线方式执行:
tmax=max(t1,t2,t3)=max(3,2,4)=4
(t1+t2+t3)+(n-1)*tmax=(3+2+4)+(10-1)*4=45Δt
答案:90、45
- 一条指令的执行过程可以分解为取指、分析和执行三步,取指时间t1=3△t、分析时间t2=2△t、执行时间t3=4△t。10条指令的吞吐率?最大吞吐率?
解题思路:
①吞吐率=指令条数/流水线执行时间;
流水线执行时间=(t1+t2+t3)+(n-1)*tmax;
流水线周期tmax=max(t1,t2,t3);
②最大吞吐率=1/tmax
解题过程:
①吞吐率=n/((t1+t2+t3)+(n-1)*max(t1,t2,t3))=10/((3+2+4)+(10-1)*4)=10/45Δt
②最大吞吐率=1/max(t1,t2,t3)=1/4Δt
- 某计算机系统采用5级流水线结构执行指令,设每条指令的执行由取指令(2Δt)、分析指令(1Δt)、取操作数(3Δt) 、运算(1Δt)和写回结果(2Δt)组成,并分别用5个子部件完成,该流水线的最大吞吐率为( ) ;若连续向流水线输入10条指令,则该流水线的加速比为( )。
解题思路:
①最大吞吐率=1/tmax
②流水线加速比S = 不使用流水线执行时间/ 使用流水线执行时间
解题过程:
①最大吞吐率:1/max(2,1,3,1,2)Δt=1/3Δt
②不使用流水线执行时间=(2+1+3+1+2)Δt * 10 = 90Δt
使用流水线执行时间理论执行时间=(2+1+3+1+2)Δt +(10-1)*max(2,1,3,1,2)Δt =36Δt
流水线加速比S=90Δt /36Δt =5:2
答案:
1/3Δt、5:2
- 假设磁盘块与缓冲区大小相同,每个盘块读入缓冲区的时间为15us,由缓冲区送至用户区的时间是5us,在用户区内系统对每块数据的处理时间为1us,若用户需要将大小为10个磁盘块的Doc1文件逐块从磁盘读入缓冲区,并送至用户区进行处理,那么采用单缓冲区需要花费的时间为( ) us;采用双缓冲区需要花费的时间为( ) us。
(注:us表示微秒)
解题思路
磁盘块:15us;缓冲区:5us;用户区:1us
①采用单缓冲区:
分成两段流水线:
缓冲区:15+5=20us;
用户区:1us
②采用多缓冲区:
分成三段流水线:
缓冲区1:15us
缓冲区2:5us
用户区:1us
解题过程:
①采用单缓冲区:
(20 + 1)+(10-1)*20 = 201us;
②采用多缓冲区:
(15+5+1)+(10-1)*15=156us
3 性能指标与性能评价方法
3.1 性能指标


3.2 性能评价方法

3.3 例题
通常用户采用评价程序来评价系统的性能,评测准确度最高的评价程序是()。在计算机性能评估中,通常将评价程序中用得最多、最频繁的()作为评价计算机性能的标准程序,称其为基准测试程序。
答案:真实程序;核心程序
4 可靠性
4.1 可靠性指标
4.1.1 基本概念
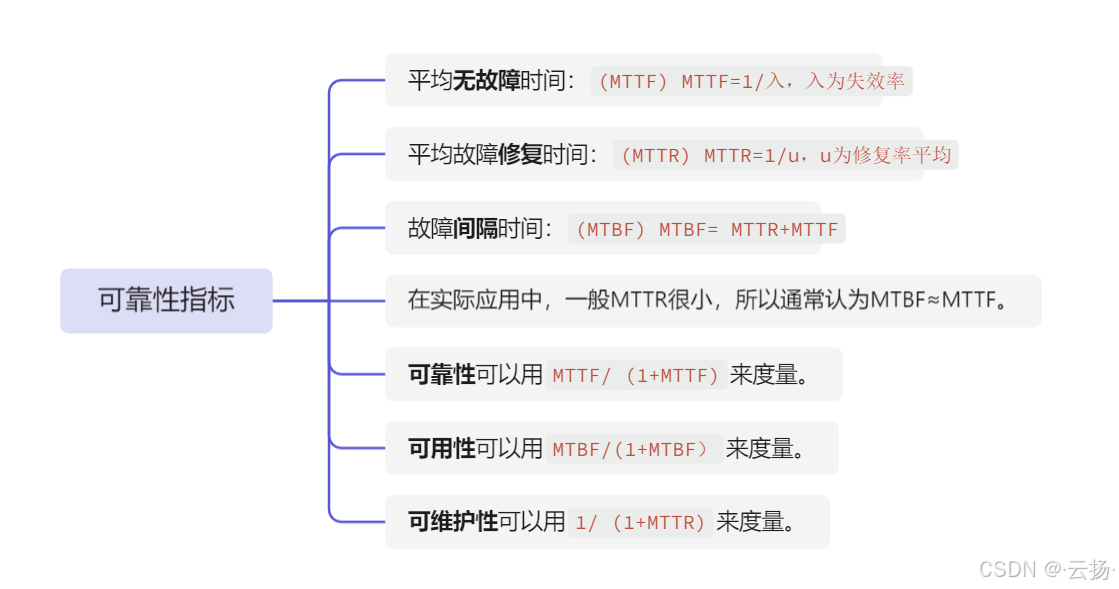
4.1.2 例题
运用互联网技术,在系统性能评价中通常用平均无故障时间(MTBF)和平均故障修复时间(MTTR)分别表示计算机系统的可靠性和可用性,( )表示系统具有高可靠性和高可用性。
A、MTBF小,MTTR小
B、MTBF大,MTTR小
C、MTBF大,MTTR大
D、MTBF小,MTTR大
解题思路:注意,题目这里将平均无故障时间的英文缩写为MTBF,这与上面提到的有点差别,遇到时以题目给出的为准。
平均无故障时间(MTBF)越大,平均故障修复时间(MTTR)越小,系统的可靠性和可用性越高。
答案:B
4.2 可靠性计算
4.2.1 计算公式
千小时可靠度
千小时可靠度:1000小时时间内,机器正常运行的概率
- 串联
所有部件同时可靠才整体可靠
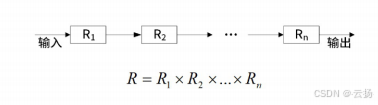
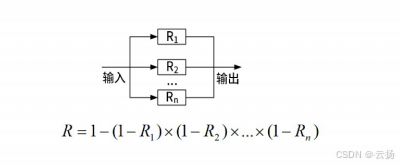
- 并联
只要有1个部件可靠整体就可靠;
所有部件都失效不可用则整体不可用;
- 混联
同时使用串联和并联
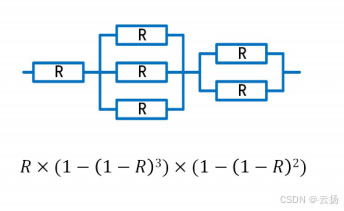
失效率:千小时失效的比例(或概率)
比如:假设同一型号的1000台计算机,在规定条件下工作1000小时,其中10台故障。其失效率为r=10/(1000*1000)=1*10^(-5)
千小时可靠度为:R(t)=1-t*r=1-1000*(1*10^(-5))=0.99
4.2.2 例题
- 某高可靠性计算机系统由下图所示的冗余部件构成。若每个部件的千小时可靠度都为R,则该计算机系统的千小时可靠度为( ) 。
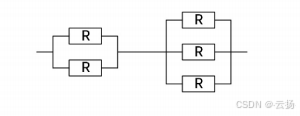
解题过程:根据图片,该系统使用的是混联,则千小时可靠度为:(1-(1-R)^2) × (1-(1-R)^3)
答案:(1-(1-R)^2) × (1-(1-R)^3)。
- 某种部件用在2000台计算机系统中,运行工作1000小时后,其中有4台计算机的这种部件失效,则该部件的千小时可靠度R为( ) 。
解题思路:
①先求出失效率,再根据失效率求出千小时可靠度
②直接求千小时可靠度
解题过程:
①失效率:4/(1000*2000)=1/500000
千小时可靠度:1-1000 *(1/500000)=1-0.002=0.998
②千小时可靠度:1996/2000=0.998
答案:0.998。
5 附录 计算机系统基础思维导图
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 系统分析师1:计算机系统基础

发表评论 取消回复