深度学习基础(Datawhale X 李宏毅苹果书AI夏令营)
3.1局部极小值和鞍点
3.1.1. 优化失败问题
在神经网络中,当优化到梯度为0的地方,梯度下降就无法继续更新参数了,训练也就停下来了,如图:
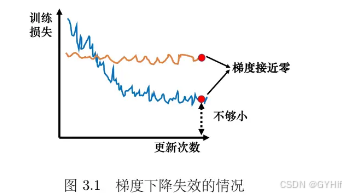
梯度为0的情况包含很多种情况:局部最小值、鞍点等。我们统称为临界值。
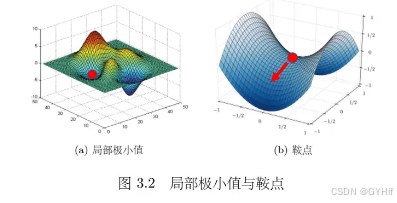
3.1.2. 判断临界值种类方法
要想知道临界值种类,我们需要知道损失函数的形状。
使用泰勒级数近似来判断:
θ
′
\theta'
θ′ 附近的
L
(
θ
)
L(\theta)
L(θ)可近似为:
L
(
θ
)
≈
L
(
θ
′
)
+
(
θ
−
θ
′
)
T
g
+
1
2
(
θ
−
θ
′
)
T
H
(
θ
−
θ
′
)
.
L(\boldsymbol{\theta})\approx L\left(\boldsymbol{\theta}^{\prime}\right)+\left(\boldsymbol{\theta}-\boldsymbol{\theta}^{\prime}\right)^{\mathrm{T}}\boldsymbol{g}+\frac{1}{2}\left(\boldsymbol{\theta}-\boldsymbol{\theta}^{\prime}\right)^{\mathrm{T}}\boldsymbol{H}\left(\boldsymbol{\theta}-\boldsymbol{\theta}^{\prime}\right).
L(θ)≈L(θ′)+(θ−θ′)Tg+21(θ−θ′)TH(θ−θ′).
其中,第一项
L
(
θ
)
′
L(θ)'
L(θ)′ 告诉我们,当
θ
θ
θ 跟
θ
′
θ'
θ′ 很近的时候,
L
(
θ
)
L(θ)
L(θ) 应该跟
L
(
θ
′
)
L(θ')
L(θ′) 还蛮靠近的;第二项
(
θ
−
θ
′
)
T
g
(θ − θ')^Tg
(θ−θ′)Tg 中,
g
g
g 代表梯度,它是一个向量,可以弥补
L
(
θ
′
)
跟
L
(
θ
)
L(θ') 跟 L(θ)
L(θ′)跟L(θ) 之间的差距。第三项跟梅森矩阵
H
H
H 有关,
在临界点,梯度
g
g
g 为0,也就是第二项为0,则损失函数可近似为:
L
(
θ
)
≈
L
(
θ
′
)
+
1
2
(
θ
−
θ
′
)
T
H
(
θ
−
θ
′
)
;
L(\boldsymbol{\theta})\approx L\left(\boldsymbol{\theta}'\right)+\frac{1}{2}\left(\boldsymbol{\theta}-\boldsymbol{\theta}'\right)^{\mathrm{T}}\boldsymbol{H}\left(\boldsymbol{\theta}-\boldsymbol{\theta}'\right);
L(θ)≈L(θ′)+21(θ−θ′)TH(θ−θ′);
我们可以根据
1
2
(
θ
−
θ
′
)
T
H
(
θ
−
θ
′
)
\frac12\left(\theta-\theta^{\prime}\right)^\mathrm{T}\boldsymbol{H}\left(\boldsymbol{\theta}-\boldsymbol{\theta}^{\prime}\right)
21(θ−θ′)TH(θ−θ′)来判断在
θ
′
\boldsymbol{\theta}^{\prime}
θ′附近的误差表 (error surface) 到底长什么样子。知道误差表面的“地貌”,我们就可以判断
L
(
θ
′
)
L(\boldsymbol{\theta}^{\prime})
L(θ′)是局部极小值、局部极大值,还是鞍点。为了符号简洁,我们用向量
v
v
v来表示
θ
−
θ
′
,
(
θ
−
θ
′
)
T
H
(
θ
−
θ
′
)
\theta-\theta^{\prime},\left(\theta-\theta^{\prime}\right)^\mathrm{T}H\left(\theta-\theta^{\prime}\right)
θ−θ′,(θ−θ′)TH(θ−θ′)可改写为
v
T
H
v
v^\mathrm{T}Hv
vTHv,
对于三种情况:
- 如果对所有 v , v T H v > 0. v,v^{\mathrm{T}}\boldsymbol{H}\boldsymbol{v}>0. v,vTHv>0.这意味着对任意 θ , L ( θ ) > L ( θ ′ ) \boldsymbol{\theta},L(\boldsymbol{\theta})>L(\boldsymbol{\theta}^{\prime}) θ,L(θ)>L(θ′).只要 θ \boldsymbol{\theta} θ在 θ ′ \boldsymbol{\theta}^{\prime} θ′附近, L ( θ ) L(\boldsymbol{\theta}) L(θ)都大于 L ( θ ′ ) L(\boldsymbol{\theta}^\prime) L(θ′).这代表 L ( θ ′ ) L(\boldsymbol{\theta}^{\prime}) L(θ′)是附近的一个最低点,所以它是局部极小值。
- 如果对所有 v , v T H v < 0. v,v^\mathrm{T}\boldsymbol{H}v<0. v,vTHv<0.这意味着对任意 θ , L ( θ ) < L ( θ ′ ) , θ ′ \boldsymbol{\theta},L(\boldsymbol{\theta})<L(\boldsymbol{\theta}^{\prime}),\boldsymbol{\theta}^{\prime} θ,L(θ)<L(θ′),θ′是附近最高的一个点, L ( θ ′ ) L(\boldsymbol{\theta}^\prime) L(θ′)是局部极大值。
- 如果对于 v v v, v T H v v^\mathrm{T}Hv vTHv有时候大于零,有时候小于零。这意味着在 θ ′ \theta^{\prime} θ′附近,有时候 L ( θ ) > L ( θ ′ ) L(\boldsymbol{\theta})>L(\boldsymbol{\theta}^{\prime}) L(θ)>L(θ′),有时候 L ( θ ) < L ( θ ′ ) L(\boldsymbol{\theta})<L(\boldsymbol{\theta}^{\prime}) L(θ)<L(θ′).因此在. θ ′ \boldsymbol{\theta}^{\prime} θ′附近, L ( θ ′ ) L(\boldsymbol{\theta}^{\prime}) L(θ′)既不是局部极大值,也不是局部极小值,而是鞍点。
一个更简单的计算方法:只看 H H H的特征值:
若 H H H的所有特征值都是正的, H H H为正定矩阵,则 v T H v > 0 v^\mathrm{T}Hv>0 vTHv>0,临界点是局部极小值。若 H H H的所有特征值都是负的, H \boldsymbol{H} H为负定矩阵,则 v T H v < 0 \boldsymbol v^\mathrm{T}\boldsymbol{H}\boldsymbol{v}<0 vTHv<0,临界点是局部极大值。若 H H H的特征值有正有负,临界点是鞍点。
3.2 批量和动量
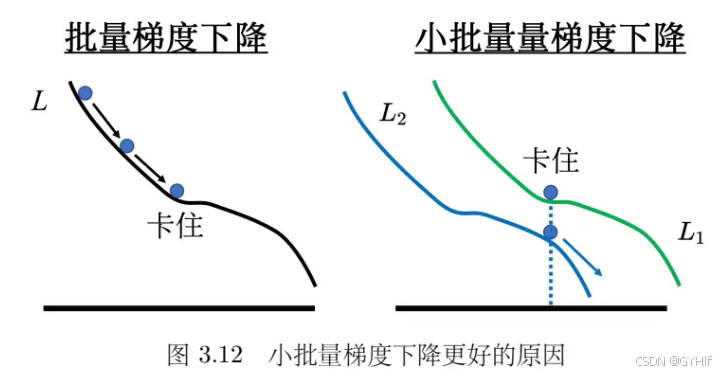
3.2.1 批量大小对梯度下降法的影响
-
批量梯度下降(BGD)
使用整个训练集的优化算法被称为批量(batch)或确定性(deterministic)梯度算法,因为它们会在一个大批量中同时处理所有样本。
-
随机梯度下降(SGD)
随机梯度下降法不同于批量梯度下降,随机梯度下降是在每次迭代时使用一个样本来对参数进行更新(mini-batch size =1)。
-
BGD每次更新更稳定,更准确;SGD在梯度上引入随机噪声,在非凸优化问题种,更容易逃离局部最小值,优化效果更好。
-
BGD遇到临界值,梯度为0的点时,难以逃离;而SGD容易逃出局部极小点等。
-
BGD泛化性一般情况下比SGD差。
3.2.2 动量法
动量法(momentum method)是一个可以对抗鞍点或局部最小值的方法。即在梯度为0的点时,可以利用自身的动量在一定情况下冲出局部极小值和鞍点等。
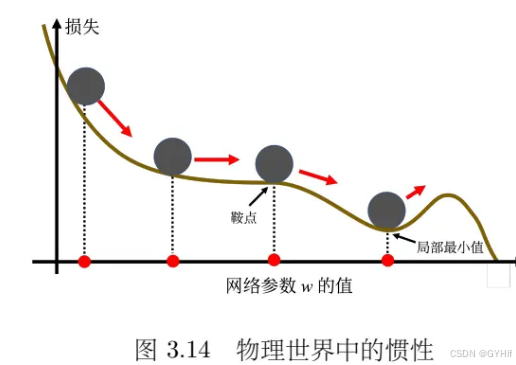
与传统的梯度下降不一样,动量法引入动量后,每次在移动参数的时候,不是只往梯度的反方向来移动参数,而是根据梯度的反方向加上前一步移动的方向决定移动方向。
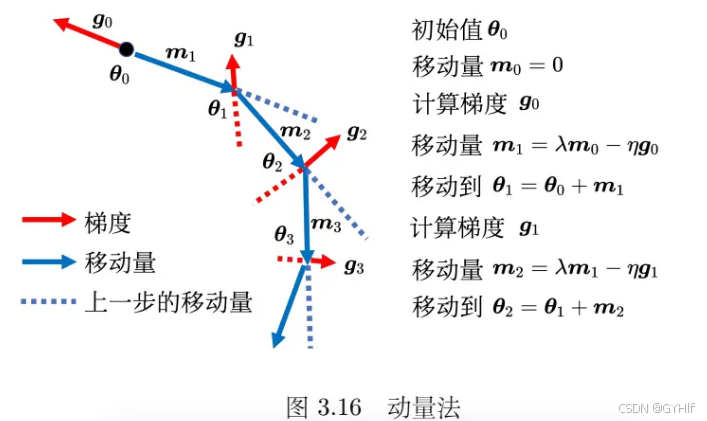
这样让梯度下降在梯度为0的点时有一定可能继续继续更新。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 深度学习基础(Datawhale X 李宏毅苹果书AI夏令营)

发表评论 取消回复