Introducing Apple’s On-Device and Server Foundation Models
technical details June 10, 2024
在2024年的全球开发者大会上,苹果推出了Apple Intelligence,这是一个深度集成到iOS 18、iPadOS 18和macOS Sequoia中的个人智能系统。Apple Intelligence由多个高性能生成模型组成,专门为用户的日常任务提供支持,并可以根据当前活动进行实时调整。内置于Apple Intelligence中的基础模型经过精细调整,用于改善用户体验,例如撰写和完善文本、优先处理和总结通知、创建与家人和朋友对话时有趣的图像以及简化跨应用程序交互所需的应用内操作。在接下来的概述中,
本文将详细介绍其中两个模型——一个拥有约30亿参数的设备上语言模型以及一个更大且运行在苹果自研芯片服务器上并可通过私有云计算使用的服务器端语言模型——它们如何被构建和适应以高效、准确且负责任地执行特定任务。这两个基础模型是苹果创建用于支持用户和开发者而形成更大生成模型家族中一部分;该家族还包括编码模型(用于向Xcode添加智能功能)以及扩散模型(帮助用户在消息应用程序等场景下进行视觉表达)。我们期待很快分享关于这一更广泛模型集合的更多信息。
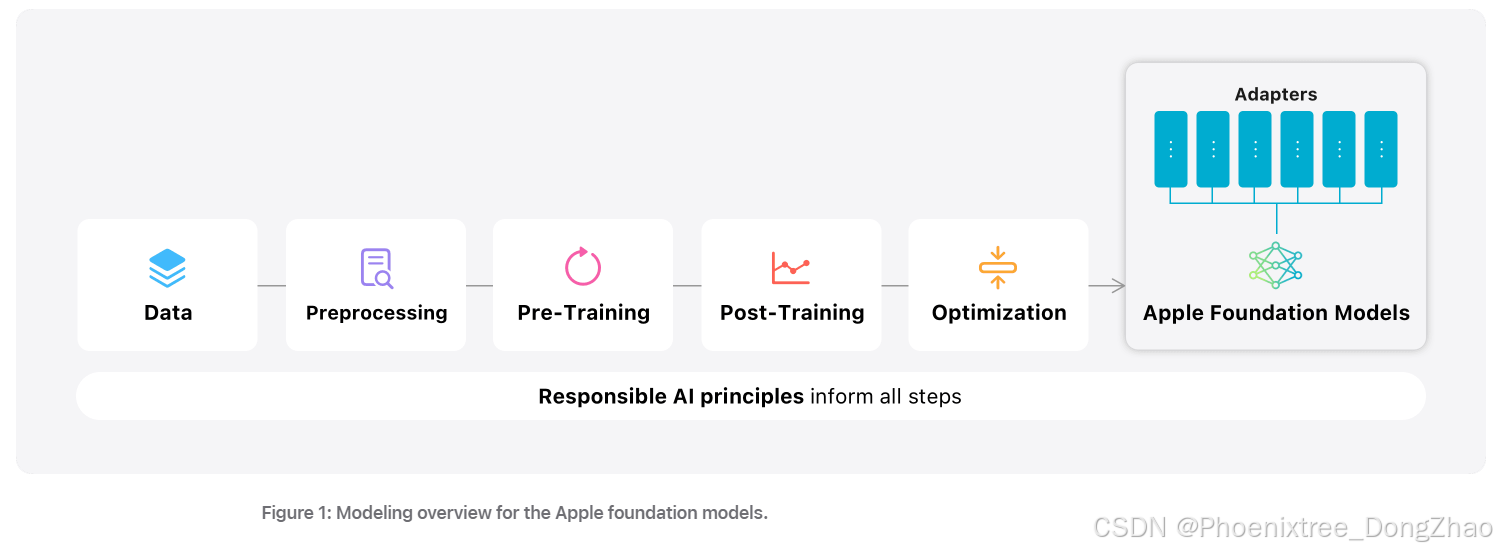
全面详细的技术说明:Apple 的设备端与服务器端基础模型
在 2024 年全球开发者大会(WWDC24)上,Apple 引入了 Apple Intelligence,一个深度集成于 iOS 18、iPadOS 18 和 macOS Sequoia 的个人智能系统。Apple Intelligence 由多个高性能的生成模型组成,这些模型专注于用户的日常任务,并能根据当前活动快速适应。本文档将详细介绍 Apple 的设备端(约 30 亿参数)和服务器端(基于 Private Cloud Compute)语言模型,探讨它们的构建、优化及在多种任务中的表现。
模型架构与训练
-
训练框架与数据
Apple 的基础模型基于开源的 AXLearn 框架进行训练,该框架建立在 JAX 和 XLA 之上,支持在各种训练硬件和云平台上高效扩展,包括 TPU 和 GPU。模型训练数据主要来自公开数据集和 AppleBot 爬取的网页内容,后者是 Apple 的网络爬虫工具。所有使用的内容均经过数据使用者控制(Data Usage Control)处理,确保数据合法合规。
在数据处理阶段,Apple 过滤掉个人身份信息和低质量内容,如信用卡号码、社会安全号码和脏话。同时,通过数据提取、去重和模型分类器应用,选择高质量文档进行训练。此外,Apple 还利用人工标注和合成数据混合的策略,以提升模型训练效果。
-
预训练与后训练优化
预训练阶段,Apple 使用并行处理技术,包括数据并行、张量并行、序列并行和全分片数据并行(FSDP),以提高训练效率。后训练阶段,则引入了两个关键算法:拒绝采样微调算法和教师委员会,以及从人类反馈中学习的强化学习算法(RLHF),这些算法显著提高了模型遵循指令的质量。
apple_inteligence
模型优化
-
设备端优化
为了在资源受限的设备上高效运行,Apple 对设备端模型进行了多项优化。首先,采用低比特量化技术,如低比特调色板化和激活量化,以减少内存和计算需求。对于关键组件,如 LoRA 适配器,Apple 采用混合 2 位和 4 位配置策略,平均每个权重为 3.7 比特,几乎保持了与未压缩模型相同的精度。
此外,Apple 使用了分组查询注意力机制(grouped-query-attention)和共享输入输出词汇嵌入表,进一步减少内存占用和推理成本。设备端模型的词汇量被设置为 49K,适用于大多数日常应用场景。
-
服务器端优化
服务器端模型则部署在 Apple 硅服务器上,利用 Private Cloud Compute 提供高性能计算能力。尽管服务器端模型不受设备资源限制,但 Apple 仍对其进行了优化,如使用更大的词汇量(100K)以支持更广泛的语言和技术术语。同时,通过共享嵌入表和查询注意力机制,保持高效推理。
任务适配与评估
-
适配器机制
Apple 通过 LoRA 适配器为不同用户任务进行微调,如文本摘要、优先级排序和通知总结等。每个适配器针对具体任务需求进行训练,以确保模型输出满足用户期望。例如,在邮件摘要任务中,适配器会根据邮件内容生成简洁明了的摘要,同时保持关键信息的完整性。
-
性能评估
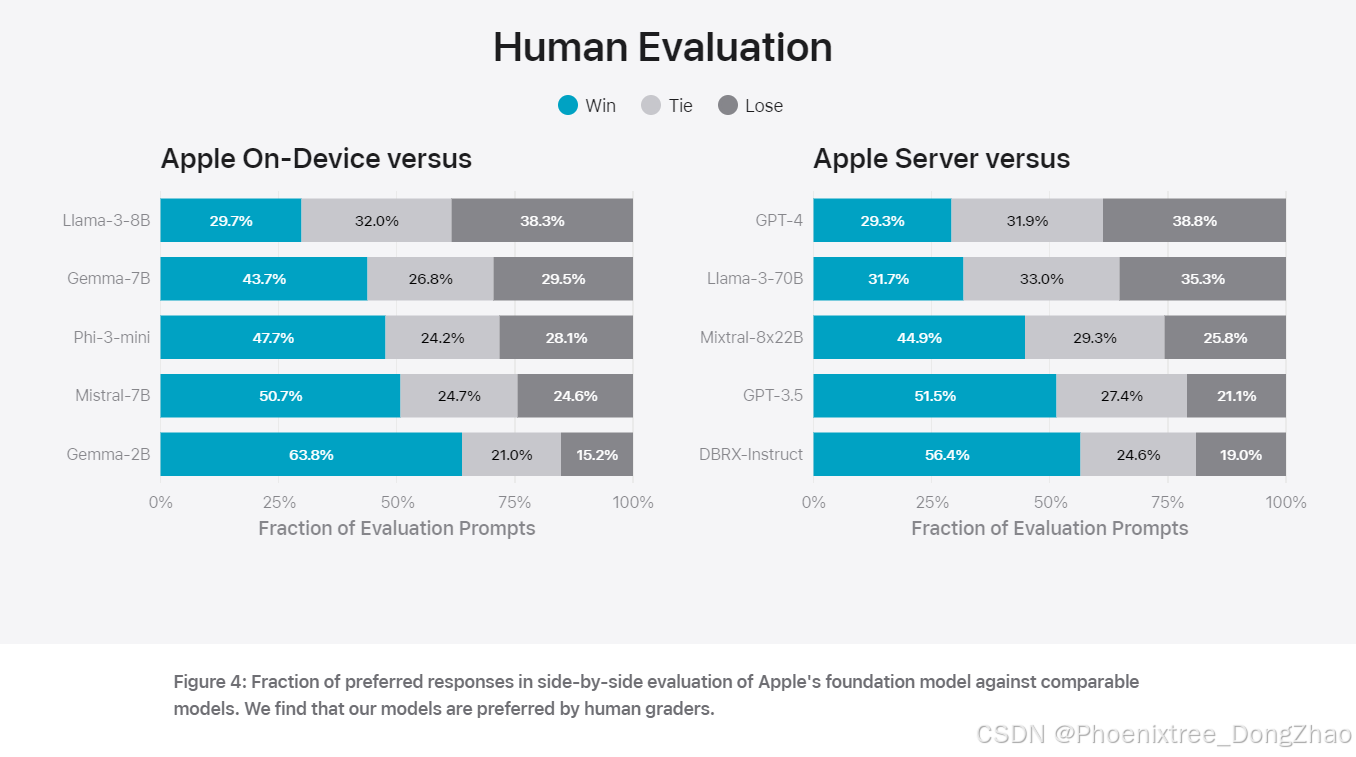
Apple 采用多种评估方法来衡量模型性能,包括自动评估和人类评估。自动评估通过标准基准测试(如 IFEval)衡量模型的指令遵循能力和写作能力。人类评估则通过真实用户场景下的使用反馈,确保模型输出的有用性和无害性。
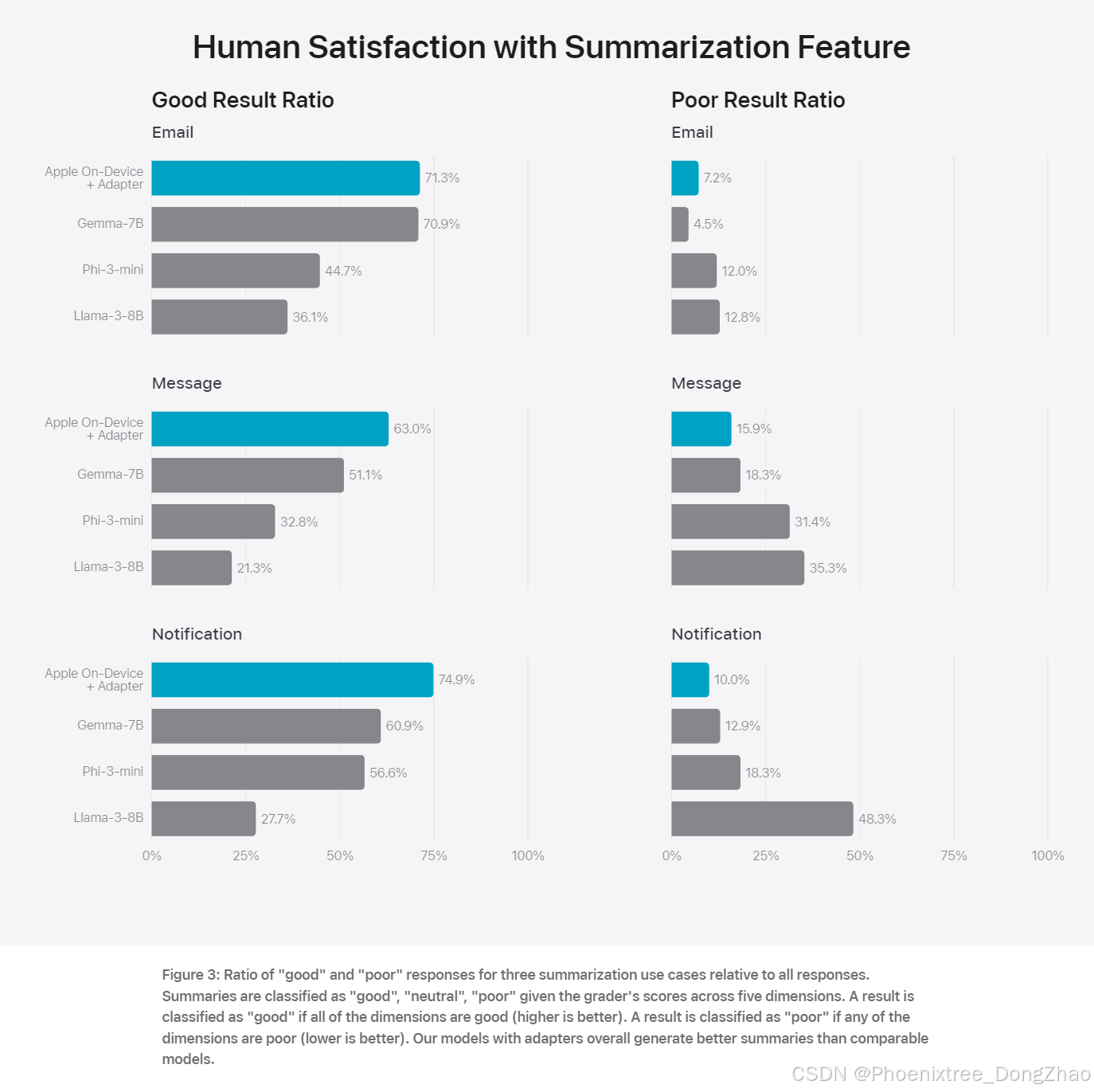
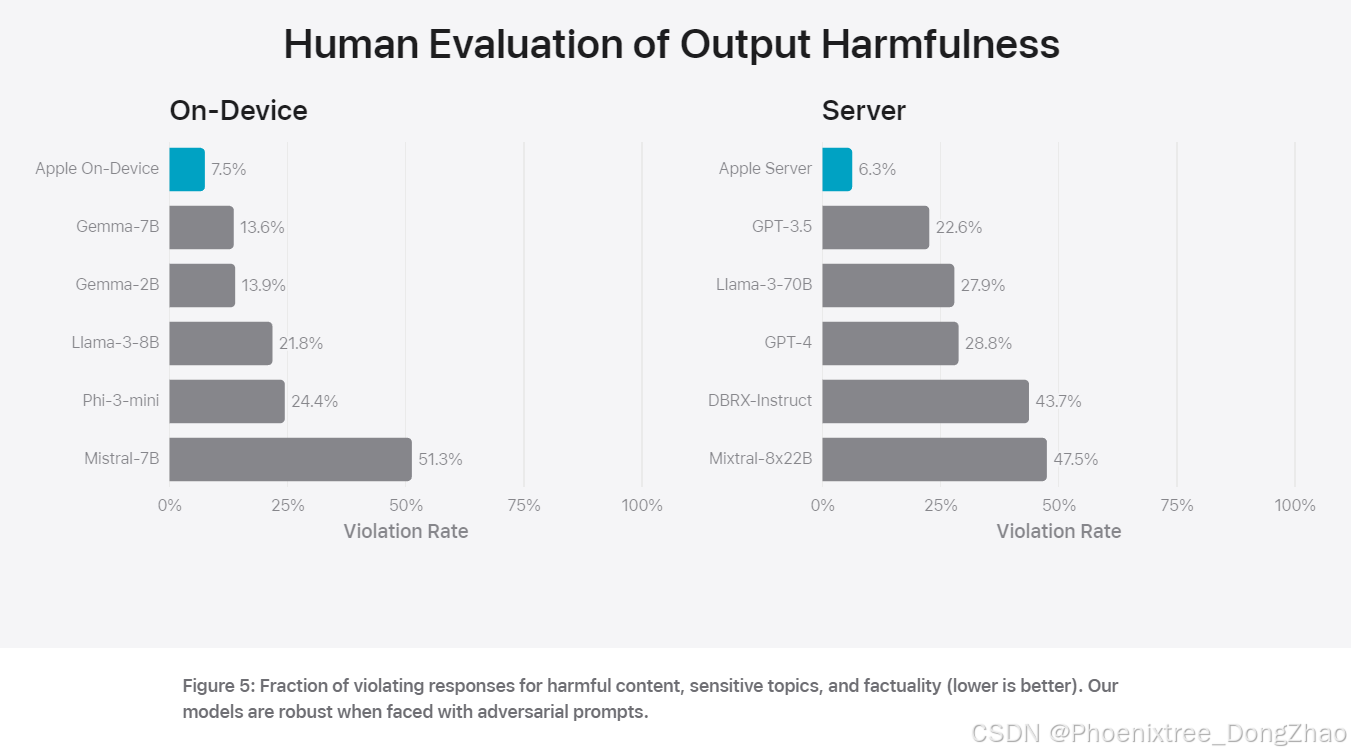
在摘要任务中,Apple 的设备端和服务器端模型均表现出色,生成的摘要在准确性、相关性和有用性方面优于其他可比模型。特别是在处理敏感内容和对抗性样本时,Apple 的模型展现出较高的鲁棒性和安全性。
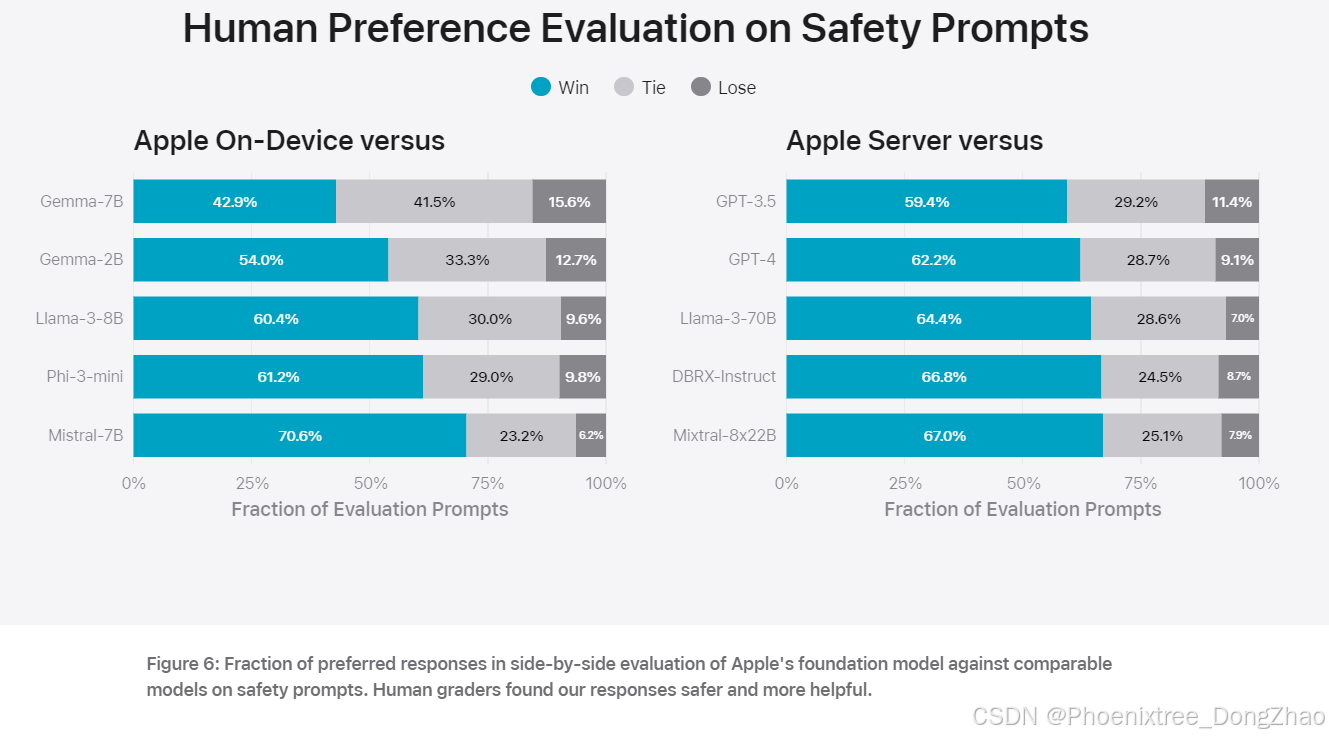
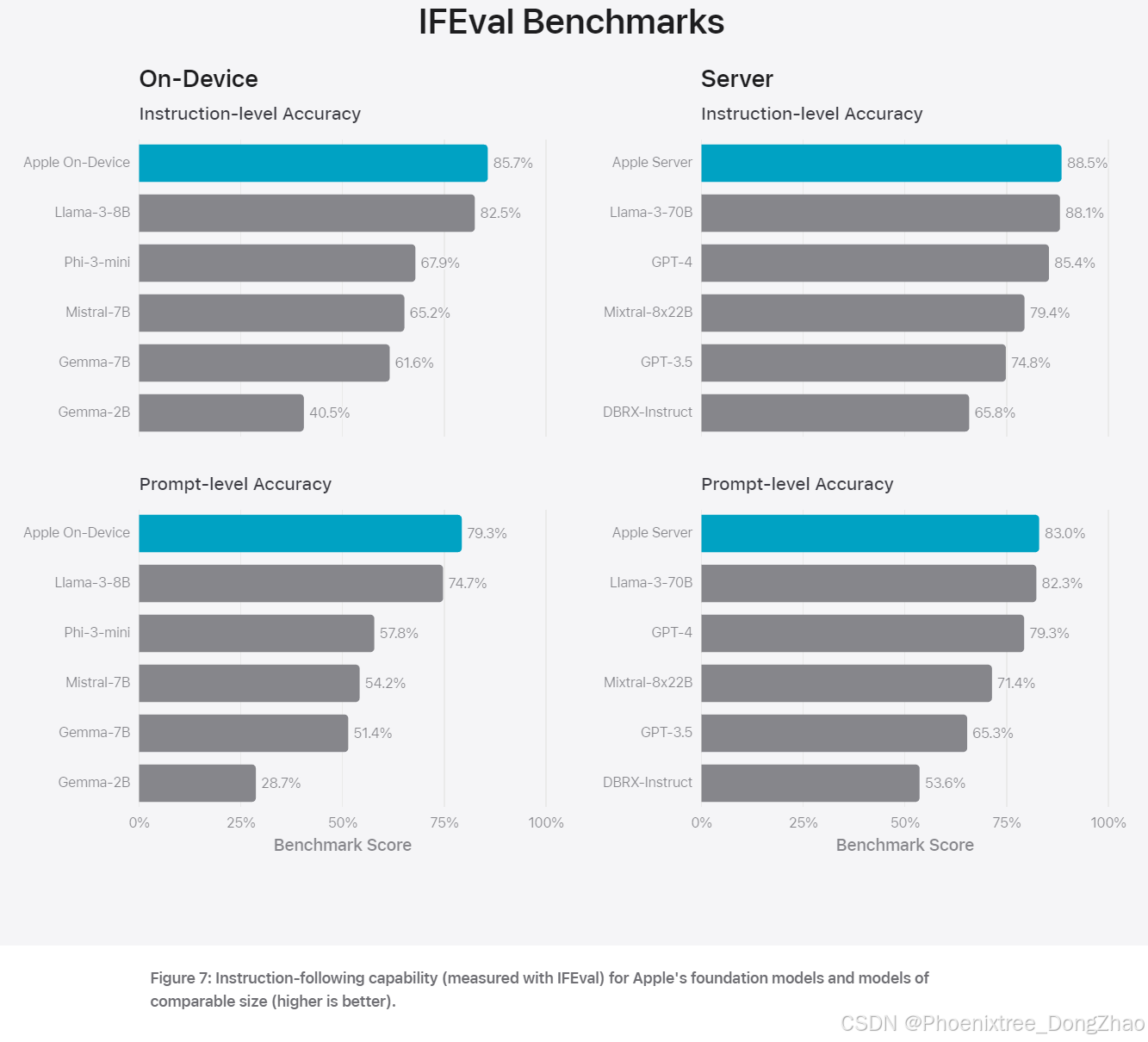
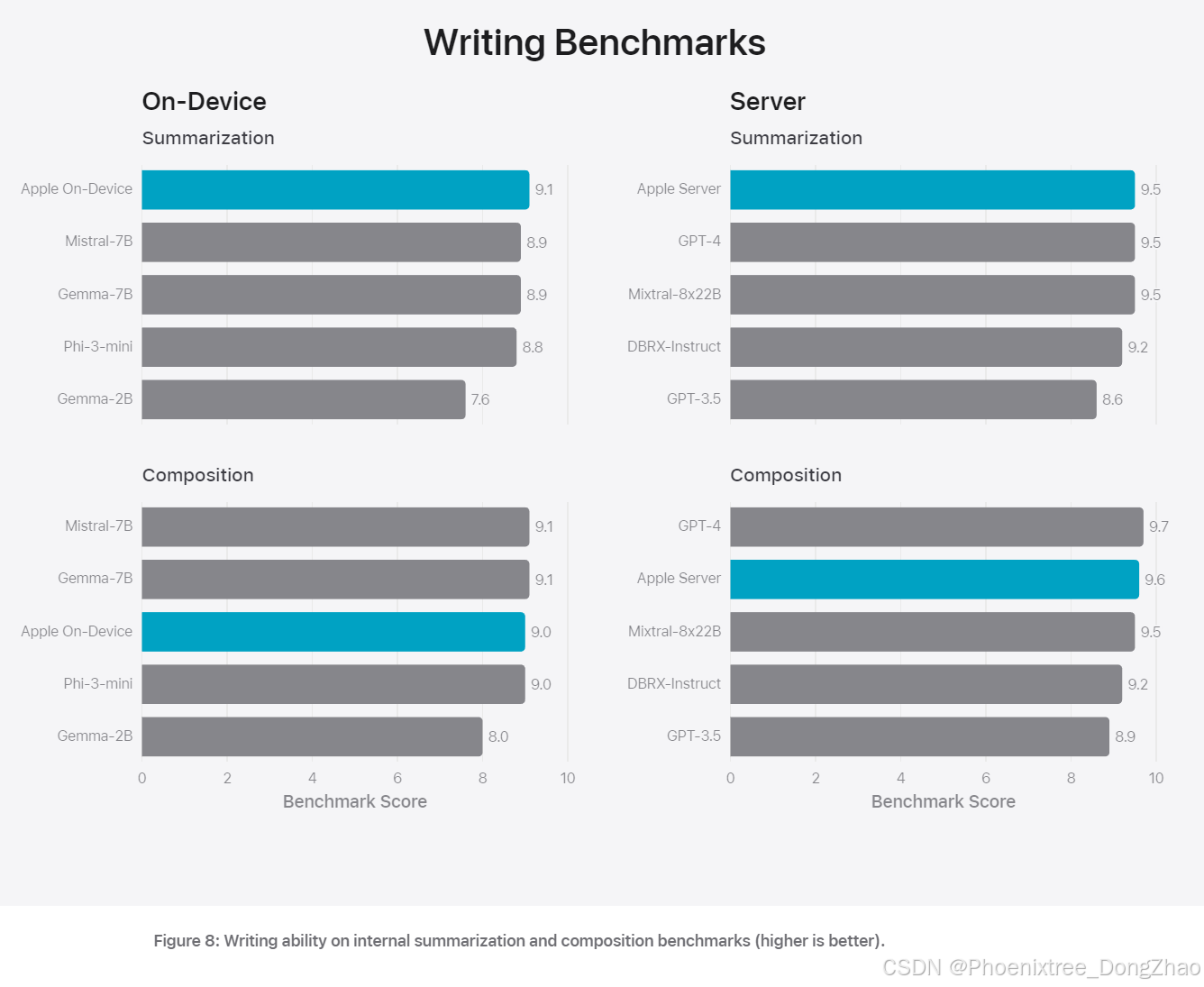
责任性 AI 原则
Apple 在开发 AI 工具及其底层模型时,始终坚持责任性 AI 原则。这些原则包括:
- 赋能用户:识别 AI 可以负责任地用于创建满足用户特定需求的工具。
- 代表用户:构建能够真实反映全球用户的深度个性化产品,避免刻板印象和系统性偏见。
- 设计需谨慎:在设计、模型训练、功能开发和质量评估的每个阶段采取预防措施,防止 AI 工具被误用或造成潜在伤害。
- 保护隐私:通过强大的设备端处理和创新的基础设施(如 Private Cloud Compute)保护用户隐私。
Apple 的设备端和服务器端基础模型作为 Apple Intelligence 的核心组成部分,展示了强大的生成能力和广泛的应用潜力。通过持续的技术创新和优化,Apple 致力于为用户提供更加智能、高效和安全的个人智能体验。未来,Apple 计划分享更多关于其生成模型家族的信息,包括语言模型、扩散模型和编码模型等,进一步推动 AI 技术的发展和应用。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Apple 智能基础语言模型

发表评论 取消回复