其实使用爬虫也不是第一次了,之前从网站爬过图片,下载过大型文件,如今从下载视频开始才想到要写一篇关于爬虫的博客。
这次是为了给PPT添加视频,发现我的WPS当前版本只能添加本地视频,在线视频无法添加,并且还需要会员才可以添加大于20M的视频。Office只能添加它支持的以YouTube为代表的视频网站的一些视频,无法添加像B站等国内网站的在线视频。对于添加本地视频,WPS和Office添加方法没有什么区别,WPS还有文件大小的限制。
不能添加在线视频就只能退而求其次,添加下载好的视频,这就遇到个问题,我们要先下载好视频。
1. 下载原理
获取视频资源的源地址,然后爬取视频的二进制内容,再写入到本地即可。
2. 网页分析
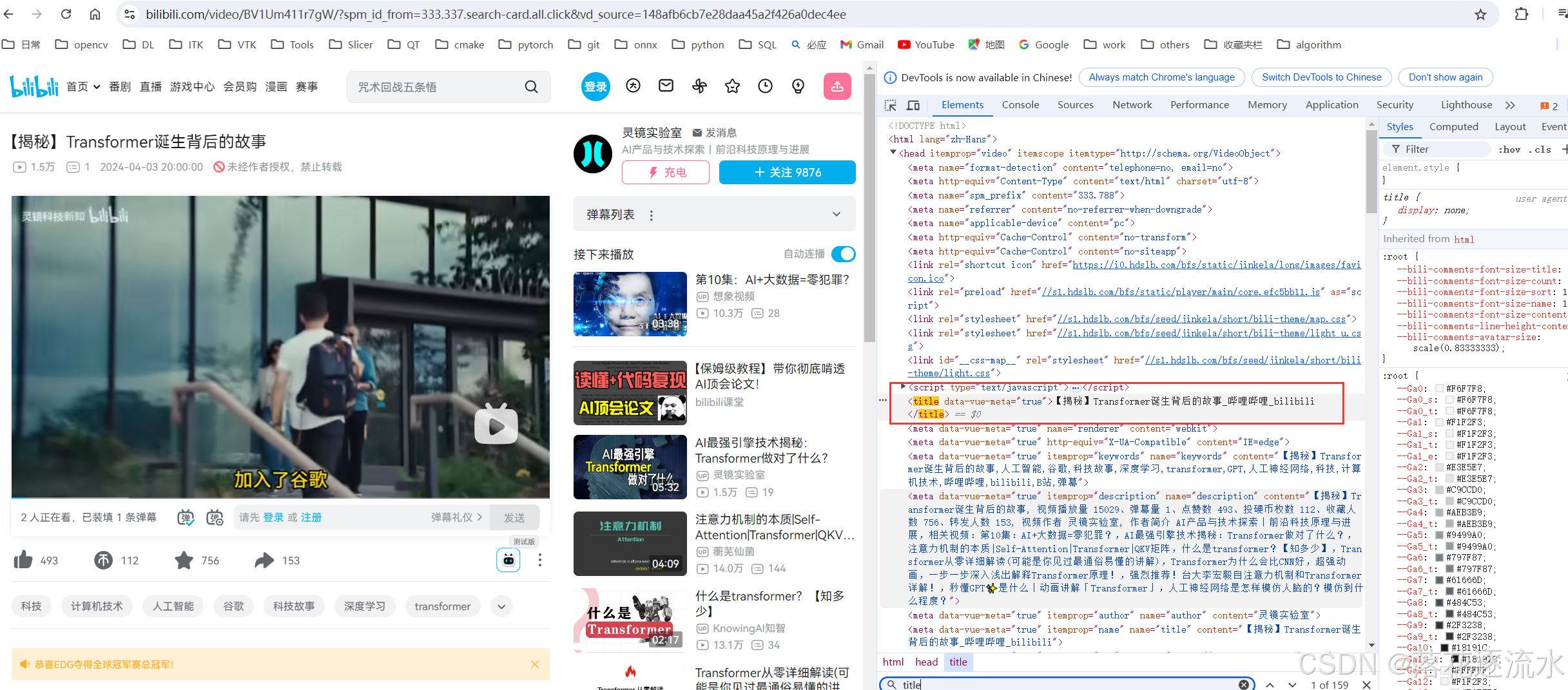
案例视频地址:https://www.bilibili.com/video/BV1Um411r7gW/?spm_id_from=333.337.search-card.all.click&vd_source=148afb6cb7e28daa45a2f426a0dec4ee
打开该网页,然后F12进入开发者模式,接着点开网络—>全部,因为视频资源一般比较大,我这里根据大小进行了从大到小的排序,找到了第一条这些可能和视频源地址有关。
查看页面源代码,经过查找可以发现视频在“playinfo”处,图片并不完整,大家可以自行搜取。
3. 请求页面,找到数据
session = requests.session()
url = 'https://www.bilibili.com/video/BV1Um411r7gW/?spm_id_from=333.337.search-card.all.click&vd_source=148afb6cb7e28daa45a2f426a0dec4ee'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.37',
"Referer": "https://www.bilibili.com"}
resp = session.get(url, headers=headers)
# print(resp.text)
利用session代替requests进行请求,session可以认为是一连串的请求,在这个过程中的cookie不会丢失。
referer代表防盗链,请求头中没有这一项将请求不到内容。防盗链可以在抓包工具中查找
4. 数据解析
title = re.findall(r'<title data-vue-meta="true">(.*?)_哔哩哔哩_bilibili', resp.text)[0]
play_info = re.findall(r'<script>window.__playinfo__=(.*?)</script>', resp.text)[0]
'''print(title)
print(play_info,type(play_info))'''
json_data = json.loads(play_info)
# pprint.pprint(json_data) #格式化输出,便于观看
# print(type(json_data))
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] # 音频地址 [0]清晰度最高
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0] # 视频地址
title与代码对应部分
<title data-vue-meta="true">【揭秘】Transformer诞生背后的故事_哔哩哔哩_bilibili</title>
playinfo与代码对应部分
<script>
window.__playinfo__={"code":0,"message":"0","ttl":1,"data":{"from":"local","result":"suee","message":"","quality":32,"format":"flv480","timelength":229505,"accept_format":"hdflv2,flv,flv720,flv480,mp4","accept_description":["高清 1080P+","高清 1080P","高清 720P","清晰 480P","流畅 360P"],"accept_quality":[112,80,64,32,16],"video_codecid":7,"seek_param":"start","seek_type":"offset","dash":{"duration":230,"minBufferTime":1.5,"min_buffer_time":1.5,"video":[{"id":32,"baseUrl":
请求到页面源代码后,解析提取“playinfo”即视频链接项,使用正则表达式(python中re库)进行提取。
利用json库将提取数据转化为字典数据,并利用pprint库进行格式化输出进行分析 。
数据中包含视频和音频两种内容,故b站的视频和音频是分开的,我们都要下载下来,然后用其他工具合成。
上面已经把提取数据转化为字典,然后利用字典找到音频audio_url 和视频地址video_url。
5. 音频、视频下载
audio_content = session.get(audio_url, headers=headers).content # 音频二进制内容
video_content = session.get(video_url, headers=headers).content # 视频二进制内容
with open(r'D:\documents\python\daily\download/' + title + '.mp3', 'wb') as f:
f.write(audio_content)
with open(r'D:\documents\python\daily\download/' + title + '.mp4', 'wb') as f:
f.write(video_content)
请求音频和视频地址,并下载下来。
6. 合并音频与视频
from moviepy.editor import *
def merge(title):
video_path = title + '.mp4'
audio_path = title + '.mp3'
# 提取音轨
audio = AudioFileClip(audio_path)
# 读入视频
video = VideoFileClip(video_path)
# 将音轨合并到视频中
video = video.set_audio(audio)
# 输出
video.write_videofile(f"{title}(含音频).mp4")
调用
merge(title)
print('有音频视频处理完成')
7. 完整代码
# -*- coding : UTF-8 -*-
# @file : download_bilibili.py
# @Time : 2024/8/26 0026 7:51
# @Author : Administrator
import pprint
import requests
import re
import json
from moviepy.editor import *
def merge(title):
video_path = title + '.mp4'
audio_path = title + '.mp3'
# 提取音轨
audio = AudioFileClip(audio_path)
# 读入视频
video = VideoFileClip(video_path)
# 将音轨合并到视频中
video = video.set_audio(audio)
# 输出
video.write_videofile(f"{title}(含音频).mp4")
if __name__ == "__main__":
session = requests.session()
url = 'https://www.bilibili.com/video/BV1Um411r7gW/?spm_id_from=333.337.search-card.all.click&vd_source=148afb6cb7e28daa45a2f426a0dec4ee'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.37',
"Referer": "https://www.bilibili.com"}
resp = session.get(url, headers=headers)
# print(resp.text)
title = re.findall(r'<title data-vue-meta="true">(.*?)_哔哩哔哩_bilibili', resp.text)[0]
play_info = re.findall(r'<script>window.__playinfo__=(.*?)</script>', resp.text)[0]
'''print(title)
print(play_info,type(play_info))'''
json_data = json.loads(play_info)
# pprint.pprint(json_data) #格式化输出,便于观看
# print(type(json_data))
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] # 音频地址 [0]清晰度最高
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0] # 视频地址
audio_content = session.get(audio_url, headers=headers).content # 音频二进制内容
video_content = session.get(video_url, headers=headers).content # 视频二进制内容
with open(r'D:\documents\python\daily\download/' + title + '.mp3', 'wb') as f:
f.write(audio_content)
with open(r'D:\documents\python\daily\download/' + title + '.mp4', 'wb') as f:
f.write(video_content)
merge(title)
print('有音频视频处理完成')
将视频下载到本地后,无论是添加到Office的PPT中还是WPS的PPT中都很方便,但是遇到WPS的PPT有文件大小限制,所以还是使用了Office的PPT。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 下载B站视频作为PPT素材

发表评论 取消回复