背景
有意义的句子是由有意义的单词组成的,任何希望像人类一样处理自然语言的系统都必须拥有关于单词及其含义的信息。这些信息传统上是通过字典提供的,而机器可读的字典现在已经广泛使用。但字典词条的发展是为了方便人类读者,而不是为了机器。传统词典一般都是按字母顺序组织词条信息的,这样的词典在解决用词和选义问题上是有价值的。然而,它们有一个共同的缺陷,就是忽略了词典中同义信息的组织问题。
主要工作
WordNet提供了传统词典编纂信息和现代计算的更有效结合。WordNet是一个在线词汇数据库,设计用于在程序控制下使用。英语名词、动词、形容词和副词被组织成同义词组,每个同义词组代表一个词汇化的概念,语义关系将同义词集连接起来。
WordNet与其他标准词典最显著的不同在于:它将词汇分成五个大类:名词、动词、形容词、副词和虚词。实际上,WordNet仅包含名词、动词、形容词和副词。虚词通常是作为语言句法成分的一部分,WordNet忽略了英语中较小的虚词集。
WordNet最具特色之处是根据词义而不是词形来组织词汇信息。可以说WordNet是一部语义词典。但是与按字母排列的语义词典以及按主题排列的语义词典都不同,它是按照词汇的矩阵模型组织的。如下图所示。同义词集合(synonymy set)可以看作是词形(word form)之间一种具有中心角色的语义关系。WordNet的2.0版本中,有115424个同义词集合,其中名词同义词集合就有79685个。基本上涵盖了我们常用的英语名词词汇。
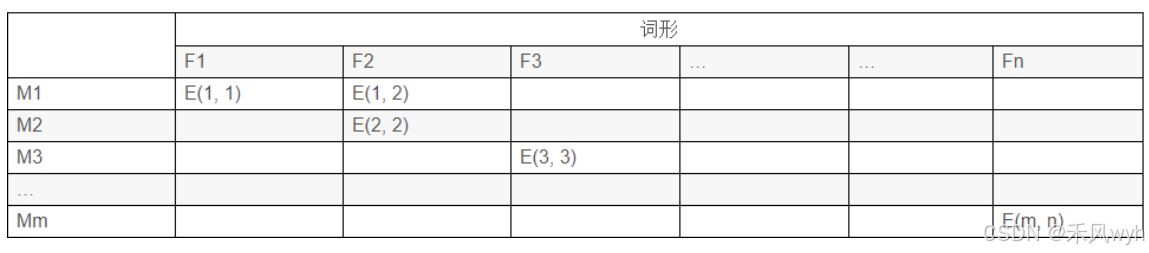
语言定义
| vocabulary 词汇 |  | |
| form 词形 |  | 由一串音素组成的话语,也可以是由一串字符组成的铭文 |
| sense 词义 |  | 来自一组给定意义的元素 |
| word 单词 | / | 有意义的形式 |
| polysemous 多义词 | / | 有一个以上意思的词 |
| synonymous 同义词 | / | 两个至少有一种意义相同的词 |
| word’s usage 词的用法 | 集合C | 词的用法是指该词可以适用的所有语言上下文。这些上下文可以被视为一个集合,用C来表示 |
| syntax句法类别 | / | 语言的句法将集合C组织成不同的句法类别。例如,一些词属于子集N(名词),另一些属于V(动词)等等。这种分类是基于词在句子中所能扮演的语法角色 |
| 语义上下文 | / | 在每个句法类别内,根据词义还有进一步的细分,称为语义上下文。这些语义上下文定义了一个词在哪些具体的上下文中可以表达特定的意义。因此,每个词都有一组上下文,在这些上下文中,它可以表达特定的语义,分别用f(形式)和s(意义)表示 |
| morphology 形态学 | 集合M | 形态学研究词的结构,它是通过词形之间的关系集合定义的。在英语中,包括:
|
| lexical semantics 词汇语义学 | 集合S | 这指的是语言中不同词义之间的关系集合。一个词所参与的特定语义关系有助于定义其意义。例如,同义词、反义词和上位词都是可以阐明词义的语义关系类型 |
语义关系

| Semantic Relation 语义关系 | Syntactic Category 语法分类 | Examples |
| Synonymy 同义词 | N, V, Aj, Av | pipe, tube rise, ascend sad, unhappy rapidly, speedily |
| Antonymy 反义词 | Aj, Av, (N, V) | wet, dry powerful, powerless friendly, unfriendly rapidly, slowly |
| Hyponymy 下位关系 | N | sugar maple, maple maple, tree tree, plant |
| Meronymy 部分关系 | N | brim, hat gin, martini ship, fleet |
| Troponomy 下位关系 | V | march, walk whisper, speak |
| Entailment 蕴含关系 | V | drive, ride divorce, marry |
下面我们介绍一些反义关系、上下位关系、部分关系。
反义关系(antonymy):一个词x的反义词有时并不是非x。如,“富有(rich)”和“贫穷(poor)”是一对反义词,但是要说某个人不富有并不意味着一定穷;许多人认为自己既不富也不穷。反义词似乎是一种简单的对称关系,实际上却是相当复杂的。反义词是一种词形间的语义关系,而不是词义间的语义关系。例如,词义{升高,上升}和{下落,下降}可能在概念上是相对的,其中[升高/下落]是反义词,[上升/下降]也是反义词。但是,如果说“升高”与“下降”与“上升”于“下落”是否是反义词,就要考虑一下了。所以有必要区分词形之间的语义关系和词义之间的语义关系。反义关系为WordNet中的形容词和副词提供了一种中心组织原则。
上下位关系 :上位关系(hypernymy)/下位关系(hyponymy)是词义之间的语义关系。如:{樟树}是{树}的下位词,{树}又是{植物}的下位词。下位/上位关系也称为从属/上属关系,子集/超集关系,或IS-A关系。如果以英语为母语接受以“An x is a (kind of) y”框架构造的句子,则同义词集合{x1,x2,…}表示的概念与同义词集合{y1,y2,…}表达的概念是下位概念和上位概念的关系。上下位关系具有某种限制,而且是一种不对称的关系。通常情况下,一个同义词集合如果有与之是下位概念和上位概念的关系的同义词集合,则也只有惟一的一个。即便是不惟一,同为上位概念的关系的同义词集合之间差别也是非常小的。这就产生了一种层次语义结构,其中下位词位于其上属关系的下层。这样的层次表达方法,Touretzky称作继承体系,它意味着下位词继承了上位词更一般化概念的所有性质,并且至少增加一种属性,以区别它与它的上位词以及该上位词的其他下位词。如,“枫树”继承了其上位词“树”的属性,但却以其坚硬的木质、叶片的形状等特性区别于其他的树。这种方法为WordNet中的名词提供了一种核心的组织原则。我们将根据WordNet名词体系中的这一继承体系的特点,定义基于一个概念(同义词集合)的概念链。
部分关系:简记为HAS-A,语言学家称之为部分词(meronym)/整体词(holonym)的关系。如果以英语为母语接受以“A y is an x”或“An x is a part of y”框架构造的句子,则同义词集合{x1,x2,…}表示的概念与同义词集合{y1,y2,…}表达的概念是部分概念和整体概念的关系。部分关系也具有某种限制,且是不对称的关系,可以构造一种部分等级关系。
相关概念
独立起始概念(Unique Beginner):如果有一同义词集合(即概念)没有上位同义词集合(即上位概念),则称之为独立起始概念(Unique Beginner)。在WordNet名词体系中,共有25个独立起始概念。其他名词通过上位/下位关系与这25个独立起始概念构成25个独立的层次结构。也就是说,标识着某个起始概念特点的属性将它的所有下位概念所继承,而这个起始概念就可以看作为是该语义领域内的所有概念(同义词集合)的一个原始语义元素。
词典编撰ID(Lexicographer ID):每一个同义词集合(synonymy set)均有惟一的一个编号,这个编号就称为词典编撰ID(Lexicographer ID)。
概念链(Concept Chain):概念链一般的定义是这样一种结构::=(C,<),其中C代表的是概念集合,<代表概念间的下位/上位关系。也就是说概念链是由C概念集合中的概念通过概念间的上位/下位关系连接而成。
WordNet名词体系中的概念链(Concept Chain)::=((C,<)<UBCi),其中UBCi表示WordNet名词体系的一个独立起始概念,C代表的是概念集合,<代表概念间的下位/上位关系。也就是说概念链是以一个独立起始概念UBCi为链首,通过概念间的上位/下位关系连接与C概念集合连接而成。同时C概念集合中的概念也是通过概念间的上位/下位关系进行连接。
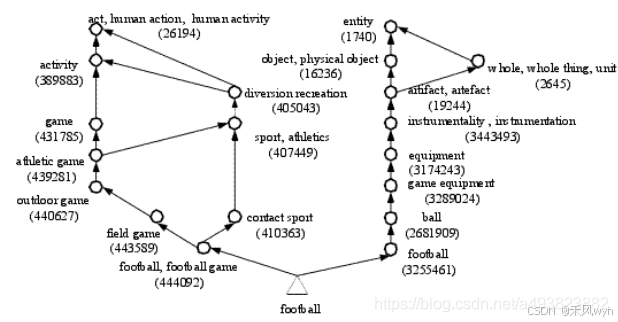
上图展示的就是一个概念链的示意范例。小三角形代表的是词“football”。每一个小圆圈都代表WordNet中的一个同义词集合(也就是概念)。小圆圈旁边的注释就是该同义词集合的内容。注释中的数字是该同义词集合的词典编撰ID(Lexicographer ID)。
这个示意范例表达的是:词“football”有两个义项,即它在两个同义词集合中出现,也就是对应图中的两个小圆圈。小圆圈之间用带箭头的线连接,表示的是小圆圈所代表的概念通过下位/上位关系联系起来,从而构成概念链。概念链的首端对应的就是WordNet中的独立起始概念。比如:概念链ch1可以表示为:(3255461)<(2681909)<(3289024)<(3174243)<(3443493)<(19244)<(2645)<(16236)<(1740)。其中(3255461)作为概念链的末端代表的是词“football”的一个义项,而(1740)是WordNet中的独立起始概念,成为概念链的首端。概念“game equipment”(3289024)是概念“ball”(2681909)的上层概念,表达的语义更抽象。
代码示例
WordNet 的完整搭建是一个非常复杂的任务,涉及到语言学、计算机科学以及大量的人工注释工作。WordNet 是由普林斯顿大学的一个团队开发和维护的,因此它的具体实现代码并没有公开提供。但是,您可以使用一些现有的工具和库来访问和操作 WordNet 数据。这些工具和库通常已经包括了 WordNet 数据库的访问和处理功能。
WordNet的使用
# 在代码中引入WordNet包
from nltk.corpus import wordnet as wn
# 查询一个词所在的所有词集
print(wn.synsets('dog'))
# 查询一个同义词集的定义
print(wn.synset('apple.n.01').definition())
# 查询词语一个词义的例子
print(wn.synset('dog.n.01').examples())
# 查询词语某种词性所在的同义词集合
print(wn.synsets('dog',pos=wn.NOUN))
# 查询一个同义词集中的所有词
print(wn.synset('dog.n.01').lemma_names( ))
# 输出词集和词的配对——词条
print(wn.synset('dog.n.01').lemmas( ))
# 利用词条查询反义词
good=wn.synset('good.a.01')
print(good)
# 查询两个词之间的语义相似度
print(good.lemmas()[0].antonyms())
WordNet的可视化
# 在代码中引入WordNet包
from nltk.corpus import wordnet as wn
import networkx as nx
import matplotlib
from nltk.corpus import wordnet as wn
def traverse(graph, start, node):
graph.depth[node.name] = node.shortest_path_distance(start)
for child in node.hyponyms():
graph.add_edge(node.name, child.name)
traverse(graph, start, child)
def hyponym_graph(start):
G = nx.Graph()
G.depth = {}
traverse(G, start, start)
return G
def graph_draw(graph):
nx.draw(graph,node_size=[16 * graph.degree(n) for n in graph], node_color=[graph.depth[n] for n in graph], with_labels=False)
matplotlib.pyplot.show()
if __name__ == '__main__':
dog = wn.synset('dog.n.01')
graph = hyponym_graph(dog)
graph_draw(graph)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » WordNet介绍——一个英语词汇数据库

发表评论 取消回复