目录
本来是想了解完Dask后做一个分布式的测试,在gitee上找了一个源码库,结果太简单了没有任何参考价值,将就看吧。
一、源码来源
二、鸢尾花数据集的品种分类
首先说明源码是使用了经典的鸢尾花数据集(Iris dataset),该数据集包含了三种不同种类的鸢尾花的测量数据。
鸢尾花数据集是一个常用的测试数据集,这些数据通常用于分类任务的示例和测试,用于演示和验证机器学习算法的分类能力。
1、数据处理步骤
该代码使用鸢尾花数据集进行了简单的特征选择(使用全部四个特征),并进行了简单的数据划分(训练集和测试集)。
(1)数据集加载
iris = datasets.load_iris()
这一行代码使用 sklearn.datasets 模块中的 load_iris() 函数加载了鸢尾花数据集。
(2)准备特征和标签
X_train, X_test, y_train, y_test = train_test_split(
iris_X, iris_y, train_size=.7)
iris.data 包含了鸢尾花的四个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度。
iris.target 包含了每个样本对应的类别标签,分别代表三种不同的鸢尾花品种。
(3)训练集和测试集划分
X_train, X_test, y_train, y_test = train_test_split(
iris_X, iris_y, train_size=.7)
使用 train_test_split 函数将数据集划分为训练集(70%)和测试集(30%)。设置 train_size=.7 表示训练集占总数据的70%。
2、安装必需的软件包
pip install dask distributed matplotlib seaborn scikit-learn imbalanced-learn joblib
3、运行程序
运行src_svm目录中的joblib_svm.py文件。
python3 joblib_svm.py在这个文件中,是使用支持向量机(SVM)进行分类,预测鸢尾花的品种。
- 使用了
sklearn提供的datasets.load_iris()加载数据。 - 使用了
svm.SVC作为分类器。 - 使用
dask.distributed来分布式执行任务。 - 评估模型性能时,计算了准确率、召回率、F1 值等指标,并绘制了混淆矩阵的热力图。
执行结果:
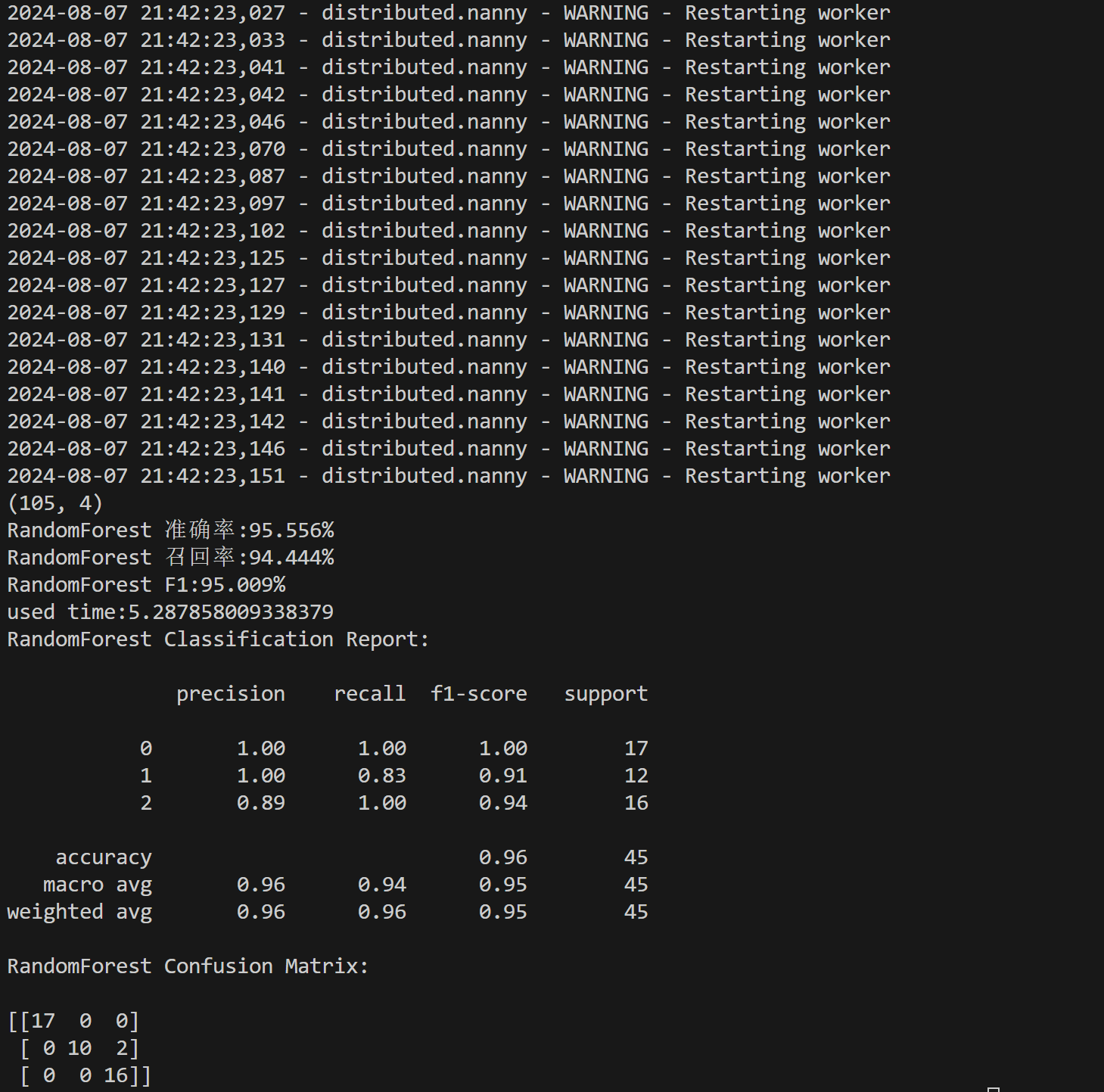
其中上半部分为性能变量:
- precision:精确度,即预测为某一类别的样本中,真正属于这一类别的比例。
- recall:召回率,即真正属于某一类别的样本中,被模型预测为这一类别的比例。
- f1-score:F1 分数,综合考虑精确度和召回率的加权平均值,用于衡量模型在各个类别上的综合表现。
- accuracy:准确率,即模型在整个测试集上预测正确的比例。
- macro avg: 对所有类别的指标取算术平均值,每个类别的权重相同。
- weighted avg: 对所有类别的指标取加权平均值,权重为各类别在测试集中的比例。
下半部分为混淆矩阵。随机森林的混淆矩阵(Confusion Matrix)是一个 3x3 的矩阵,用于评估分类模型在多分类问题上的性能:
- 矩阵的行表示真实的类别(Actual),列表示模型预测的类别(Predicted)。
- 每一个单元格中的值表示真实类别和预测类别的交集数量。
在这里表示:
- 第一行
[17 0 0]表示真实类别为 0 的样本,模型预测为类别 0 的有 17 个,预测为类别 1 和类别 2 的都没有。 - 第二行
[ 0 10 2]表示真实类别为 1 的样本,模型预测为类别 1 的有 10 个,预测为类别 0 的没有,预测为类别 2 的有 2 个。 - 第三行
[ 0 0 16]表示真实类别为 2 的样本,模型预测为类别 2 的有 16 个,预测为类别 0 和类别 1 的都没有。
三、信用卡欺诈数据集检测信用卡交易中的欺诈行为
源码的主要作用是构建一个机器学习模型来预测信用卡交易是否为欺诈。使用的数据集是名为 creditcard.csv 的CSV文件,位于当前工作目录下的 ./dataset/creditcard.csv。
1、数据处理过程
(1)数据读取和缩放
使用 Pandas 的 read_csv 函数读取 creditcard.csv 文件。
使用 RobustScaler 对 Amount 和 Time 列进行缩放,以减少异常值的影响。
(2)数据预处理
将数据集划分为特征 (X) 和标签 (y)。
使用 train_test_split 函数将数据集划分为训练集 (X_train_resampled, y_train_resampled) 和测试集 (x_test, y_test),并且通过 stratify=y 参数保持了训练集和测试集中类别的比例一致。
使用 SMOTE 进行过采样,以处理类别不平衡问题,通过 fit_resample 方法生成了平衡后的训练集 (X_train_resampled, y_train_resampled)。
(3)模型训练和预测
使用随机森林分类器 (RandomForestClassifier),设置了 n_estimators=100 用于构建 100 棵决策树,criterion='gini' 使用基尼不纯度作为划分标准,n_jobs=4 表示使用 4 个并行作业。
使用 joblib.parallel_backend("dask") 实现在 Dask 集群中并行训练模型。
对测试集 x_test 进行预测,并计算模型的准确率、召回率和 F1 值。
(4)评估和可视化
打印模型的准确率、召回率、F1 值以及训练和预测所花费的时间。
输出分类报告 (classification_report) 和混淆矩阵 (confusion_matrix),用于评估模型在测试集上的性能。
绘制混淆矩阵的热图,帮助可视化模型预测结果和真实结果之间的差异。
3、运行过程
提示没有数据集文件:
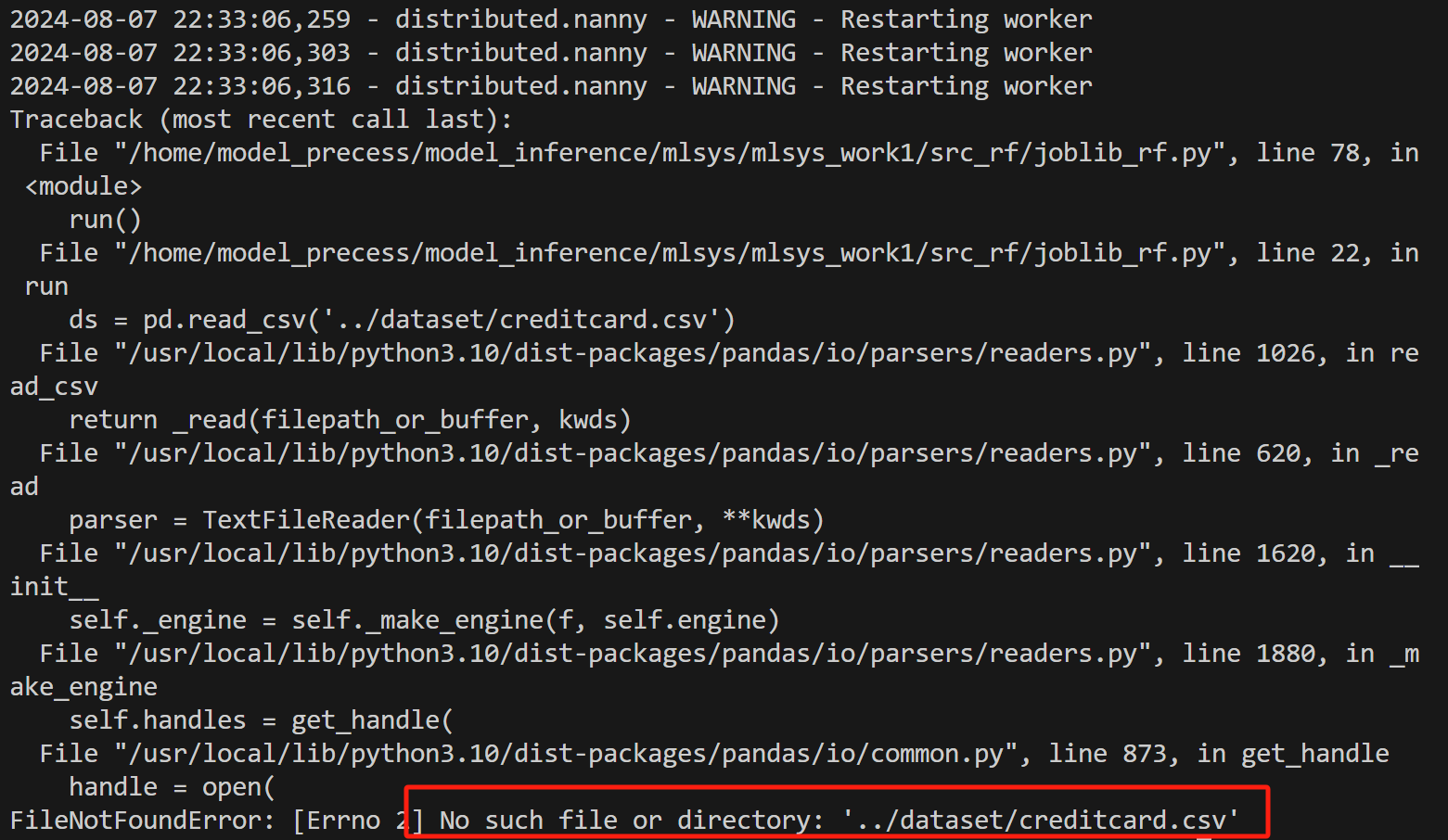
我去gitee上找了个数据集:Datasets: jbrownlee/Datasets
下载后转到数据集目录记得解压:
unzip creditcard.csv.zipbut这个数据集不对,暂时放置。运行后提示少了一行关键字:
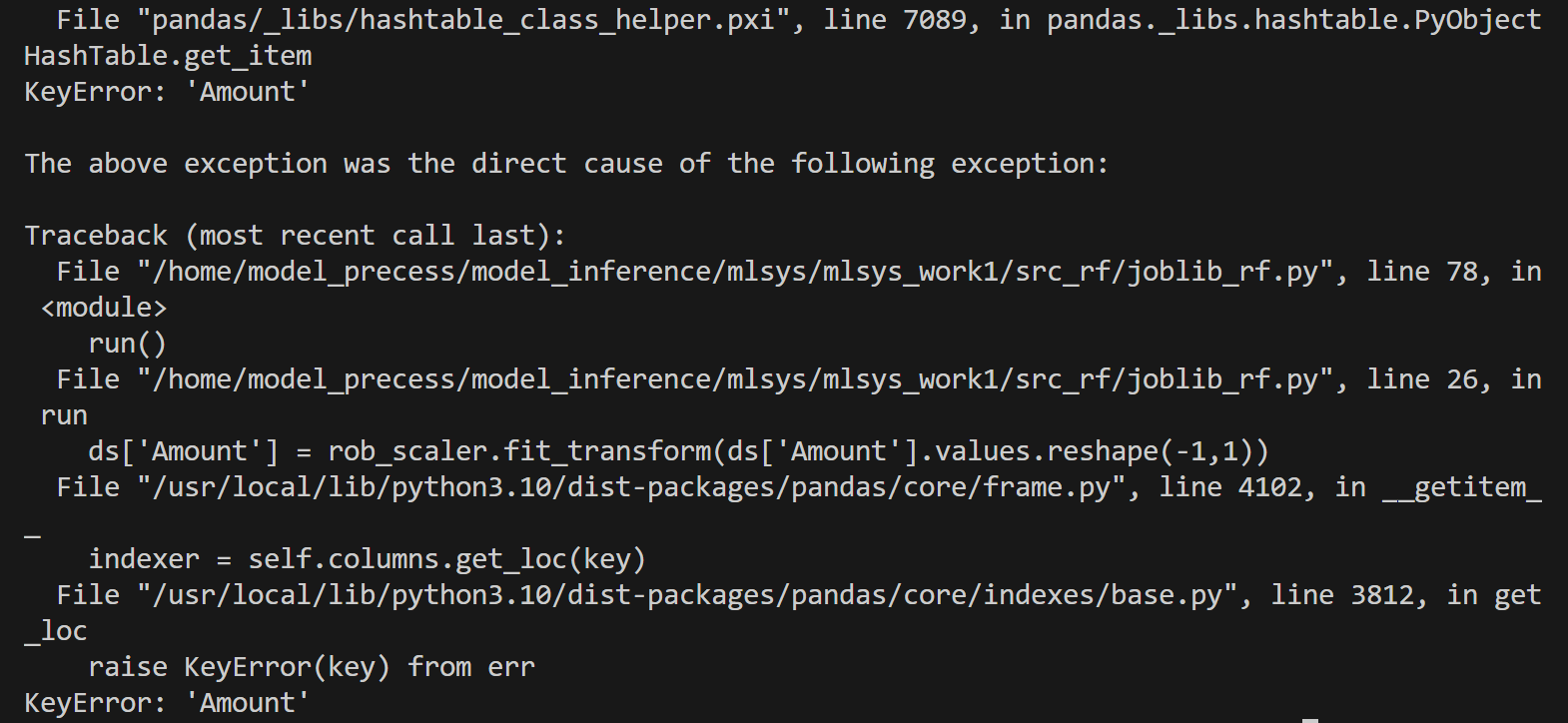
后续找到正确的数据集后再运行。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python学习(2):在单机机器学习,使用Dask实现鸢尾数据集 Iris 的分类任务

发表评论 取消回复