个人博客:Pandaconda-CSDN博客
专栏地址:http://t.csdnimg.cn/fYaBd
专栏简介:在这个专栏中,我将会分享 C++ 面试中常见的面试题给大家~
️如果有收获的话,欢迎点赞收藏,您的支持就是我创作的最大动力
13. b rk 和 sbrk 的区别
brk 和 sbrk 是用于管理进程内存空间的系统调用函数。
brk 函数用于将进程的数据段(data segment)的结束地址设置到指定的地址。可以通过调用 brk 函数来扩大或缩小进程的堆空间。它的原型如下:
int brk(void *addr);brk 函数将数据段的结束地址设置为 addr,并返回 0 表示成功,-1 表示失败。addr 必须是数据段结束地址向上舍入到系统内存页大小的倍数。
sbrk 函数用于修改进程堆的大小。它的原型如下:
void *sbrk(intptr_t increment);sbrk 函数会将进程堆的结束地址增加 increment 字节,并返回指向扩展后的堆的起始地址。注意,sbrk 的返回值是指向之前堆的结束地址的指针。如果 increment 是负数,则会减少堆的大小。increment 的值可以是任意整数值。
因此,brk 函数设置数据段的结束地址,而 sbrk 函数则用于将堆的大小扩大或缩小。在实际使用中,较常见的是使用 sbrk 函数来进行内存的分配和释放。而 brk 函数则很少直接被使用,一般是由更高级的内存管理函数或库进行调用和管理。
再总结一下:
brk 和 sbrk 是用于控制进程堆区大小的系统调用,通常用于实现动态内存分配。
-
brk调用可以将进程的堆区底部指针移动到指定位置,从而扩展或收缩堆区的大小。 -
sbrk调用可以增加或减少进程堆区的大小,它接受一个整数参数,表示要增加或减少的字节数。
需要注意的是,具体的内存分配实现可能因操作系统和编译器的不同而有所差异。因此,在特定的环境下, malloc 的行为可能会有所不同。
14. mmap 和 munmap 的区别
mmap 和 munmap 用于内存映射,通常用于实现动态内存分配和释放。
-
mmap调用可以将一个文件或匿名内存映射到进程的地址空间,也可以用于分配一块匿名内存(例如堆区)。 -
munmap调用用于取消内存映射,释放已映射的内存区域。
15. malloc 实现方案
由于 brk/sbrk/mmap 属于系统调用,如果每次申请内存,都调用这三个函数中的一个,那么每次都要产生系统调用开销 (即 cpu 从用户态切换到内核态的上下文切换,这里要保存用户态数据,等会还要切换回用户态) ,这是非常影响性能的;
其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果低地址的内存没有被释放,高地址的内存就不能被回收。
鉴于此,malloc 采用的是内存池的实现方式,malloc 内存池实现方式更类似于 STL 分配器和 memcached 的内存池,先申请一大块内存,然后将内存分成不同大小的内存块,然后用户申请内存时,直接从内存池中选择一块相近的内存块即可。
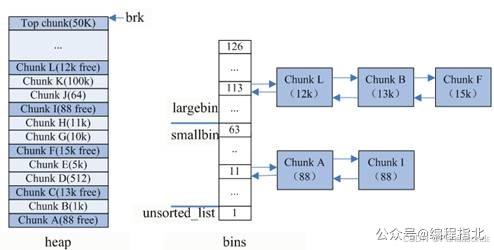

malloc 将内存分成了大小不同的 chunk,然后通过 bins 来组织起来。malloc 将相似大小的 chunk (图中可以看出同一链表上的 chunk 大小差不多) 用双向链表链接起来,这样一个链表被称为一个 bin。malloc 一共维护了 128 个 bin,并使用一个数组来存储这些 bin。数组中第一个为 unsorted bin,数组编号前 2 到前 64 的 bin 为 small bins,同一个 small bin 中的 chunk 具有相同的大小,两个相邻的 small bin 中的 chunk 大小相差 8 bytes。small bins 后面的 bin 被称作 large bins。large bins 中的每一个 bin 分别包含了一个给定范围内的 chunk,其中的 chunk 按大小序排列。large bin 的每个 bin 相差 64 字节。
malloc 除了有 unsorted bin,small bin,large bin 三个 bin 之外,还有一个 fast bin。一般的情况是,程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的 chunk 之后,也许马上就会有另一个小块内存的请求,这样分配器又需要从大的空闲内存中切分出一块,这样无疑是比较低效的,故而,malloc 中在分配过程中弓入了 fast bins,不大于 max fast (默认值为 64B) 的 chunk 被释放后,首先会被放到 fastbins 中,fast bins 中的 chunk 并不改变它的使用标志 P。这样也就无法将它们合并,当需要给用户分配的 chunk 小于或等于 max fast 时,malloc 首先会在 fast bins 中查找相应的空闲块,然后才会去查找 bins 中的空闲 chunk。在某个特定的时候,malloc 会遍历 fast bins 中的 chunk,将相邻的空闲 chunk 进行合并,并将合并后的 chunk 加入unsorted bin 中,然后再将 unsorted bin 里的 chunk 加入 bins 中。
unsorted bin 的队列使用 bins 数组的第一个,如果被用户释放的 chunk 大于 max fast,或者 fast bins 中的空闲 chunk 合并后,这些 chunk 首先会被放到 unsorted bin 队列中,在进行 malloc 操作的时候,如果在 fast bins 中没有找到合适的 chunk,则 malloc 会先在 unsorted bin 中查找合适的空闲 chunk,然后才查找 bins。如果unsorted bin 不能满足分配要求。malloc 便会将 unsorted bin 中的 chunk 加入 bins 中。然后再从 bins 中继续进行查找和分配过程。从这个过程可以看出来,unsorted bin 可以看做是 bins 的一个缓冲区,增加它只是为了加快分配的速度。 (其实感觉在这里还利用了局部性原理,常用的内存块大小差不多,从 unsorted bin 这里取就行了,这个和 TLB 之类的都是异曲同工之妙啊!)
除了上述四种 bins 之外,malloc 还有三种内存区:
-
当 fast bin 和 bins 都不能满足内存需求时,malloc 会设法在 top chunk 中分配一块内存给用户;top chunk 为在 mmap 区域分配一块较大的空闲内存模拟 sub-heap。(比较大的时候) > top chunk 是堆顶的 chunk,堆顶指 brk 位于 top chunk 的顶部。移动 brk 指针,即可扩充 top chunk 的大小。当 top chunk 大小超过 128k (可配置) 时,会触发 malloc trim 操作,调用 sbrk (-size) 将内存归还操作系统。
-
当 chunk 足够大,fast bin 和 bins 都不能满足要求,甚至 top chunk 都不能满足时 malloc 会从 mmap 来直接使用内存映射来将页映射到进程空间,这样的 chunk 释放时,直接解除映射,归还给操作系统。 (极限大的时候)
-
Last remainder 是另外一种特殊的 chunk,就像 top chunk 和 mmaped chunk 一样不会在任何 bins 中找到这种 chunk。当需要分配一个 small chunk,但在 small bins 中找不到合适的 chunk,如果 last remainder chunk 的大小大于所需要的 small chunk 大小,last remainder chunk 被分裂成两个 chunk,其中一个 chunk 返回给用户,另一个 chunk 变成新的 last remainder chunk。 (这个应该是 fast bins 中也找不到合适的时候,用于极限小的)
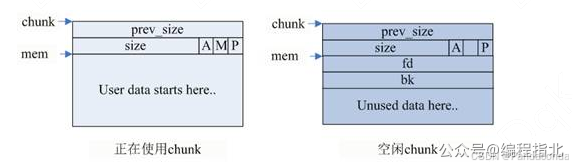

当 chunk 空闲时,其 M 状态是不存在的,只有 AP 状态,原本是用户数据区的地方存储了四个指针,指针 fd 指向后一个空闲的 chunk,而 bk 指向前一个空闲的 chunk,malloc 通过这两个指针将大小相近的 chunk 连成一个双向链表。在 large bin 中的空闲 chunk,还有两个指针,fd nextsize 和 bk nextsize,用于加快在 large bin 中查找最近匹配的空闲 chunk。不同的 chunk 链表又是通过 bins 或者 fast bins 来组织的。(这里就很符合网上大多数人说的链表理论了)。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【C++ 面试 - 内存管理】每日 3 题(五)

发表评论 取消回复