作者:南墨
监控指标
进入Flink的原生页面,需要从yarn的原生页面的后台链接进入,如下图:

这里必须要用supergroup组的用户或者flink提交任务的用户(如果该用户是机机用户不能登录)才能够看到任务。
系统监控
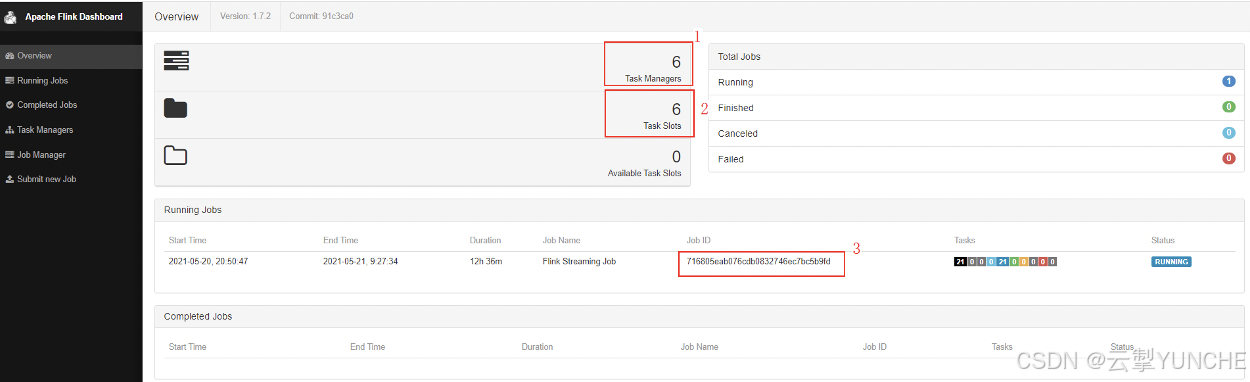
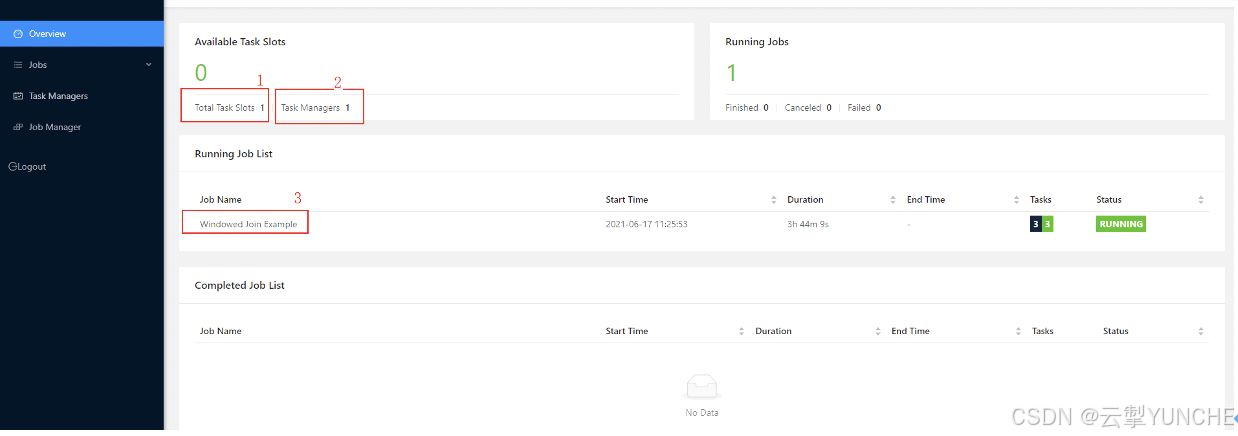
Flink的原生页面首页是任务的执行概要页面。其中主要关注的点如下:
1、 taskmanager的数量:一个taskmanager是nodemanager上面启动的一个进程,占用一个container。
2、 已使用slot的数量:表示使用的slot的数量,这里要注意,taskmanager一般跟slot数量是一个比例关系,在图中“Avaliable Task slots”+“Taskslots”表示这个集群中的总slot的数量。
3、 Jopid:代表这个flink任务的id。
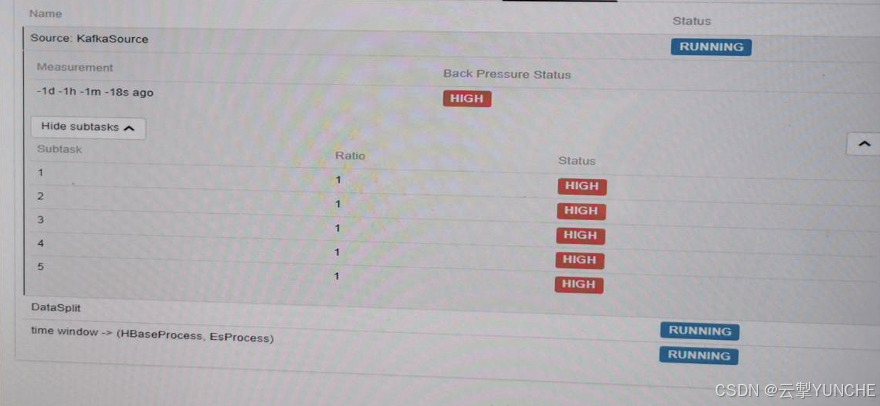
反压监控
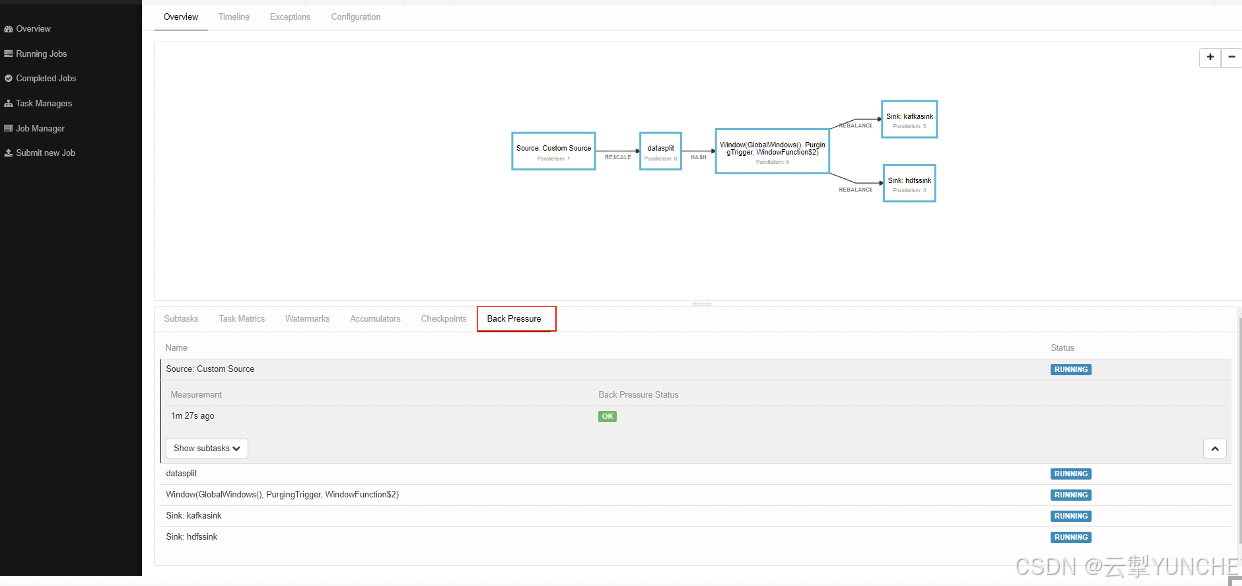
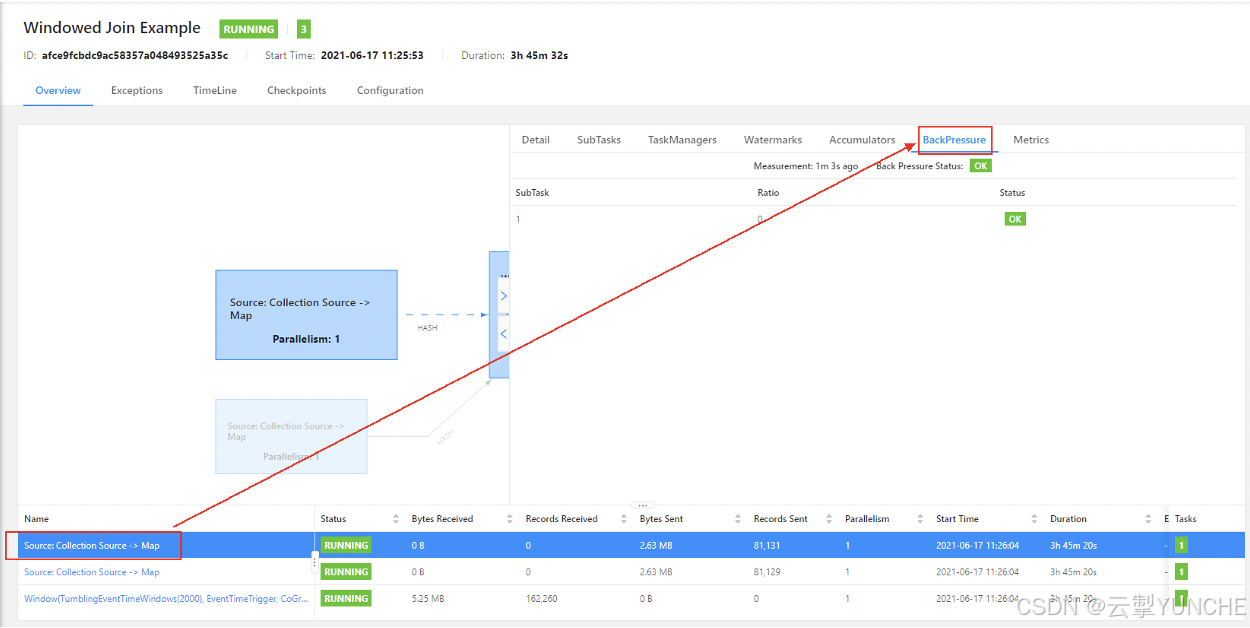
反压监控表示了在每个算子的并行度中buffer所挤压的数据。正常情况下有三种状态,“high”“OK”“low”。
High:表示队列中的数据已经挤压到90%以上
OK:表示没有
Low:表示在50%左右。
如果所有算子都是OK则表示没有反压,如果第一个算子是high,需要向下找算子中第一个出现OK的算子,那么这个处于OK状态的算子就是整个链路的处理瓶颈。
Checkpoint监控
检查点监控能够说明业务运行过程中每个检查点的运行状态和运行结果。
Overview :整个checkpoint阶段的概览,需要重点关注的点包括:
a) Overview:整体checkpoint的概览,包括,trigger,触发了多少次、in Progress 正在运行中的数量Completed已完成的数量,failed的数量。
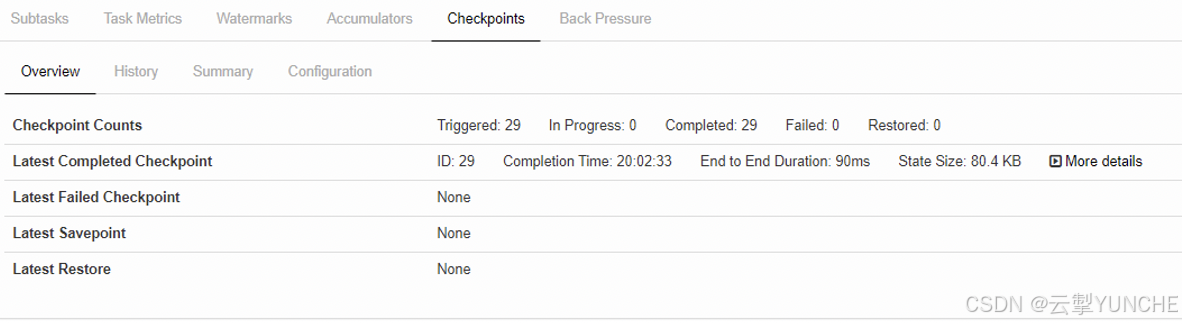
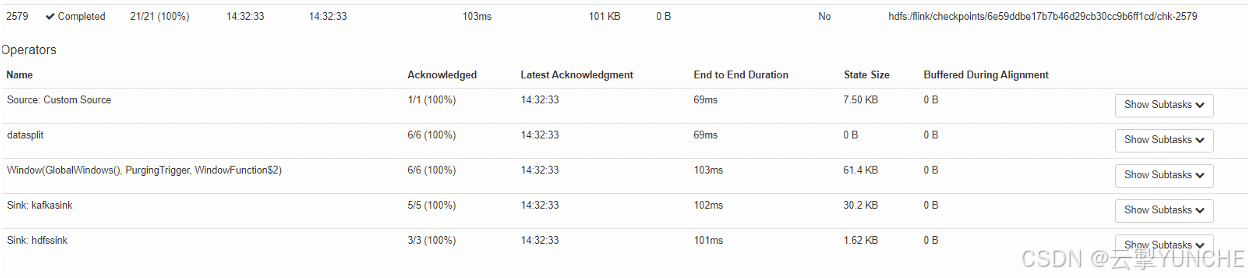
需要注意的是,在Latest Completed Checkpoint后面的More detail中,能够看到每个checkpoint在每个算子中的耗时,耗时能够反映算子打checkpoint的耗时

b) History和Summary页面
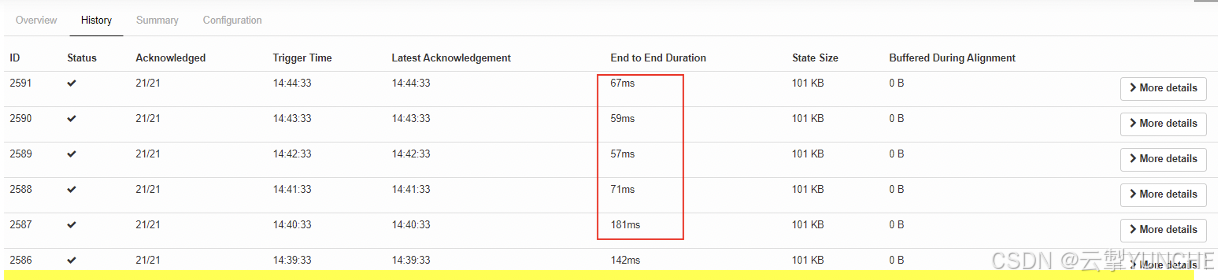
这个页面能够看到每个checkpoint的耗时,如果耗时是平均的,那么能够说明整个任务链的是健壮的;如果checkpoint的耗时是逐渐递增的说明任务链极有可能存在严重的背压,导致每次checkpoint的耗时都非常的长。
Summary页面中显示了这个所有checkpoint中统计的平均值

c) Configuration页面
这个页面显示了checkpoint的一些配置,这些配置可以在代码中设置。

更多技术信息请查看云掣官网https://yunche.pro/?t=yrgw
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » flink web监控

发表评论 取消回复