随机森林
随机森林(Random Forest)是一种集成学习方法,属于决策树模型的扩展。它通过构建多个决策树并将它们的预测结果进行汇总,以此来提高预测的准确性和稳定性。随机森林是“集成学习”中最流行的算法之一,尤其在分类和回归任务中表现出色。
基本原理
随机森林的构建基于两个主要原则:Bagging(Bootstrap Aggregating)和随机特征选择。
我们主要了解一下Bagging原则:
Bagging:随机森林通过从原始数据集中有放回地随机抽取样本(称为bootstrap样本)来构建多棵决策树。每个决策树都是在这样的随机样本上训练的,因此不同的树可能使用到不同的数据点。这样做可以增加模型的多样性,因为每棵树都是在不同的数据子集上训练的。
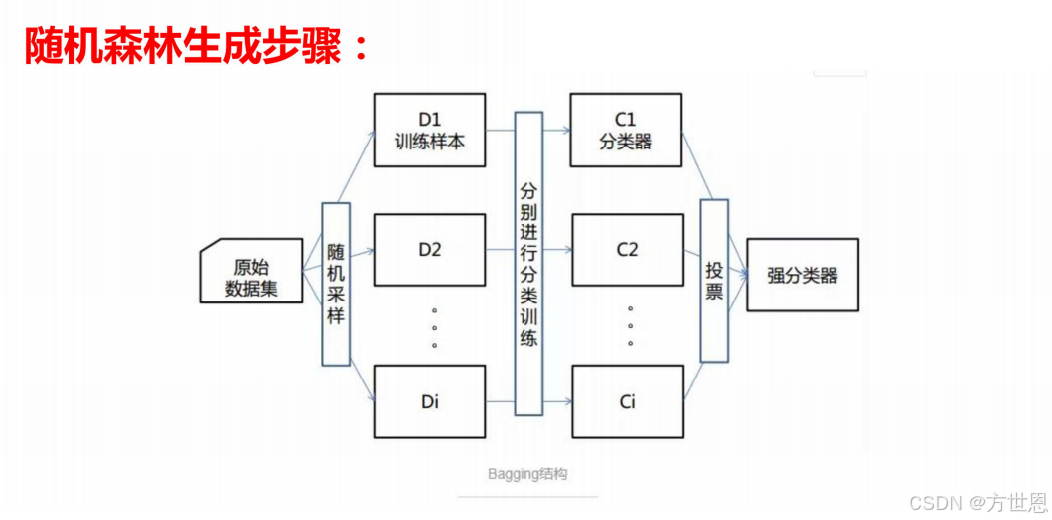
随机森林特点
优点
- 准确性高:由于结合了多个决策树的预测结果,随机森林通常能提供比单一决策树更高的预测准确性。
- 能够处理高维数据:随机特征选择机制使得随机森林能够有效地处理包含大量特征的数据集。
- 能够评估特征的重要性:通过计算每个特征在构建所有树时产生的平均信息增益或平均不纯度减少量,可以评估出各个特征的重要性。
- 不易过拟合:由于随机性和多样性,随机森林模型通常对训练数据的噪声和异常值具有较好的鲁棒性,不太容易过拟合。
缺点
- 复杂:当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大。
- 随机森林模型还有许多不好解释的地方,有点算个黑盒模型
构建模型
对于构建一个完整的模型,主要从以下两个方面进行:
- 训练模型
- 测试模型
但是对于随机森林算法,随机森林作为一种强大的集成学习算法,通过构建多个决策树并将它们的结果进行汇总,以提高模型的预测准确性和泛化能力。在这个过程中,理解哪些特征对模型的预测结果具有重要影响是至关重要的,所以知道特征的影响权重是很重要的,于是我们需要在上面两步的基础上,再加一步:
- 绘制重要特征:便于进行特征工程,去除无关特征
模型参数
class sklearn.ensemble.RandomForestClassifier(
n_estimators=’warn’,criterion=’gini’,max_depth=None,min_samples_split=2,
min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features=’auto’,
max_leaf_nodes=None,min_impurity_decrease=0.0,min_impurity_split=None,
bootstrap=True,oob_score=False,n_jobs=None,random_state=None,verbose=0,
warm_start=False,class_weight=None
)
随机森林一些重要参数:
-- 1.n_estimators :(随机森林独有)随机森林中决策树的个数。在0.20版本中默认是10个决策树;在0.22版本中默认是100个决策树;
-- 2.criterion :(同决策树)节点分割依据,默认为基尼系数。----> 可选【entropy:信息增益】
-- 3.max_depth:(同决策树)【重要】default=(None)设置决策树的最大深度,默认为None。
【(1)数据少或者特征少的时候,可以不用管这个参数,按照默认的不限制生长即可
(2)如果数据比较多特征也比较多的情况下,可以限制这个参数,范围在10~100之间比较好】
-- 4.min_samples_split : (同决策树)【重要】默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则建议增大这个 值。
-- 5.min_samples_leaf :(同决策树)【重要】这个值限制了叶子节点最少的样本数。
-- 6.min_weight_fraction_leaf : (同决策树)这个值限制了叶子节点所有样本权重和的最小值。【一般不需要注意】
-- 7.max_features : (随机森林独有)【重要】随机森林允许单个决策树使用特征的最大数量。当为整数时,即最大特征数;
当为小数时,训练集特征数*小数;
-- 8.max_leaf_nodes:(同决策树)通过限制最大叶子节点数,可以防止过拟合,默认是None
-- 9.min_impurity_split:(同决策树)这个值限制了决策树的增长【一般不推荐改动默认值】
-- 10.bootstrap=True(随机森林独有)是否有放回的采样,按默认,有放回采样
-- 11. n_jobs=1:并行job个数。这个在是bagging训练过程中有重要作用,可以并行从而提高性能。1=不并行;n:n个并行;-1:CPU有多 少core,就启动多少job。
训练模型
- 收集数据
链接:训练数据
提取码:7f7y
- 数据预处理
数据预处理一般有:读取数据、分开变量和标签、划分训练集和测试集数据:
import pandas as pd
data_1 = pd.read_csv("spambase.csv")
x = data_1.iloc[:,:-1]
y = data_1.iloc[:,-1]
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y = \
train_test_split(x,y,test_size=0.2,random_state=100)
- 构建模型
构建模型,给予数据训练结果,调整模型参数,得到尽量优的结果:
from sklearn.ensemble import RandomForestClassifier #导入随机森林算法模型
rf = RandomForestClassifier(
n_estimators=100, #训练时划分决策树的个数
max_features=0.8, #允许单个决策树使用特征的最大数量
random_state=0
)
rf.fit(train_x,train_y)
测试模型
- 测试训练集本身数据
from sklearn import metrics
train_predict = rf.predict(train_x)
print(metrics.classification_report(train_y,train_predict))
-------------------------
precision recall f1-score support
0 1.00 1.00 1.00 2246
1 1.00 1.00 1.00 1431
accuracy 1.00 3677
macro avg 1.00 1.00 1.00 3677
weighted avg 1.00 1.00 1.00 3677
- 测试划分的测试集模型
test_predict = rf.predict(test_x)
print(metrics.classification_report(test_y,test_predict))
---------------------------
precision recall f1-score support
0 0.94 0.96 0.95 539
1 0.94 0.92 0.93 381
accuracy 0.94 920
macro avg 0.94 0.94 0.94 920
weighted avg 0.94 0.94 0.94 920
绘制重要特征
-
导入必要的库:
# 导入matplotlib的pyplot模块,用于绘图 import matplotlib.pyplot as plt -
获取特征重要性:
从随机森林模型rf中获取特征重要性。
importances = rf.feature_importances_ -
创建DataFrame来存储特征重要性:
使用pandas的DataFrame来存储特征重要性:
import pandas as pd im = pd.DataFrame(importances,columns=["importances"]) -
准备特征名称:
从某个data_1 中获取列名(即特征名称),然后转换为列表,并去掉最后一个元素
clos = data_1.columns clos_1 = clos.values clos_2 = clos_1.tolist() #转化成列表 clos = clos_2[0:-1] -
将特征名称添加到DataFrame中:
将处理后的特征名称列表clos作为一列添加到DataFrame: im中,列名为’clos’:
im['clos'] = clos -
排序并选择前10个最重要的特征:
根据"importances"列的值对DataFrame进行降序排序,并只保留前10行(即最重要的10个特征)。
im = im.sort_values(by=['importances'],ascending=False)[:10] -
准备绘图:
index = range(len(im)) #生成一个与DataFrame:im长度相同的索引列表。 plt.yticks(index,im.clos) #设置y轴的刻度标签为DataFrame:im中的'clos'列的值,即特征名称。 plt.barh(index,im['importances']) #绘制一个水平条形图,x轴为特征的重要性,y轴为特征名称。 -
显示图形:
显示绘制的图形:
plt.show() -
完整绘图展示:
#绘制特征重要排名
import matplotlib.pyplot as plt
from pylab import mpl
importances = rf.feature_importances_
im = pd.DataFrame(importances,columns=["importances"])
clos = data_1.columns
clos_1 = clos.values
clos_2 = clos_1.tolist()
clos = clos_2[0:-1]
im['clos'] = clos
im = im.sort_values(by=['importances'],ascending=False)[:10]
index = range(len(im))
plt.yticks(index,im.clos)
plt.barh(index,im['importances'])
plt.show()
图像展示:
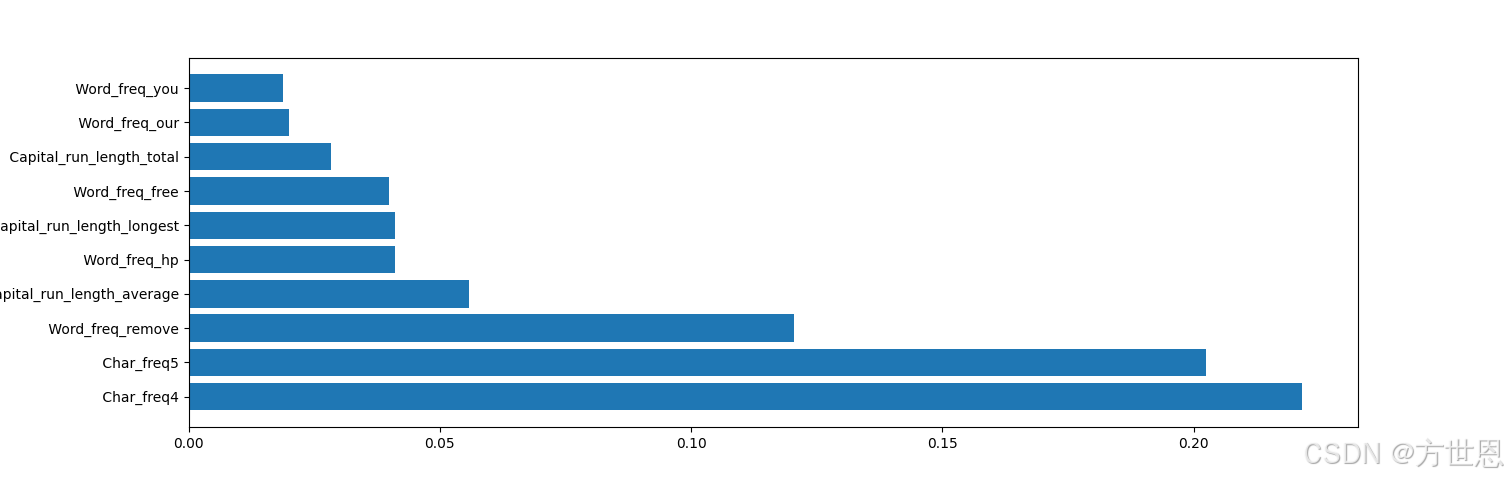
这样,我们就可以通过这个图片来进行特征工程,筛选出无关变量,优化模型啦!!
注意事项
- 尽管随机森林在很多情况下表现优异,但它仍然需要足够的训练数据来避免过拟合,并且需要仔细调整其参数(如树的数量、每个节点的最大特征数等)以达到最佳性能。
- 在处理高度不平衡的数据集时,可能需要采用特定的策略来改进随机森林的性能,如通过调整类别权重或使用不同的评估指标。
总结
本篇介绍了:
- Bagging原则
- 随机森林模型的参数
- 构建随机森林模型
- 如何绘制重要特征,进行特征工程,优化模型
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 亦菲喊你来学机器学习(12) --随机森林

发表评论 取消回复