一、进度概述
1、机器学习常识23-24,以及相关代码复现
2、python 补完计划(详见 python 专题)
二、详情
23、U-Net
从宏观结构上来讲(以下摘自常识23):
U-Net 就是 U 形状的网络, 前半部分 (左边) 进行编码, 后半部分 (右边) 进行解码.
- 编码部分, 将一个图像经过特征提取, 变成一个向量. 前面说过: 深度学习本质上只做件事情, 就是特征提取.
- 解码部分, 将压缩表示解压, 又变成矩阵.
- 从思想上, 压缩与解压, 这与矩阵分解有几分类似, 都是把数据进行某种形式的压缩表示. 把图片压缩成向量 (而不是两个子矩阵), 想想都可怕.
在之前的学习中,我们其实已经对机器学习中的一些基本操作(如采样,卷积,池化)有了一定了解。这个时候再来看 U-Net,就显得有迹可循了。
关于 U-Net 的细致讲解,这个博客写的十分好:从零开始的U-net入门_u net-CSDN博客
同时,在文末给出的项目,自己过一遍还是挺有意义的。
此外,这里还给出两个代码实例,跑出来也是很不错的:
医学图像分割模型:U-Net详解及实战_u-net模型-CSDN博客
U-Net详解-CSDN博客
对于 U-Net 的结构理解,个人理解如下:
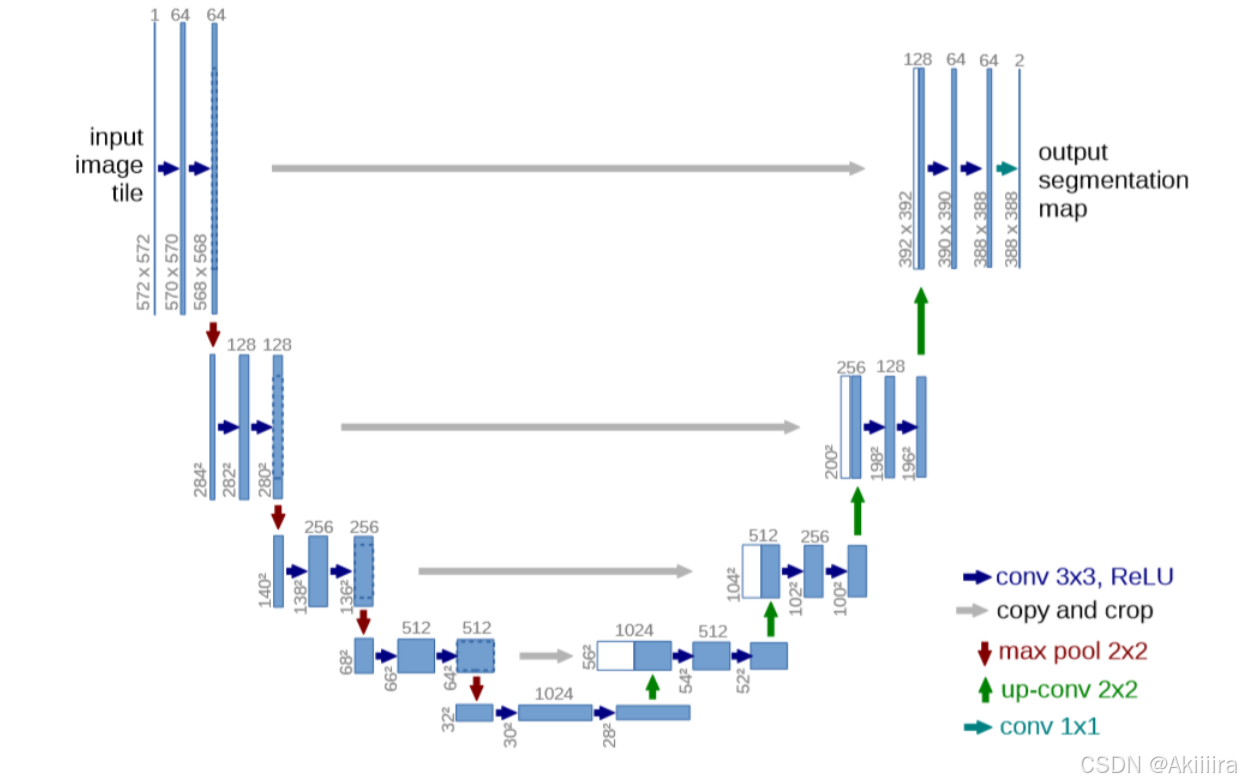
从最左边开始,输入的是一张572×572×1的图片,然后经过64个3×3的卷积核进行卷积,再通过ReLU函数后得到64个570×570×1的特征通道。然后把这570×570×64的结果再经过64个3×3的卷积核进行卷积,同样通过ReLU函数后得到64个568×568×1的特征提取结果,这就是第一层的处理结果。
第一层的处理结果是568×568×64的特征图片,通过2×2的池化核,对图片下采样为原来大小的一半:284×284×64,然后通过128个卷积核进一步提取图片特征。后面的下采样过程也是以此类推,每一层都会经过两次卷积来提取图像特征;每下采样一层,都会把图片减小一半,卷积核数目增加一倍。最终下采样部分的结果是28×28×1024,也就是一共有1024个特征层,每一层的特征大小为28×28。
右边部分从下往上则是4次上采样过程。从最右下角开始,把28×28×1024的特征矩阵经过512个2×2的卷积核进行反卷积,把矩阵扩大为56×56×512(注意不是1024个卷积核,结果仅仅是右半边蓝色部分的512个特征通道,不包含左边白色的),由于反卷积只能扩大图片而不能还原图片,为了减少数据丢失,采取把左边降采样时的图片裁剪成相同大小后直接拼过来的方法增加特征层(这里才是左半边白色部分的512个特征通道),再进行卷积来提取特征。由于每一次valid卷积都会使得结果变小一圈,因此每次拼接之前都需要先把左边下采样过程中的图片进行裁剪。矩阵进行拼接后,整个新的特征矩阵就变成56×56×1024,然后经过512个卷积核,进行两次卷积后得到52×52×512的特征矩阵,再一次进行上采样,重复上述过程。每一层都会进行两次卷积来提取特征,每上采样一层,都会把图片扩大一倍,卷积核数目减少一半。最后上采样的结果是388×388×64,也就是一共有64个特征层,每一层的特征大小为388×388。
在最后一步中,选择了2个1×1的卷积核把64个特征通道变成2个,也就是最后的388×388×2,其实这里就是一个二分类的操作,把图片分成背景和目标两个类别。
从整体上来讲,U-Net 的下采样过程,就是一个模糊化过程,信息越来越精华,越来越不像原图;而上采样,则是闭上眼睛脑补(通过下采样给出的特征,反向脑补原图);同时,为了防止只由 “浓缩精华” 特征去做任务导致绝对信息丢失,便引入了中间的灰色箭头,即通过直接拼接的方法来增加特征层。
如果原始图片是多个通道(如 RGB,对应 3 通道),那么中间层和输出层也就变为对应的多通道。
U-Net 可以应用于很多任务:
- 自编码器. 直接将输入数据作为标签, 看编码导致的损失 (更像矩阵分解了).
- 从一种风格转换为另一种风格. 如将自然照片转换成卡通风格, 将地震数据转换成速度模型 (2010年如果你这么做会被业内人士笑话的).
- 图像分割, 或提取图片的边缘. 嗯, 这个和转成卡通风格也差不多.
- 机器翻译. 把句子编码成机器内部的表示 (一种新的世界语言?), 然后转成其它语言的句子.
- 输入一个头, 输出多个头, 就可以做多任务. 如在速度模型反演的同时, 进行边缘提取, 这样导致反演的结果更丝滑.
24、自注意力机制
以下列举一些讲的十分好的博客:
知识讲解:
自注意力机制(Self-Attention)-CSDN博客
一文搞定自注意力机制(Self-Attention)-CSDN博客
Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结_注意力机制和自注意力机制-CSDN博客
【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解-CSDN博客
Attention 机制超详细讲解(附代码) - 知乎 (zhihu.com)
实战参考:
PyTorch——实现自注意力机制(self-attention)_pytorch self attention-CSDN博客
自注意力机制的启示,在常识中给了一个十分妙的例子:
研表究明, 汉字的序顺并不定一能影阅响读, 比如当你看完这句话后, 才发这现里的字全都是乱的.
从这个例子表明, 人类在阅读句子的时候, 并不是逐个字地阅读, 而是扫描一遍, 抓住重点. 换言之, 做机器翻译时, RNN, LSTM 重点考虑单词的前后关系, 这并不一定是必要的.
再来从机器学习的角度看看自注意力机制引入的目的,细细品味,其中还是有相似之处的:
神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译问题(序列到序列的问题,机器自己决定多少个标签),词性标注问题(一个向量对应一个标签),语义分析问题(多个向量对应一个标签)等文字处理问题。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
更细节的原理及代码,参考上面给出的博客,讲的都十分清晰明了,各个互补起来能够形成一个比较不错的认识。
后记
机器学习过了一遍很粗的学习,后续呢准备在实战中逐渐完善知识体系的构筑。
需要注意的是,现阶段还需要对 python 再过一遍,有点久没用了。
同时,在过完这一遍机器学习后,需要对 inversionnet 再做一遍整理分析,尽可能搞懂其中原理上的分析。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【学习笔记】Day 22

发表评论 取消回复