项目背景
项目的目的,是为了对情感评论数据集进行预测打标。在训练之前,需要对数据进行数据清洗环节,下面对数据集进行清洗,清洗完,后续再进行训练、评估
数据清洗
导包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
import pickle
import numpy as np
import gc
import swifter
import os
导入数据
df = pd.read_csv('data/sentiment_analysis.csv')
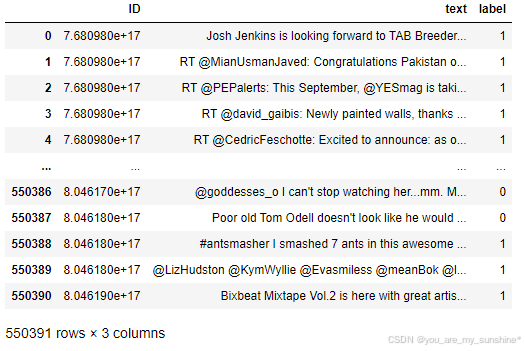
df
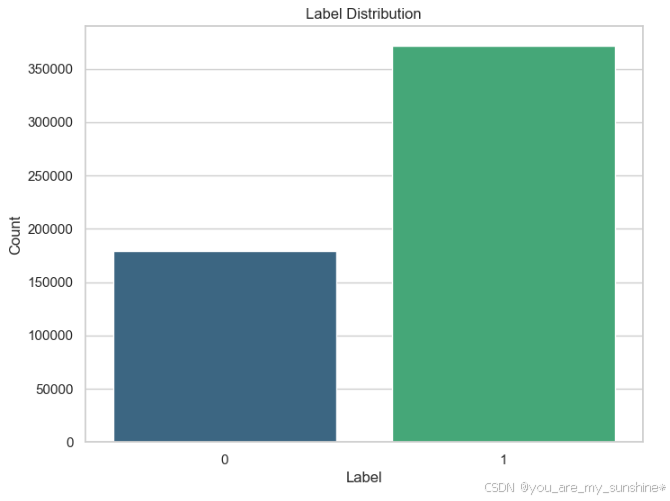
查看标签分布
# 设置Seaborn的样式
sns.set(style="whitegrid")
# 创建一个计数图
plt.figure(figsize=(8, 6))
sns.countplot(x='label', data=df, palette='viridis')
# 添加标题和标签
plt.title('Label Distribution')
plt.xlabel('Label')
plt.ylabel('Count')
# 显示图形
plt.show()
删除emoji表情
import re
from cleantext import clean
df['text'] = df['text'].swifter.apply(clean)
删除URL
df['text'] = df['text'].swifter.apply(lambda x: re.sub(r'http\S+', '', x))
转换成小写
df['text'] = df['text'].swifter.apply(lambda x: x.lower())
删除停用词
import nltk
from nltk.corpus import stopwords
stopwords=set(stopwords.words('english'))
def remove_stopwords(data):
output_array=[]
for sentence in tqdm(data):
temp_list=[]
for word in sentence.split():
if word not in stopwords:
temp_list.append(word)
output_array.append(' '.join(temp_list))
return output_array
df['text'] = remove_stopwords(df['text'])

删除标点符号
import string
df['text'] = df['text'].swifter.apply(lambda x: x.translate(str.maketrans('', '', string.punctuation)))
保存清洗后的数据
df.to_csv('data/sentiment_analysis_clean.csv',index=False)
同类型项目
阿里云-零基础入门NLP【基于深度学习的文本分类3-BERT】
也可以参考进行学习
学习的参考资料:
深度之眼
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » NLP_情感分类_数据清洗

发表评论 取消回复