1. 基本流程
二分类任务决策树流程:决策树:包含 1个根结点、若干个内部结点、若干个叶结点。叶结点对应决策结果,内部结点对应属性测试
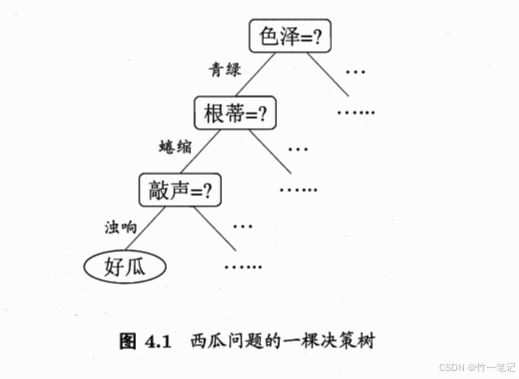
决策树训练过程
- 结点包含的样本同属于同一类别,无需划分
- 属性值完全一致,或者属性集为空(递归边界条件)
- 样本集合为空
对第1、2点区别:
样本同属于同一类别,指的是 D 的 y 值取值相同,此时无需划分
属性值完全一致,但是对应的 y 值可能有多个,此时也无需划分。一个原因导致多个结果,不能界定该原因具体会导致哪个结果
第1点关注的是决策树的目标输出
第2点关注的是输入特征
对于2,可以把当前结点标记为叶结点,将类别 y 设定为 取值最多 的类别(后验分布)
对于3,标记为叶结点,将类别设定为 父结点 所含样本最多的类别(先验分布)
对于3,样本划分过程有空集落入,可能由于:
- 划分过程中,样本被错误分类到其他子节点
- 过程的划分属性或者划分值导致某些子节点没有样本
这样处理是为了使模型处理不完美数据时也能正常工作,并给出合理的预测结果
2. 划分选择
由 决策树学习算法 可知,算法的关键在于第 8 行:如何选择最优属性
随着划分过程不断进行,决策树的分支包含的样本应尽可能属于同一类别,即结点的 纯度 越来越高
2.1 信息增益
信息熵(information entropy):度量样本集合纯度的指标

约定:若 p = 0,则 p l o g 2 p k = 0 plog_2p_k = 0 plog2pk=0
E
n
t
(
D
)
Ent(D)
Ent(D) 的值越小,D 的纯度越高信息增益(information gain):
即
a
∗
=
a
r
g
m
a
x
a
∈
A
G
a
i
n
(
D
,
a
)
a_*= \underset{a\in A}{arg\ max}\ Gain(D, a)
a∗=a∈Aarg max Gain(D,a)
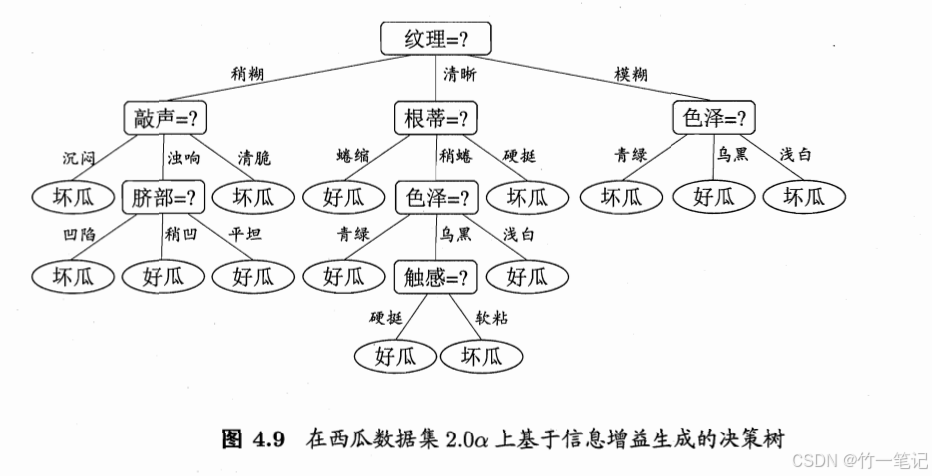
信息增益计算案例:
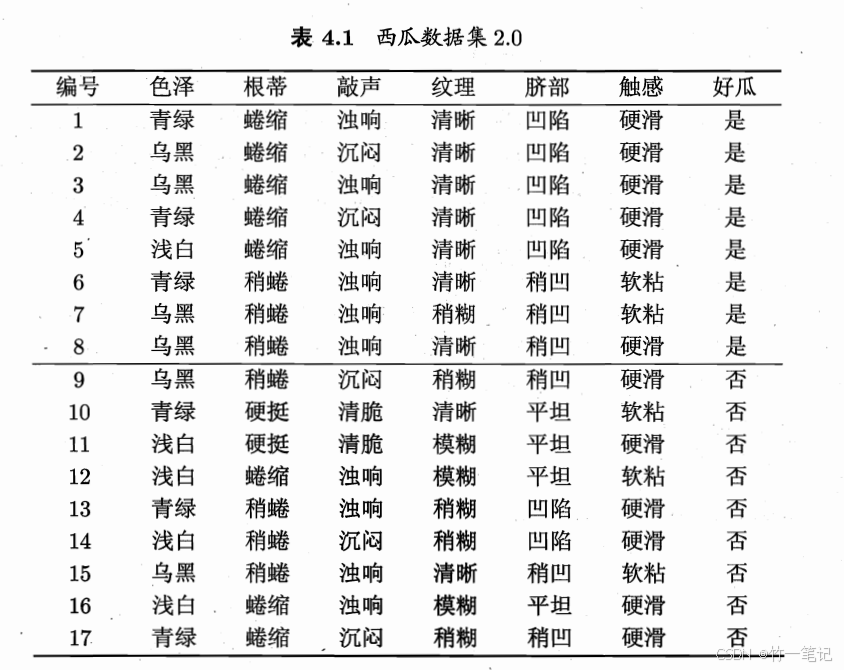




2.2 增益率
信息增益准则对取值数目较多的属性有偏好。例如把上述案例的编号作为划分属性,信息增益远大于其他属性。因为每个编号分支仅对应一个样本,分支结点的纯度最大。但这没有意义增益率:减少信息增益准则对可取值数目较多的属性的偏好带来不利影响增益率 对可取值较少的属性有偏好信息增益 对可取值较多的属性有偏好
可以从划分属性中 找出信息增益高于平均水平的属性,再 从中选出增益率最高的

2.3 基尼系数

3. 剪枝处理
剪枝:对付“过拟合”。过度学习导致决策树分支过多
基本策略:预剪枝、后剪枝
预剪枝:生成决策树过程中,划分结点前先估计。若当前结点的划分不能提升决策树的泛化能力,停止划分并将结点标记为叶结点
后剪枝:生成完决策树,自底向上检察非叶结点。若将该结点对应的子树替换为叶结点能提升泛化性能,则将该子树替换为叶结点
验证方法可使用前面章节提到的 “留出法”,事先预留部分数据作为验证集
3.1 预剪枝
以下为原文:
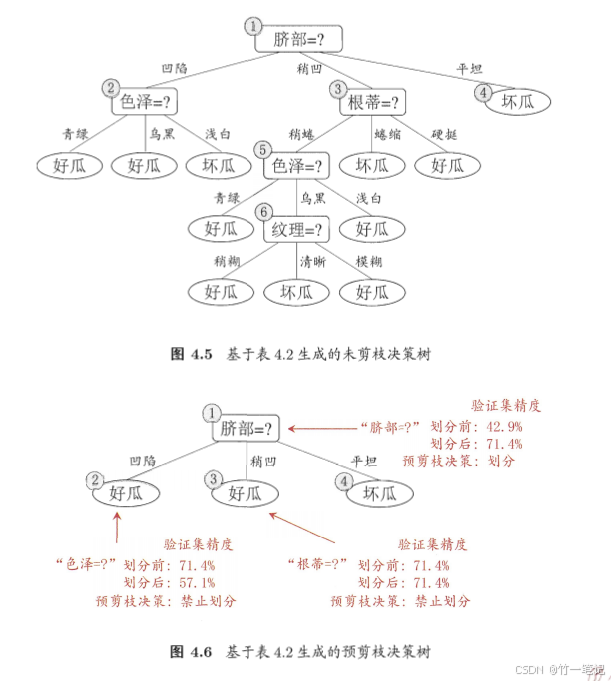


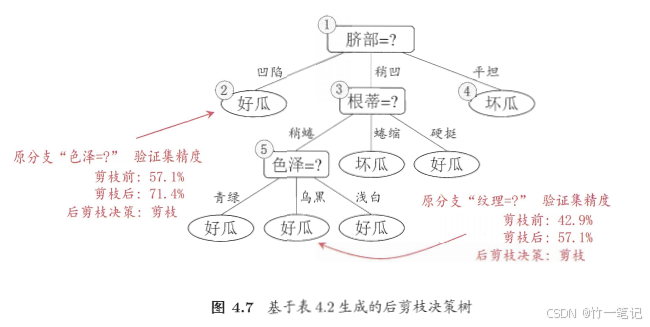
对于结点2,3,4,按脐部的属性凹陷、稍凹、平坦将训练集归类。对于凹陷,1、2、3是好瓜,14是坏瓜。因此把 结点2 暂时判断为 好瓜。对于稍凹,6、7是好瓜,15、17是坏瓜。此时把结点3归纳为好瓜、坏瓜 对验证集精度计算是没有影响的。
如果某个结点划分的子结点,好瓜坏瓜的比例都是50%,验证集精度划不划分都是50%。个人觉得划分好点。可能划分后子结点的子结点能提升验证集精度。可能赚可能不赚,但至少不会亏
3.2 后剪枝


4. 连续与缺失值
4.1 连续值处理
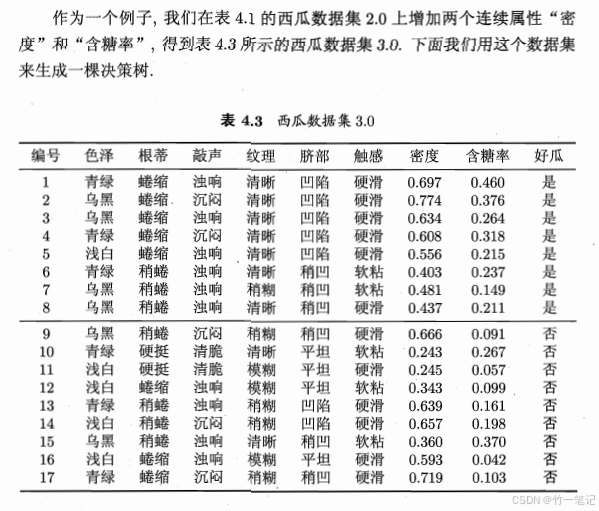
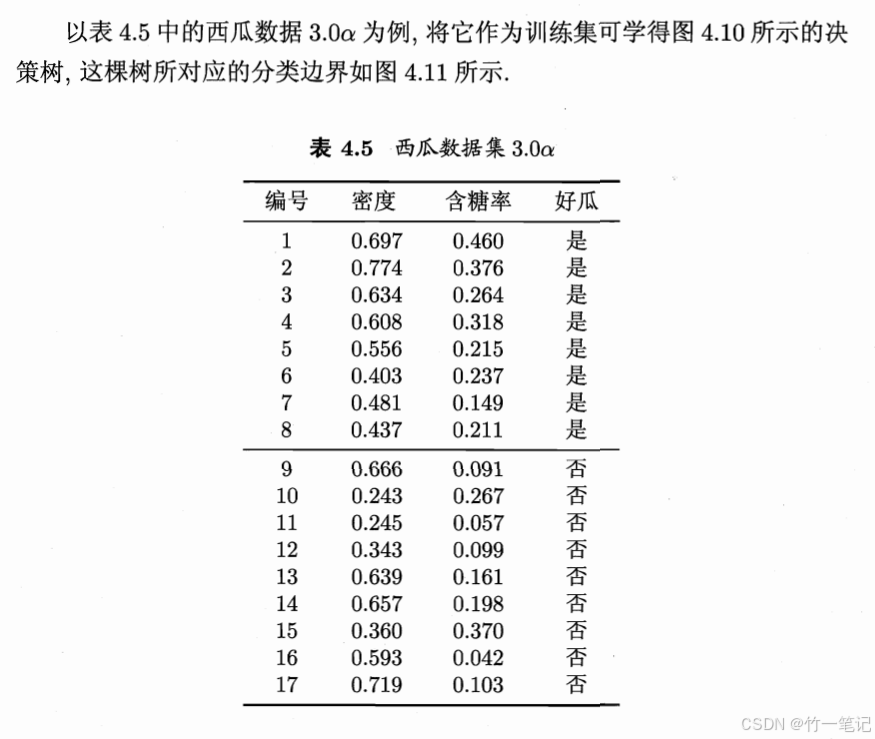
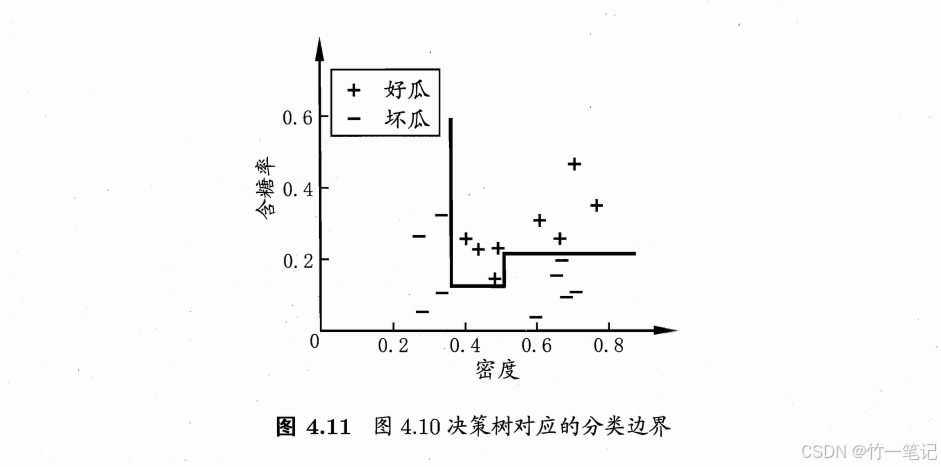
上述例子用到的都是离散属性来生成决策树。在现实学习任务中,常会遇到连续属性。连续属性的可取值数目是无限的,因此可以将 连续属性离散化
关键在于找到划分点 t。以连续值的二分类任务为例:


以下示例:
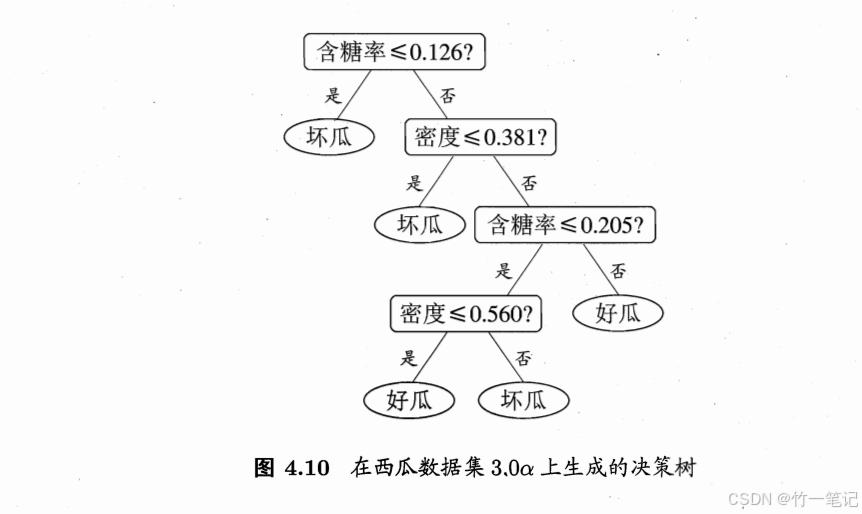
计算 G a i n ( D , a ) Gain(D, a) Gain(D,a),先计算根结点的熵 E n t ( D ) Ent(D) Ent(D) ,17瓜,8好9坏,得 E n t ( D ) = 0.9975 Ent(D) = 0.9975 Ent(D)=0.9975
- 以 t = 0.381 t = 0.381 t=0.381 为例,17个瓜分为2类,
- 小于等于0.381的,4瓜,0好4坏;
- 大于0.381,13瓜,8好5坏;
- 计算 E n t ( D ) Ent(D) Ent(D) 分别为 0,0.9612366。
- G a i n = E n t ( D ) − Σ ∣ D ′ ∣ ∣ D ∣ E n t ( D ′ ) = 0.9975 − ( 0.9612366 ∗ 13 17 + 0 ∗ 4 17 ) = 0.262 Gain = Ent(D) - \Sigma\frac{|D'|}{|D|}Ent(D') = 0.9975 - (0.9612366 * \frac{13}{17} + 0 * \frac{4}{17}) = 0.262 Gain=Ent(D)−Σ∣D∣∣D′∣Ent(D′)=0.9975−(0.9612366∗1713+0∗174)=0.262
计算其他 t,得到的 G a i n Gain Gain 均小于此。所以选择 0.381 作为划分点

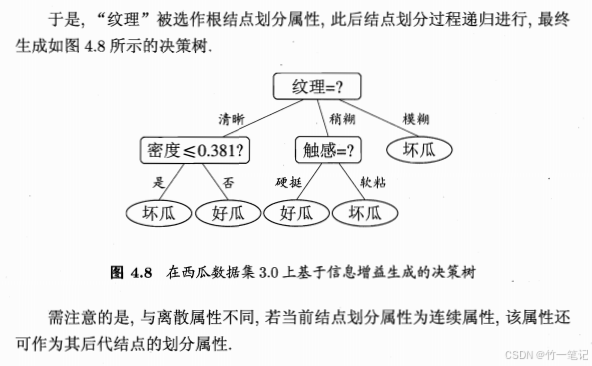
4.2 缺失值处理
将缺失值直接丢弃会造成样本浪费。考虑利用有缺失值的样例进行学习
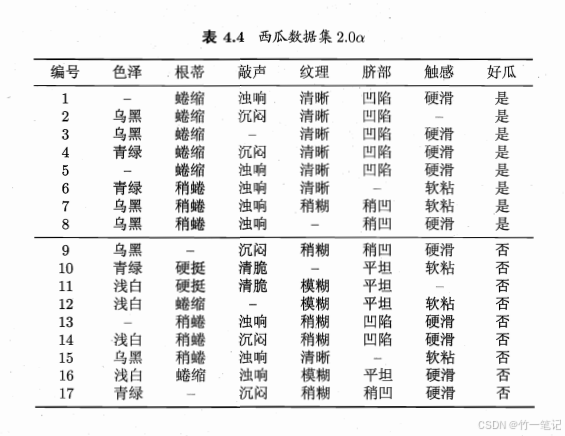
- (1)如何在属性值缺失情况下进行划分属性选择?
- (2)给定划分属性,若样本在该属性上的值缺失,如何样本划分?
对于问题(1)


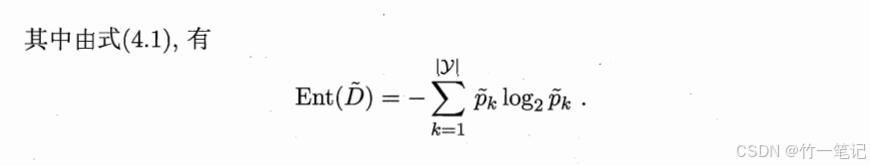
这部分就是把不缺失值的数据集单独拎出来,再计算时加个权重。
划分属性选择缺失值不参与
对于问题(2)

在a属性上的取值是样本在a上的取值,不是样本取值y
以下示例:
ρ \rho ρ : 整个样本集中,无缺失值样本占的比例
p k p_k pk : 无缺失值样本中,某类样本占的比例
r r r :无缺失值样本中,属性某个取值的样本占的比例
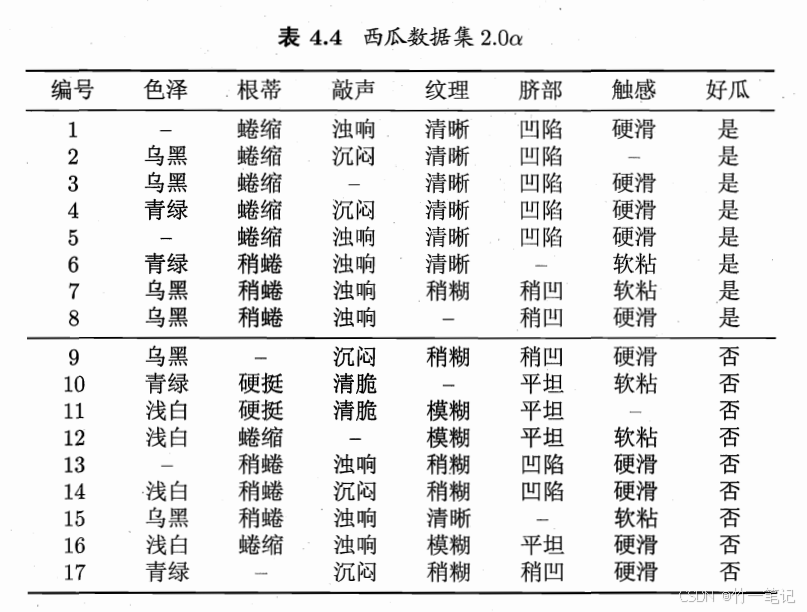



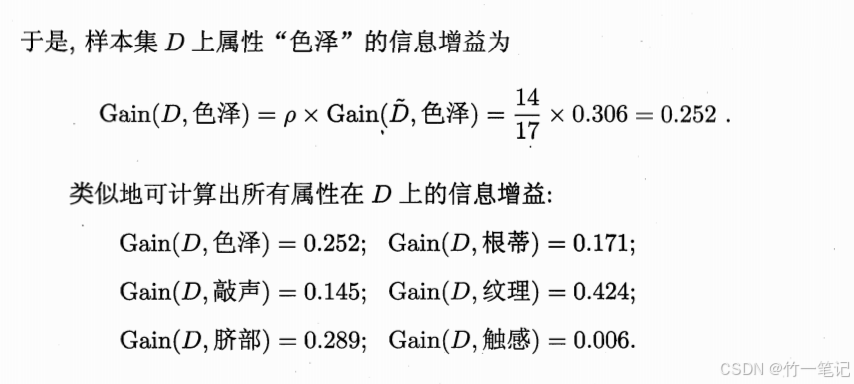

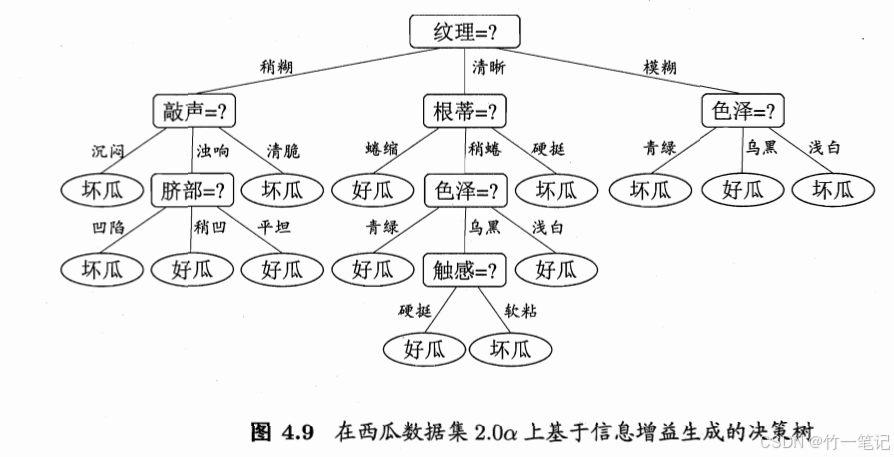
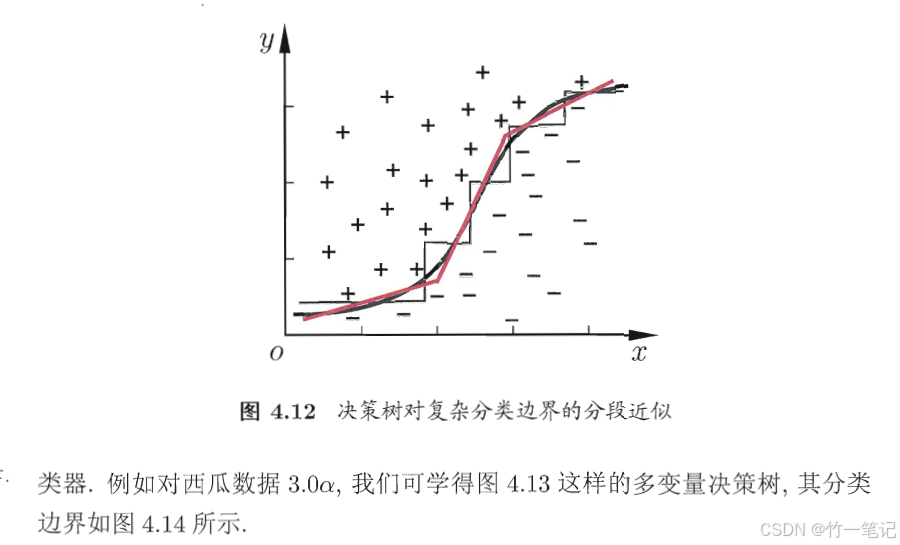
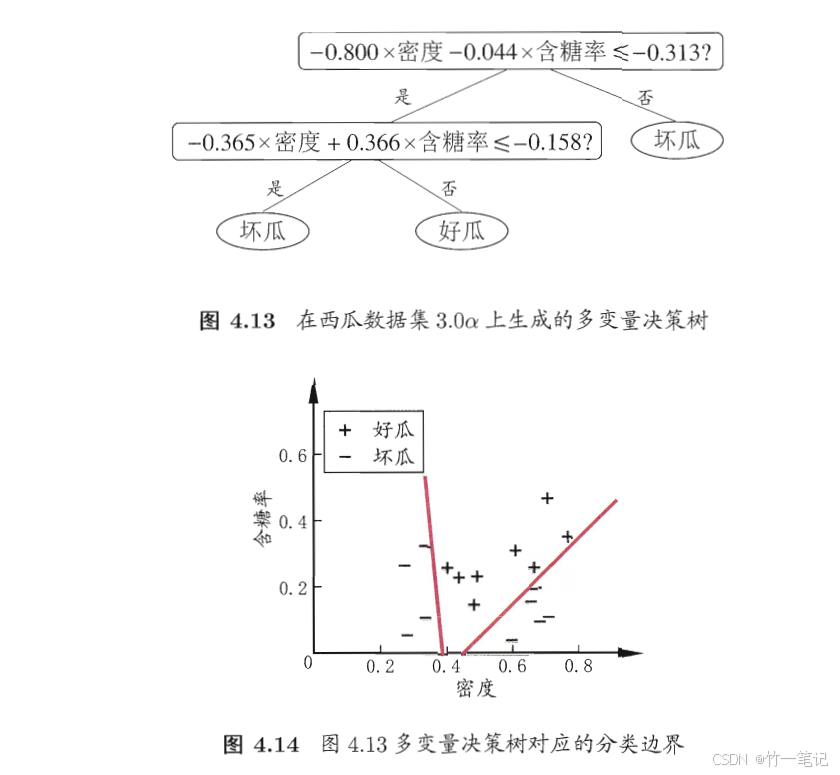
5. 多变量决策树



本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【人工智能 | 机器学习 | 理论篇】决策树(decision tree)

发表评论 取消回复