系列文章:
PyTorch 基础学习(1) - 快速入门
PyTorch 基础学习(2)- 张量 Tensors
PyTorch 基础学习(3) - 张量的数学操作
PyTorch 基础学习(4)- 张量的类型
PyTorch 基础学习(5)- 神经网络
PyTorch 基础学习(6)- 函数API
PyTorch 基础学习(7)- 自动微分
介绍
在深度学习中,常常需要在多个进程之间共享数据。torch.multiprocessing 封装了 Python 的 multiprocessing 模块,使得在不同进程之间共享 PyTorch 张量变得更加简单和高效。通过使用 torch.multiprocessing,我们可以将张量或存储移动到共享内存中,从而在多个进程之间共享它们,而无需额外的复制操作。
主要概念
- 共享内存:通过共享内存,多个进程可以访问相同的数据,而无需将数据复制到每个进程的内存空间中。
- 共享策略:定义了如何在不同进程间共享张量的方式。常见的共享策略有
file_descriptor和file_system。 - CUDA 张量共享:CUDA 张量共享仅在 Python 3 中支持,且只能使用
spawn或forkserver启动方法。
主要应用场景
- 多进程训练:在分布式训练中,需要在不同进程间共享模型参数和数据。
- 数据加载:多进程的数据加载可以加速训练过程,而共享内存允许多个进程同时访问相同的数据。
- 模型并行:在模型并行中,可以将模型的不同部分分配给不同的进程,并通过共享内存来访问模型的各个部分。
基本使用方法
在使用 torch.multiprocessing 进行多进程张量共享时,首先需要将张量移动到共享内存中,然后再将其传递给其他进程。
以下是基本的代码实例:
import torch
import torch.multiprocessing as mp
def worker(shared_tensor):
# 在进程中访问共享张量
print(f"Worker process received tensor: {shared_tensor}")
if __name__ == "__main__":
# 创建一个张量
tensor = torch.tensor([1, 2, 3, 4])
# 将张量移动到共享内存中
shared_tensor = tensor.share_memory_()
# 创建多个进程并共享张量
processes = []
for _ in range(4):
p = mp.Process(target=worker, args=(shared_tensor,))
p.start()
processes.append(p)
for p in processes:
p.join()
共享策略管理
可以通过 torch.multiprocessing 来管理和设置共享策略,以便在不同的系统环境中实现更好的兼容性和性能。
获取系统支持的共享策略:
strategies = mp.get_all_sharing_strategies()
print(f"Supported sharing strategies: {strategies}")
获取当前的共享策略:
current_strategy = mp.get_sharing_strategy()
print(f"Current sharing strategy: {current_strategy}")
设置共享策略:
mp.set_sharing_strategy('file_system')
应用实例:并发线性规划
在这个实例中,我们将展示如何在多进程的数据加载中使用 torch.multiprocessing 来加速训练过程。我们将使用共享内存将数据集加载到内存中,然后在多个进程中共享这些数据,以便在训练时进行并行处理。
import torch
import torch.multiprocessing as mp
from torch.utils.data import DataLoader, TensorDataset
import torch.nn as nn
import torch.optim as optim
# 定义线性回归模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 线性层
def forward(self, x):
return self.linear(x)
# 定义训练函数
def train_model(dataloader, model, optimizer, criterion, epochs=10):
model.train() # 将模型设置为训练模式
for epoch in range(epochs):
for batch_idx, (inputs, targets) in enumerate(dataloader):
# 将数据移动到共享内存中,以确保进程之间共享
inputs, targets = inputs.share_memory_(), targets.share_memory_()
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch + 1}/{epochs}], Batch [{batch_idx + 1}/{len(dataloader)}], Loss: {loss.item()}")
# 主进程
if __name__ == "__main__":
# 生成一些模拟数据
torch.manual_seed(42) # 设置随机种子以保证结果可复现
x = torch.linspace(-10, 10, 100).view(-1, 1) # 输入数据 (100, 1)
y = 2 * x + 3 + torch.randn(x.size()) # 线性关系 y = 2x + 3 加上一些噪声
# 创建数据集和数据加载器
dataset = TensorDataset(x, y)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
# 将模型和数据复制到共享内存中
model = LinearRegressionModel().share_memory()
optimizer = optim.SGD(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
# 创建多个进程并共享数据进行训练
processes = []
for _ in range(4): # 使用4个进程
p = mp.Process(target=train_model, args=(dataloader, model, optimizer, criterion, 100))
p.start()
processes.append(p)
for p in processes:
p.join()
# 验证训练结果
model.eval() # 将模型设置为评估模式
with torch.no_grad():
predictions = model(x)
mse = criterion(predictions, y)
print(f"Final Mean Squared Error: {mse.item()}")
# 可视化结果
import matplotlib.pyplot as plt
plt.scatter(x.numpy(), y.numpy(), label='Original Data')
plt.plot(x.numpy(), predictions.numpy(), color='red', label='Fitted Line')
plt.legend()
plt.show()
执行结果:
......
Final Mean Squared Error: 0.9632949829101562
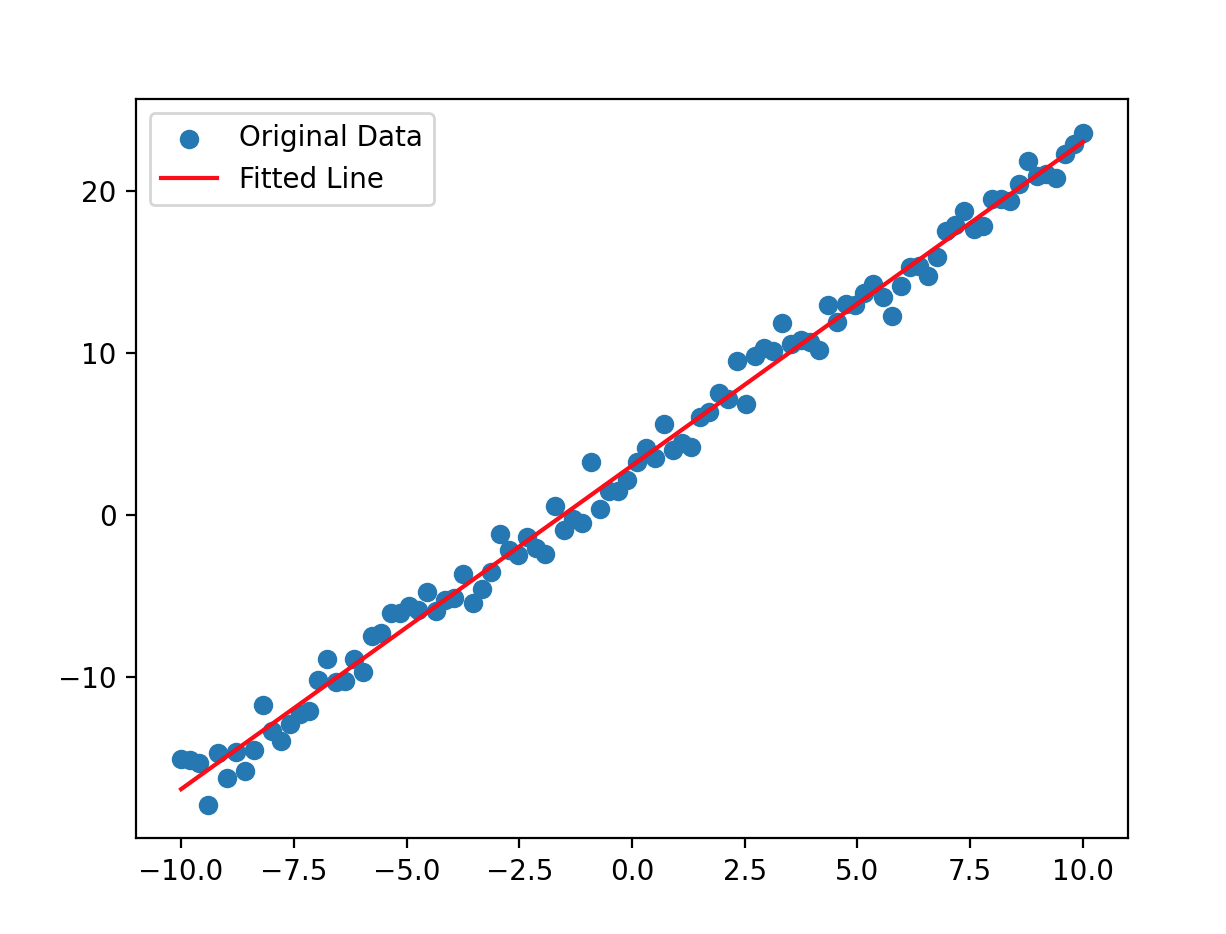
在这个实例中,我们创建了一个简单的数据集并将其加载到共享内存中。然后,多个进程可以并行地访问这些数据,从而提高训练的效率。
结论
torch.multiprocessing 是一个强大的工具,允许在 PyTorch 中轻松实现多进程张量共享。通过合理设置共享策略和使用共享内存,可以在多进程应用场景中显著提升性能。希望通过本教程,您能更好地理解和应用 torch.multiprocessing 来优化您的深度学习任务。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PyTorch 基础学习(8)- 多进程并发

发表评论 取消回复