问题的出发点:如何智能地调整学习率?
在深度学习模型训练过程中,学习率是一个至关重要的超参数,可以把它看作是寻优过程中迈的步子大小。这个参数会影响到训练效率,以及模型是否能收敛。模型寻优时聪明不聪明很大程度上依赖学习率这个参数。
上篇文章提到,训练模型时我们有时会头痛模型卡在critical point 训练不动了,随着迭代次数增加,损失函数不再下降,而且损失函数在该点梯度变得很小。但还有另外一种情况,随着迭代,损失函数不再下降,但是梯度却并没有变得很小,见下图的呈现情况,梯度的范数并没有维持在0附近的水平: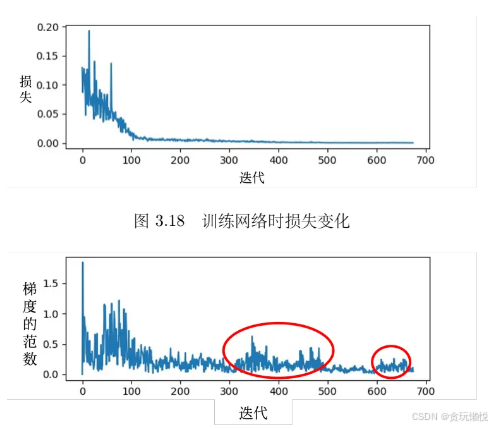
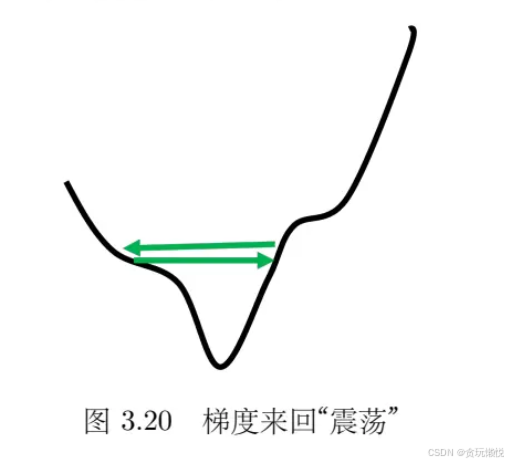
还有另一种情况,在函数比较“平坦”的地方,梯度的步子“迈得太小”,一直收敛不到最优值。
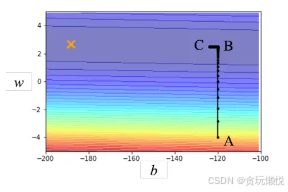
就像下面这幅图中,在AB方向上坡度很陡,步子可以放小一点,否则步伐太大就无法慢慢地滑到山谷里面。而在BC方向上的坡度很平缓,此时的步子太小,就无法向前迈进,一直在原地附近打转,这时梯度下降很难训练。
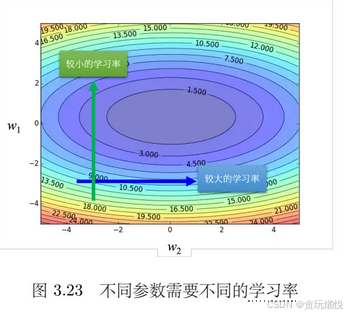
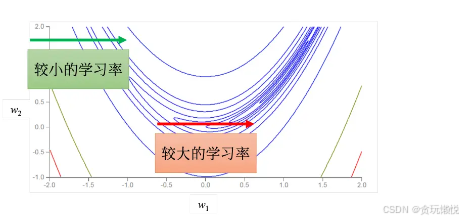
实际上在训练的时候,要走到鞍点或局部最小值是一件困难的事情,我们遇到critical point的机会并不多。在梯度下降里,所有的参数都是一样的学习率,这显然时不够的,就如上图中两个参数需要的学习率是不一样的,W2方向上的学习率应该大一点,w1方向上的学习率应该小一点。所以要找到更好的梯度下降的版本,能够实现为每个参数定制化学习率,这就引出了自适应学习率(Adaptive learning rate)
一、自适应学习率
自适应学习率(Adaptive Learning Rate)指的是根据梯度变化或参数更新历史,自动调整学习率的优化算法。相较于固定学习率,自适应学习率能够更好地适应不同阶段的训练需求,根据训练过程中的变化,灵活调整参数更新步伐。既可以在初期快速收敛,又能在接近最优解时细致调整,避免过度波动。这就能够解决固定学习率的局限:学习率过大会导致震荡,过小则收敛缓慢。在训练接近最优点时,固定学习率可能难以做出足够小的步伐调整,从而错过更优解。
以下是一些常见的自适应学习率算法:
1.1 Adagrad
Adagrad是一种经典的自适应学习率算法,通过对每个参数的更新历史进行累积来调整学习率。
核心思想:
- 用每个参数过去的梯度平方和的倒数进行调整。
- 对于变化大的参数,学习率较小;变化小的参数,学习率较大。
迭代公式:


优缺点:
- 优点:在稀疏数据和高维特征中表现良好。
- 缺点:学习率会随着训练过程逐渐减小,可能导致训练停滞。
1.2 RMSprop
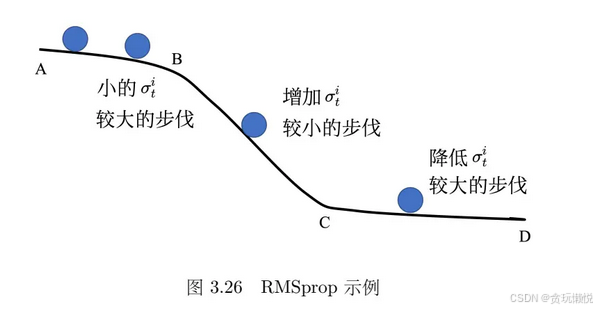
RMSprop是对Adagrad的改进,同一个参数的学习率 也可能随着时间而改变,所以同一个参数的同一个方向上,学习率也需要动态调整。像下面这幅图,在w1方向,坡度是有在变化的。
核心思想:
- 引入一个超参数来进行加权平均,RMSprop能够更稳定地调整学习率,避免Adagrad学习率不断减小的缺点(到后期迭代次数增多,分母上加的东西越来越多)。
迭代公式:


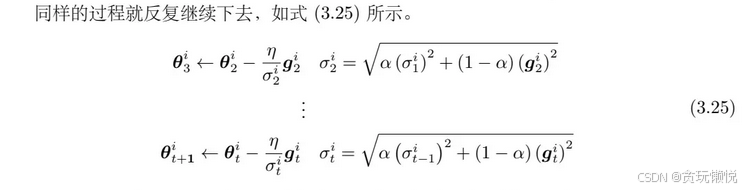
优缺点:
- 优点:更适合非平稳的目标函数,能够保持稳定的学习率。
- 缺点:依赖于超参数 α \alpha α 的选择,而这个参数是人为控制的。
1.3 Adam
Adam(Adaptive Moment Estimation)可以看作是在RMSprop上加上动量的思想,比起Adagrad, Adam是用动量
m
t
i
m_t^i
mti作为参数更新的方向,而非梯度
g
t
i
g_t^i
gti作为参数更新方向。同时用RMSProp迭代
σ
t
i
\sigma_t^i
σti,进行学习率调整。形象地理解就是动量掌控方向盘,RMSProp负责前进迈的步子有多大。
更新公式:
θ
t
+
1
i
←
θ
t
i
−
η
σ
t
i
m
t
i
\theta_{t+1}^i \leftarrow \theta_t^i - \frac{\eta}{\sigma_t^i} m_t^i
θt+1i←θti−σtiηmti
优缺点:
- 优点:兼具动量和RMSprop的优势,收敛速度快且稳定。
- 缺点:在某些情况下可能会导致欠收敛,需要仔细调节超参数。
1.4 实战:使用Adam优化器
以下是使用Adam优化器在训练简单线性回归模型的示例代码,可以用简单的例子体验一下原理:
(但你要是真的要用Adam的话,直接用Pytorch就好啦!里面已经内置了Adam)
import numpy as np
import matplotlib.pyplot as plt
# 生成示例数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 为 X 添加偏置项(即增加一列 1)
X_b = np.c_[np.ones((100, 1)), X] # 将 X 扩展为 (100, 2)
# Adam优化器的实现
class AdamOptimizer:
def __init__(self, learning_rate=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8):
self.lr = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
self.m = 0
self.v = 0
self.t = 0
def update(self, theta, grad):
self.t += 1
self.m = self.beta1 * self.m + (1 - self.beta1) * grad
self.v = self.beta2 * self.v + (1 - self.beta2) * (grad ** 2)
m_hat = self.m / (1 - self.beta1 ** self.t)
v_hat = self.v / (1 - self.beta2 ** self.t)
theta -= self.lr * m_hat / (np.sqrt(v_hat) + self.epsilon)
return theta
# 初始化参数
theta = np.random.randn(2, 1) # 与 X_b 的形状兼容
adam = AdamOptimizer(learning_rate=0.1)
# 存储损失值和参数更新路径
losses = []
theta_path = [theta.copy()]
# 训练过程
for epoch in range(100):
gradients = 2/len(X_b) * X_b.T.dot(X_b.dot(theta) - y)
theta = adam.update(theta, gradients)
# 计算当前损失
loss = np.mean((X_b.dot(theta) - y) ** 2)
losses.append(loss)
theta_path.append(theta.copy())
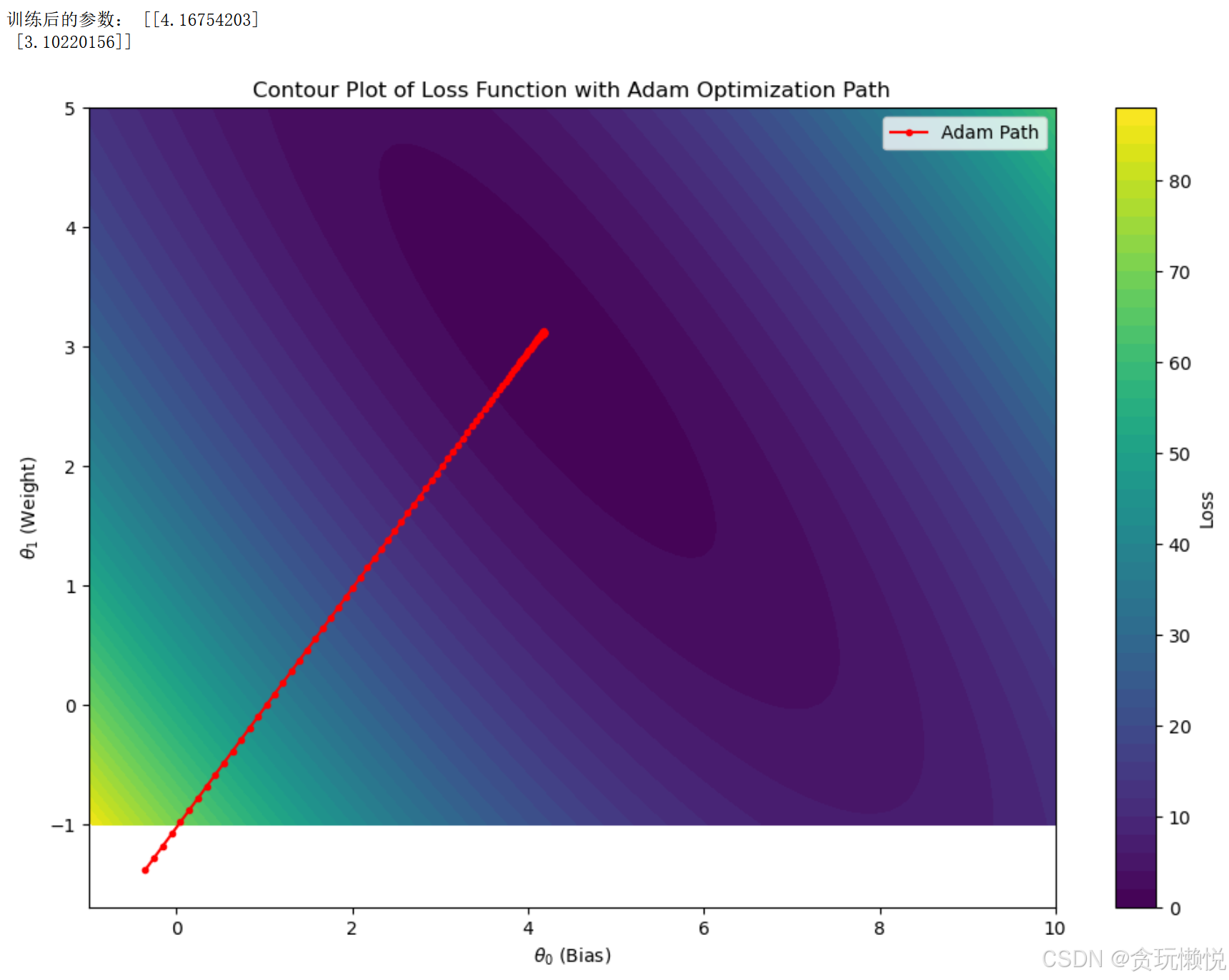
print("训练后的参数:", theta)
# 可视化损失函数的等高线图
theta0_vals = np.linspace(-1, 10, 100) # 调整范围以覆盖可能的参数值
theta1_vals = np.linspace(-1, 5, 100)
Theta0, Theta1 = np.meshgrid(theta0_vals, theta1_vals)
Loss = np.zeros(Theta0.shape)
# 计算每一对参数下的损失值
for i in range(len(theta0_vals)):
for j in range(len(theta1_vals)):
t = np.array([[Theta0[i, j]], [Theta1[i, j]]])
Loss[i, j] = np.mean((X_b.dot(t) - y) ** 2)
# 绘制等高线图并添加颜色
plt.figure(figsize=(12, 8))
contour = plt.contourf(Theta0, Theta1, Loss, levels=50, cmap='viridis') # 调整 levels 以获得更细致的颜色梯度
plt.xlabel(r'$\theta_0$ (Bias)')
plt.ylabel(r'$\theta_1$ (Weight)')
plt.title('Contour Plot of Loss Function with Adam Optimization Path')
# 添加颜色条
cbar = plt.colorbar(contour)
cbar.set_label('Loss')
# 绘制 Adam 更新路径
theta_path = np.array(theta_path)
plt.plot(theta_path[:, 0], theta_path[:, 1], 'r-o', markersize=3, label='Adam Path')
plt.legend()
plt.show()
二、学习率调度(learning rate scheduling)
学习率调度(learning rate scheduling)是另外一个控制学习率参数的方法。它可以帮助避免自适应学习率在训练后期会出现的震荡和过度跳跃(如下图所示)。为什么在训练后期会出现震荡和过度跳跃呢?
毕竟作为分母的
σ
t
i
\sigma_t^i
σti倚赖梯度的累加,到了训练后期的时候,梯度变得越来越小,作为分母的
σ
t
i
\sigma_t^i
σti它的根号里是拿所有的梯度来做平均,所以它也会跟着变小,学习率会自动变大,寻优的步伐就变大了,这就造成了后期的震荡,不过当它震荡到一定程度,梯度又变大了,它又会慢慢荡回来的。
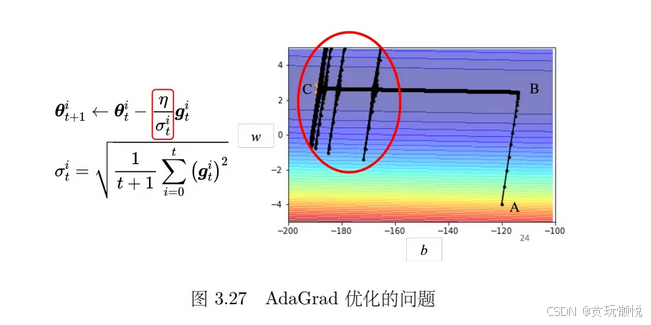
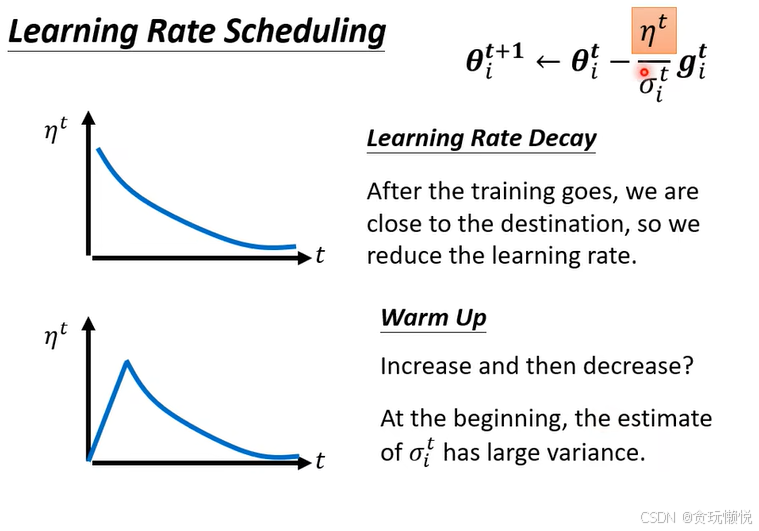
而学习率调度可以解决这个问题之前的学习率调整方法中 η 是一个固定的值,而在学习率调度中 η 跟时间有关,记为 η t \eta_t ηt,是一个和t有关的函数。有两种常用的方法:学习率衰减(learning rate decay)和预热法(Warm up),从下图看这两种方法的函数图像,随着t增大, η t \eta_t ηt都会变得很小。所以当训练后期,即使作为分母的 σ t i \sigma_t^i σti变小, η t \eta_t ηt也在变小,这样就能把震荡控制住了。
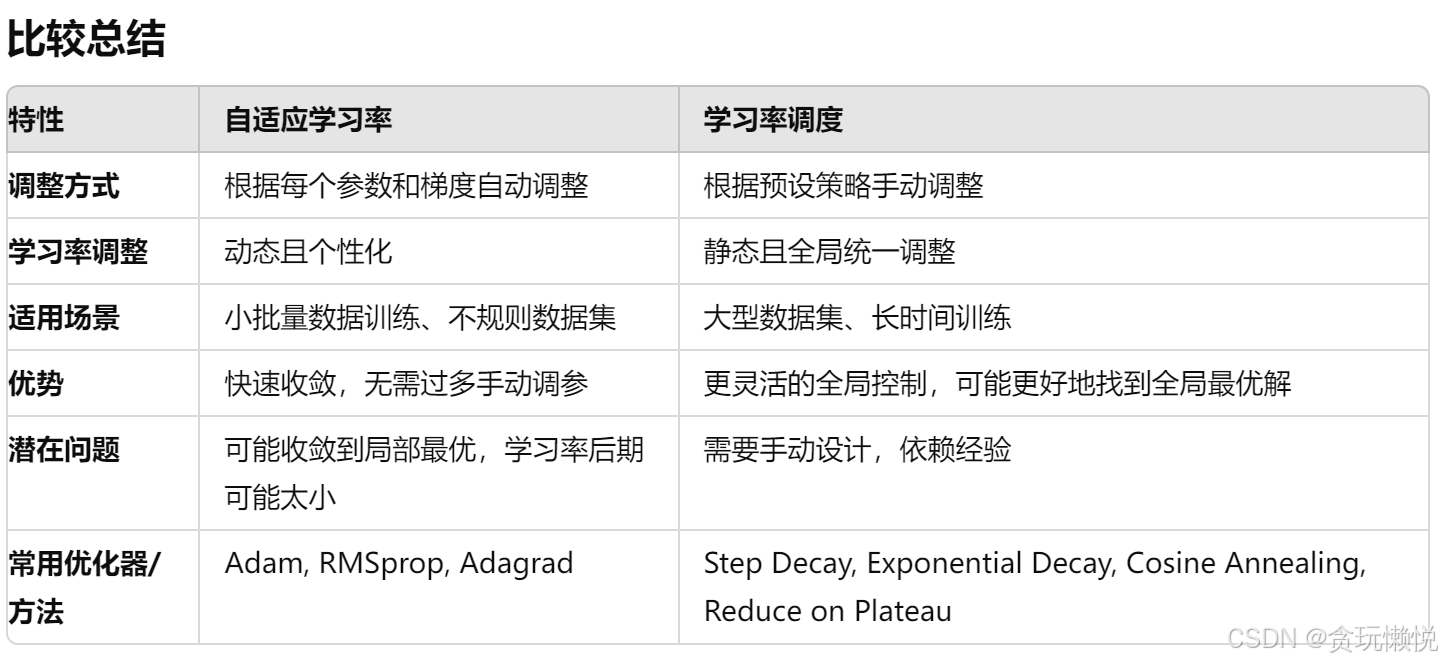
三、适应性学习率 vs 学习率调度
自适应学习率(Adaptive Learning Rate)和学习率调度(Learning Rate Scheduling)都是优化深度学习模型时用来调整学习率的方法,但它们的工作原理和应用场景有显著不同。以下是两者的详细比较:
适用学习率调度的场景
大型数据集:
对于大型数据集,自适应学习率方法在计算上可能更昂贵,因为它们需要维护每个参数的额外统计信息。而学习率调度只需要调整全局的学习率,不会增加额外的计算开销。
稳定的长时间训练:
当模型需要在大规模数据集上进行长时间的训练时,学习率调度可以通过逐步降低学习率,帮助模型更稳定地找到全局最优解。常用的调度策略如Exponential Decay和Cosine Annealing都能在训练后期通过降低学习率来避免震荡和过度跳跃。
易于调参的环境:
如果训练环境允许多次实验和调参,学习率调度可以通过反复调整策略(例如,调节步长和降低幅度)来优化模型表现。研究表明,合适的调度策略可以大幅提升模型性能。
避免快速收敛到局部最优:
当模型容易陷入局部最优时,使用调度策略可以更好地控制学习率的减少速度,帮助模型逐步细化搜索范围,找到更好的解。
经验丰富的场景:
当对特定任务和模型有较多的经验积累,可以通过设计精细的学习率调度策略来充分利用已有经验,提高模型表现。
适用自适应学习率的场景
不规则或稀疏数据集:
自适应学习率特别适合于不规则或稀疏的数据集,因为这些方法可以对每个参数进行个性化调整。例如,Adagrad特别擅长处理稀疏特征的任务,而Adam在不规则数据上表现稳定。
快速收敛需求:
在需要快速收敛的场景中,自适应学习率(如Adam和RMSprop)能显著加快收敛速度,因为它们根据梯度的历史信息自动调整步长,避免走过长或过短的步。
初学者或调参资源有限:
自适应学习率减轻了学习率调参的负担,初学者或资源有限的场景下,通过简单设置就能取得不错的结果,减少了手动调参的复杂性。
小批量训练:
自适应学习率在小批量训练(mini-batch)中效果很好,因为它能更好地处理噪声和不稳定的梯度。Adam由于对梯度一阶和二阶矩估计的调整能力,在小批量训练中尤为常用。
自动调整需求:
当你需要在训练过程中自动适应不同参数的学习率,或者不想手动设计学习率策略,自适应学习率优化器是更好的选择。
结合使用的建议
在某些情况下,可以结合使用两者来获得最佳效果:
自适应学习率 + 学习率调度: 可以在使用自适应学习率优化器(如 Adam)的同时,引入学习率调度策略(如Reduce on Plateau),在训练性能没有明显改善时进一步降低全局学习率。
四、总结
θ t + 1 i ← θ t i − η t σ t i m t i \theta_{t+1}^i \leftarrow \theta_t^i - \frac{\eta_t}{\sigma_t^i} m_t^i θt+1i←θti−σtiηtmti
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Datawhle X 李宏毅苹果书AI夏令营深度学习笔记:如何让你的模型更聪明地学习

发表评论 取消回复