背景
在企业应用过程中,报表一般会按照数据分析的主题、项目将多个报表放在一处,一些图表类报表会有通过超链接等方式,跳转到对应的明细报表中。
并且在正式的使用中,这些报表不会绑定到目录。
在梳理数据分析项目使用情况时这些报表会难以辨认所属的项目,因为即使按照很标准的方式【将同一项目的报表放在同一目录】也会有数据分析项目相互包含的问题影响梳理的工作量。
同时在fine logDB 的访问记录中 displayName 也不会记录访问时的目录名称,所以需要通过报表模板和报表模板之间的调用关系,将没有绑定目录的报表与已经绑定目录的报表关联到一起。
从而完成梳理过程。
抓取
范围
报表模板中可以配置跳转的目标报表,一般会以以下方式配置结果
- 超链接 网络报表
- 插入子报表
- 超链接 url
- 公式定义器
- 报表块JS事件
方式
finereport 报表模板是xml格式文本文件,使用vscode打开可以确认,
xml格式文本文件可以通过 xpath 语法解析出想要的内容,以下是解析配置结果对应的xpath表达式
超链接 网络报表
//*/JavaScript[@class='com.fr.js.ReportletHyperlink']/ReportletName
插入子报表
//*/O[@t='SubReport']/packee/Path
超链接 url
//*/JavaScript[@class='com.fr.js.WebHyperlink']/URL
公式定义器
//*/O[@class='com.fr.base.Formula']/Attributes
报表块JS事件
//*/JavaScript[@class='com.fr.js.JavaScriptImpl']/Content")
如下图,在任意单元格中插入超链接,这里使用网络报表为例:
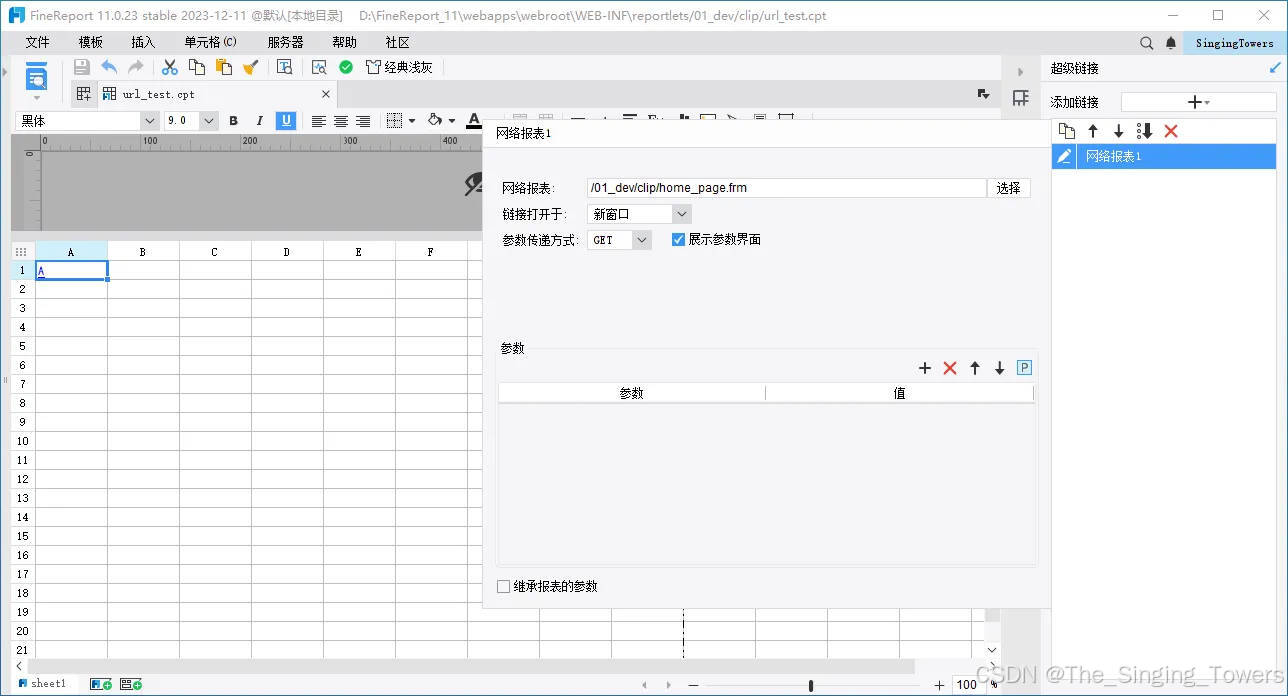
此报表模板路径为
D:\FineReport_11\webapps\webroot\WEB-INF\reportlets\01_dev\clip\url_test.cpt
配置结果中网络报表 url 为
D:\FineReport_11\webapps\webroot\WEB-INF\reportlets\01_dev\clip\home_page.frm
使用 vscode 打开 url_test.cpt
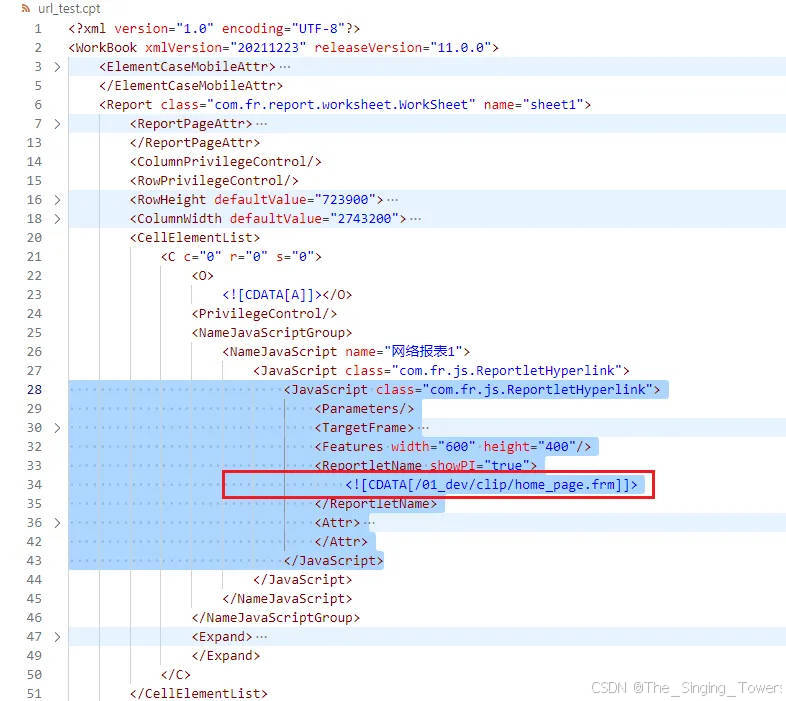
可以看到 xml 中<JavaScript class="com.fr.js.ReportletHyperlink"> 元素
它的子元素 <ReportletName showPI="true"> 包含着我们想要的结果<![CDATA[/01_dev/clip/home_page.frm]]>
所以使用 XPath 能够将 ReportletName 匹配到,并且提取到网络报表中配置的报表路径。
这里的报表路径是相对于 {fine_report_path}\webapps\webroot\WEB-INF\reportlets 的相对路径。
也是预览链接中 viewlet 参数指向的路径。http://localhost:8075/webroot/decision/view/report?viewlet=01_dev/clip/home_page.cpt
完整代码
import itertools
import pathlib
import pandas as pd
import yarl
from lxml import etree
reportlets = "D:\\FineReport_11\\webapps\\webroot\\WEB-INF\\reportlets\\"
top = "D:\\FineReport_11\\webapps\\webroot\\WEB-INF\\reportlets\\demo"
path_top = pathlib.Path(reportlets)
result_lst = []
for reportlet in itertools.chain(path_top.rglob("*.cpt"), path_top.rglob("*.frm")):
with open(reportlet, mode="rb") as fr:
xml_string = fr.read()
if xml_string is None or xml_string.__len__() <= 0:
continue
root = etree.XML(xml_string)
tree = etree.ElementTree(root)
# xpath提取 超链接 网络报表
elements_reportlet = root.xpath("//*/JavaScript[@class='com.fr.js.ReportletHyperlink']/ReportletName")
# xpath提取 插入子报表
elements_sub_report = root.xpath("//*/O[@t='SubReport']/packee/Path")
# xpath提取 超链接 url
elements_url = root.xpath("//*/JavaScript[@class='com.fr.js.WebHyperlink']/URL")
# xpath提取 公式定义器
# element_formula = root.xpath("//*/O[@class='com.fr.base.Formula']/Attributes")
# xpath提取 报表块JS事件
# element_js_content = root.xpath("//*/JavaScript[@class='com.fr.js.JavaScriptImpl']/Content")
extract_lst = []
# 处理 xpath 提取到的结果
for e in itertools.chain(elements_reportlet,
elements_sub_report):
text_element = e.text
if text_element is None:
continue
content_text = str(text_element).strip()
if ".cpt" not in content_text and ".frm" not in content_text:
continue
if content_text not in extract_lst:
extract_lst.append(content_text)
for e in itertools.chain(elements_url):
text_element = e.text
if text_element is None:
continue
url_obj = yarl.URL(text_element)
# 提取URL的各个部分
# print("# url ")
# print(url_obj.human_repr())
# print("## scheme ")
# print(url_obj.scheme)
# print("## host ")
# print(url_obj.host)
# print("## path ")
# print(url_obj.path)
# print("## query ")
# for k in url_obj.query.keys():
# print("- ", k, url_obj.query.get(k))
# print("## fragment ", url_obj.fragment)
if not url_obj.host == "localhost":
continue
if not "/webroot/ReportServer" == url_obj.path:
continue
if url_obj.query is None or url_obj.query.get("reportlet") is None:
continue
content_query = url_obj.query.get("reportlet")
# print("## reportlet ")
# print(reportlet)
if content_query not in extract_lst:
extract_lst.append(content_query)
if extract_lst is None or len(extract_lst) <= 0:
continue
for extract in extract_lst:
result_item = {
"reportlet": reportlet.relative_to(path_top).as_posix().__str__(),
"extract": extract
}
# 打印示例提取结果 {'reportlet': 'url_test.cpt', 'extract': '/01_dev/clip/home_page.frm'}
print(result_item)
result_lst.append(result_item)
# 用 pandas 存入 Excel
# 也可进行其他处理 比如存入数据库
df = pd.DataFrame(result_lst)
df.to_excel("./report_let.xlsx", engine="openpyxl", index=False)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【摸鱼笔记】python 提取和采集 finereport 未绑定目录的报表模板

发表评论 取消回复