作者:后端小肥肠
在Neo4j系列我打算写一个Neo4j同步关系数据库、增删改查及展示的基础小系统,这篇文件先分享系统里面的基础工具类,感兴趣的可以点个关注,看了文章的jym有更好的方法可以分享在评论区。
创作不易,未经允许严谨转载。
基础篇:
目录
1. 前言
Neo4j作为领先的图数据库,在处理复杂关系数据时展现出了卓越的性能和灵活性。然而,在实际开发中,我们常常会遇到一些重复性的任务和常见的挑战。为了提高开发效率,减少不必要的麻烦,一个强大而实用的工具类往往能够事半功倍。
在接下来的内容中,我们将详细介绍这个工具类的具体代码及核心功能。让我们一起探索如何让Neo4j开发变得更加高效和轻松吧!
如果这篇文章对你有帮助,别忘记动动小手点点关注哦~
2. 与工具类适配的前端展示工具
2.1. neo4jd3.js 介绍
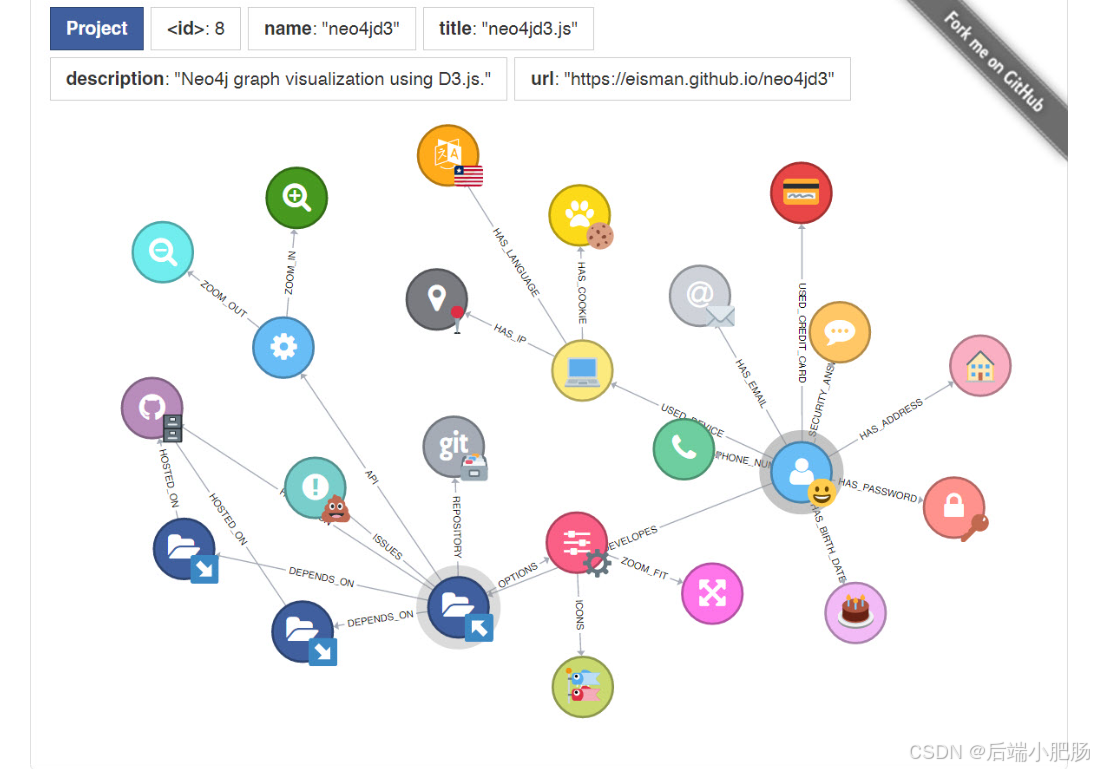
neo4jd3.js 是一个基于 JavaScript 的库(源码地址:https://github.com/eisman/neo4jd3),它使用 D3.js 技术来可视化 Neo4j 图数据库中的数据。这种工具特别适合需要在 Web 环境中展示图形数据的应用场景。其核心优势包括:
- 动态图形显示:用户可以看到图中的所有节点和边,并能通过拖拽和缩放来探索图中的元素。
- 高度自定义:支持自定义节点和边的颜色、大小、形状和标签,使得每个项目都能够根据其具体需求来调整视图。
- 交互性:提供点击节点查看详细信息,或是通过界面上的操作来进行图数据的动态查询和更新。
这些功能使得neo4jd3.js成为展示复杂关系和数据分析时的有力工具,帮助开发者和数据分析师更直观地理解和操作图数据库。
2.2. neo4jd3.js使用效果展示
下面是neo4jd3.js基础效果展示(无后端),先贴出html代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Force</title>
<style>
.nodetext {
font-size: 12px;
font-family: SimSun;
fill: #000000;
}
.linetext {
fill: #1f77b4;
fill-opacity: 0.0;
}
.circleImg {
stroke: #ff7f0e;
stroke-width: 1.5px;
}
</style>
</head>
<body>
<h1>小肥肠知识图谱示例</h1>
<script src="http://d3js.org/d3.v3.min.js" charset="utf-8"></script>
<script src="https://code.jquery.com/jquery-3.2.1.min.js"></script>
<script>
var width = 900;
var height = 800;
var img_w = 77;
var img_h = 80;
var radius = 30; //圆形半径
var svg = d3.select("body")
.append("svg")
.attr("width", width)
.attr("height", height);
var edges = [];
d3.json("xfc.json", function(error, root) {
if (error) {
return console.log(error);
}
console.log(root);
root.edges.forEach(function(e) {
var sourceNode = root.nodes.filter(function(n) {
return n.id === e.source;
})[0],
targetNode = root.nodes.filter(function(n) {
return n.id === e.target;
})[0];
edges.push({
source: sourceNode,
target: targetNode,
relation: e.type
});
});
console.log(edges);
var force = d3.layout.force()
.nodes(root.nodes)
.links(edges)
.size([width, height])
.linkDistance(200)
.charge(-1500)
.start();
var defs = svg.append("defs");
var arrowMarker = defs.append("marker")
.attr("id", "arrow")
.attr("markerUnits", "strokeWidth")
.attr("markerWidth", "15")
.attr("markerHeight", "15")
.attr("viewBox", "0 0 12 12")
.attr("refX", "17")
.attr("refY", "6")
.attr("orient", "auto");
var arrow_path = "M2,2 L10,6 L2,10 L6,6 L2,2";
arrowMarker.append("path")
.attr("d", arrow_path)
.attr("fill", "#ccc");
var edges_line = svg.selectAll("line")
.data(edges)
.enter()
.append("line")
.attr("class", "line")
.style("stroke", "#ddd")
.style("stroke-width", 3)
.attr("marker-end", "url(#arrow)");
var edges_text = svg.selectAll(".linetext")
.data(edges)
.enter()
.append("text")
.attr("class", "linetext")
.text(function(d) {
return d.relation;
})
.style("fill-opacity", 1.0);
var nodes_img = svg.selectAll("image")
.data(root.nodes)
.enter()
.append("circle")
.attr("class", "circleImg")
.attr("r", radius)
.attr("fill", function(d, i) {
var defs = svg.append("defs").attr("id", "imgdefs");
var catpattern = defs.append("pattern")
.attr("id", "catpattern" + i)
.attr("height", 1)
.attr("width", 1);
catpattern.append("image")
.attr("x", -(img_w / 2 - radius))
.attr("y", -(img_h / 2 - radius))
.attr("width", img_w)
.attr("height", img_h)
.attr("xlink:href", d.labels);
return "url(#catpattern" + i + ")";
})
.call(force.drag);
var text_dx = -20;
var text_dy = 20;
var nodes_text = svg.selectAll(".nodetext")
.data(root.nodes)
.enter()
.append("text")
.attr("class", "nodetext")
.attr("dx", text_dx)
.attr("dy", text_dy)
.text(function(d) {
var uservalue = d.properties.username || "";
var personvalue = d.properties.person || "";
var phonevalue = d.properties.phone || "";
return uservalue + phonevalue + personvalue;
});
force.on("tick", function() {
root.nodes.forEach(function(d) {
d.x = d.x - img_w / 2 < 0 ? img_w / 2 : d.x;
d.x = d.x + img_w / 2 > width ? width - img_w / 2 : d.x;
d.y = d.y - img_h / 2 < 0 ? img_h / 2 : d.y;
d.y = d.y + img_h / 2 + text_dy > height ? height - img_h / 2 - text_dy : d.y;
});
edges_line.attr("x1", function(d) { return d.source.x; });
edges_line.attr("y1", function(d) { return d.source.y; });
edges_line.attr("x2", function(d) { return d.target.x; });
edges_line.attr("y2", function(d) { return d.target.y; });
edges_text.attr("x", function(d) { return (d.source.x + d.target.x) / 2; });
edges_text.attr("y", function(d) { return (d.source.y + d.target.y) / 2; });
nodes_img.attr("cx", function(d) { return d.x; });
nodes_img.attr("cy", function(d) { return d.y; });
nodes_text.attr("x", function(d) { return d.x; });
nodes_text.attr("y", function(d) { return d.y + img_w / 2; });
});
});
</script>
</body>
</html>
通过上述代码,用户可以在网页上看到一个动态的知识图谱,节点以图像的形式展示,节点之间的关系通过带箭头的线条表示,并且每条线上显示关系类型。用户可以通过拖动节点来重新排列图谱,从而更直观地理解数据之间的关联性。
xfc.json文件:
{
"nodes": [
{
"id": "2",
"labels": "./image/kn.png",
"properties": {
"person": "康娜1号"
}
},
{
"id": "58688",
"labels": "./image/kn2.png",
"properties": {
"person": "康娜2号"
}
},
{
"id": "128386",
"labels": "./image/kn3.png",
"properties": {
"person": "小肥肠"
}
},
{
"id": "200000",
"labels": "./image/kn4.png",
"properties": {
"person": "人物4号"
}
},
{
"id": "300000",
"labels": "./image/kn5.png",
"properties": {
"person": "人物5号"
}
},
{
"id": "400000",
"labels": "./image/kn6.png",
"properties": {
"person": "人物6号"
}
},
{
"id": "500000",
"labels": "./image/kn7.png",
"properties": {
"person": "人物7号"
}
},
{
"id": "600000",
"labels": "./image/kn8.png",
"properties": {
"person": "人物8号"
}
}
],
"edges": [
{
"id": "23943",
"type": "know",
"source": "2",
"target": "58688",
"properties": {}
},
{
"id": "94198",
"type": "know",
"source": "58688",
"target": "128386",
"properties": {}
},
{
"id": "1000000",
"type": "know",
"source": "128386",
"target": "200000",
"properties": {}
},
{
"id": "1100000",
"type": "know",
"source": "200000",
"target": "300000",
"properties": {}
},
{
"id": "1200000",
"type": "know",
"source": "300000",
"target": "400000",
"properties": {}
},
{
"id": "1300000",
"type": "know",
"source": "400000",
"target": "500000",
"properties": {}
},
{
"id": "1400000",
"type": "know",
"source": "500000",
"target": "600000",
"properties": {}
}
]
}
效果展示:
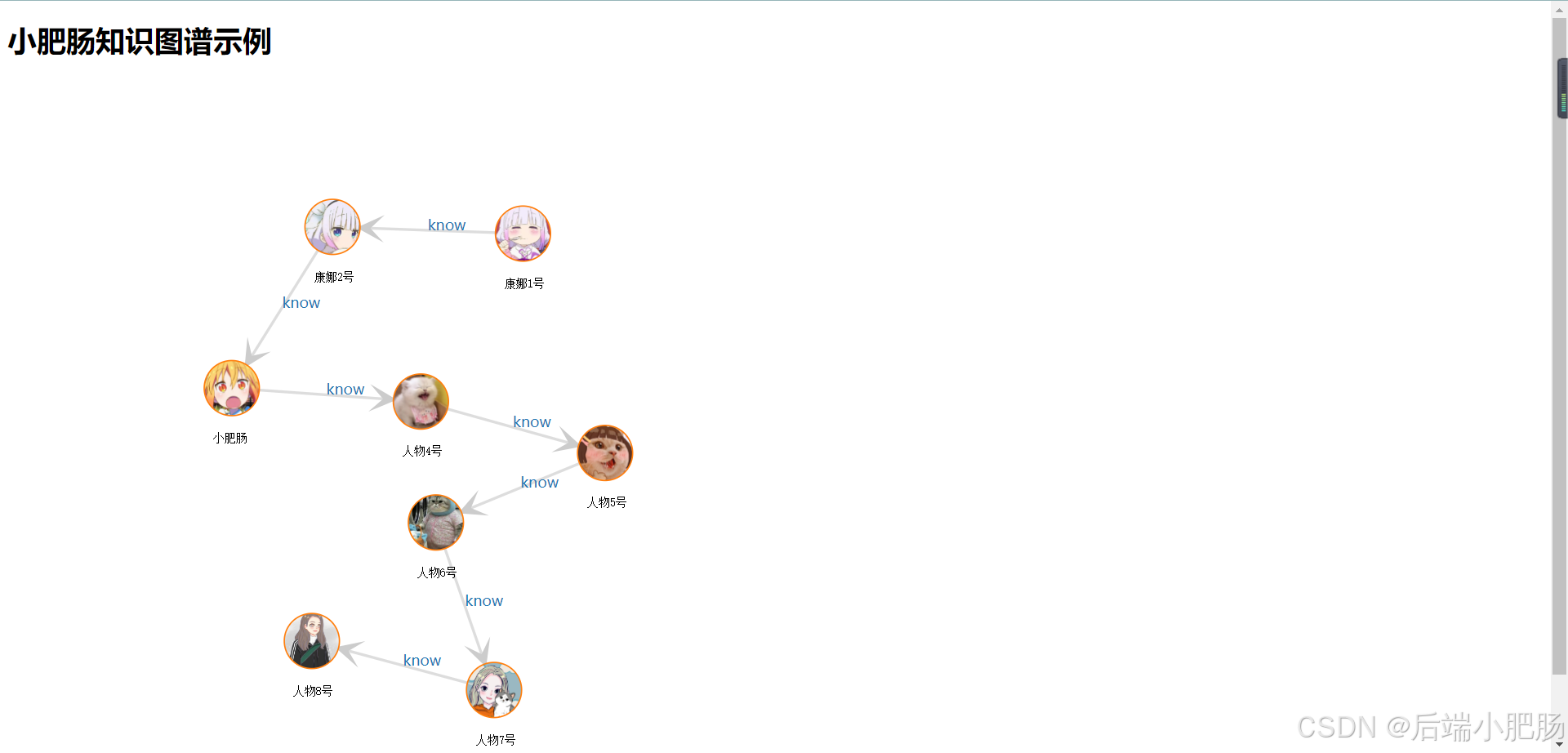
效果还是不错的吧,请忽略我这个略丑的demo界面,之后的系统肯定会呈现一个完美的功能界面的,现在只是给大家打个样。
3. Neo4j工具类包含功能简介
工具类的构建参考了github上的一个项目(https://github.com/MiracleTanC/Neo4j-KGBuilder),我在他的基础上做了稍微的修改,工具类包含返回节点集合、获取所有标签、获取数据库索引、删除索引、创建索引、返回关系、返回节点和关系、返回单个节点的信息等(后续文章会放出全部代码)。
ps:我的工具类是要适配前端的neo4jd3.js,所以工具类里面有数据格式的部分都是对应neo4jd3.js所要求的格式。
3.1. 编写 GraphDTO
@Data
@AllArgsConstructor
@NoArgsConstructor
public class GraphDTO {
private List<GraphNodeDTO>nodes;
private List<GraphLinkDTO>edges;
}3.2. 编写GraphNodeDTO
@Data
@AllArgsConstructor
@NoArgsConstructor
public class GraphNodeDTO {
private String id;
private String labels;
private HashMap<String,Object> properties;
}3.3. 编写GraphLinkDTO
@Data
@AllArgsConstructor
@NoArgsConstructor
public class GraphLinkDTO {
private String id;
private String type;
private String source;
private String target;
private HashMap<String,Object> properties;
}3.4. 节点
3.4.1. 获取节点集合(无关系)
public static List<GraphNodeDTO> getGraphNode(String cypherSql) {
log.debug("Executing Cypher query: {}", cypherSql);
try (Session session = neo4jDriver.session(SessionConfig.builder().withDefaultAccessMode(AccessMode.WRITE).build())) {
return session.writeTransaction(tx -> {
Result result = tx.run(cypherSql);
return result.list().stream()
.flatMap(record -> record.fields().stream())
.filter(pair -> pair.value().type().name().equals("NODE"))
.map(pair -> {
Node node = pair.value().asNode();
// label为节点对应图片
String label = "";
HashMap<String, Object> properties = new HashMap<>(node.asMap());
return new GraphNodeDTO(String.valueOf(node.id()), label, properties);
})
.collect(Collectors.toList());
});
} catch (Exception e) {
log.error("Error executing Cypher query: {}", cypherSql, e);
return new ArrayList<>();
}
}这段代码定义了一个名为 getGraphNode 的Java方法,它用于执行一个Neo4j Cypher查询来获取节点,并将结果封装为 GraphNodeDTO 对象的列表。该方法首先设置会话为写入模式,确保能执行可能涉及写入的查询。使用 session.writeTransaction 确保查询在事务中执行,这有助于处理可能的并发修改和保证数据一致性。
3.4.2. 获取单个节点
public static GraphNodeDTO getSingleGraphNode(String cypherSql) {
List<GraphNodeDTO> nodes = getGraphNode(cypherSql);
if(CollectionUtils.isNotEmpty(nodes)){
return nodes.get(0);
}
return null;
} getSingleGraphNode 方法从数据库中执行指定的 Cypher 查询,获取查询结果中的第一个图谱节点。如果结果列表不为空,它会返回第一个节点;如果列表为空,则返回 null。这个方法简单明了,旨在快速获取一个节点或确认没有结果。
3.4.3. 获取所有节点(包含关系)
public static GraphDTO getGraphNodeAndShip(String cypherSql) {
log.debug("Executing Cypher query: {}", cypherSql);
GraphDTO graphDTO = new GraphDTO();
try (Session session = neo4jDriver.session(SessionConfig.builder().withDefaultAccessMode(AccessMode.WRITE).build())) {
return session.writeTransaction(tx -> {
Result result = tx.run(cypherSql);
List<GraphNodeDTO> nodes = new ArrayList<>();
List<GraphLinkDTO> relationships = new ArrayList<>();
HashSet<String> uuids = new HashSet<>();
result.list().stream().flatMap(record -> record.fields().stream()).forEach(pair -> {
String type = pair.value().type().name();
if ("NODE".equals(type)) {
Node node = pair.value().asNode();
String uuid = String.valueOf(node.id());
if (uuids.add(uuid)) {
HashMap<String, Object> properties = new HashMap<>(node.asMap());
nodes.add(new GraphNodeDTO(uuid, node.labels().iterator().next(), properties));
}
} else if ("RELATIONSHIP".equals(type)) {
Relationship relationship = pair.value().asRelationship();
HashMap<String, Object> properties = new HashMap<>(relationship.asMap());
relationships.add(new GraphLinkDTO(String.valueOf(relationship.id()), relationship.type(),
String.valueOf(relationship.startNodeId()),
String.valueOf(relationship.endNodeId()),
properties));
}
});
graphDTO.setNodes(nodes);
graphDTO.setEdges(toDistinctList(relationships));
return graphDTO;
});
} catch (Exception e) {
log.error("Error executing Cypher query: {}", cypherSql, e);
return new GraphDTO();
}
}这段代码定义了一个名为 getGraphNodeAndShip 的Java方法,用于在Neo4j数据库中执行Cypher查询,从而获取并处理节点和关系数据,将结果封装成 GraphDTO 对象。它使用了写入事务来确保操作的稳定性,并在出现异常时进行了错误记录,最终返回一个包含节点和关系的复合数据对象。
3.5. 获取所有标签
public static List<HashMap<String, Object>> getGraphLabels() {
String cypherSql = "CALL db.labels()";
log.debug("Executing Cypher query: {}", cypherSql);
try (Session session = neo4jDriver.session()) {
return session.readTransaction(tx -> {
Result result = tx.run(cypherSql);
return result.list().stream()
.map(record -> {
HashMap<String, Object> labelInfo = new HashMap<>();
record.fields().forEach(pair -> {
String key = pair.key();
Value value = pair.value();
if (key.equalsIgnoreCase("label")) {
String label = value.asString().replace("\"", "");
labelInfo.put(key, label);
} else {
labelInfo.put(key, value.asObject());
}
});
return labelInfo;
})
.collect(Collectors.toList());
});
} catch (Exception e) {
log.error("Error executing Cypher query for graph labels", e);
return new ArrayList<>();
}
}这段代码用于从 Neo4j 数据库中检索所有图谱标签。它执行 CALL db.labels() 查询,并将结果转换为 List<HashMap<String, Object>> 格式。每个标签信息以 HashMap 的形式存储,其中包含标签的键和值。如果查询过程中发生异常,代码会记录错误并返回一个空列表。
3.6. 数据库索引
3.6.1. 获取数据库索引
public static List<HashMap<String, Object>> getGraphIndex() {
String cypherSql = "CALL db.indexes()";
log.debug("Executing Cypher query: {}", cypherSql);
try (Session session = neo4jDriver.session()) {
return session.readTransaction(tx -> {
Result result = tx.run(cypherSql);
return result.list().stream()
.map(record -> {
HashMap<String, Object> indexInfo = new HashMap<>();
record.fields().forEach(pair -> {
String key = pair.key();
Value value = pair.value();
if (key.equalsIgnoreCase("labelsOrTypes")) {
String objects = value.asList().stream()
.map(Object::toString)
.collect(Collectors.joining(","));
indexInfo.put(key, objects);
} else {
indexInfo.put(key, value.asObject());
}
});
return indexInfo;
})
.collect(Collectors.toList());
});
} catch (Exception e) {
log.error("Error executing Cypher query for index information", e);
return new ArrayList<>();
}
}这个方法执行 Cypher 查询 CALL db.indexes() 来获取数据库索引信息。它记录查询语句,然后在 Neo4j 会话中执行查询并处理结果。对于每个索引信息记录,方法将其字段转换为 HashMap,特别处理 labelsOrTypes 字段,将其值转换为逗号分隔的字符串。最终,它将所有索引的 HashMap 收集到一个列表中并返回。如果出现异常,则记录错误并返回一个空列表。
3.6.2. 创建 | 删除数据库索引
/**
* 删除索引
* @param label
*/
public static void deleteIndex(String label) {
try (Session session = neo4jDriver.session()) {
String cypherSql=String.format("DROP INDEX ON :`%s`(name)",label);
session.run(cypherSql);
} catch (Exception e) {
log.error(e.getMessage());
}
}
/**
* 创建索引
* @param label
* @param prop
*/
public static void createIndex(String label,String prop) {
try (Session session = neo4jDriver.session()) {
String cypherSql=String.format("CREATE INDEX ON :`%s`(%s)",label,prop);
session.run(cypherSql);
} catch (Exception e) {
log.error(e.getMessage());
}
}这段代码包含两个方法,deleteIndex 和 createIndex,分别用于在 Neo4j 数据库中删除和创建索引。deleteIndex 方法根据提供的标签删除该标签上的 name 索引,而 createIndex 方法在指定标签的指定属性上创建一个新索引。两者都使用 Neo4j 的 Cypher 查询语句执行操作,并在发生异常时记录错误信息。
3.7. 获取所有关系
public static List<GraphLinkDTO> getGraphRelationship(String cypherSql) {
log.debug("Executing Cypher query: {}", cypherSql);
try (Session session = neo4jDriver.session(SessionConfig.builder().withDefaultAccessMode(AccessMode.WRITE).build())) {
return session.writeTransaction(tx -> {
Result result = tx.run(cypherSql);
return result.list().stream()
.flatMap(record -> record.fields().stream())
.filter(pair -> pair.value().type().name().equals("RELATIONSHIP"))
.map(pair -> {
Relationship relationship = pair.value().asRelationship();
String id = String.valueOf(relationship.id());
String source = String.valueOf(relationship.startNodeId());
String target = String.valueOf(relationship.endNodeId());
HashMap<String, Object> properties = new HashMap<>(relationship.asMap());
return new GraphLinkDTO(id, relationship.type(), source, target, properties);
})
.collect(Collectors.toList());
});
} catch (Exception e) {
log.error("Error executing Cypher query: {}", cypherSql, e);
return new ArrayList<>();
}
}
这段代码定义了一个名为 getGraphRelationship 的方法,它执行一个Neo4j Cypher查询以获取关系数据,并将每个关系转换为 GraphLinkDTO 对象。方法在写入事务中执行查询,确保稳定性,并使用流处理来提取和封装关系的详细信息,包括ID、类型、起始节点、目标节点和属性。如果查询执行过程中发生异常,会记录错误并返回一个空列表
4. 工具类使用实战
4.1. 新增节点
参数:

代码:
public GraphDTO createNode(AddNodeDTO addNodeDTO) {
GraphDTO dataGraphDTO = new GraphDTO();
String cypherSql = String.format("n.name='%s'", addNodeDTO.getProperties().get("name"));
String buildNodeql = "";
buildNodeql = String.format("create (n:`%s`) set %s return n", addNodeDTO.getDomain(), cypherSql);
List<GraphNodeDTO> nodes = Neo4jUtil.getGraphNode(buildNodeql);
dataGraphDTO.setNodes(nodes);
return dataGraphDTO;
}4.2. 新增关系
参数:

代码:
public GraphDTO createLink(AddLinkDTO addLinkDTO) {
String cypherSql = String.format("MATCH (n:`%s`),(m:`%s`) WHERE id(n)=%s AND id(m) = %s "
+ "CREATE (n)-[r:%s]->(m)" + "RETURN n,m,r", addLinkDTO.getDomain(), addLinkDTO.getDomain(), addLinkDTO.getSource(), addLinkDTO.getTarget(), addLinkDTO.getType());
return Neo4jUtil.getGraphNodeAndShip(cypherSql);
}4.3. 展示所有节点(包含关系)
public GraphDTO getGraph(String domain) {
GraphDTO graphDTO = new GraphDTO();
if (!StringUtil.isBlank(domain)) {
String nodeSql = String.format("MATCH (n:`%s`) RETURN distinct(n) ", domain);
List<GraphNodeDTO> graphNode = Neo4jUtil.getGraphNode(nodeSql);
graphDTO.setNodes(graphNode);
String relationShipSql = String.format("MATCH (n:`%s`)<-[r]-> (m) RETURN distinct(r) ", domain);// m是否加领域
List<GraphLinkDTO> graphRelation = Neo4jUtil.getGraphRelationship(relationShipSql);
graphDTO.setEdges(graphRelation);
}效果图: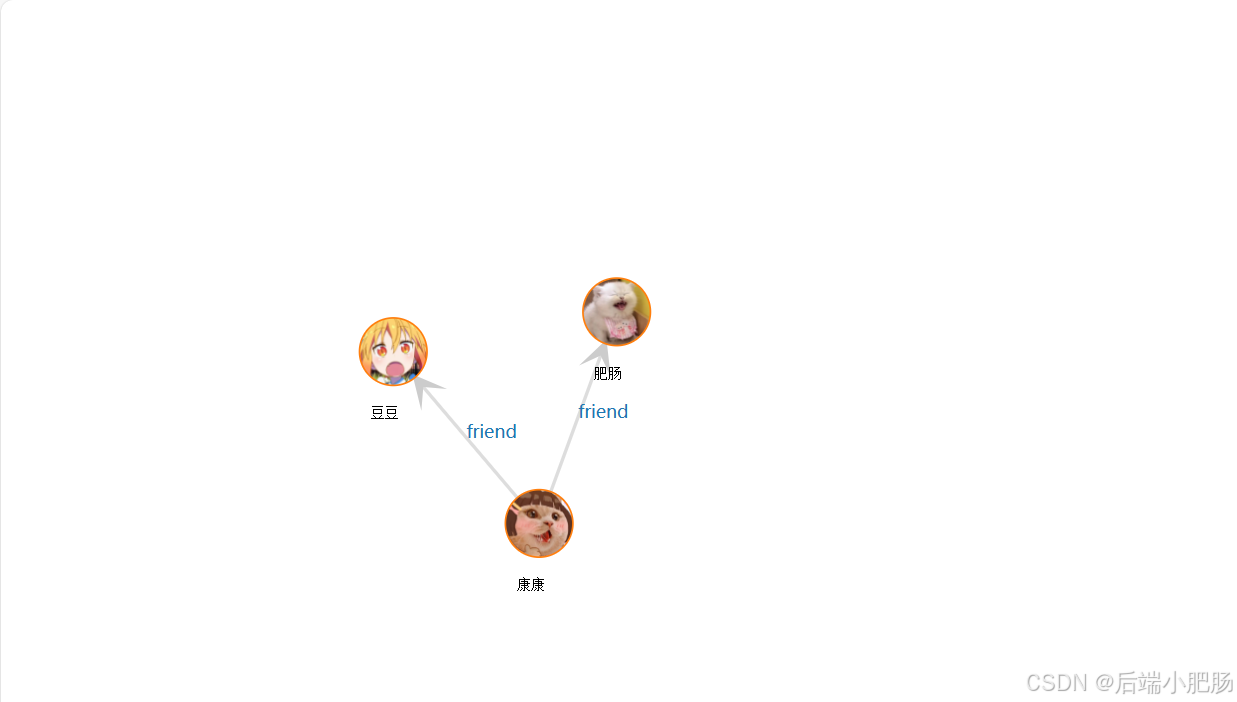
5. 结语
在本文中介绍了面向neo4jd3.js的后端neo4j工具类。本工具不仅简化了图数据库的操作,还通过GraphDTO, GraphNodeDTO, 和 GraphLinkDTO等类,有效地封装和传输图数据。同时演示了如何使用这些工具执行常见的图操作,包括新增节点和关系,以及展示关系数据,下一章节将介绍如何在实际场景中实现neo4j与关系数据库实现数据同步,感兴趣的话可动动小手点点关注~

6. 参考链接
基于d3.js/neovis.js/neod3.js实现链接neo4j图形数据库的图像化显示功能_javascript技巧_脚本之家
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Neo4j系列】简化Neo4j数据库操作:一个基础工具类的开发之旅

发表评论 取消回复