点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
HDFS(已更完)
MapReduce(已更完)
Hive(已更完)
Flume(已更完)
Sqoop(已更完)
Zookeeper(已更完)
HBase(已更完)
Redis (已更完)
Kafka(已更完)
Spark(正在更新!)
章节内容
上节我们完成了如下的内容:
- RDD 的创建
- 从集合创建RDD、从文件创建RDD、从RDD创建RDD
- RDD操作算子:Transformation 详细解释
Transformation
RDD的操作算子分为两类:
- Transformation,用来对RDD进行转换,这个操作时延迟执行的(或者是Lazy),Transformation,返回一个新的RDD
- Action,用来触发RDD的计算,得到相关计算结果或者将结果保存到外部系统中,Action:返回int、double、集合(不会返回新的RDD)

上节完成了Transformation
Action
Action 用来触发RDD的计算,得到相关的计算结果
- collect()/collectAsMap()
- stats/count/mean/stdev/max/min
- reduce(func)/fold(func)/aggregate(func)
- first() 返回第一个RDD
- take(n) 从开头拿一定数量的RDD
- top(n) 按照将需或指定排序规则 返回前num个元素
- takeSample 返回采样数据
- froeach / foreachPartition 与 map、mapPartition类似
- saveAsTextFile/saveAsSequenceFile/saveAsObjectFile
Key-Value RDD
RDD整体上分为 Value类型 和 Key-Value类型
前面介绍是 Value类型的RDD操作,实际上使用更多的是Key-Value类型的RDD,也称为 PairRDD
- Value类型的RDD操作基本集中在RDD.scala中
- Key-Value类型的RDD操作集中在PairRDDFunctions.scala中
创建PairRDD
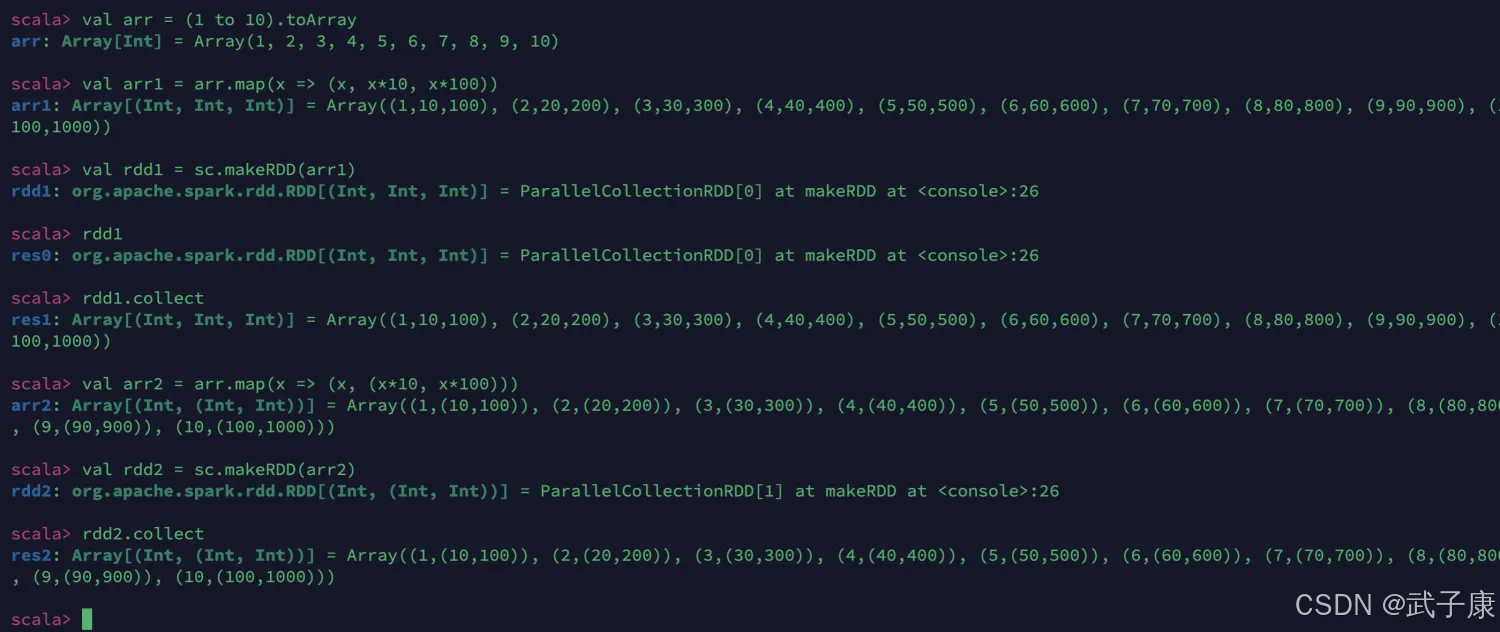
val arr = (1 to 10).toArray
val arr1 = arr.map(x => (x, x*10, x*100))
# rdd1 不是 Pair RDD
val rdd1 = sc.makeRDD(arr1)
# rdd2 是 Pair RDD
val arr2 = arr.map(x => (x, (x*10, x*100)))
val rdd2 = sc.makeRDD(arr2)
运行查看如下的结果:
Transformation操作
mapValues
# mapValues代码更简洁
val a = sc.parallelize(List((1,2),(3,4),(5,6)))
val b = a.mapValues(x => 1 to x)
b.collect
运行结果如下图:

flatMapValues
将values压平、拍平
val c = a.flatMapValues(x => 1 to x)
c.collect
执行结果如下图所示:

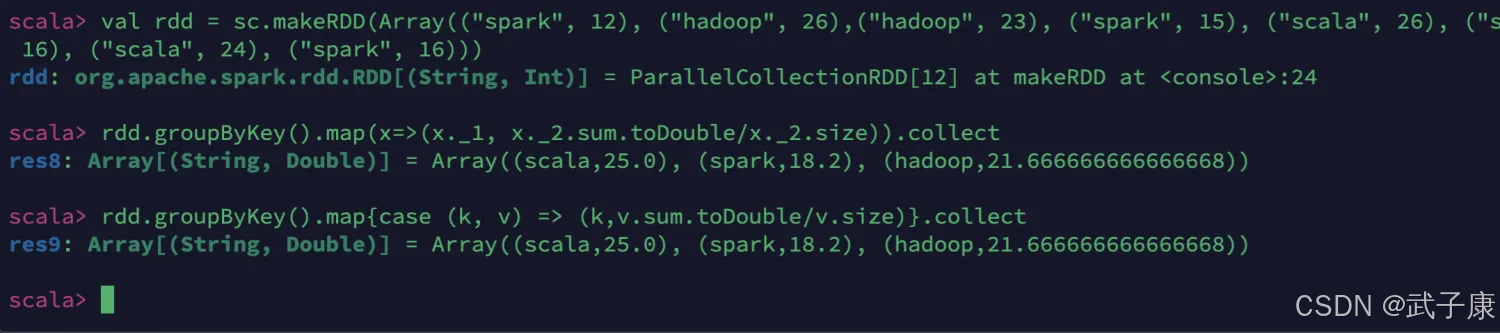
groupByKey
键值对的key表示图书名称,value表示某天图书销量。计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
val rdd = sc.makeRDD(Array(("spark", 12), ("hadoop", 26),("hadoop", 23), ("spark", 15), ("scala", 26), ("spark", 25),("spark", 23), ("hadoop", 16), ("scala", 24), ("spark", 16)))
# 三种写法
rdd.groupByKey().map(x => (x._1, x._2.sum.toDouble/x._2.size)).collect
rdd.groupByKey().map{case (k, v) => (k,v.sum.toDouble/v.size)}.collect
rdd.groupByKey.mapValues(v => v.sum.toDouble/v.size).collect
执行结果如下图所示:
reduceByKey
这种方式也可以
rdd.mapValues((_, 1)).reduceByKey((x, y)=> (x._1+y._1, x._2+y._2)).mapValues(x => (x._1.toDouble / x._2)).collect()
foldByKey
rdd.mapValues((_, 1)).foldByKey((0, 0))((x, y) => {
(x._1+y._1, x._2+y._2)}).mapValues(x=>x._1.toDouble/x._2).collect
执行结果如下图所示:

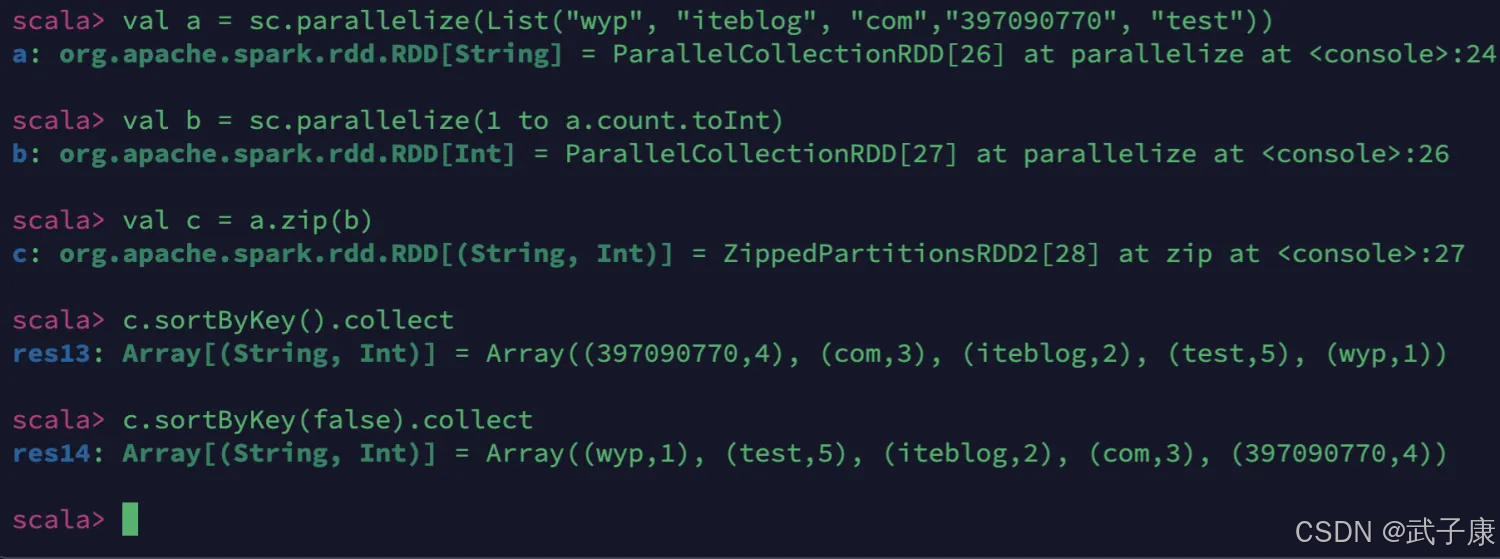
sortByKey
根据key来进行排序
val a = sc.parallelize(List("wyp", "iteblog", "com","397090770", "test"))
val b = sc.parallelize(1 to a.count.toInt)
val c = a.zip(b)
c.sortByKey().collect
c.sortByKey(false).collect
执行如下图所示:
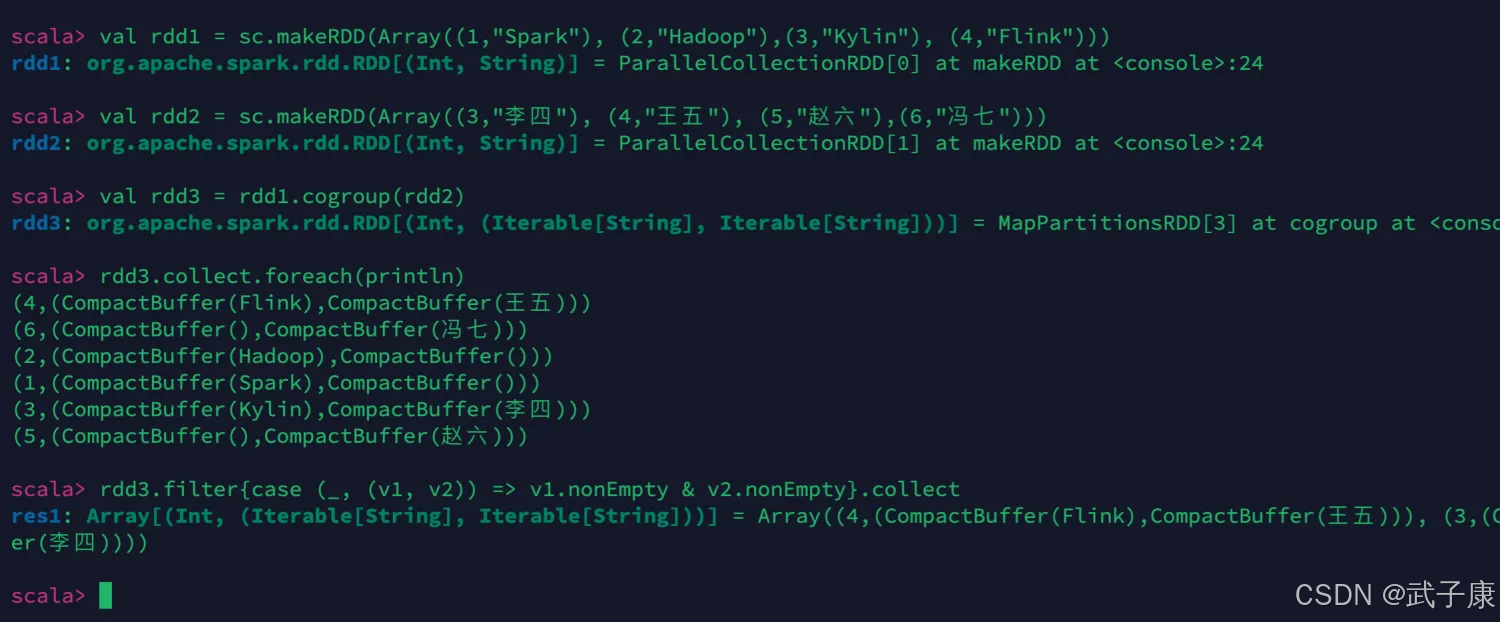
cogroup
val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"),(3,"Kylin"), (4,"Flink")))
val rdd2 = sc.makeRDD(Array((3,"李四"), (4,"王五"), (5,"赵六"),(6,"冯七")))
# join
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect.foreach(println)
rdd3.filter{case (_, (v1, v2)) => v1.nonEmpty & v2.nonEmpty}.collect
执行结果如下图所示:
outerjoin
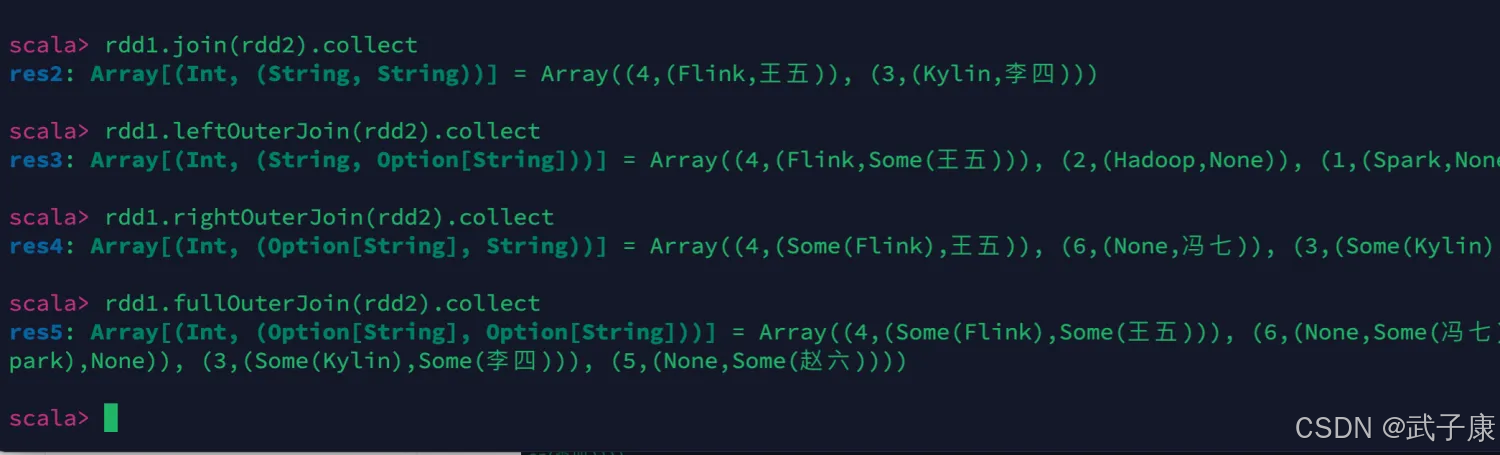
# 不同的JOIN操作
rdd1.join(rdd2).collect
rdd1.leftOuterJoin(rdd2).collect
rdd1.rightOuterJoin(rdd2).collect
rdd1.fullOuterJoin(rdd2).collect
执行结果如下图所示:
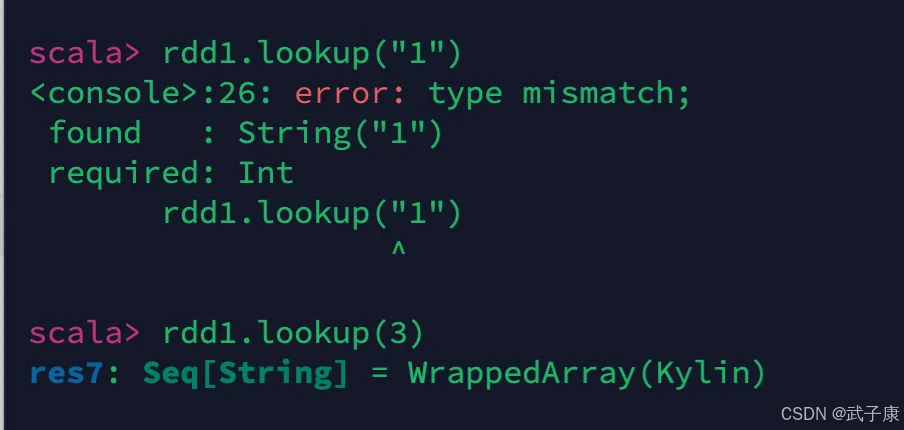
lookup
rdd1.lookup("1")
rdd1.lookup(3)
执行结果如下图所示:
文件输入输出
文本文件
- 数据读取:textFile(String),可指定单个文件,支持通配符
- 返回值RDD[(String, Sting)],其中Key是文件的名称,Value是文件的内容。
- 数据保存:saveAsTextFile(String) 指定输出目录
csv文件
读取CSV(Comma-Separated Values)/TSV(Tab-Separaed Values)数据和读取JSON数据相似,都需要先把文件当做普通文件来读取数据,然后通过将每一行进行解析实现对CSV的提取。
CSV/TSV 数据的输出也是需要将结构化RDD通过相关库转换成字符串的RDD,然后使用Spark的文本文件API写出去
JSON文件
如果JSON文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文件来读取,然后利用相关的JSON库对每一条数据进行JSON解析
JSON数据的输出主要通过在输出之前将由结构化数据组成的RDD转换为字符串RDD,然后使用Spark的文本文件API写出去
JSON文件的处理使用 SparkSQL 最为简洁。
SequenceFile
SequenceFile文件是Hadoop用存储二进制形式的Key-Value而设计的一种平面文件(FlatFile)。
Spark有专门用来读取SequenceFile的接口,在SparkContext中,可以调用:SequenceFile[keyClass, valueClass];
调用 saveAsSequenceFile(path)保存PairRDD,系统将键和值能够自动转换为Writable类型。
对象文件
对象文件是序列化后保存的文件,采用Java的序列化机制。
通过 objectFile 接收一个路径,读取对象文件,返回对应的RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出,因为序列化所以要指定类型。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-85 Spark 集群 RDD创建 RDD-Action Key-Value RDD详解 RDD的文件输入输出

发表评论 取消回复