【通俗理解】自编码器——深度学习的数据压缩与重构
第一节:自编码器的类比与核心概念
1.1 自编码器的类比
- 你可以把自编码器想象成一个“智能压缩机”,它能够把输入的数据(比如图片)压缩成一个更小的表示(编码),然后又能够从这个压缩的表示中恢复出原始的数据(解码)。
- 在深度学习的上下文中,自编码器就像是学习如何压缩和解压数据的机器,它通过学习数据的内在结构来实现这一过程。
1.2 相似公式比对
- 线性回归: y = W x + b y = Wx + b y=Wx+b,描述了如何通过线性变换(权重W和偏置b)来预测目标值y。
- 自编码器的基本形式: output = decode ( encode ( input ) ) \text{output} = \text{decode}(\text{encode}(\text{input})) output=decode(encode(input)),其中 encode \text{encode} encode是将输入压缩成编码的过程, decode \text{decode} decode是从编码恢复出原始输入的过程。
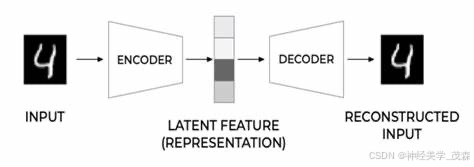
第二节:通俗解释与案例
2.1 自编码器的核心概念
- 自编码器由两部分组成:编码器(encoder)和解码器(decoder)。编码器负责将输入数据压缩成一个编码,而解码器则负责将这个编码恢复成原始数据。
- 例如,在图像处理的场景中,编码器可以将一张高分辨率的图片压缩成一个低维的向量,而解码器则可以从这个向量中恢复出原始的图片。
2.2 自编码器的应用
- 在数据降维中,自编码器可以帮助我们找到数据的有效低维表示,这对于数据可视化和存储都是非常有用的。
- 在特征学习中,自编码器可以学习到数据的特征表示,这些特征可以用于后续的分类、聚类等任务。
2.3 自编码器的优势
- 自编码器是一种无监督的学习方法,它不需要标签数据就可以学习到数据的内在结构。
- 通过自编码器学习到的特征表示往往是更加鲁棒和有用的。
2.4 自编码器与深度学习的类比
- 你可以把自编码器比作深度学习工具箱中的一把“瑞士军刀”,它既可以用来进行数据压缩,也可以用来学习数据的特征表示。
- 深度学习则像是一个大型的工具箱,里面包含了各种各样的工具(比如卷积神经网络、循环神经网络等),而自编码器就是其中非常有用的一把。
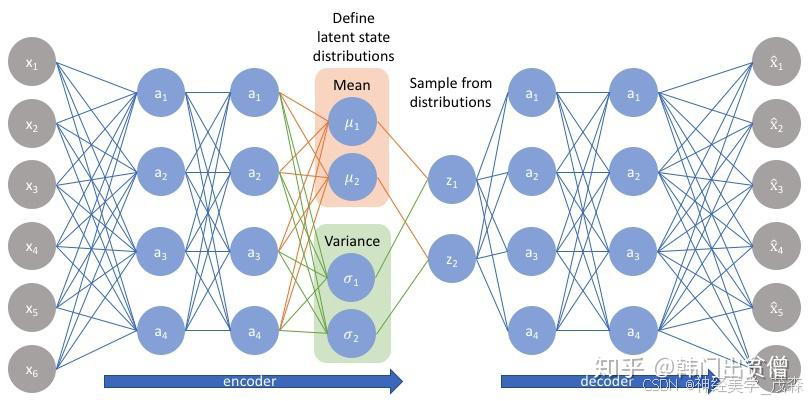
第三节:自编码器与深度学习交汇的核心作用
| 组件/步骤 | 描述 |
|---|---|
| 3.1 编码器 | 负责将输入数据压缩成一个低维的编码,这个编码是原始数据的一种有效表示。 |
| 3.2 解码器 | 负责从编码器输出的编码中恢复出原始的数据,确保数据的完整性和准确性。 |
| 3.3 损失函数 | 用于衡量解码器输出的数据与原始数据之间的差异,通过最小化损失函数来训练自编码器。 |
第四节:公式探索与推演运算
4.1 自编码器的基本公式
自编码器的基本公式可以表示为:
output = σ ( W 2 ⋅ σ ( W 1 ⋅ input + b 1 ) + b 2 ) \text{output} = \sigma(W_2 \cdot \sigma(W_1 \cdot \text{input} + b_1) + b_2) output=σ(W2⋅σ(W1⋅input+b1)+b2)
其中, W 1 W_1 W1 和 b 1 b_1 b1 是编码器的权重和偏置, W 2 W_2 W2 和 b 2 b_2 b2 是解码器的权重和偏置, σ \sigma σ 是激活函数(比如ReLU或sigmoid)。
4.2 损失函数与优化
自编码器通常使用均方误差(MSE)作为损失函数来衡量解码器输出的数据与原始数据之间的差异:
Loss = 1 n ∑ i = 1 n ( output i − input i ) 2 \text{Loss} = \frac{1}{n} \sum_{i=1}^{n} (\text{output}_i - \text{input}_i)^2 Loss=n1i=1∑n(outputi−inputi)2
其中, n n n 是数据的维度。通过梯度下降等优化算法来最小化损失函数,从而训练出自编码器。
4.3 与深度学习的关系
- 自编码器是深度学习中的一个重要模型,它通过学习数据的内在结构来实现数据的压缩和重构。
- 在深度学习中,自编码器可以作为特征提取器或预训练模型的一部分,为后续的任务提供有用的特征表示。
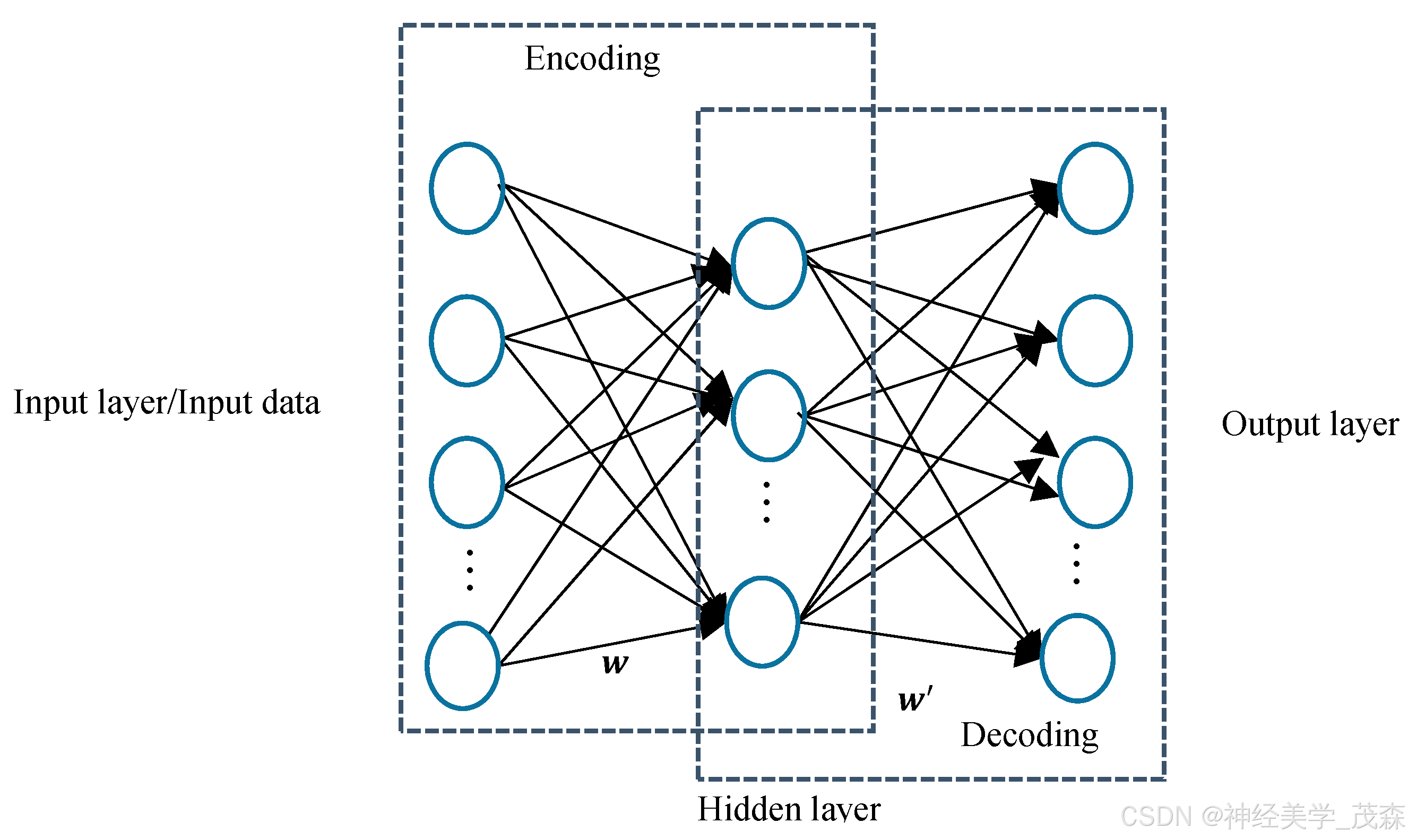
第五节:公式推导与相似公式比对
- 线性回归 与 自编码器 的共同点在于它们都是通过学习参数(权重和偏置)来最小化损失函数。不同之处在于,线性回归是用于预测连续值的目标变量,而自编码器则是用于学习数据的低维表示。
- 主成分分析(PCA) 与 自编码器 在功能上有相似之处,都是用于数据降维。但PCA是一种线性方法,而自编码器可以通过非线性激活函数学习到更加复杂的数据结构。
第六节:核心代码
以下是一个简单的自编码器模型的Python代码示例:
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# 定义编码器和解码器
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
# 定义自编码器模型
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='mse')
# 训练自编码器
# (假设x_train是已经预处理好的训练数据)
autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True)
第七节:关键词提炼
#自编码器
#深度学习
#数据压缩
#数据重构
#编码器
#解码器
#损失函数
#均方误差
#特征提取
#无监督学习
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【生成模型系列(初级)】自编码器——深度学习的数据压缩与重构

发表评论 取消回复