传统方法与预训练方法的比较
思想解读: 预训练的概念就和我们人读书和工作一样;先是通过基础教育到大学毕业,学习了通用的基础知识,这个做大多数工作,我们都能够快速学习和上手。模型预训练同样如此;避免了每一个下游任务都从零开始训练模型

由于语言模型不需要特别的标注数据,所以非常适合做预训练的目标。
预训练方式 --BERT
Mask Language Model (MLM)
训练任务
1.完型填空
Bidirectional Language Model
a.依照一定概率,用[mask]掩盖文本中的某个字或词

b.通过遮住词两侧的内容,去预测被遮住的词
2.句子关系预测
Next Sentence Prediction
[CLS] 师徒四人历经艰险[SEP] 取得真经[SEP] -> True
[CLS] 师徒四人历经艰险[SEP] 火烧赤壁[SEP] -> False
释义: 通过上下两句话,去训练模型去判断是否为上下句子关系,即一个二分类任务。但是目前大家普遍不太使用该训练任务,因为这个规律模型比较容易学习到。
模型结构
BERT主要包含两个部分,第一部分是embedding层,以及在embedding层后面的网络结构。
与word2vec对比
区别:word2vec是静态的,而BERT是动态的;在相同的文本输入后,word2vec输出的向量是固定的,BERT通过embedding后,还需进行后续网络层的计算,那么就能抓住输入的字与字、词与词;即token之间的关系。并能够进行计算输出。
BERT结构-Embedding
释义图:
释义:
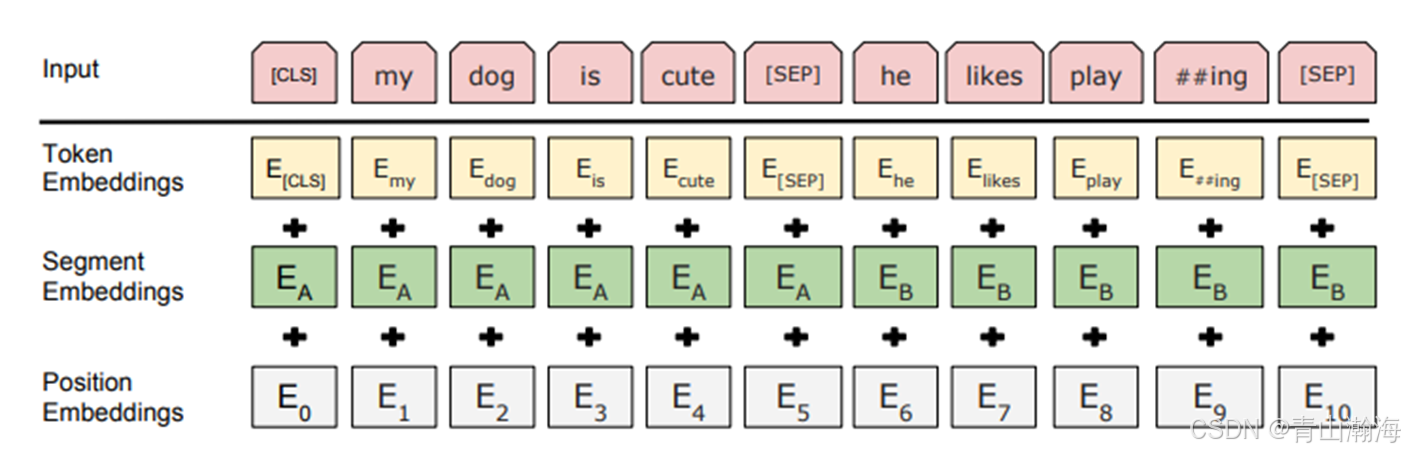
1.Token Embeddings就是传统的embedding;即将词或字转为对应的向量。所以它的大小:
Word-list _Size * Vector_size 即词表大小和向量空间的大小
2.Segment Embeddings是由于训练任务中,需要区别两句话,前面我们说需要区分两句话是否为上下句;这里用两个向量就能够去标记是两句话,所以大小为:2 * Vector_size
3.Position Embeddings是对输入的数据进行位置标记,在初始版的BERT中,一条数据最多有512长度,即标记的向量最多512个;所以该层大小为:512 * Vector_size
4.加入[CLS] [SEP] 来标记文本起始位置
5.上面3层embedding相加,就是整个embedding的结果;其大小为:World_Lenth(<=Position_Size) * Vector_Size
6.加和后会做Layer Normalization
BERT结构-Encoder
介绍: BERT的模型主体结构使用Google自己在17年提出的Transformer结构。
如下图:
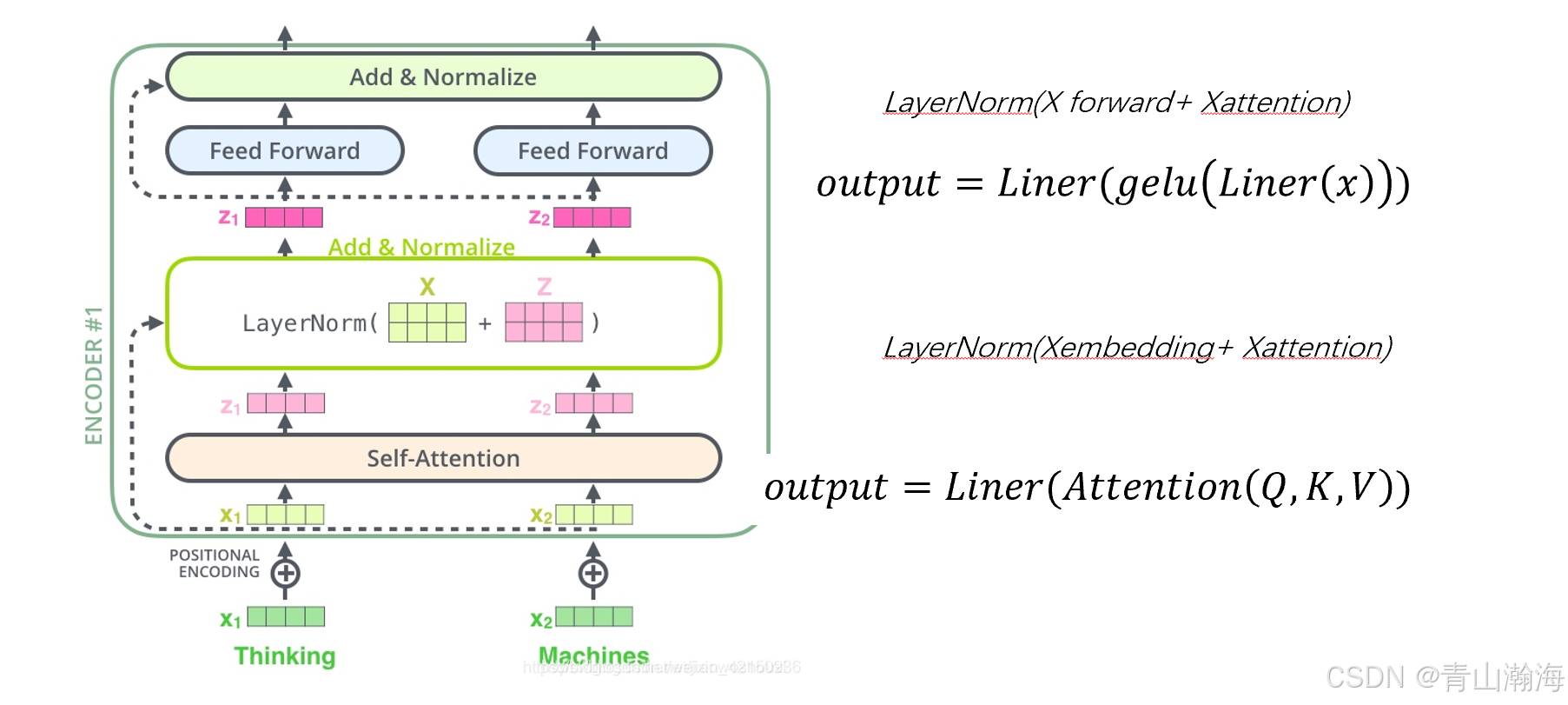
详细释义:
1.embedding后得到输入X;这里的X1、X2可以理解为将输入复制了多份进入到自注意力模块训练
2.自注意力计算完后,需要经过一个线下层;才会进入下一个模块
3.Add & Normailize 是残差计算,这里会将自注意力计算后的结果加上输入注意力计算前的值;再过一个归一化层;这里加上原有值,即残差计算的目的:是为了使得模型搭的更深;因为self-attention会捕捉一些规律,但是也会遗失其他的信息;加上一个计算前的值(可以是前一层、也可以是前几层的值)就可以保留
4.前馈网络Feed Forward就是经过两个线性层;和一个激活层;注意点在基础的BERT中,进入前馈网络的结构为:World_Length* Vector_Size;这里的两个线性层分别为:Vector_Size * 4Vector_Size;和 4Vector_Size * Vector_Size;所以第二个线性层计算后,输出仍然为:World_Length* Vector_Size。
5.最后再次经过一个残差计算,残差计算经过一个线性层计算后,就完成了一个基础的transformer结构
BERT结构-self-attention
示意图:
其中Z的计算公式:
释义:
1.我们先来梳理矩阵计算的情况
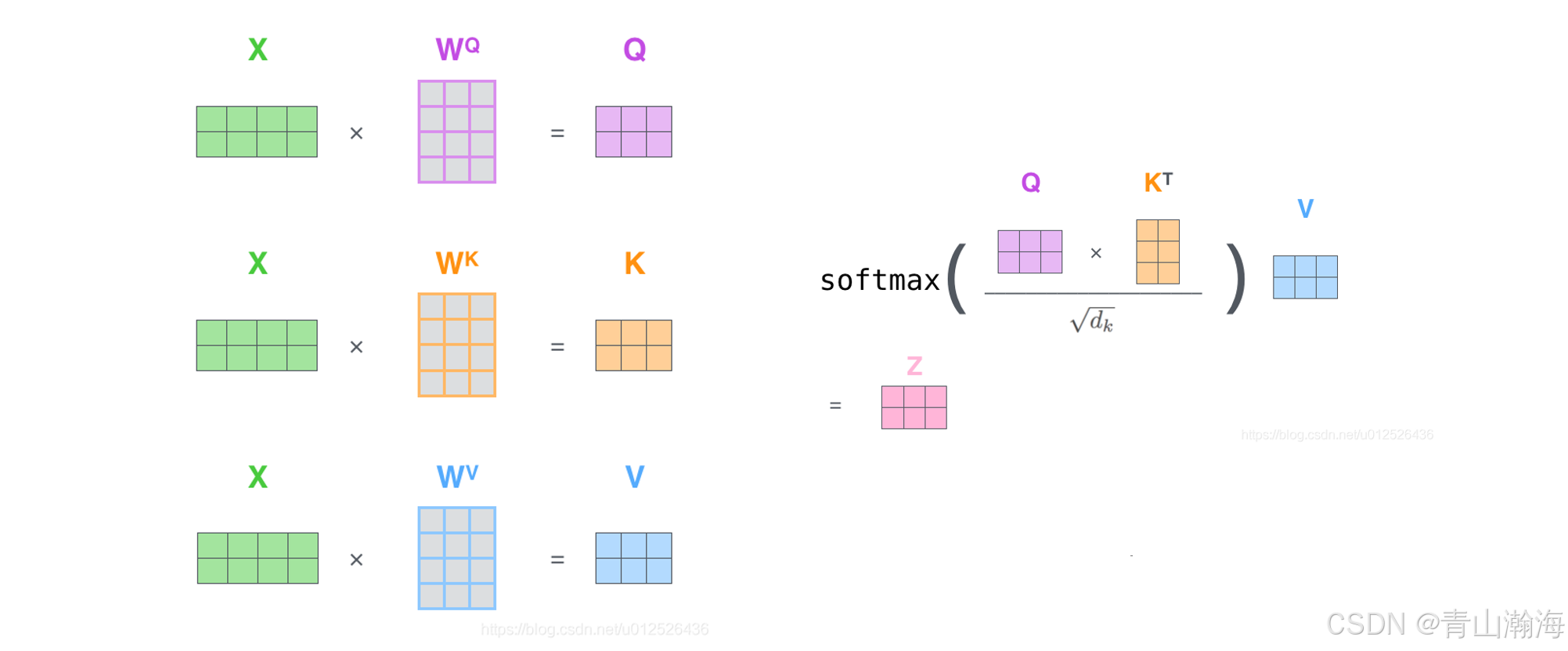
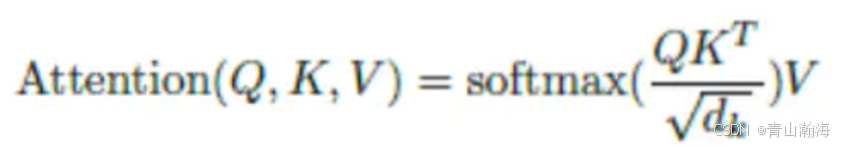
a.图中,x就是我们Embedding输入,是
World_Length* Vector_Size
b.我们把x拆成3份,分别于紫色、黄色、蓝色的线下层想乘(Q、K、V);我们最后计算的结果,对矩阵的形状是不变的;所以输出的形状需要为:World_Length* Vector_Size;那么线下层的形状就是:Vector_Size * Vector_Size
c.公式中,Q、K进行相乘;那么K需要进行转置,即K左上角T的含义;转置后,K的矩阵形状:Vector_Size * World_Length;所以Q、K相乘的结果为:World_Length * World_Length
d.Q、K相乘后,进行一些列操作,不影响矩阵的形状,继续与V相乘,结果Z的形状就是:World_Length* Vector_Size;即和输入的形状一致
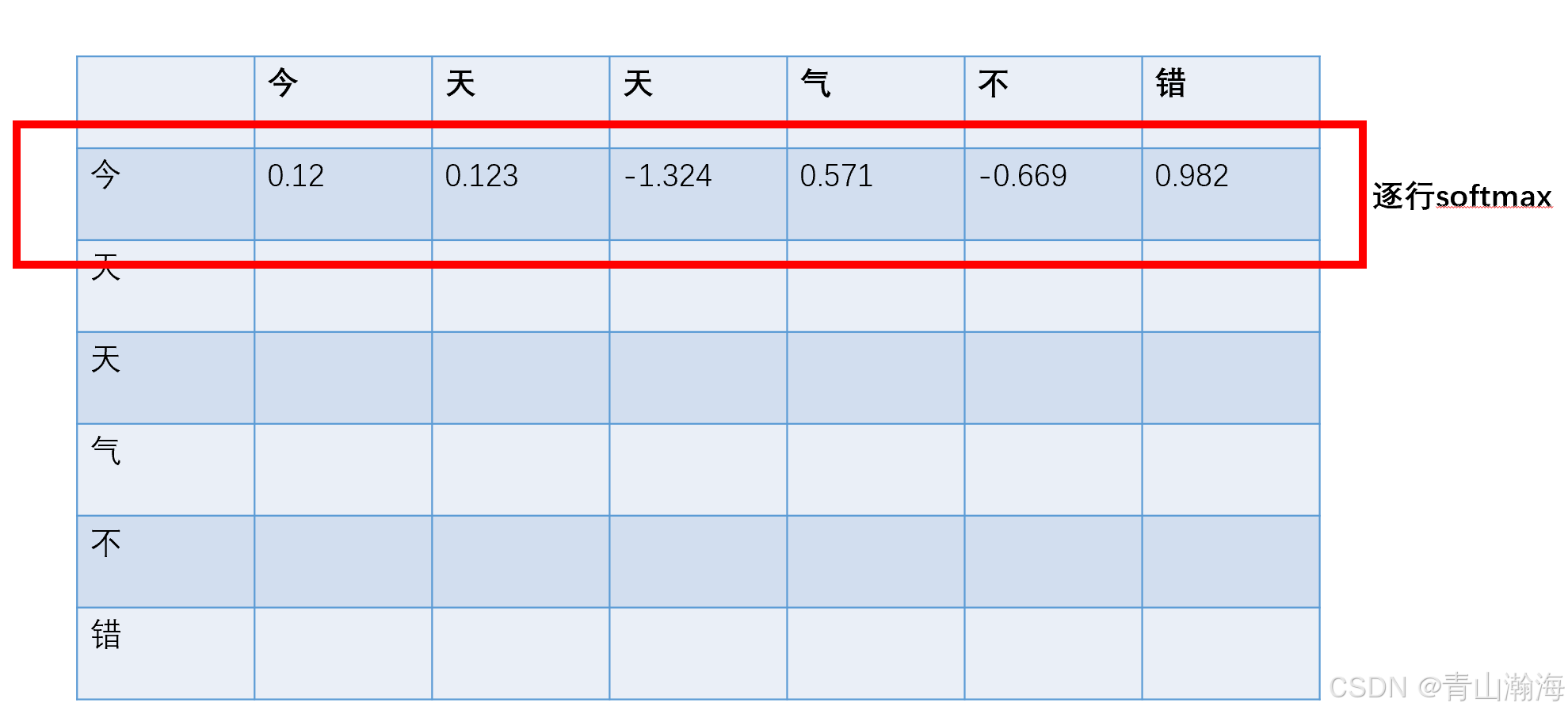
2.Q*K.T和softmax的理解
Q*K.T即:World_Length * World_Length;这个World_Length就是我们输入的文本长度。
所以我们展开可有下面示意图:
注意: 矩阵中的数据,是不是就代表着,这个词与该句子中其他词的关系紧密程度呢。所以这行数据,就是这个字对这句话的注意力。
softmax作用: 就是归一化操作,即将字与句子中其他词的关系程度之和,归一化到1的区间中来。
3.根号下dk的理解
我们在前面说,Q、K、V是通过输入x和对应的线下层相乘得到的;其形状为:World_Length* Vector_Size;
重点关注
1.在进行后续Q、K.T相乘 和乘V的步骤之间,是对Q K V进行拆分的;
2.比如:基础版本BERT的Vector_size为768;这里拆分成12部分,即多头数量为12,;那么每一个Q的形状:World_Length * 64
3.上面拆分后,V也会同样拆分,分别进行计算,最后合并在一起得到:World_Length* Vector_Size
4.最后合并的矩阵再进行 除于根号dk;再归一化的操作:
示意图:
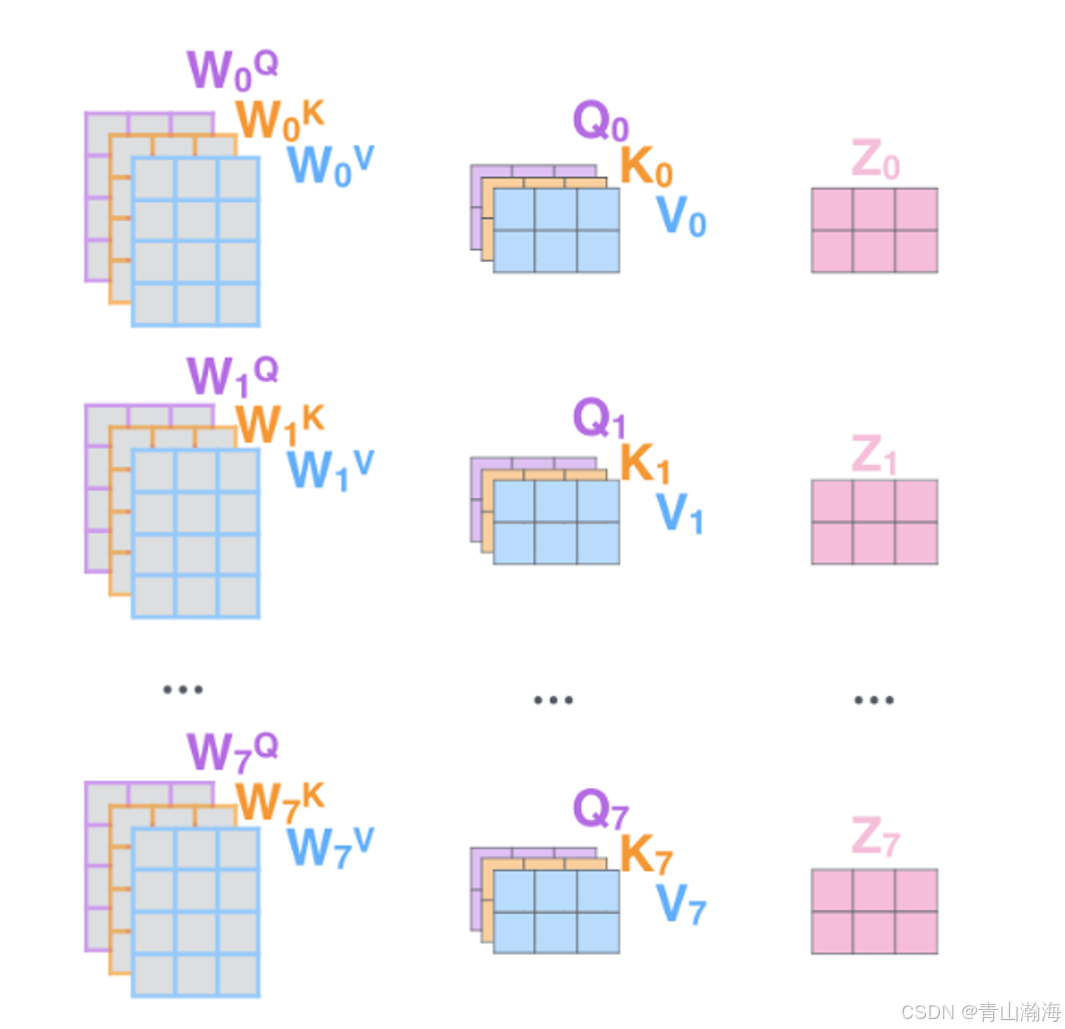
注意、总结: 在多个Q * K.T中,不管Q、K的Vector_Size 拆分成多少份,即有多少个多头计算;但是在这里计算的结果都是:World_Length * World_Length ;我们上面说了,就是词与句子中其他词的关系紧密程度。
注意核心理解比喻: 这里的多头,造成有多个World_Length * World_Length的结果,其实就是模型在不同维度,去找句子中词与词之间的关系。多头1找的是名称关系紧密程度、多头2找的是动词的关系紧密程度…
dk的值: 在基础版本的BERT中,dk是64,这个值是词向量维度:768与多头数量12的商。
dk作用: 因为softmax是将多个值的和归一化为1;根据softmax的函数特性,会出现在进行归一化的数中,有的比较大,归一化后就接近1;而小的数,就接近零了;这样对于模型的计算不好,这种接近零的值要尽量避免;所以先除于dk;使得值的差距被缩放;再进行归一化。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 语言模型-预训练模型(三)

发表评论 取消回复