package Pachong;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Regx {
public static void main(String[] args) {
String str ="Java自从95年问世以米,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
// method1(str);
Pattern p = Pattern.compile("Java\\d{0,2}");
Matcher m = p.matcher(str);
while (m.find()){
String s1 = m.group();
System.out.println(s1);
}
}
private static void method1(String str) {
//Pattern:表示正则表达式
//Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取
//获取正则表达式对象
Pattern p = Pattern.compile("Java\\d{0,2}");
//获取文本匹配器的对象
//m:文本匹配器的对象
//str:大串
//p:规则
//m要在石头人中找符合p规则的小串
Matcher m = p.matcher(str);
//拿着文本匹配器从头开始读取,寻找是否有满足规则的字串
//如果没有,方法返回false
//如果有,返回true。在底层记录字串的起始索引和结束索引+1
//0,4
boolean b = m.find();
//方法底层会根据find方法记录的索引进行字符串的截取
// substring(起始索引,结束索引);包头不包尾
// (0,4)但是不包含4索引
// 会把截取的小串进行返回
String s1 = m.group();
System.out.println(s1);
}
}
有?:和没有这个代表的是衔接的意思
?!这个是不需要有后面的这些数字意思
abbbbbbbbbbbbbaaaaaaaaaaaaaa
贪婪爬取:在爬取数据的时候,尽可能的多获取数据 ab+
非贪婪爬取:在爬取数据的时候,尽可能的少获取数据 ab+?



分组
每组是有组号的,也就是序号
规则1:从1开始,连续不间断
规则2:以左括号为基准,最左边的是第一组,其次为第二组,以此类推
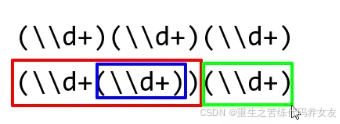
捕获分组:
后续还要继续使用本组数据
正则内部使用:\\组号
正则外部使用:$组号
非捕获分组:
分组之后不需要再用本组数据,仅仅是把数据括起来
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Java爬虫

发表评论 取消回复