问题描述
今天在调试 Mamba 模型,然后我发现一个很奇怪的现象:如果我指定了 “CUDA:5” 进行调试,程序就会出现如下的报错;但如果我用 “CUDA:0” 运行程序,就能够正常运行,不发生程序报错。
我从张量的维度,张量的数据类型等方面都详细检查过了,同时确保了张量和模型也确实同时在 “CUDA:5” 显卡上,这让我和GPT都一脸懵逼。
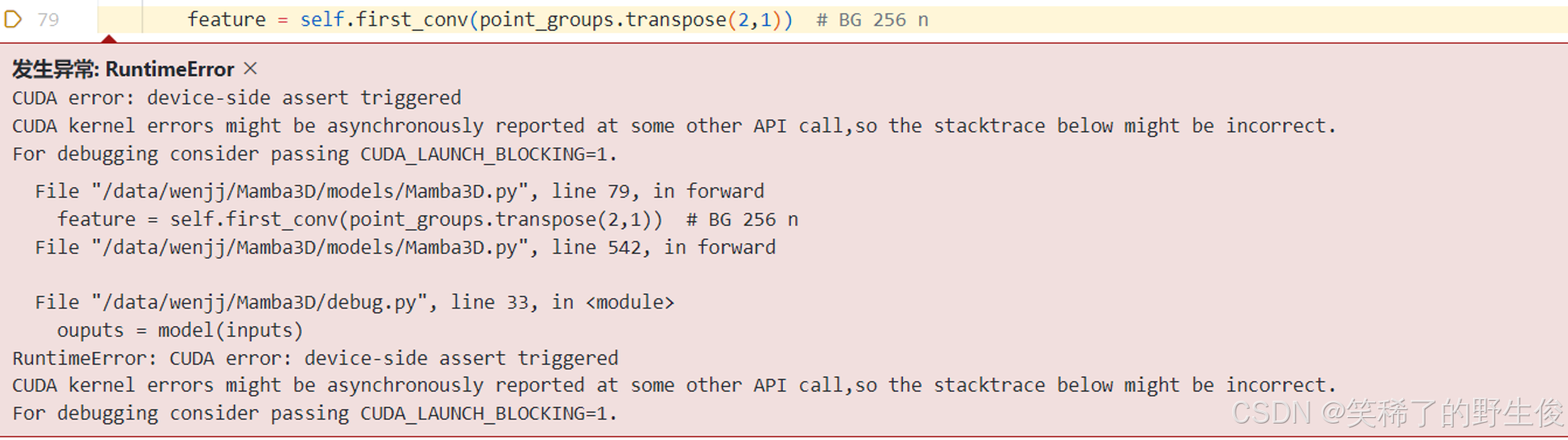

错误代码
我用如下的代码指定当前环境的可见显卡,这样一来,你猜猜我的 inputs 会出现哪张显卡上?
出现在:CUDA0!而非CUDA5!
import torch
import models
import os
os.environ["CUDA_VISIBLE_DEVICES"] ="5"
inputs = torch.randn(2, 1024, 3).cuda()正确代码
正确方法!必须在导入torch前,就设置 CUDA_VISIBLE_DEVICES ,代码如下,否则无效!
确保 os.environ["CUDA_VISIBLE_DEVICES"] = "5" 这一行代码是在导入 PyTorch 或执行任何 CUDA 操作之前设置的。如果已经有其他 CUDA 操作或模块初始化在 CUDA_VISIBLE_DEVICES 之前执行,那么这个环境变量的更改不会生效。
import os
os.environ["CUDA_VISIBLE_DEVICES"] ="5,6"
import torch
import models错因总结
因为我使用了错误代码,因此运行环境仍然对所有显卡都可见,导致某些中间运行结果暂存在 "CUDA:0" 上,这与我的模型 "CUDA:5" 的设备不一致,导致发生错误。
切记!检查环境变量是否生效!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Bug | CUDA | cuDNN error: CUDNN_STATUS_INTERNAL_ERROR

发表评论 取消回复