引言
本文基于《Designing Data-Intensive Applications》一书(设计数据密集型应用,简称 DDIA),深入探讨了 Redis、Kafka 和 Elasticsearch 等常用组件的分区与复制机制。通过这些案例分析,我们可以更好地理解分布式系统的基本原理和实际应用。
DDIA 复制与分区
复制
复制机制主要由领导者(leader,又称为 master/primary)和追随者(follower,又称为 slave/replica)组成。
根据领导者的数量,复制可以分为以下几种形式:
- 单主复制:最常见的形式。
- 多主复制:常见于多数据中心、离线设备、协同编辑等场景。
- 无主复制:多受 Dynamo 系统启发。
根据复制时的确认机制,复制分为:
- 同步:客户端发起请求,主库和从库都完成变更后才响应。
- 异步:主库完成变更后立即响应,不等待从库。
- 半同步:一主多从,某些从库同步,其他从库异步。
复制的主要挑战在于复制延迟,客户端对从库读有可能读到落后的数据。
分区
分区(partition 或 shard 等)是指将大型数据集划分成若干小部分。
对 key-value 数据的分区方式包括:
- 范围分区:例如开头字母 A-F 为一组,G-N 为一组,其余字母为一组。
- 哈希分区(hash-based):通过哈希算法将 key 打散分布到不同的分区。
分区涉及到次级索引则会更复杂,常见方法有:
- 本地索引:也称为文档分区索引,每个分区只维护自己的次级索引。
- 全局索引:覆盖所有分区数据。
分区的常见问题有负载偏斜(数据分布不均衡)、热点、分区再平衡等。
常用组件分析
Redis
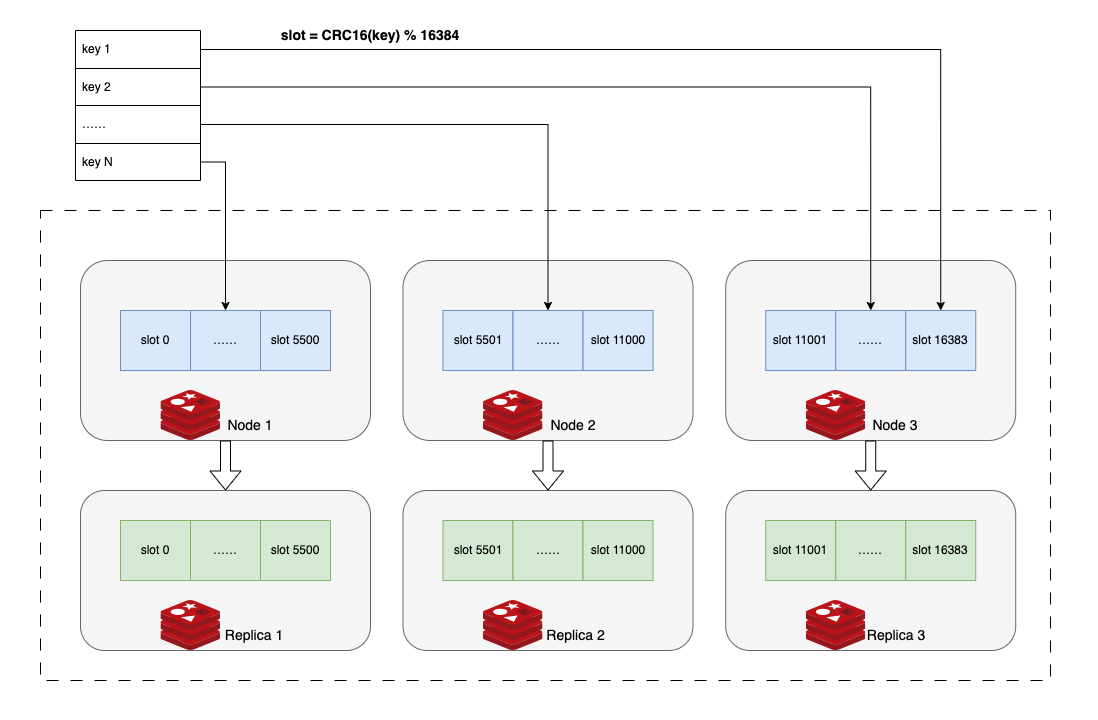
Redis 在集群模式下,总共划分了 2^14 = 16384 个 slot 数据槽,每个节点可以灵活分配多个 slot。数据被分配到哪个 slot 中,由对 key 进行 CRC16 计算后与 16384 取模决定。这是一种典型的 hash-based 算法。
取模运算最大的缺点就是除数(这里是数据槽的个数 16384)不能轻易改变,因为一旦改变则意味着同样的 key 可能会被分配到不同的槽中,由此会带来大量的数据迁移问题,因此 Redis 的 slot 数量被设计成了固定值。
至于分区再平衡的问题,当集群的节点数量发生改变时,Redis 本身并未提供 slot 自动调整的机制,需要用户手动调整或者使用一些第三方工具自动调整。
Redis 的复制提供了主从机制,以节点为单位,从节点同步主节点的数据,复制过程默认是异步的,可以设置多个从节点,并配置以下参数:
min-replicas-to-write:可以同步数据的最少从节点数,满足时才允许主节点进行写操作。min-replicas-max-lag:从节点允许的最大同步延迟(以秒为单位)。replica-read-only:从节点只读,即从节点也可以处理读请求,但是要注意数据延迟导致的一致性问题。
Kafka
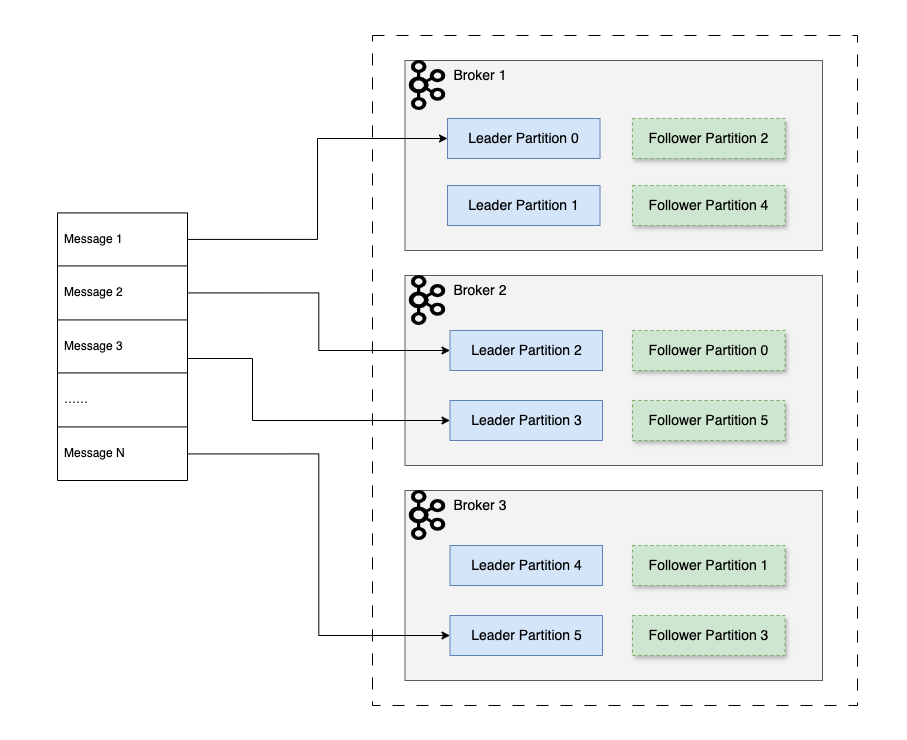
Kafka 中的节点叫 broker,分区叫 partition。分区的数量设置后只能增加不能减少。将消息分配到具体的分区的策略有:
- 默认轮询
- 基于消息进行 hash
- 自定义策略
复制以 partition 为单位,可以配置一主多从(多个副本),通过 replica.lag.time.max.ms 参数配置副本同步延迟的最大时间窗口,满足条件的副本统称为 ISR(In-Sync Replicas)。
数据写入受以下影响:
- 消息生产者
acks参数:- acks 为 0 :不等待 broker 的确认,这意味着消息可能投递不成功,一般不会使用。
- acks 为 1 :等待 leader partition 确认写入即可,不等待 follower 。
- acks 为 all 或者 -1 :必须等待 follower 确认。
min.insync.replicas参数:配合 acks=all 使用,确认写入的最少ISR副本数。
Kafka 的 follower partition(从分区)不提供消费能力,只用作冗余备份和故障切换。
Elasticsearch
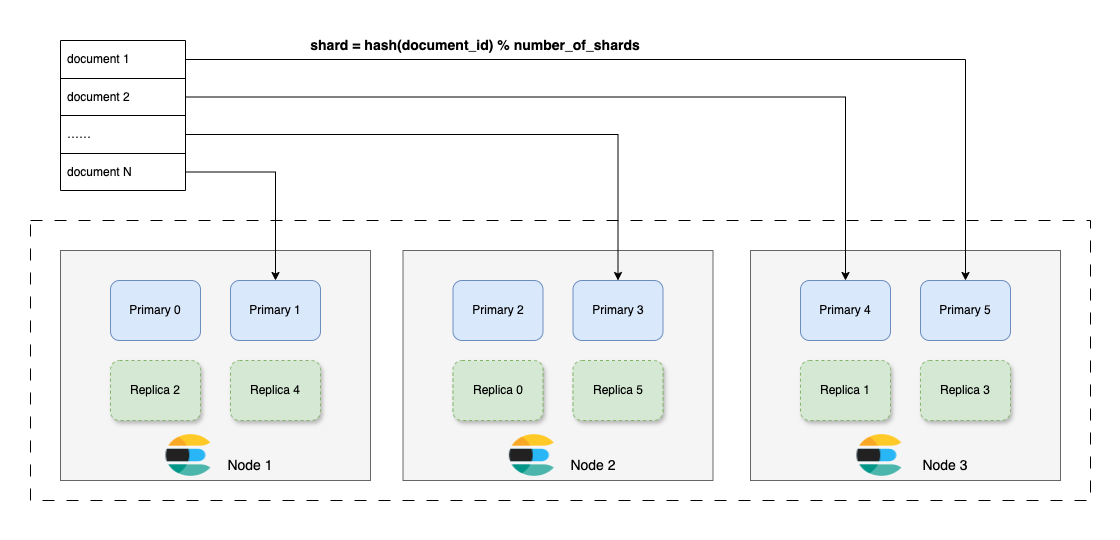
在 Elasticsearch 中,数据称为 document 文档,分片统称 shard,又细分为 primary shard 主分片和 replica shard 副本分片。
数据默认根据文档 id(也可以配置为文档中的其它值)取哈希,然后与主分片数取模,最后确认文档归属的分片。
只要看到取模运算,就知道分区数不能轻易扩展,没错,ES 里的主分片数是不能修改的。
复制以 shard 为单位,可以配置多个副本分片。副本分片与主分片的数据同步是异步的,可以通过 wait_for_active_shards 参数设置数据写入时需要确认的分片数。副本分片可以处理读请求。
倒排索引
ES 会对文档进行分词后构建倒排索引,此时就涉及到了 DDIA 中描述的分区与次级索引,前文提到有两种构建次级索引的方式:本地索引和全局索引。
ES 使用的是本地索引的方式,即每个 shard 分片内部构建自己的倒排索引。这就引发了另外的问题,当数据分布不均匀时,由于每个分片使用自身的而不是全局的 Term/Document 频率进行相关度打分,因此可能会造成打分偏差,从而影响最终搜索结果的相关性,这种情况就是默认的 search_type 为 query_then_fetch。而另一种搜索类型 dfs_query_then_fetch 则是先查询每个分片,汇总得到全局的 Term/Document 频率再进行打分,精确度是提高了,但是性能极差,一般也很少使用。
为了解决上述问题,大多会为了性能而容忍偏差,但是通过配置 routing 参数将同样的请求路由到同样的节点(保证同一个用户查询结果一致就行)。
总结
本文通过对 Redis、Kafka 和 Elasticsearch 三个常用组件的分析,展示了分布式系统中分区和复制机制的设计与实现。
可以看到哈希分区是常见的选择。基于性能和复杂度的权衡,单主异步复制往往是默认配置,但为了提供更高的数据一致性,这些组件也会提供多从复制确认的方案。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » DDIA 分布式数据的分区与复制 - 基于 Redis、Kafka、Elasticsearch 的深入分析

发表评论 取消回复