执行引擎、JIT、逃逸分析
JIT(Just-In-Time,即时编译)
针对的是热点代码(触发JIT的条件)
Client模式:32bit才有
Server模式:64bit
触发条件后,谁来编译,编译线程
C1:Client模式下
C2: Server模式下
JDK6之后,混合在一起,
热点代码((统计的并不是被调用的绝对次数,而是一个相对的执行频率,一段时间内方法被调用的次数))其中包括
- 1.方法
- 2.代码块 循环
Client模式下:1500次执行触发
Server模式下:10000次执行JIT及时编译
JIT的底层实现,达到条件之后会以异步队列的方式Queue封装成VM:Operation入队,然后叫i给VM:Thread:loop
但是热点代码会有一个热度衰减的概念,
比如执行了7000次,在执行3001次之后触发JIT,但是过了1min之后,可能需要执行6501次才可以,相当于1min前的7000次衰减为了3500次
热度衰减的原因:确保是热点代码,不然触发JIT的代码会越来越多
方法调用计数器触发即时编译
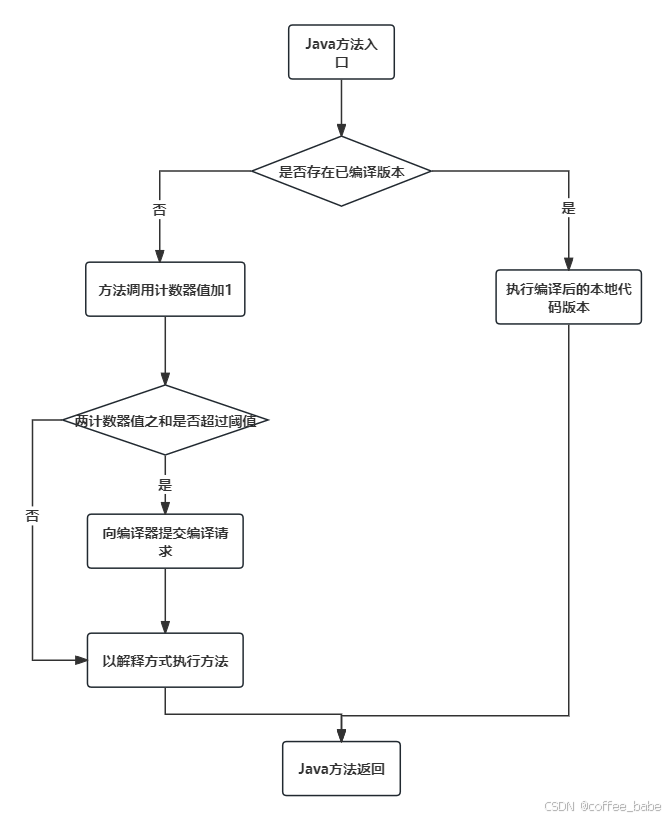
查看及分析即时编译结果(需要开启VM 参数-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompilation -XX:+PrintInlining)
public class JITTest {
public static final int NUM = 15000;
public static int doubleValue(int i) {
// 这个空循环用于后面演示JIT代码优化过程
for (int i1 = 0; i1 < 100000; i1++);
return i * 2;
}
public static long calcSum() {
long sum = 0;
for (int i = 0; i < 100000; i++) {
sum += doubleValue(i);
}
return sum;
}
public static void main(String[] args) {
for (int i = 0; i < NUM; i++) {
calcSum();
}
}
}
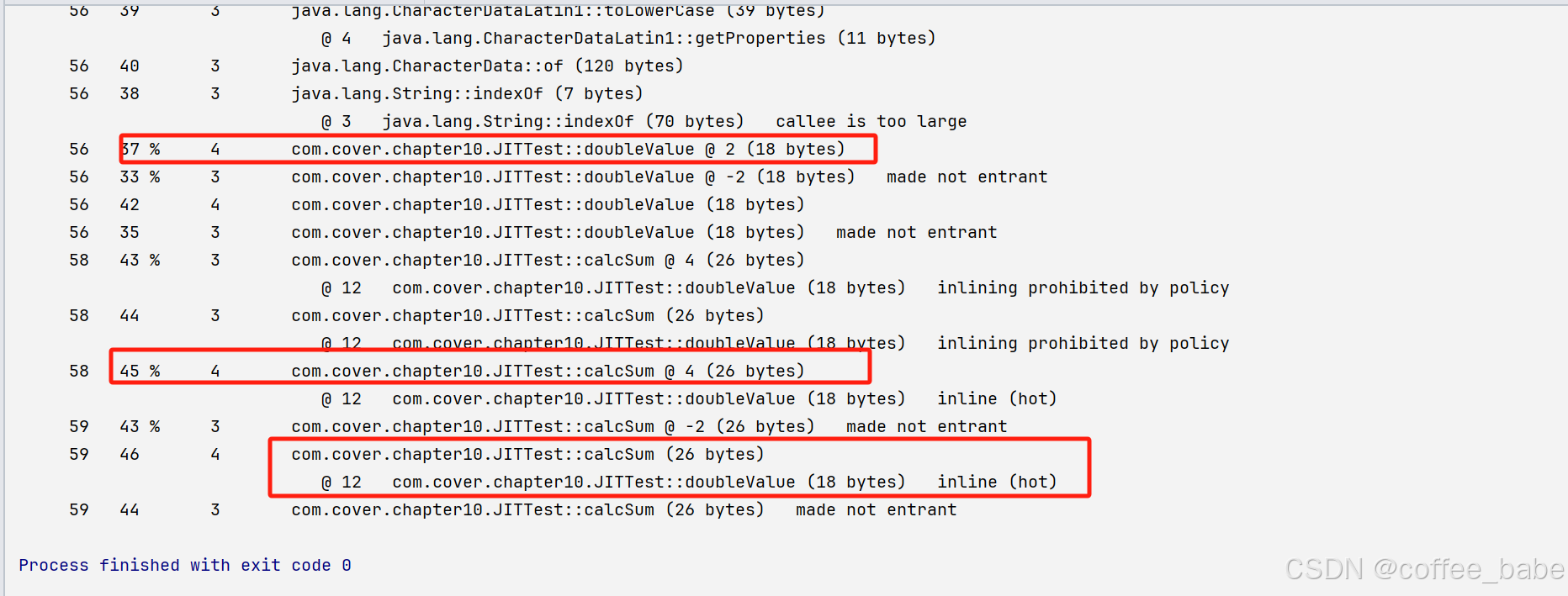
带%的输出说明是由回边计数器触发的即时编译,可以看到calcSum()和doubleValue()方法都已经被即时编译,并且还看到了doubleValue方法已经被内联编译到calcSum()方法中
热点代码缓存区
热点代码缓存时保存在方法区的,这块也是调优需要调的地方
server编译器模式下代码缓存大小起始于2496KB
client编译器模式下代码缓存大小起始于160KB
热机且冷机故障(热机在崩溃的边缘)
新加的机器,流量切过去之后,就挂了。热机运行了很长时间。冷机才刚运行不久。冷机字节码解释器模式,CPU升高就挂了
原因:Java刚启动时,一段时间触发JIT之后,性能才会达到最高。
怎么解决呢?
1.缓缓的切流量,慢慢测
2.加更多的机器。
JIT触发,会将多个执行流合并
逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术,它与类继承关系分析一样,并不是直接优化代码的手段,而是为其他优化手段提供依据的分析技术。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,称为方法逃逸。甚至还有可能被外部线程访问到,比如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。
如果能证明一个对象不会逃逸到方法或线程之外,也就是别的方法或线程无法通过任何途径访问到这个对象,则可能为这个变量进行一些高效的优化,如下所示:
- 1.栈上分配(Stack Allocation)
Java虚拟机中,在Java堆上分配创建对象的内存空间几乎时Java程序员都清除的常识了,Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问堆中存储的对象数据。虚拟机的垃圾收集系统可以回收堆中不再使用的对象,但回收动作无论是筛选可回收对象,还是回收和整理内存都需要耗费时间。如果一个对象不会逃逸出方法之外,那让这个对象在栈上分配内存将会是一个很不错的注意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,不会逃逸的局部对象所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集系统的压力将会小很多。 - 2.同步消除(Syncrhonization Elimination):线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那这个变量的读写肯定就不会有竞争,堆这个变量实施的同步措施也就可以消除掉
- 3.标量替换(Scalar Replacement):标量(Scalar)是指一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型以及类型reference类型等)都不能再进一步分解,它们就可以称为标量。相对的,如果一个数据可以继续分解,那它就称做聚合量(Aggregate),Java中的对象就是最典型的聚合量。如果把一个Java对象拆散,根据程序访问的情况,将其使用到的成员变量恢复原始类型来访问就叫做标量替换。如果逃逸分析证明一个对象不会被外部访问,并且这个对象可以被拆散的话,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,有很大的概率会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可以为后续进一步的优化手段创建条件。
在早期阶段,这项技术还不够成熟,原因主要是不能保证逃逸分析的性能收益必定高于它的消耗。如果要完全准确地判断一个对象是否会逃逸,需要进行数据流敏感的一系列复杂分析,从而确定程序各个分支执行时对此对象的影响。这是一个相对高耗时的过程,如果分析完后发现没有几个不逃逸的对象,那这些运行期好用的时间就白白浪费了。
如何查看
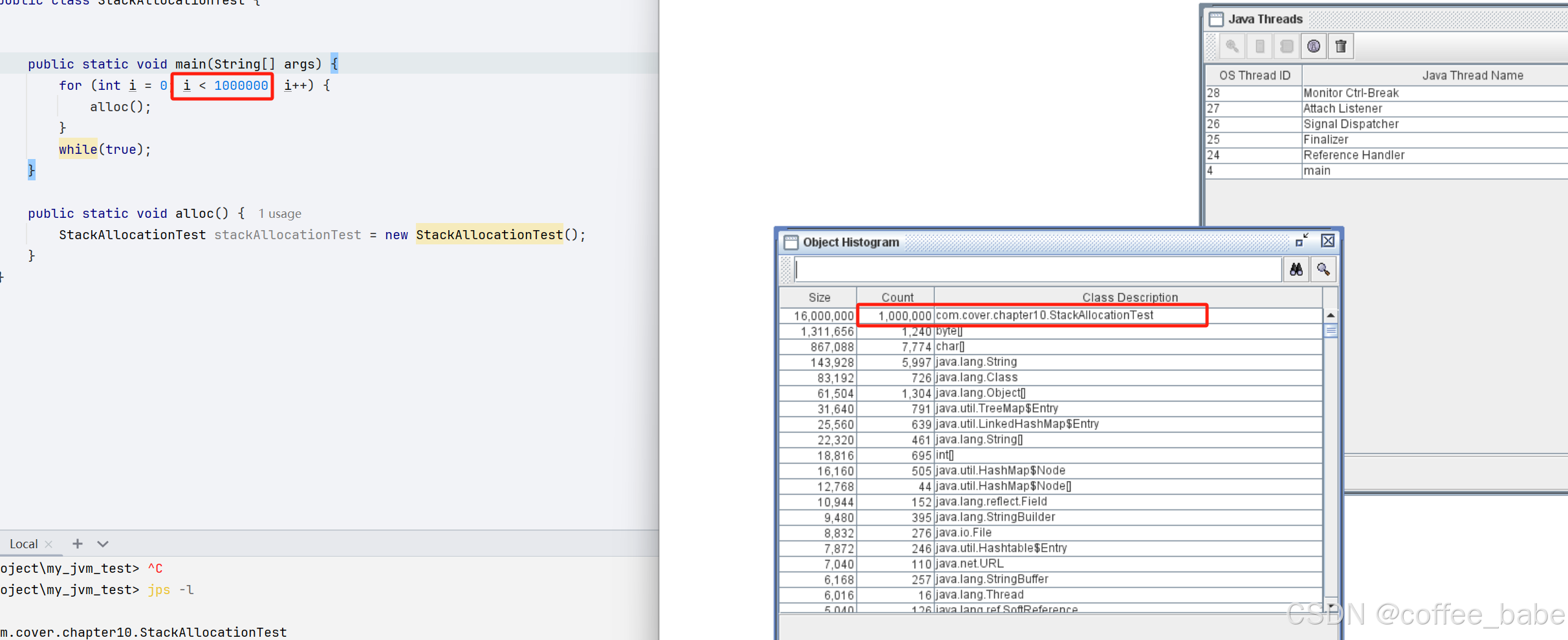
开始栈上分配,创建100w个对象,HSDB查看对象的数量,只有11w个对象
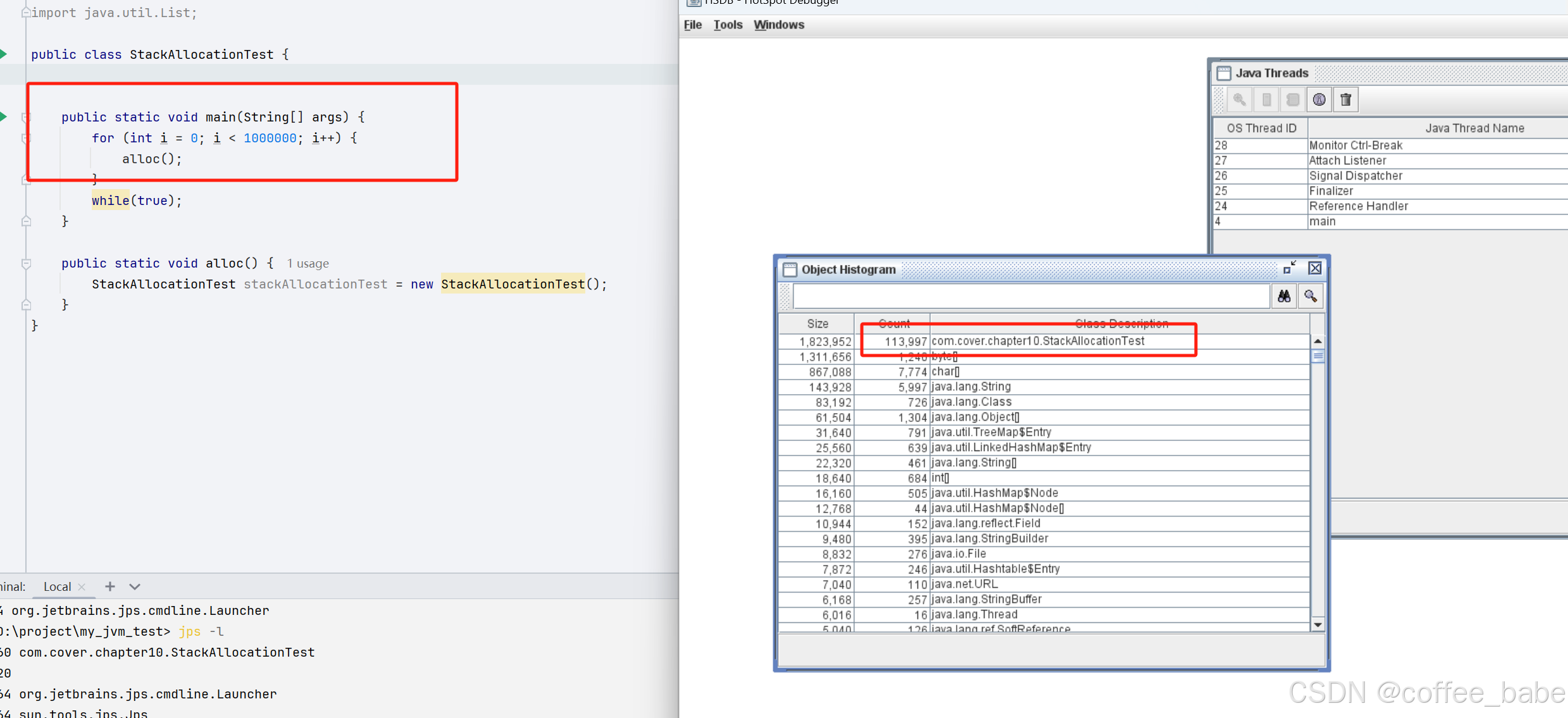
关闭栈上分配
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【JVM】执行引擎、JIT、逃逸分析(二)

发表评论 取消回复