目录
一、前言
在当今的数字化时代,系统的稳定性和可靠性对于企业的成功至关重要。随着监控技术的不断发展,告警管理已成为确保系统健康运行的关键环节。Alertmanager,作为Prometheus生态系统中的核心组件,以其强大的告警处理能力和灵活的配置选项,成为了众多企业和开发者的首选工具。
本文将深入探讨Alertmanager的各个方面,从其基本概念和核心功能,到详细的配置参数说明,再到实际应用中的邮件告警和钉钉告警的具体实现方式。通过本文的阅读,大伙将全面了解Alertmanager的工作组件,掌握其配置技巧,并能够根据实际需求构建高效的告警管理系统。希望对感兴趣的小伙伴有帮助~
二、Alertmanager 简介
Alertmanager 最初是由 Prometheus 社区开发的,作为 Prometheus 监控系统的一部分。Prometheus 是一个开源的系统监控和告警工具包,而 Alertmanager 则是其告警管理的核心组件。随着 Prometheus 的流行,Alertmanager 也逐渐成为云原生生态系统中广泛使用的告警管理工具。它负责删除重复数据、分组,并将警报通过路由发送到正确的接收器,比如电子邮件、Slack等。Alertmanager还支持groups,silencing和警报抑制的机制。
三、Alertmanager核心内容介绍
(1)告警分组(Alert Grouping)
告警分组是 Alertmanager 的核心功能之一,它允许用户将相似的告警信息分组在一起,从而减少通知的数量,并使告警更易于管理和响应。通过合理的分组策略,用户可以更高效地处理大量的告警信息,避免信息过载。
分组原理
Alertmanager 根据用户在配置文件中定义的分组规则,将具有相同标签的告警归为一组。这些标签可以是告警信息中的任何键值对,例如 alertname、severity、instance 等。当一组告警被触发时,Alertmanager 会将这些告警合并成一个通知发送给接收器。
配置示例
以下是一个简单的 Alertmanager 配置示例,展示了如何进行告警分组:
route:
group_by: ['alertname', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: 'default'
在这个配置中:
group_by: ['alertname', 'severity']:表示告警将根据alertname和severity标签进行分组。group_wait: 30s:表示在发送新分组的告警通知之前,等待 30 秒以收集更多的告警。group_interval: 5m:表示在发送同一分组的后续告警通知之前,等待 5 分钟。repeat_interval: 3h:表示在发送已经发送过的告警通知之前,等待 3 小时。
我们可以根据实际需求灵活配置分组策略。例如,可以根据告警的严重性、服务类型、实例名称等进行分组。
(2)告警路由(Alert Routing)
告警路由是 Alertmanager 的另一个核心功能,它允许用户根据告警的标签将告警信息路由到不同的接收器。通过灵活的路由配置,用户可以实现告警的精细化管理,确保不同类型的告警能够被正确地发送给相应的团队或个人。
路由原理
Alertmanager 的路由功能基于告警信息中的标签进行匹配。用户可以在配置文件中定义多个路由规则,每个规则可以包含一个或多个匹配条件。当告警信息到达 Alertmanager 时,它会按照配置文件中定义的顺序依次匹配路由规则,直到找到匹配的规则并将告警发送到相应的接收器。
配置示例
路由块定义了路由树及其子节点。如果没有设置的话,子节点的可选配置参数从其父节点继承。每个警报都会在配置的顶级路由中进入路由树,该路由树必须匹配所有警报(即没有任何配置的匹配器),然后遍历子节点。以下是一个简单的 Alertmanager 配置示例,展示了如何进行告警路由:
route:
group_by: ['alertname', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: 'default'
routes:
- match:
severity: 'critical'
receiver: 'critical_alerts'
- match:
severity: 'warning'
receiver: 'warning_alerts'
- match:
team: 'operations'
receiver: 'operations_team'
- match:
team: 'network'
receiver: 'network_team'
在这个配置中:
route部分定义了全局的路由配置,包括分组规则和默认接收器。routes部分定义了多个子路由规则,每个规则包含一个match条件和一个receiver。
例如:
- 第一个子路由规则匹配
severity为critical的告警,并将其发送到名为critical_alerts的接收器。 - 第二个子路由规则匹配
severity为warning的告警,并将其发送到名为warning_alerts的接收器。 - 第三个子路由规则匹配
team为operations的告警,并将其发送到名为operations_team的接收器。 - 第四个子路由规则匹配
team为network的告警,并将其发送到名为network_team的接收器。
我们可以根据实际需求灵活配置路由策略。例如,可以根据告警的严重性、服务类型、团队归属等进行路由。
(3)告警静默(Alert Silencing)
告警静默是 Alertmanager 提供的一项重要功能,它允许用户在一段时间内忽略特定的告警。静默功能对于维护窗口期间或已知问题处理期间非常有用,可以避免不必要的告警干扰,提高运维效率。
静默原理
Alertmanager 的静默功能基于静默规则(Silences)进行配置。用户可以在 Alertmanager 的 Web 界面或通过 API 创建静默规则,定义需要静默的告警条件和静默的有效时间,通过匹配器(matchers)来配置,就像路由树一样。传入的警报会匹配RE,当符合条件的告警触发时,Alertmanager 会根据静默规则忽略这些告警,不发送通知。
配置示例
以下是一个静默规则的配置示例:
silences:
- id: '12345678-1234-1234-1234-1234567890ab'
matchers:
- name: alertname
value: HighMemoryUsage
isRegex: false
- name: instance
value: 'server1'
isRegex: false
startsAt: '2023-04-01T00:00:00Z'
endsAt: '2023-04-01T01:00:00Z'
createdBy: 'admin'
comment: 'Maintenance on server1'
在这个配置中:
id:静默规则的唯一标识符。matchers:定义静默规则的匹配条件,例如alertname为HighMemoryUsage且instance为server1的告警将被静默。startsAt和endsAt:定义静默规则的有效时间范围。createdBy:创建静默规则的用户。comment:静默规则的备注信息。
我们可以根据实际需求灵活配置静默规则。例如,可以根据告警的名称、实例、标签等进行静默。
(4)告警抑制(Alert Inhibition)
告警抑制是 Alertmanager 提供的一项高级功能,它允许用户在某些告警触发时抑制其他相关的告警。抑制功能对于减少告警噪声、避免重复通知非常有用,特别是在处理严重告警时,可以避免其他次要告警的干扰。
抑制原理
Alertmanager 的抑制功能基于抑制规则(Inhibit Rules)进行配置。用户可以在配置文件中定义抑制规则,指定当某个告警触发时,抑制其他符合条件的告警。抑制规则通常用于在处理严重告警时,抑制相关的次要告警。
配置示例
以下是一个抑制规则的配置示例:
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance']
在这个配置中:
source_match:定义触发抑制的告警条件,例如severity为critical的告警。target_match:定义被抑制的告警条件,例如severity为warning的告警。equal:定义匹配条件,表示alertname和instance标签必须相等。
当一个 severity 为 critical 的告警触发时,所有 severity 为 warning 且 alertname 和 instance 标签与 critical 告警相同的告警将被抑制,不会发送通知。
(5)接收器(Receivers)
接收器(Receivers)是 Alertmanager 配置中的一个关键组件,它定义了告警信息发送的目标。Alertmanager 支持多种接收器类型,包括电子邮件、Slack、钉钉、Webhook 等。通过配置接收器,用户可以将告警信息发送到不同的通知渠道,确保相关人员能够及时收到告警通知。
接收器类型
Alertmanager 支持多种接收器类型,常见的包括:
-
电子邮件(Email):
- 通过 SMTP 协议发送告警信息到指定的电子邮件地址。
-
Slack:
- 通过 Slack Webhook 发送告警信息到指定的 Slack 频道。
-
钉钉(DingTalk):
- 通过钉钉机器人 Webhook 发送告警信息到指定的钉钉群组。
-
Webhook:
- 通过 HTTP POST 请求将告警信息发送到指定的 Webhook 地址。
-
PagerDuty:
- 通过 PagerDuty API 发送告警信息,用于事件响应和通知。
-
OpsGenie:
- 通过 OpsGenie API 发送告警信息,用于事件管理和通知。
配置示例
以下是一个包含多种接收器类型的 Alertmanager 配置示例:
receivers:
- name: 'email_receiver'
email_configs:
- to: 'alerts@example.com'
from: 'alertmanager@example.com'
smarthost: 'smtp.example.com:587'
auth_username: 'alertmanager'
auth_password: 'password'
require_tls: true
send_resolved: true
- name: 'slack_receiver'
slack_configs:
- api_url: 'https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX'
channel: '#alerts'
username: 'Alertmanager'
icon_emoji: ':alert:'
send_resolved: true
- name: 'dingtalk_receiver'
webhook_configs:
- url: 'https://oapi.dingtalk.com/robot/send?access_token=your_access_token'
send_resolved: true
- name: 'webhook_receiver'
webhook_configs:
- url: 'http://example.com/webhook'
send_resolved: true
在这个配置中:
email_receiver:定义了一个电子邮件接收器,配置了 SMTP 服务器信息和发送地址。slack_receiver:定义了一个 Slack 接收器,配置了 Slack Webhook URL 和通知频道。dingtalk_receiver:定义了一个钉钉接收器,配置了钉钉机器人 Webhook URL。webhook_receiver:定义了一个 Webhook 接收器,配置了自定义的 Webhook URL。
接收器配置参数
每种接收器类型都有其特定的配置参数,以下是一些常见的配置参数:
- name:接收器的唯一标识符。
- to:电子邮件接收地址。
- from:电子邮件发送地址。
- smarthost:SMTP 服务器地址和端口。
- auth_username 和 auth_password:SMTP 认证用户名和密码。
- require_tls:是否要求 TLS 加密。
- api_url:Slack Webhook URL 或钉钉机器人 Webhook URL。
- channel:Slack 通知频道。
- username:Slack 通知用户名。
- icon_emoji:Slack 通知图标。
- url:Webhook URL。
- send_resolved:是否发送恢复告警通知。
通过上述这些核心配置以组成alertmanager的配置文件,通过合理的配置,我们可以根据自己监控告警需求去实现告警的精细化管理和高效通知。
四、Alertmanager配置邮件告警
首先要准备相关服务,prometheus+alertmanager+node_exporter是必不可少的。这里因为咱们接上文离线环境下的 Prometheus 生态部署攻略进行编写的,所以这里不再说明相关组件怎么进行安装的问题了,前面针对离线环境下的安装已经很清楚了,如果有使用docker或者k8s的那应该更方便。所以这块主要对配置流程及方法进行说明。
然后需要在alertmanager配置文件中配置邮件信息,这里以qq邮箱为例:
root@master01:/opt/monitor# vi alertmanager/alertmanager.yml
root@master01:/opt/monitor# cat alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '自己的@qq.com'
smtp_auth_username: '自己的@qq.com'
smtp_auth_password: '申请的授权码'
smtp_hello: 'qq.com'
smtp_require_tls: false
route:
#这里的标签列表是接收到报警信息后的重新分组标签
group_by: ['alertname','severity']
#当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知
group_wait: 30s
#当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 40s
#如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 30s
#默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: 'email'
#上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
#使用标签匹配报警,这里匹配告警规则中severity为warning的告警信息
match:
severity: warning
receivers:
- name: 'email'
email_configs:
- to: '自己的@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'severity', 'instance']
需要说明的是,这里的qq授权码大家需要进入qq邮箱-账号安全中去开启POP3/IMAP/SMTP/Exchange/CardDAV 服务,并申请授权码。
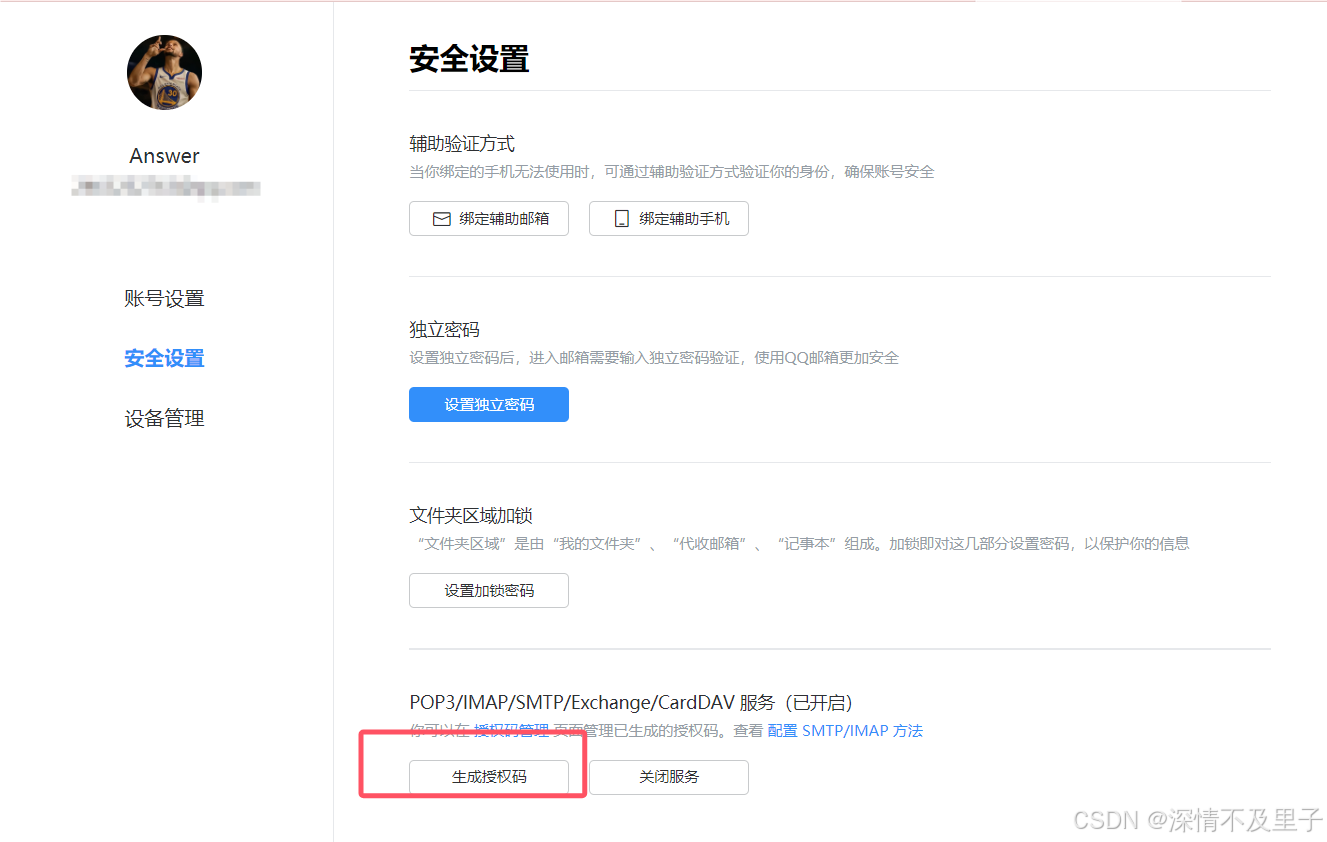
配置好相应的分组信息及邮件接收信息后即可配置对应的告警规则了。当然也可以先配置告警规则再配置alertmanager。只要注意labels中的标签与前面alertmanager中的要有部分匹配,不然定义的alertmanager告警可能会处理不了告警信息。
root@master01:/opt/monitor# vi prometheus/first_rules.yml
root@master01:/opt/monitor# cat prometheus/first_rules.yml
groups:
- name: my first rules
rules:
- alert: 内存使用率过高
expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 60
for: 3m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"
description: "{{ $labels.instance }} 内存使用率超过60%, 当前使用率{{ $value }}%."
- alert: 服务器宕机
expr: up == 0
for: 1s
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} 服务器宕机, 请尽快处理!"
description: "{{ $labels.instance }} 服务器延时超过3分钟, 当前状态{{ $value }}."
- alert: CPU高负荷
expr: 100 - (avg by (instance, job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU使用率过高, 请尽快处理!"
description: "{{ $labels.instance }} CPU使用大于80%, 当前使用率{{ $value }}%."
- alert: 磁盘IO性能
expr: avg(irate(node_disk_io_time_seconds_total[1m])) by (instance, job) * 100 > 50
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 流入磁盘IO使用率过高, 请尽快处理!"
description: "{{ $labels.instance }} 流入磁盘IO大于50%, 当前使用率{{ $value }}%."
- alert: 网络流入
expr: ((sum(rate(node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance, job)) / 100) > 102400
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 流入网络带宽过高,请尽快处理!"
description: "{{ $labels.instance }} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{ $value }}."
- alert: 网络流出
expr: ((sum(rate(node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance, job)) / 100) > 102400
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 流出网络带宽过高, 请尽快处理!"
description: "{{ $labels.instance }} 流出网络带宽持续5分钟高于100M. RX带宽使用量{{ $value }}."
- alert: TCP连接数
expr: node_netstat_Tcp_CurrEstab > 10000
for: 2m
labels:
severity: warning
annotations:
summary: "TCP_ESTABLISHED过高!"
description: "{{ $labels.instance }} TCP_ESTABLISHED大于100%, 当前使用率{{ $value }}%."
- alert: 磁盘容量
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 50
for: 1m
labels:
severity: critical
annotations:
summary: "{{ $labels.mountpoint }} 磁盘分区使用率过高,请尽快处理!"
description: "{{ $labels.instance }} 磁盘分区使用大于50%,当前使用率{{ $value }}%."
这里笔者故意设置较低的阈值使某些条件满足来测试告警,以便能收到告警信息 ,毕竟这块咱们的服务器不是正式环境下的。然后重新加载prometheus和alertmanager服务:
root@master01:/opt/monitor# curl -X POST "http://192.168.1.200:9093/-/reload"
root@master01:/opt/monitor# curl -X POST "http://192.168.1.200:30080/-/reload"
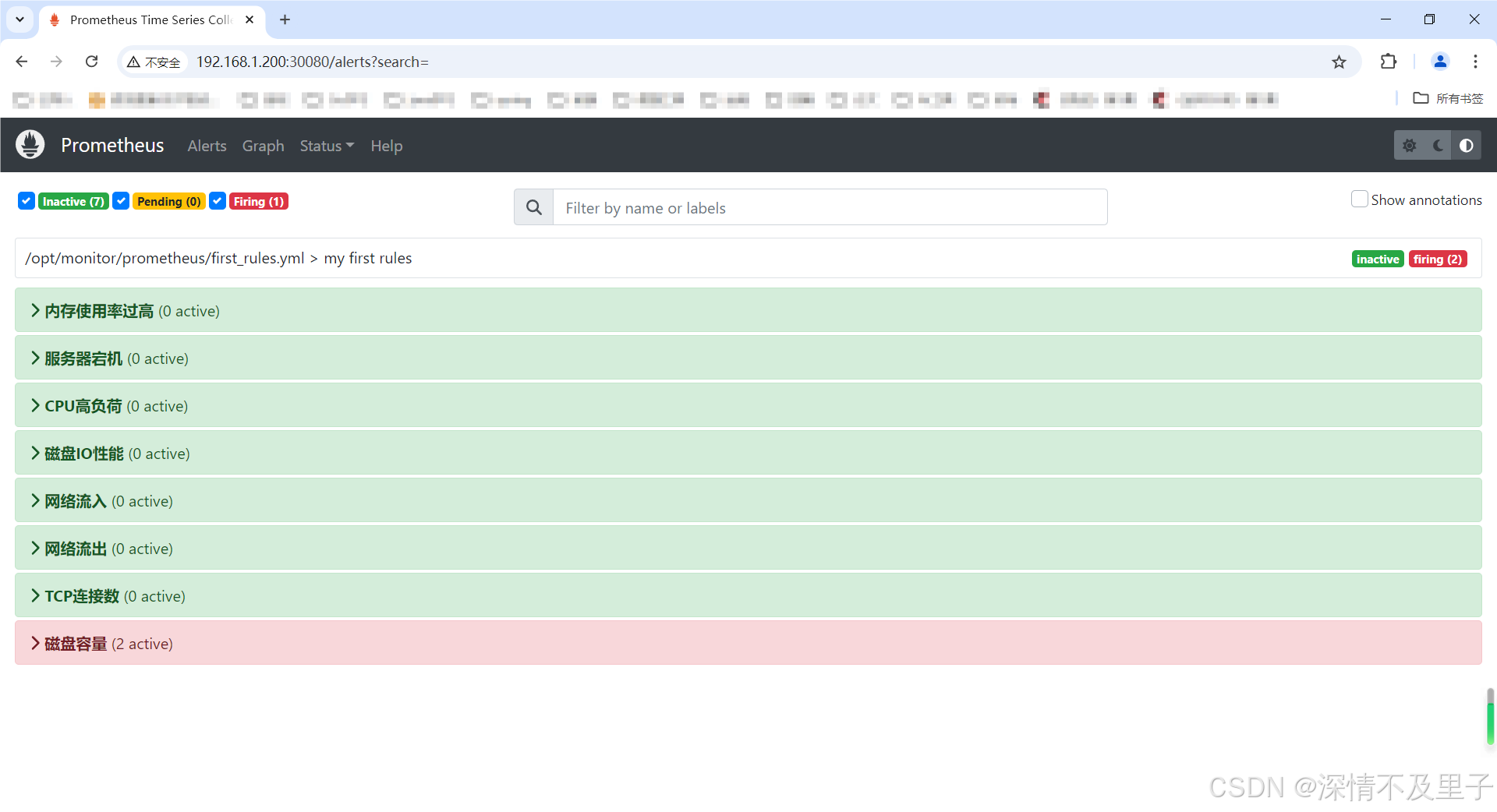
只要配置正确一般都能正常重启,除非yml文件格式不对。然后等待1分钟后prometheus进入了等待PENDING状态,当前值已经大于我们设置的限额数值后,现在已经出发报警。可以看到prometheus的alert界面,已经产生告警信息了。
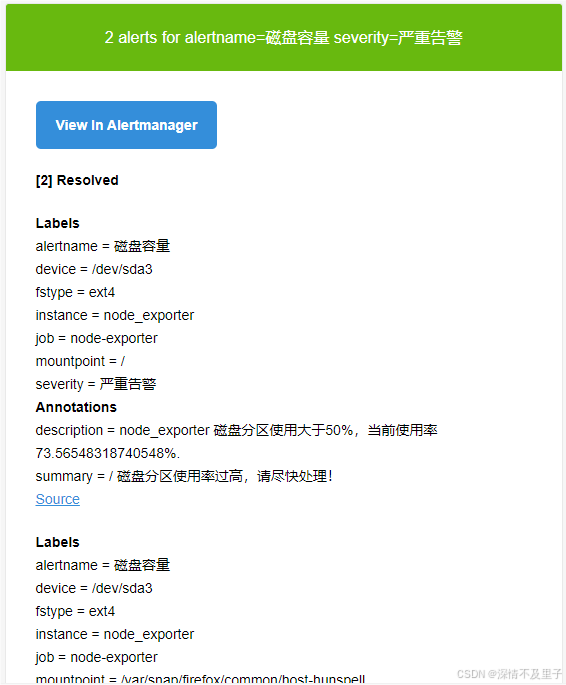
然后咱们的邮箱就能收到告警的信息了,由于时间间隔设置的比较短,所以可能短信会比较多,这个大家需要根据自己需求自己设置好频率,不然挺烦的:

并且可以查看其中的具体信息:
五、Alertmanager通过webhook集成钉钉告警
除了邮箱外,alertmanager还支持其他很多方式,比如工作中常见的还有企业微信、钉钉等等。所以这块通过webhook,咱们可以与钉钉机器人集成,便于在工作中方便的监督服务运行情况,比邮箱动不动提醒就方便多了。
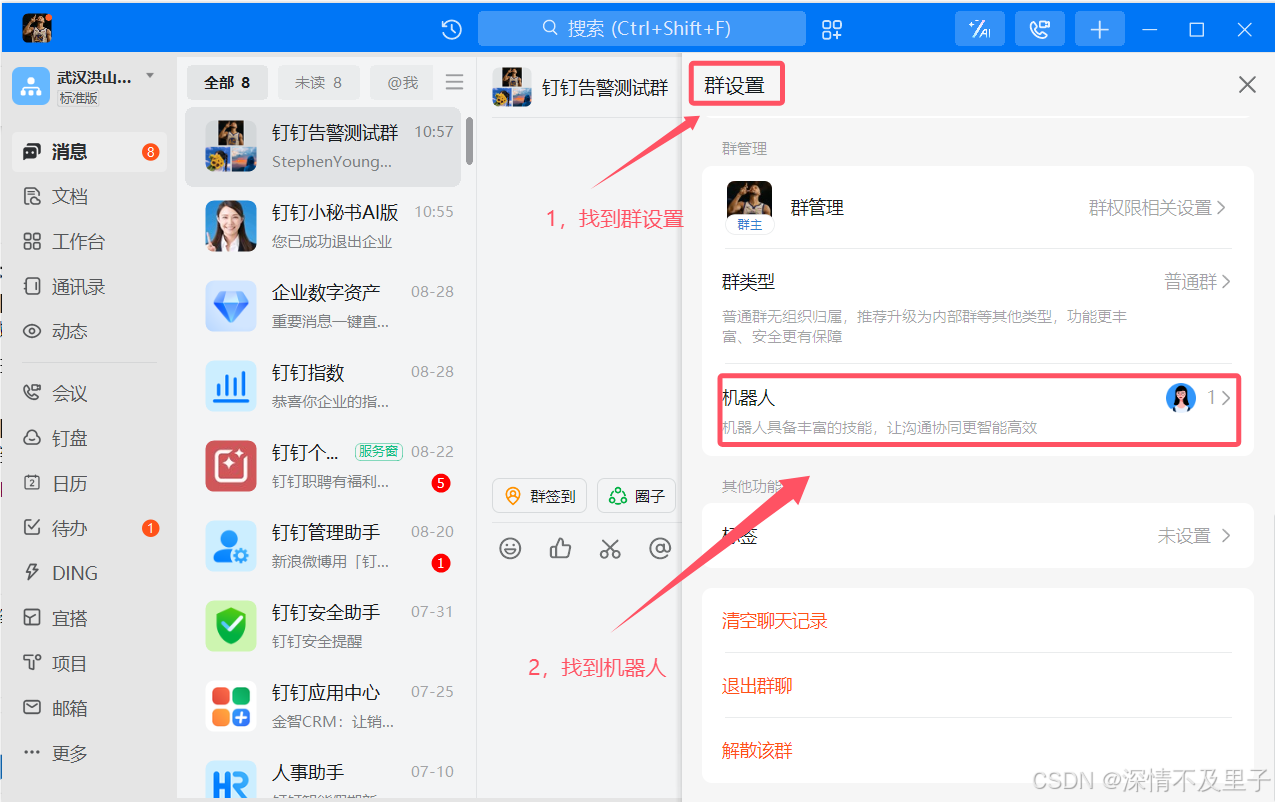
(1)添加钉钉告警机器人
首先登录钉钉后在钉钉群里面找到群设置,然后在其中找到钉钉中的“机器人”,点进去。
然后选择添加机器人:
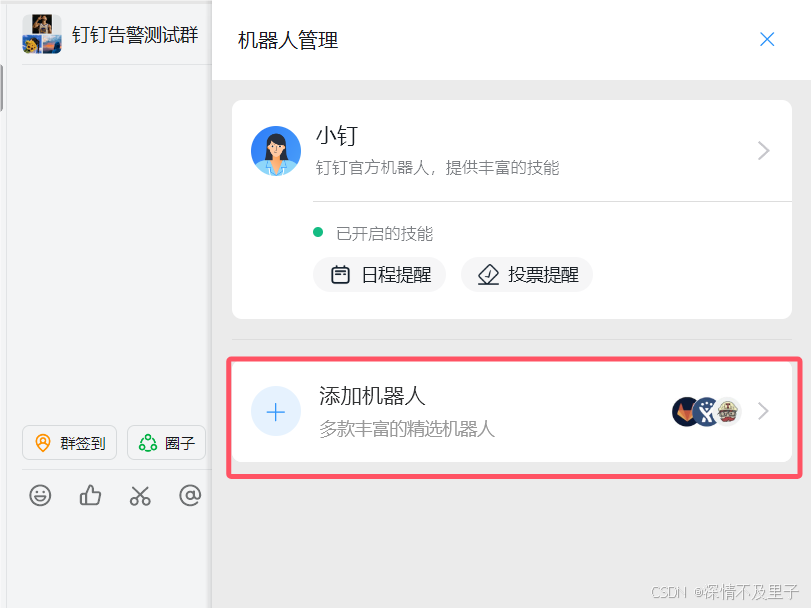
此时可以看到有很多机器人可供使用,但是我们仅需要webhook可接入自定义服务的即可:
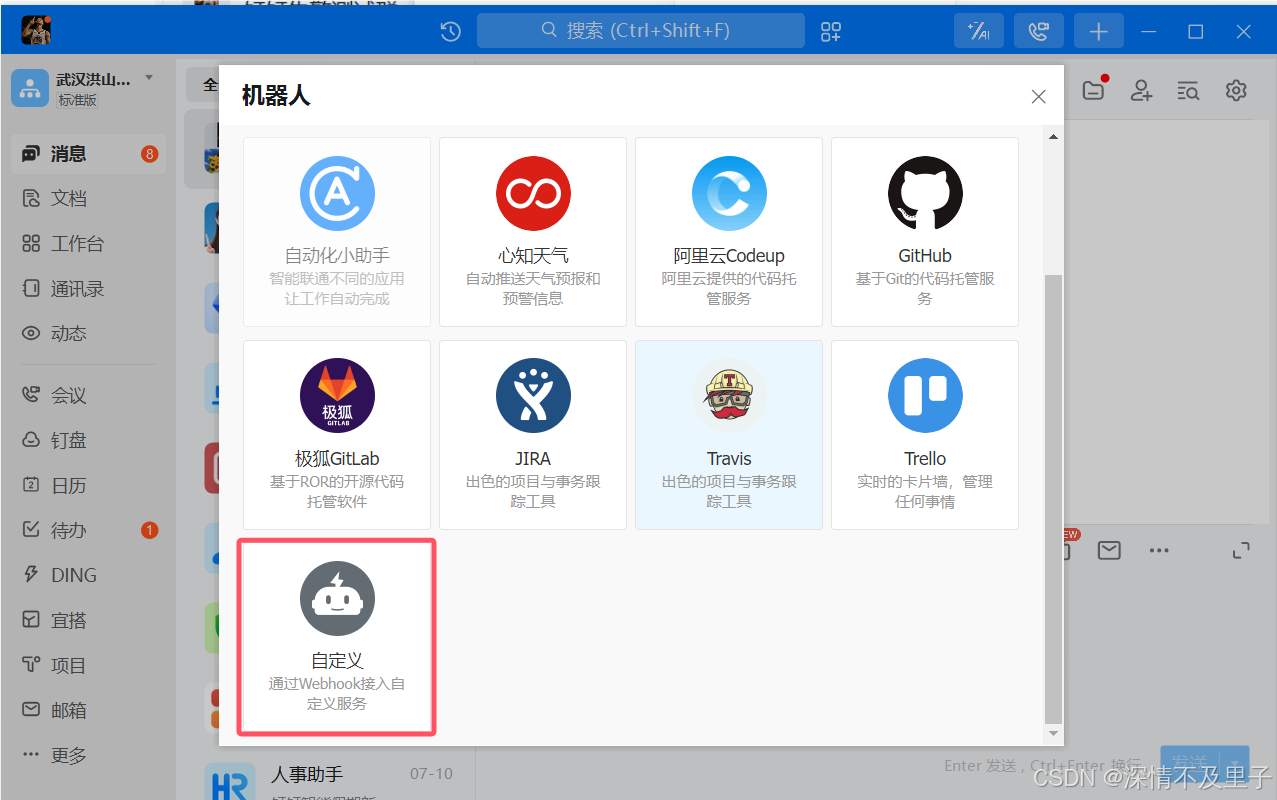
然后添加一些添加机器人的信息进行添加,这里必须要设置一个安装设置,根据自己需求设置即可:
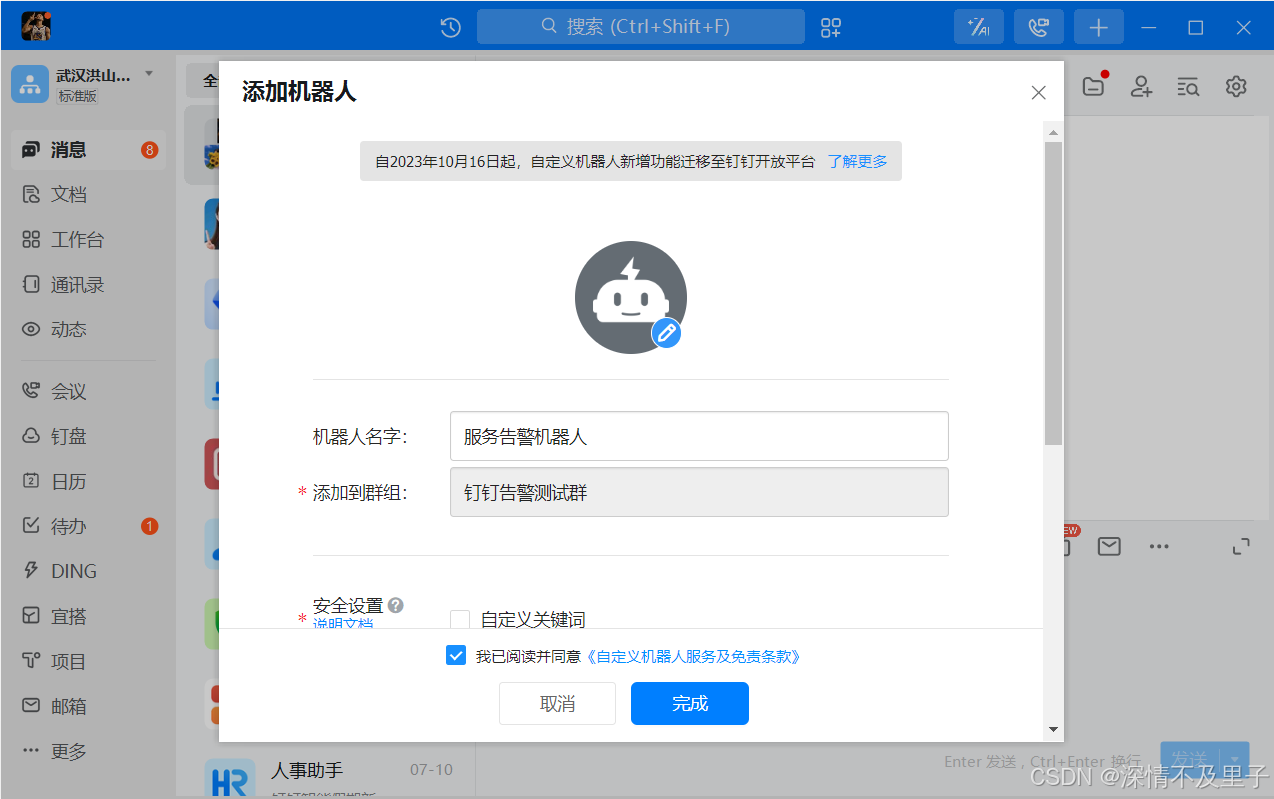
最后就能生成一个webhook地址,在access_token=后面的就是我们需要的token,便于后面在alertmanager中配置使用,需要妥善保管:
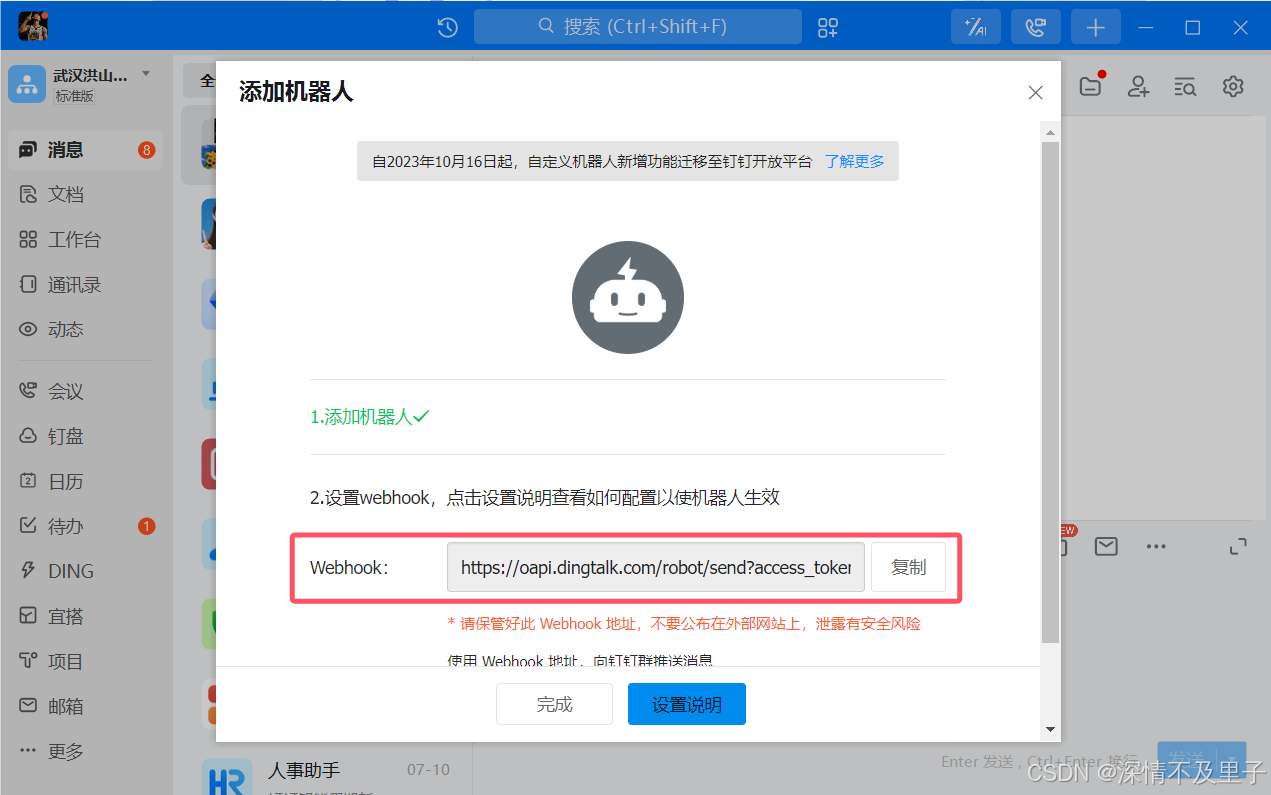
测试 webhook 通信
使用curl命令测试钉钉的 webhook URL,手动发送一个简单的 JSON 请求,以验证钉钉群是否可以接收到消息。例如:
root@master01:/opt/monitor# curl -X POST -H 'Content-Type: application/json' -d '{"msgtype":"text","text":{"content":"这是测试消息"}}' 'https://oapi.dingtalk.com/robot/send?access_token=YOUR_ACCESS_TOKEN'如果钉钉群能收到这条消息,说明 webhook 配置没有问题;如果没有收到,可以检查钉钉机器人的配置设置。
(2)离线安装webhook-dingtalk
将离线安装包上传到服务器上进行解压:
root@master01:/opt/monitor# tar -xvf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
prometheus-webhook-dingtalk-2.1.0.linux-amd64/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/LICENSE
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/templates/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/templates/issue43/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/templates/issue43/template.tmpl
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/templates/legacy/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/templates/legacy/template.tmpl
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/config/
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/config/config.yaml
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/config/template.tmpl
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/deployment.yaml
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/kustomization.yaml
prometheus-webhook-dingtalk-2.1.0.linux-amd64/contrib/k8s/service.yaml
prometheus-webhook-dingtalk-2.1.0.linux-amd64/config.example.yml
prometheus-webhook-dingtalk-2.1.0.linux-amd64/prometheus-webhook-dingtalk
root@master01:/opt/monitor# mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 ./webhook-dingtalk然后配置到系统服务,并配置其中的配置信息,指定钉钉机器人的响应地址:
root@master01:/opt/monitor/webhook-dingtalk# pwd
/opt/monitor/webhook-dingtalk
root@master01:/opt/monitor/webhook-dingtalk# ls -l
总计 18748
-rw-r--r-- 1 3434 3434 1299 4月 21 2022 config.example.yml
drwxr-xr-x 4 3434 3434 4096 4月 21 2022 contrib
-rw-r--r-- 1 3434 3434 11358 4月 21 2022 LICENSE
-rwxr-xr-x 1 3434 3434 19172733 4月 21 2022 prometheus-webhook-dingtalk
drwxr-xr-x 2 3434 3434 4096 9月 2 16:57 webhook-dingtalk
root@master01:/opt/monitor/webhook-dingtalk# cat /etc/systemd/system/webhook-dingtalk.service
[Unit]
Description=https://github.com/timonwong/prometheus-webhook-dingtalk/releases/
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/opt/monitor/webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/opt/monitor/webhook-dingtalk/config.example.yml
[Install]
WantedBy=multi-user.target
root@master01:/opt/monitor/webhook-dingtalk# vi config.example.yml
root@master01:/opt/monitor/webhook-dingtalk# cat config.example.yml
## Request timeout
# timeout: 5s
## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true
## Customizable templates path
#templates:
# - contrib/templates/legacy/template.tmpl
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# secret for signature
secret: SEC000000000000000000000
webhook2:
url: 修改为你的钉钉机器人回调地址
webhook_legacy:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# Customize template content
message:
# Use legacy template
title: '{{ template "legacy.title" . }}'
text: '{{ template "legacy.content" . }}'
webhook_mention_all:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
mention:
all: true
webhook_mention_users:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
mention:
mobiles: ['156xxxx8827', '189xxxx8325']
root@master01:/opt/monitor/webhook-dingtalk# systemctl start webhook-dingtalk.service && systemctl enable webhook-dingtalk.service
Created symlink /etc/systemd/system/multi-user.target.wants/webhook-dingtalk.service → /etc/systemd/system/webhook-dingtalk.service.
root@master01:/opt/monitor/webhook-dingtalk# systemctl status webhook-dingtalk.service
● webhook-dingtalk.service - https://github.com/timonwong/prometheus-webhook-dingtalk/releases/
Loaded: loaded (/etc/systemd/system/webhook-dingtalk.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2024-09-02 17:05:21 CST; 23s ago
Main PID: 104659 (prometheus-webh)
Tasks: 8 (limit: 4546)
Memory: 2.4M
CPU: 8ms
CGroup: /system.slice/webhook-dingtalk.service
└─104659 /opt/monitor/webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/opt/monitor/webhook-dingtalk/config.example.yml
9月 02 17:05:21 master01 systemd[1]: Started https://github.com/timonwong/prometheus-webhook-dingtalk/releases/.
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.557Z caller=main.go:59 level=info msg="Starting prometheus-webhook-dingtalk" version="(version=>
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.557Z caller=main.go:60 level=info msg="Build context" (gogo1.18.1,userroot@177bd003ba4d,date202>
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.557Z caller=coordinator.go:83 level=info component=configuration file=/opt/monitor/webhook-ding>
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.558Z caller=coordinator.go:91 level=info component=configuration file=/opt/monitor/webhook-ding>
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.558Z caller=main.go:97 level=info component=configuration msg="Loading templates" templates=
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.558Z caller=main.go:113 component=configuration msg="Webhook urls for prometheus alertmanager" >
9月 02 17:05:21 master01 prometheus-webhook-dingtalk[104659]: ts=2024-09-02T09:05:21.558Z caller=web.go:208 level=info component=web msg="Start listening for connections" address=:>
服务启动成功后这里生成了一个端口为8060的webhook-dingtalk服务。并且日志中会提示我们怎么去alertmanager配置中配置webhook的url地址:
msg="Webhook urls for prometheus alertmanager" urls="http://localhost:8060/dingtalk/webhook_mention_users/send http://localhost:8060/dingtalk/webhook1/send http://localhost:8060/dingtalk/webhook2/send http://localhost:8060/dingtalk/webhook_legacy/send http://localhost:8060/dingtalk/webhook_mention_all/send"
这里由于我填写是webhook2的url配置,所以后面需要将 http://localhost:8060/dingtalk/webhook2/send填入alertmanager中的webhook_configs.url中。
(3)配置 Alertmanager
在 Alertmanager 的配置文件中,添加 webhook 配置,完成后重启alertmanager服务,检查并确保服务重启成功。
root@master01:/opt/monitor# vi alertmanager/alertmanager.yml
root@master01:/opt/monitor# cat alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '2463252763@qq.com'
smtp_auth_username: '2463252763@qq.com'
smtp_auth_password: 'ajzwsmyrlnnleccd'
smtp_hello: 'qq.com'
smtp_require_tls: false
route:
#这里的标签列表是接收到报警信息后的重新分组标签
group_by: ['alertname','severity']
#当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知
group_wait: 30s
#当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 40s
#如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 30s
#默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: 'dingtalk'
#上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
match:
severity: warning
- receiver: dingtalk
match:
severity: critical
receivers:
- name: 'dingtalk'
webhook_configs:
#- url: 'http://127.0.0.1:5001/'填写webhook-dingtalk的服务信息,这里不能直接用钉钉获取的地址,没用,需要将webhook服务化才行
- url: http://localhost:8060/dingtalk/webhook2/send
send_resolved: true
- name: 'email'
email_configs:
- to: '8888888888@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'severity', 'instance']
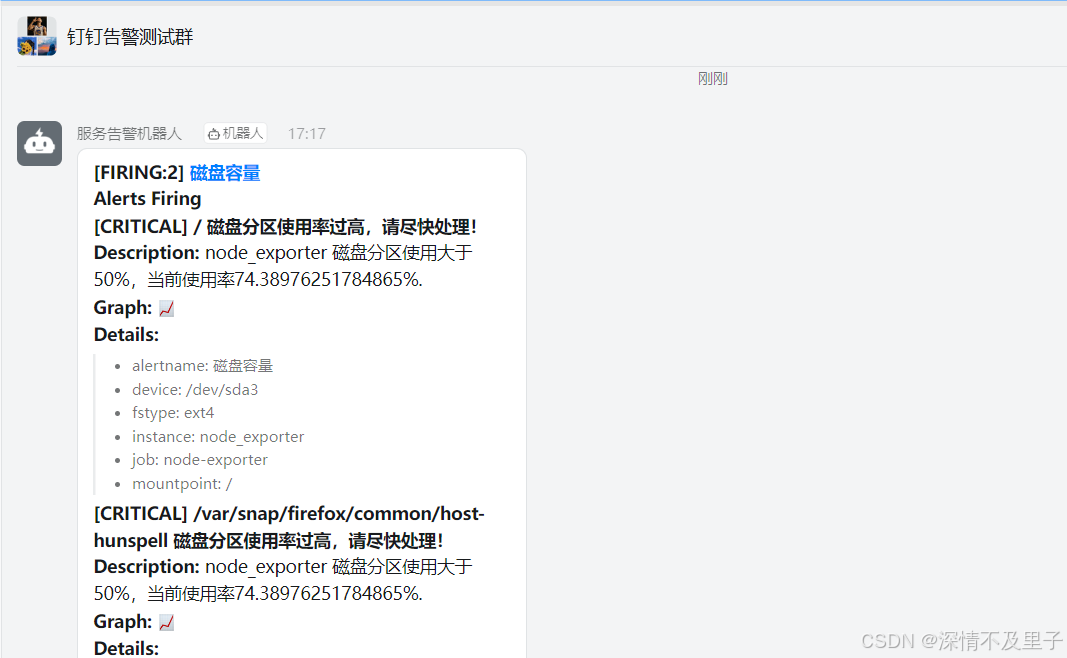
最后当告警信息出来时,钉钉群机器人会进行报警提醒了:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 告警管理大师:深入解析Alertmanager的配置与实战应用

发表评论 取消回复