我们将文本转换为基本的数值,虽然只是把它们存储在字典中。我们不使用频率字典来描述文档,而是构建词频向量。在Python中,这可以使用列表来实现,但通常它是一个有序的集合或数组:
document_vector=[]
doc_length=len(tokens)
for key,value in kite_counts.most_common():
document_vector.append(value/doc_length)
print(document_vector)
对于上述列表或者向量,我们可以直接对它们进行数学运算。
如果只处理一个元素,那么在数学上没有什么意思。只有一篇文档对应一个向量是不够的,我们可以获取更多的文档,并为每篇文档创建其对应的向量。但是每个向量内部的值必须都要相对于某个在所有向量上的一致性结果进行计算(即所有文档上有个同样的东西,大家都要对它来计算)。如果要对这些向量进行计算,那么需要相对于一些一致的东西,在公共空间中表示一个位置。向量之间需要有相同的原点,在每个维度上都有相同的表示尺度或者“单位”。这个过程的第一步是计算归一化词项频率,而不是计算文档中的原始词频。第二步是将所有向量都转换到标准长度或维度上去。
此外,我们还希望每个文档向量同一维上的元素值代表同一个词。如果允许向量子啊不同位置上都包含0,也是可以的。我们会在每篇文档中找到独立的词,然后将这些词集合求并集后从中找到每个独立的词。词汇表中的这些词集合通常称为词库。
from nltk.tokenize import TreebankWordTokenizer
tokenizer=TreebankWordTokenizer()
docs=["""
The faster Harry got to the store, the faster and faster Harry would get home.
"""]
docs.append("""
Harry is hairy and faster than Jill
""")
docs.append("""
Jill is not as hairy as Harry
""")
doc_tokens=[]
for doc in docs:
doc_tokens=doc_tokens+[sorted(tokenizer.tokenize(doc.lower()))]
print(len(doc_tokens[0]))
all_doc_tokens=sum(doc_tokens,[])
print(len(all_doc_tokens))
lexicon=sorted(set(all_doc_tokens))
print(len(lexicon))
print(lexicon)
尽管有些文档并不包含词库中所有的18个词,但是上面3篇文档的每个文档向量都会包含18个值。每个词条都会被分配向量中的一个槽位(slot),对应的是它在词库中的位置。正如我们所能想到的,向量中某些词条的频率为0:
from collections import OrderedDict
zero_vector=OrderedDict((token,0) for token in lexicon)
print(zero_vector)

接下来可以对上述基本向量进行复制,更新每篇文档的向量值,然后将它们存储到数组中:
import copy
from collections import Counter
doc_vector=[]
for doc in docs:
vec=copy.copy(zero_vector)
tokens=tokenizer.tokenize(doc.lower())
token_counts=Counter(tokens)
for key,value in token_counts.items():
vec[key]=value/len(lexicon)
doc_vector.append(vec)
现在每篇文档对应一个向量 ,我们有3个向量。实际上,这里的文档词频向量能够做任意向量能做的所有有趣的事情。
下面是一些有关向量和向量空间的知识:
向量空间
向量是线性代数或向量代数的主要组成部分。它是一个有序的数值列表,或者说这些数值是向量空间中的坐标。它描述了空间中的一个位置,或者它也可以用来确定空间中一个特定的方向和大小或距离。空间是所有可能出现在这个空间中的向量的集合。因此,两个值组成的向量在二维向量空间中,而3个值组成的向量在三维向量空间中,以此类推。
一张作图纸或者图像中的像素网格都是很好的二维空间向量。我们可以看到这些坐标顺序的重要性。如果把作图纸上表示位置的x坐标和y坐标倒转,而不倒转所有的向量计算,那么线性代数问题的所有答案都会翻转。由于x坐标和y坐标互相正交,因此作图纸和图像是直线空间或者欧几里得空间的例子。
类似地图和地球仪上的经纬度也是一个二维空间,但是经纬度坐标不是精确正交,所以经纬度构成的向量空间并不是直线空间,这意味着我们计算像二维经纬度向量一样的向量或者非欧几里得空间下的向量锁表示的两点之间举例或相似度时,必须十分小心。
下图是二维向量(5,5)、(3,2)、(-1,1)的图示方法,向量头部用于表示向量空间中的一个位置,所以,图中的3个向量的头部对应了3组坐标。位置向量的尾部总是在坐标原点。
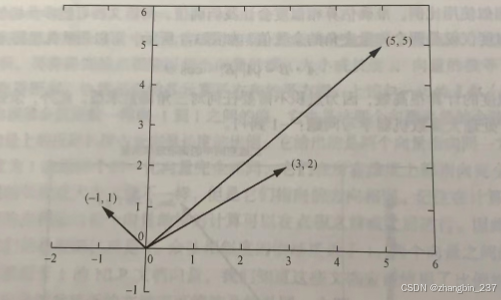
如果在三维空间,可以用三维向量的坐标x、y、z来表示。或者,由所有经度、维度、高度三元组组成的曲面空间可以描述近地球表面的位置。
但是,我们不仅仅局限于三维空间,我们可以有5维、10维、甚至5000维等各种维度的空间。线性代数对它们的处理方式都是一样的。随着维度的增加,我们可能需要更加强大的算力。
对于自然语言文档向量空间,向量空间的维数是整个语料库中出现的不同词的数量。对于TF,有时我们会用一个大写字母K,称它为K维空间。上述语料库中不同的词的数量也正好是语料库的词汇量的规模,因此在学术论文中,它通常被称为|V|。然后可以用这个K维空间中的一个K维向量来描述每篇文档。在前面3篇Harry和Jill的文档语料库中,K=18。因为人类无法轻易对三维以上的空间进行可视化,所以我们先看二维空间,这样我们就能在当前正在阅读的平面上看到向量的可视化表示。下图汇总,就是18维Harry和Jill文档向量空间的二维视图,此时K被简化为2:
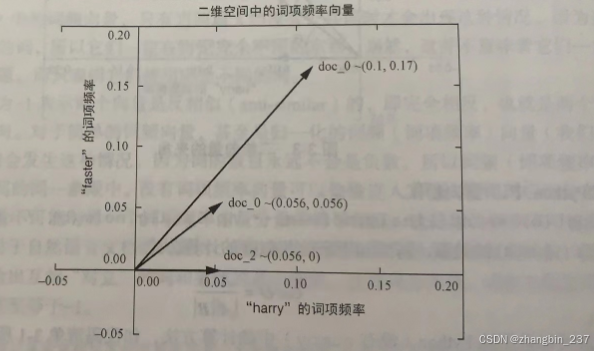
K维向量和一般向量的工作方式是完全一样的,只是不太容易地对其进行可视化而已。既然现在已经有了每个文档的表现形式,并且知道它们共享公共空间,那么接下来就可以对它们进行比较。我们可以通过向量相减,然后计算结果向量的大小来得到两个向量之间的欧几里得距离,也称为2范数距离。
如果两个向量的方向相似,他们就“相似”。他们可能具有相似的大小(长度),这意味着这两个词频(词项频率)向量所对应的文档长度基本相等。但是,当对文档中词的向量表示进行相似度估算时,我们可能不会关心文档长度。我们在对文档相似度进行估算时希望能够找到相同词的相似使用比例。准确估计相似度会让我们确信,两篇文档可能涉及相似的主题。
余弦相似度仅仅是两个向量夹角的余弦值,可以用欧几里得点积来计算:

余弦相似度的计算很高效,因为点积不需要任何对三角函数求值。此外,余弦相似度的取值范围十分便于处理大多数机器学习问题:-1到+1。
在Python中,可以使用 a.dot(b)==np.linalg.norm(a)*np.linalg.norm(b)/np.cos(theta)求解cos(theta)的关系,得到如下余弦相似度的计算公式:

还可以采用纯Python中的计算方法:
import math
def cosine_sim(vec1,vec2):
vec1=[val for val in vec1.values()]
vec2=[val for val in vec2.values()]
dot_prod=0
for i,v in enumerate(vec1):
dot_prod=dot_prod+v*vec2[i]
mag_1=math.sqrt(sum([x**2 for x in vec1]))
mag_2=math.sqrt(sum([x**2 for x in vec2]))
return dot_prod/(mag_1*mag_2)所以我们需要将两个向量中的元素成对相乘,然后再把这些乘积加起来,这样就可以得到两个向量的点积。再将得到的点积除以每个向量的模(大小或长度),向量的模等于向量的头部到尾部的欧几里得距离,也就是它的各元素平方和的平方根。上述归一化的点积的输出就像余弦函数一样取-1到+1之间的值,它也是这一两个向量夹角的余弦值。这个值等于短向量在长向量上的投影长度占长向量长度的臂力,它给出的是两个向量指向同一方向的程度。
余弦相似度为1表示两个归一化向量完全相同,它们在所有维度上都指向完全相同的方向。此外,两个向量的长度和大小可能不一样,但是他们指向的方向相同。要记住在计算上述余弦相似度时,两个向量的点积除以每个向量的模的计算可以在点积之前或之后进行。因此,归一化向量在计算点积时他们的长度都已经是1。余弦相似度的值越接近1,两个向量之间的夹角就越小。对于余弦相似度接近于1的NLP文档向量,我们知道这些文档应该使用了比例相同的相似词。因此,那些表示向量彼此接近的文档很可能涉及的是同一主题。
余弦相似度为0表示两个向量之间没有共享任何分量。他们是正交的,在所有维度上都互相垂直。对于NLP种的词频向量,只有想两篇文档没有公共词时才会出现这种情况。因为这些文档使用完全不同的词,所以它们一定在讨论完全不同的东西。当然这并不意味着它们就一定有不同的含义或主题,只表明它们使用完全不同的词。
余弦相似度为-1表示两个向量是反相似的,即完全相反,也就是两个向量指向完全相反的方向。碎玉简单的词频向量,甚至是归一化的词频(词项频率)向量,都不可能会发生这种情况。因为词的数目永远不会是负数,所以词频向量总是处于向量空间的同一象限中。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Python机器学习】NLP词中的数学——向量化

发表评论 取消回复