流程:
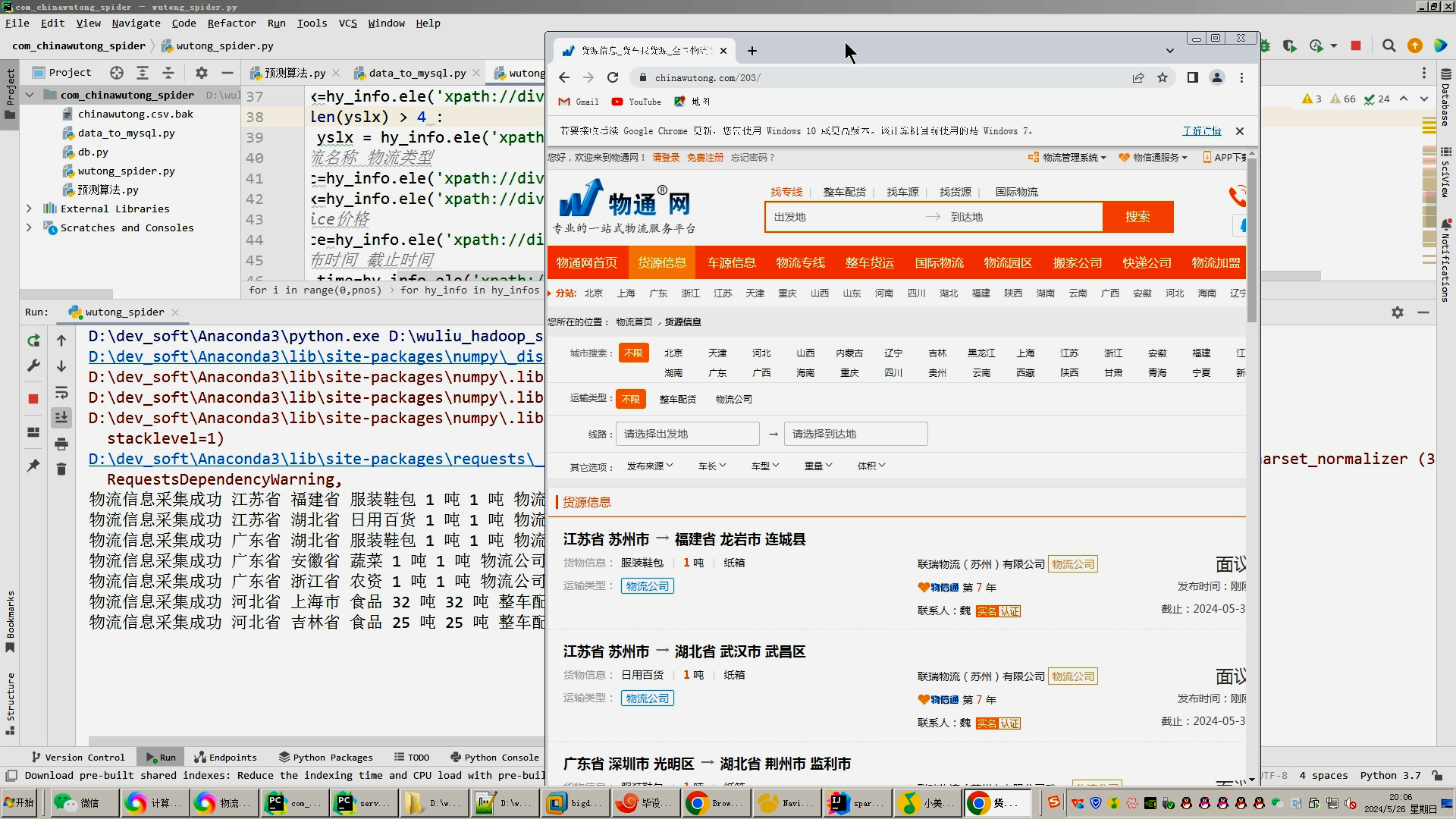
1.Python爬虫采集物流数据等存入mysql和.csv文件;
2.使用pandas+numpy或者MapReduce对上面的数据集进行数据清洗生成最终上传到hdfs;
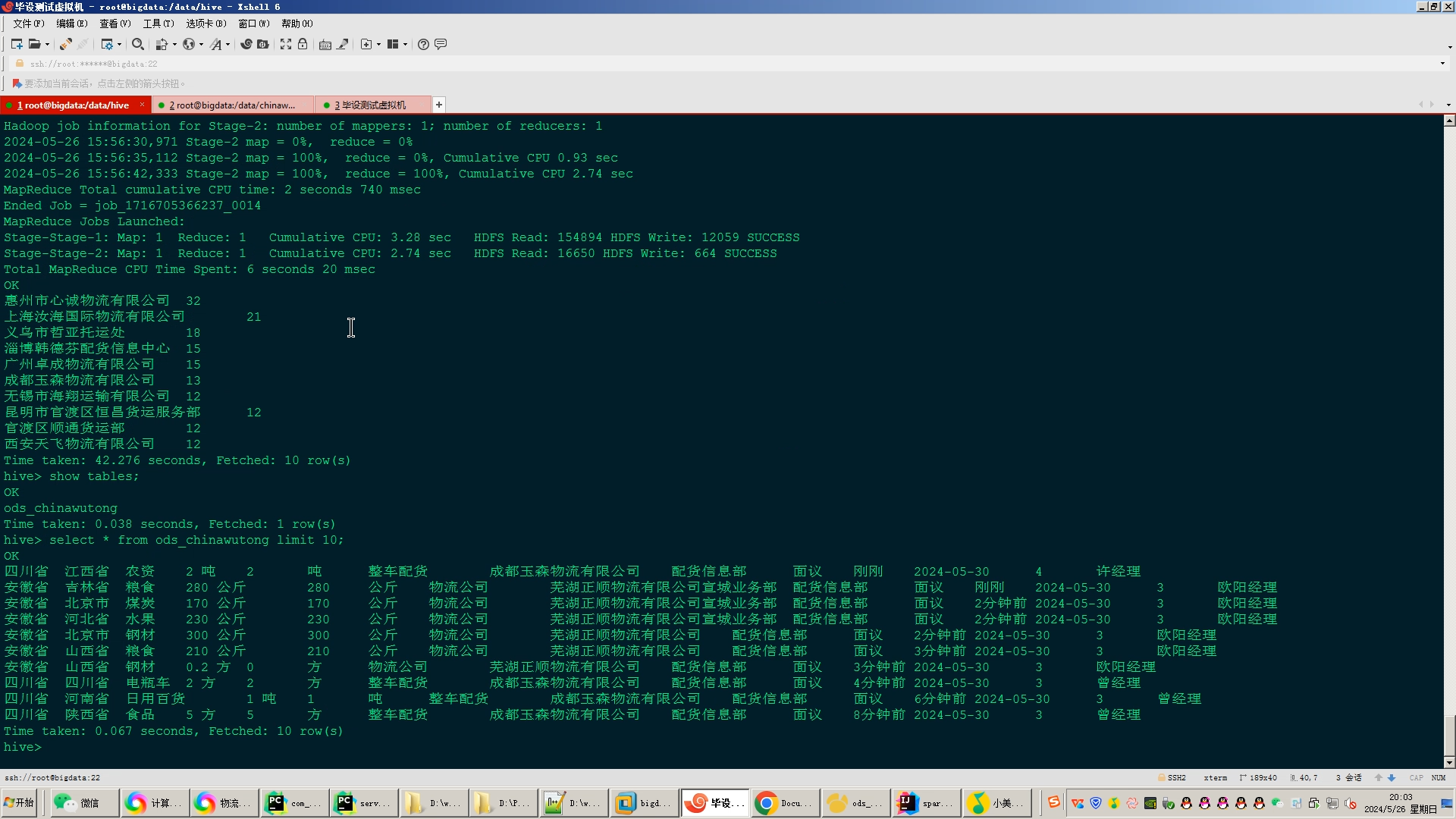
3.使用hive数据仓库完成建库建表导入.csv数据集;
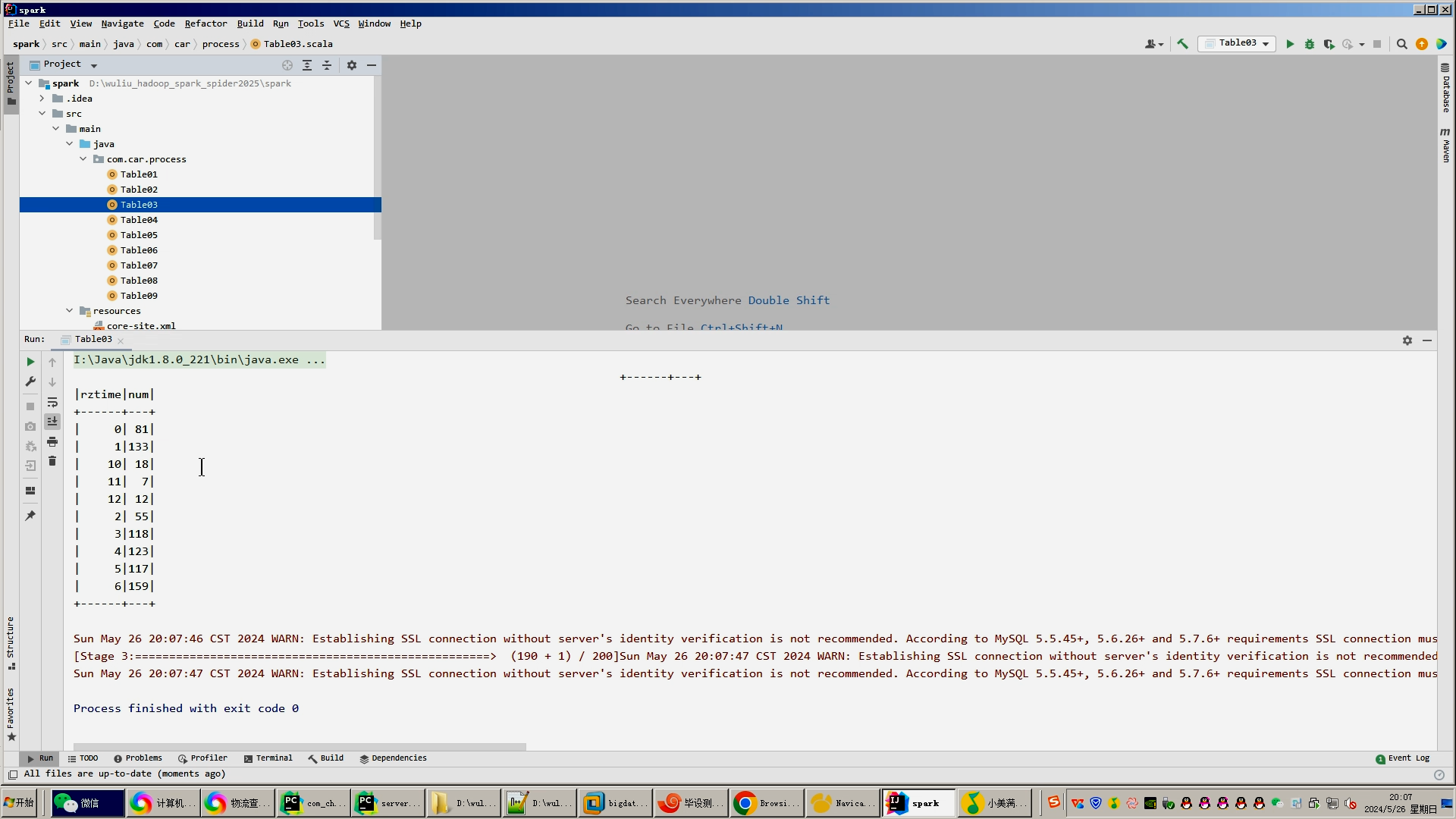
4.使用hive之hive_sql进行离线计算,使用spark之scala进行实时计算;
5.将计算指标使用sqoop工具导入mysql;
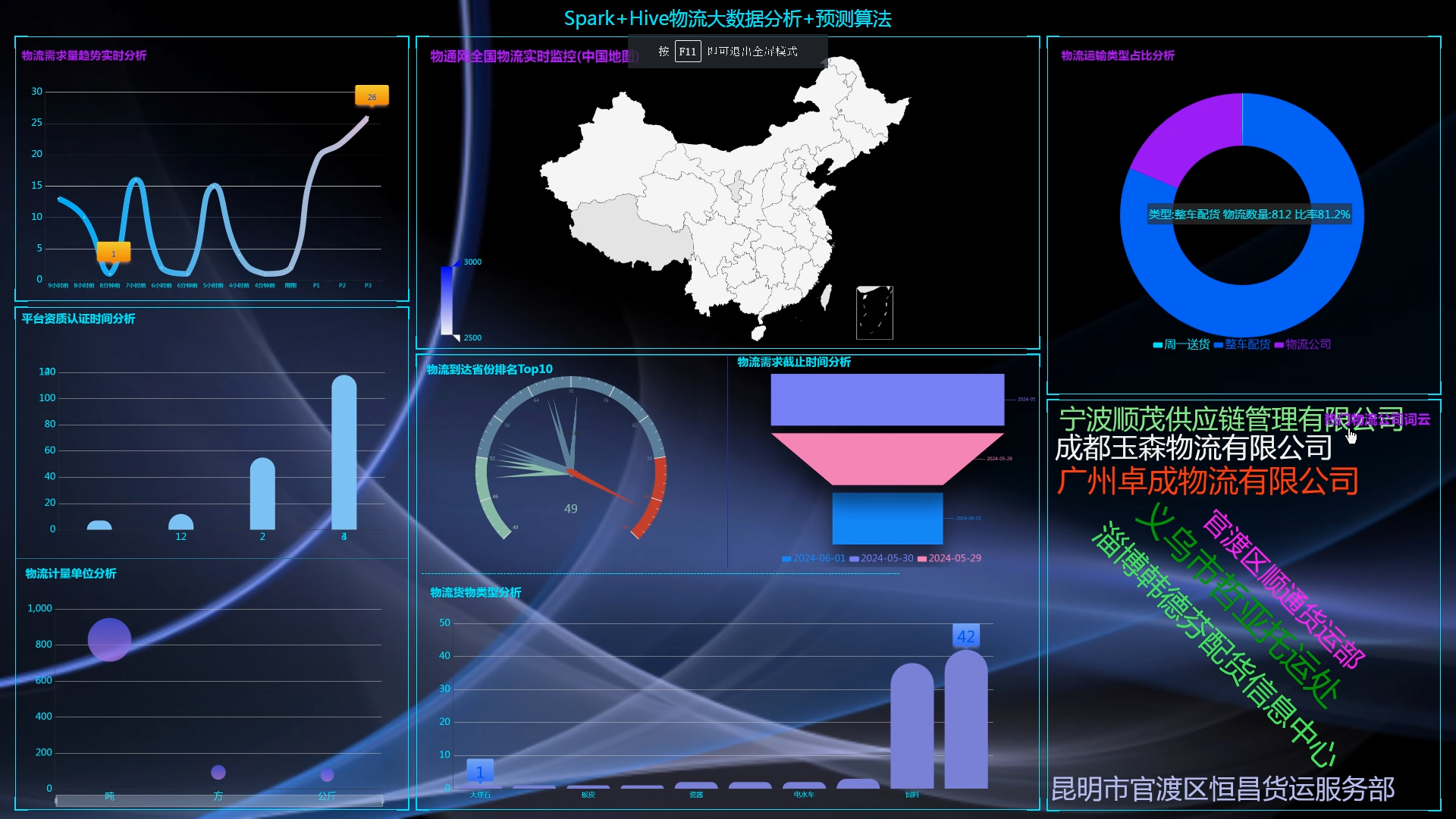
6.使用Flask+echarts进行可视化大屏实现、数据查询表格实现、含预测算法;
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 计算机毕业设计hadoop+spark+hive物流预测系统 物流大数据分析平台 物流信息爬虫 物流大数据 机器学习 深度学习

发表评论 取消回复