微软的语音合成服务(TTS)拥有500多种高品质的音色,并且在全球都有节点可以接入,在国内访问延迟可以控制在毫秒级。下面介绍在不需要编码的情况下,如何快速体验微软TTS的效果。
方式一、微软语音库UI界面
语音库地址:Speech Studio
条件:有微软开发账号
访问微软的语音库页面,在页面上选择需要体验的声音,然后输入对应文本,就能实时合成语音。
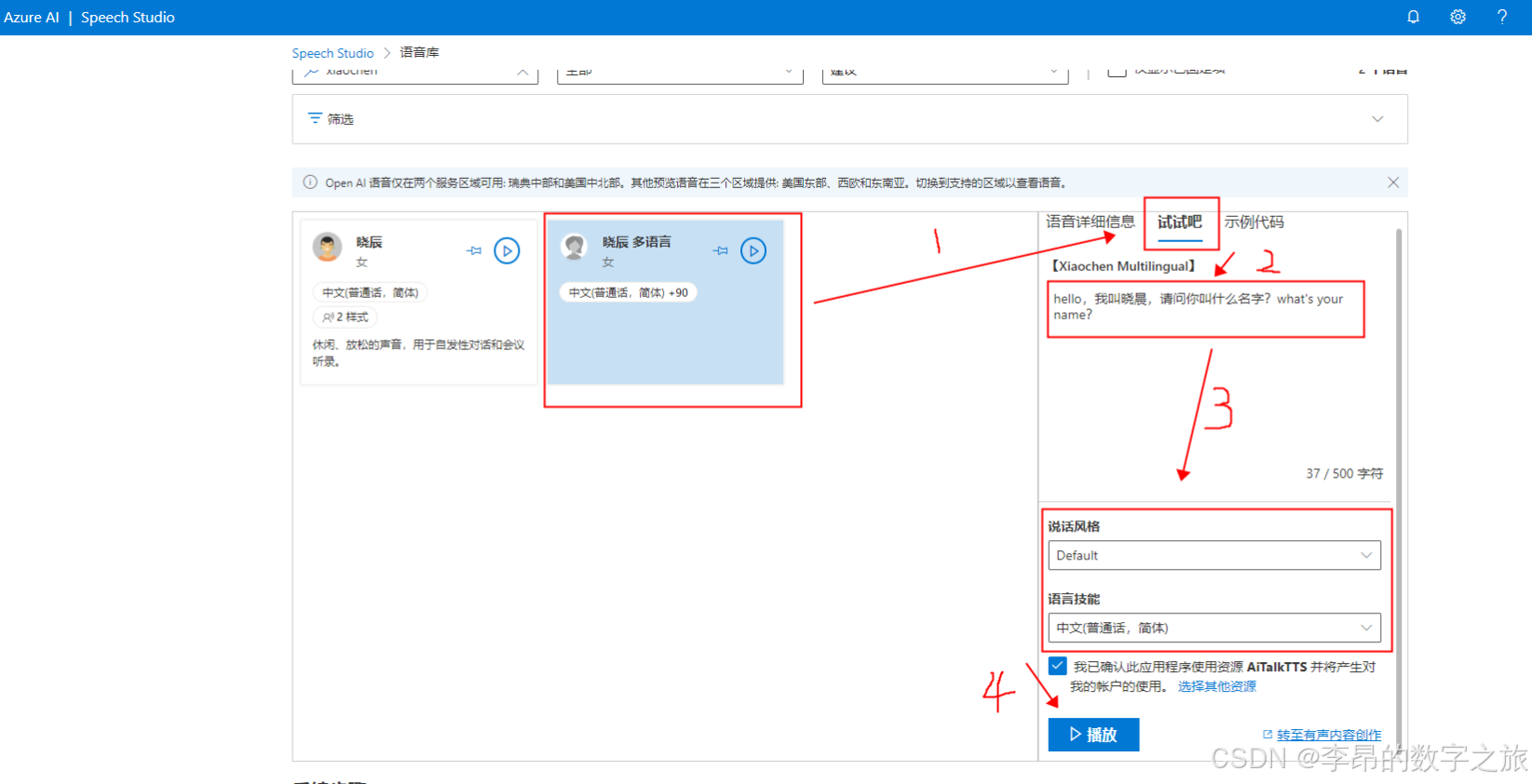
没有账号的话,可以听官方给的demo,效果可能会有差异。
方式二、REST API
TTS API:文本转语音 API 参考 (REST) - 语音服务 - Azure AI services | Microsoft Learn
条件:有语音服务的token
开发者有可能没有账号的权限,但是一定有sts的token,服务上线也需要这个token。
通过API获取音频需要分三步:
-
选取语音名称
-
获取TTS的访问token
-
调用语音合成接口
选取语音名称
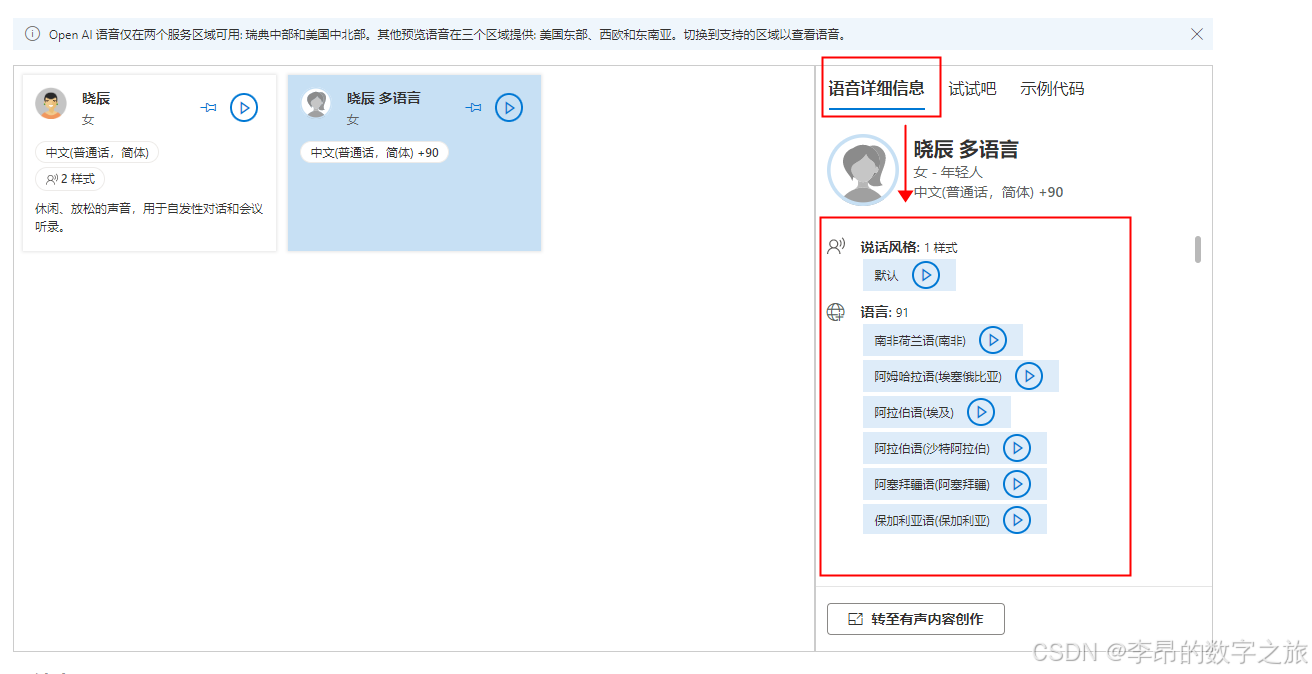
一般我们会先在语音库试听声音的demo,大致选定几个声音。然后在“示例代码”里找到:
config.SpeechSynthesisVoiceName = "zh-CN-XiaochenMultilingualNeural";"zh-CN-XiaochenMultilingualNeural"就是当前声音对应的名字。
另外,可以通过声音列表接口,获取全部支持的声音和可用的区域:
curl 'https://eastasia.tts.speech.microsoft.com/cognitiveservices/voices/list' --header 'Authorization: Bearer {accessToken}'
--- 返回值 ---
[
{
"Name": "Microsoft Server Speech Text to Speech Voice (af-ZA, AdriNeural)",
"DisplayName": "Adri",
"LocalName": "Adri",
"ShortName": "af-ZA-AdriNeural",
"Gender": "Female",
"Locale": "af-ZA",
"LocaleName": "Afrikaans (South Africa)",
"SampleRateHertz": "48000",
"VoiceType": "Neural",
"Status": "GA",
"WordsPerMinute": "147"
},
...
]请求头里的accessToken就是第二步获取到访问token。
获取访问token
获取访问token需要先拿到语音服务的apiKey,这个需要用微软账号在后台先创建出来。然后通过接口获取访问token:
curl -X POST 'https://eastasia.api.cognitive.microsoft.com/sts/v1.0/issueToken' --header 'Ocp-Apim-Subscription-Key: {apiKey}' -d ''调用语音合成接口
拿到访问token后,就能直接通过语音API /cognitiveservices/v1合成音频:
curl -X POST 'https://eastasia.tts.speech.microsoft.com/cognitiveservices/v1' \
-H 'Authorization: Bearer {accessToken}' \
-H 'X-Microsoft-OutputFormat: audio-24khz-48kbitrate-mono-mp3' \
-H 'User-Agent: TEST' \
-H 'Content-Type: application/ssml+xml' \
-d '<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="zh-CN-XiaochenMultilingualNeural">
hi there!How was your weekend?Did you do anything interesting?
</voice>
</speak>' --output test.mp3这里有几个注意点:
-
apiKey是和区域绑定,选择endpoint的时候要注意对应关系。区域和endpoint关系
-
X-Microsoft-OutputFormat决定合成音频的采样率和格式等信息,16khz效果较差,24khz和48kzh才有真人的感觉。音频输出格式
-
body里填的是SSML格式内容,voice标签可以指定声音名字。SSML介绍
方式三、通过SDK合成
SDK方式:文本转语音快速入门 - 语音服务 - Azure AI services | Microsoft Learn
条件:有语音服务的token
通过SDK合成原理是本地与TTS服务建立websocket连接,支持合成音频内容流式输出,并且增加了许多回调事件。
线上环境应该优先使用SDK合成方式,这种方式准备环境比较复杂,需要预安装一些插件,具体不展开介绍,可以查看官方文档。安装语音SDK
安装完环境后,调用方式如下:
SpeechConfig config = SpeechConfig.fromSubscription("{apiKey}", "{region}");
config.setSpeechSynthesisOutputFormat(SpeechSynthesisOutputFormat.Audio24Khz48KBitRateMonoMp3);
config.setSpeechSynthesisVoiceName("zh-CN-XiaochenMultilingualNeural");
SpeechSynthesizer speechSynthesizer = new SpeechSynthesizer(config, null);
SpeechSynthesisResult speechSynthesisResult = speechSynthesizer.SpeakSsml("""
<speak version="1.0" xmlns="https://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="zh-CN-XiaochenMultilingualNeural">
hi there!How was your weekend?Did you do anything interesting?
</voice>
</speak>
""");
System.out.println("音频的二进制内容:" + speechSynthesisResult.getAudioData());本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 快速体验微软TTS服务

发表评论 取消回复