键空间
Redis 的键是二进制安全的,这意味着你可以使用任何二进制序列作为键,从像 “foo” 这样的字符串到 JPEG 文件的内容,甚至是空字符串也可以作为有效的键。关于键,还有一些其他规则:
- 避免使用过长的键: 例如,一个 1024 字节的键不仅在内存使用上是个坏主意,而且在数据集中查找该键可能需要进行多次代价高昂的键比较。即使任务是检查大值的存在,将其哈希化(例如使用 SHA1)通常也是更好的选择,尤其是从内存和带宽的角度来看。
- 避免使用过短的键: 如果你可以使用 “user:1000:followers” 作为键,那使用 “u1000flw” 这样的键就没什么意义了。前者更具可读性,且增加的空间与键对象和值对象本身所占用的空间相比是微不足道的。虽然短键显然会消耗更少的内存,但你的任务是找到合适的平衡点。
- 遵循一个模式: 例如 “object-type:id” 是一个好的模式,比如 “user:1000”。点或短横线通常用于多词字段,如 “comment:4321:reply.to” 或 “comment:4321:reply-to”。
- 最大允许的键大小为 512 MB。
修改和查询键
有一些命令虽然不是针对特定数据类型定义的,但在与键空间交互时非常有用,因此可以对任何类型的键使用这些命令。例如:
EXISTS命令返回 1 或 0,以指示数据库中是否存在指定的键DEL命令则会删除键及其关联的值,无论该值是什么TYPE命令返回指定键所存储值的类型
键过期
键过期。键过期允许你为一个键设置超时时间,也称为 “生存时间”(TTL)。当生存时间到期时,该键会自动销毁。关于键过期,有几点重要说明:
- 过期时间可以以秒或毫秒精度设置。
- 但是,过期时间的分辨率始终为 1 毫秒。
- 过期信息会被复制并持久化到磁盘上,当你的 Redis 服务器停止时,时间实际上仍然在流逝(这意味着 Redis 保存了键到期的日期)。
使用 EXPIRE 命令可以为键设置过期时间:
> set key some-value
OK
> expire key 5
(integer) 1
> get key (immediately)
"some-value"
> get key (after some time)
(nil)
在上述示例中,键在两个 GET 调用之间消失了,因为第二次调用的时间延迟超过了 5 秒。在这个例子中,我们使用 EXPIRE 来设置过期时间(它也可以用于为已经有过期时间的键设置不同的过期时间,像 PERSIST 可以用来移除过期时间,使键永久存在)。然而,我们也可以使用其他 Redis 命令来创建带有过期时间的键。例如使用 SET 选项:
> set key 100 ex 10
OK
> ttl key
(integer) 9
上述例子设置了一个键,其字符串值为 100,过期时间为 10 秒。随后,使用 TTL 命令检查该键剩余的生存时间。
要以毫秒为单位设置和检查过期时间,可以使用 PEXPIRE 和 PTTL 命令,并查看 SET 命令的完整选项列表。
遍历键空间
为了以一种高效的方式逐步迭代 Redis 数据库中的键,你可以使用 SCAN 命令。由于 SCAN 允许逐步迭代,每次仅返回少量元素,因此它可以在生产环境中使用,而不会像 KEYS 或 SMEMBERS 命令那样对大量键或元素的集合调用时会阻塞服务器很长时间(甚至几秒钟)。另一种遍历键空间的方法是使用 KEYS 命令,但是应该谨慎使用这种方法,因为 KEYS 会阻塞 Redis 服务器直到返回所有键。当对大型数据库执行 KEYS 命令时,可能会影响性能。此命令仅用于调试和特殊操作,例如更改键空间布局。不要在常规应用程序代码中使用 KEYS。 KEYS 命令支持的 glob 风格模式:
h?llo匹配hello、hallo和hxlloh*llo匹配hllo和heeeelloh[ae]llo匹配hello和hallo,但不匹配hilloh[^e]llo匹配hallo、hbllo,但不匹配helloh[a-b]llo匹配hallo和hbllo- 如果要匹配特殊字符,请使用
\进行转义。
客户端缓存
通常,当需要数据时,应用服务器会向数据库查询所需信息,如下图所示:
+-------------+ +----------+
| | ------- GET user:1234 -------> | |
| Application | | Redis |
| | <---- username = Alice ------- | |
+-------------+ +----------+
当使用缓存时,应用程序会直接将常用查询的响应存储在内存中,以便以后可以重复使用这些响应,而无需再次联系数据库:
+-------------+ +----------+
| | | |
| Application | ( No chat needed ) | Redis |
| | | |
+-------------+ +----------+
| Local cache |
| |
| user:1234 = |
| username |
| Alice |
+-------------+
尽管用于本地缓存的应用程序内存可能不是很大,但访问本地计算机内存所需的时间比访问像数据库这样的网络服务的时间要小几个数量级。此外,许多数据集中的项目变化非常少。例如,社交网络中的大多数用户帖子要么是不可变的,要么很少被用户编辑。再加上通常只有很小一部分帖子非常受欢迎,要么是因为少数用户有很多关注者,要么是因为最近的帖子有更多的可见性,这就很容易理解为什么这种模式非常有用。通常客户端缓存的两个关键优势是:
- 数据延迟低
- 有效减少数据库压力
在计算机科学中有两个难题
上述模式的一个问题是如何使应用程序所持有的信息失效,以避免向用户呈现陈旧的数据。例如,在上述应用程序本地缓存了用户 user:1234 的信息后,Alice 可能会将她的用户名更新为 Flora。然而,应用程序可能会继续为用户 user:1234 提供旧的用户名。有时,根据我们建模的确切应用程序,这并不是一个大问题,因此客户端将只使用固定的最大“存活时间”来缓存信息。一旦经过了一定的时间,信息就不再被视为有效。更复杂的模式,在使用 Redis 时,利用 Pub/Sub 系统向正在监听的客户端发送失效消息。这样做可能行得通,但从带宽使用的角度来看,它是棘手和昂贵的,因为通常这种模式涉及将失效消息发送给应用程序中的每个客户端,即使某些客户端可能没有任何失效的数据副本。此外,每个修改数据的应用程序查询都需要使用 PUBLISH 命令,这会导致数据库更多的 CPU 时间来处理此命令。无论使用什么方案,有一个简单的事实:许多非常大的应用程序都实现了某种形式的客户端缓存,因此,Redis 6 实现了对客户端缓存的直接支持,以使这种模式更容易实现、更易于访问、更可靠和更高效。
客户端缓存的Redis实现
Redis 的客户端缓存支持被称为 Tracking(跟踪),并且具有两种模式:
- 默认模式:在这种模式下,服务器会记住给定客户端访问过的键,并在这些键被修改时发送失效消息。这种方式在服务器端会消耗内存,但只对客户端可能在内存中存储的键集合发送失效消息。
- 广播模式:在这种模式下,服务器不会试图记住客户端访问了哪些键,因此这种模式在服务器端不消耗任何内存。相反,客户端订阅类似于
object:或user:的键前缀,每当匹配的键被操作时,客户端都会收到通知消息。
我们暂且不讨论广播模式,重点关注第一种模式,稍后会更详细地介绍广播模式。
跟踪模式的工作机制
- 客户端可以根据需要启用跟踪。连接开始时默认未启用跟踪。
- 当启用跟踪时,服务器会在连接期间记住每个客户端请求的键(通过发送关于这些键的读取命令)。
- 当某个键被其他客户端修改、因到期时间而被驱逐或因最大内存策略而被驱逐时,所有启用了跟踪且可能缓存了该键的客户端都会收到失效消息。
- 当客户端接收到失效消息时,它们需要移除相应的键,以避免提供过期的数据。
客户端 1 -> 服务器: CLIENT TRACKING ON
客户端 1 -> 服务器: GET foo
(服务器记住客户端 1 可能缓存了键 "foo")
(客户端 1 可能会在本地内存中存储 "foo" 的值)
客户端 2 -> 服务器: SET foo SomeOtherValue
服务器 -> 客户端 1: INVALIDATE "foo"
表面上看,这种机制非常有效,但如果有 10,000 个客户端连接,每个客户端都在长时间连接期间请求了数百万个键,服务器最终会存储过多的信息。为了解决这个问题,Redis 使用了两个关键概念来限制服务器端内存的使用和处理数据结构的 CPU 成本:
- 失效表(Invalidation Table):服务器在一个全局表中记住可能缓存了给定键的客户端列表。该表可以包含的最大条目数是有限的。如果插入了一个新键,服务器可能会通过假装该键已被修改(即使实际上没有被修改)并向客户端发送失效消息的方式驱逐一个旧条目,从而回收该键使用的内存,即使这会迫使拥有该键本地副本的客户端将其移除。
- 客户端 ID 存储:在失效表中,我们无需存储指向客户端结构的指针,这样会在客户端断开连接时强制进行垃圾收集操作。相反,我们只存储客户端 ID(每个 Redis 客户端都有一个唯一的数字 ID)。如果客户端断开连接,这些信息将在缓存槽位失效时逐步被垃圾回收。
统一的键命名空间
Redis 采用统一的键命名空间,不按数据库编号区分。因此,如果一个客户端在数据库 2 中缓存了键 foo,而另一个客户端在数据库 3 中更改了键 foo 的值,失效消息仍会被发送。通过这种方式,我们可以忽略数据库编号,从而减少内存使用并降低实现的复杂性。
两种连接方式
在 Redis 6 中,使用支持 RESP3 协议的新版本 Redis 协议,可以在同一个连接中运行数据查询并接收失效消息。然而,许多客户端实现可能更喜欢使用两个单独的连接来实现客户端缓存:一个用于数据,一个用于失效消息。为此,当客户端启用跟踪时,可以指定将失效消息重定向到另一个连接,方法是指定不同连接的 “client ID”。多个数据连接可以将失效消息重定向到同一个连接,这对于实现连接池的客户端非常有用。对于 RESP2 协议(它不支持在同一个连接中多路复用不同类型的信息)。以下是一个使用旧 RESP2 模式的 Redis 协议的完整会话示例:
-
启动用于失效消息的连接:
首先,客户端打开一个用于接收失效消息的连接,获取连接 ID,并通过 Pub/Sub 订阅一个特殊的频道,以便在 RESP2 模式下接收失效消息(请注意,RESP2 是常规的 Redis 协议,而不是可以选择性地与 Redis 6 一起使用的更高级的 RESP3 协议)。
(连接 1 -- 用于失效消息) CLIENT ID :4 SUBSCRIBE __redis__:invalidate *3 $9 subscribe $20 __redis__:invalidate :1 -
启用数据连接的跟踪功能并重定向消息:
现在,我们可以从数据连接启用跟踪功能:
(连接 2 -- 数据连接) CLIENT TRACKING on REDIRECT 4 +OK GET foo $3 bar客户端可能决定将
"foo"=>"bar"缓存在本地内存中。 -
修改键的值:
另一个不同的客户端将修改
"foo"键的值:(其他未关联的连接) SET foo bar +OK -
接收失效消息:
结果是,用于接收失效消息的连接会收到一条使指定键失效的消息。
(连接 1 -- 用于失效消息) *3 $7 message $20 __redis__:invalidate *1 $3 foo客户端将检查此缓存槽位中是否有缓存键,并清除不再有效的信息。
缓存策略
在 Redis 的客户端缓存机制中,默认情况下,客户端不需要明确告诉服务器它们正在缓存哪些键。当一个键在只读命令的上下文中被提及时,服务器会自动跟踪这个键,因为它可能被缓存。这种机制的主要优点是不需要客户端告知服务器它正在缓存什么。对于许多客户端实现来说,这种方式非常理想,因为一个好的解决方案可能是缓存所有未被缓存的内容,使用先进先出(FIFO)策略:我们可能希望缓存固定数量的对象,每次获取新数据时,将其缓存,并丢弃最旧的缓存对象。更高级的实现可能会丢弃最少使用的对象或类似的策略。然而,如果服务器上存在写流量,缓存槽会随着时间的推移而失效。一般来说,当服务器假设我们获取的数据也会被缓存时,我们是在做出一个权衡:
- 更高效的缓存策略:当客户端倾向于缓存许多内容并采用欢迎新对象的策略时,这种机制更加高效。
- 服务器负担增加:服务器将被迫保留更多关于客户端键的数据,从而增加服务器的负担。
- 可能收到无用的失效消息:客户端可能会收到关于它未缓存对象的无用失效消息,这会增加通信成本。
Opt-in 模式
客户端实现可能只希望缓存某些特定的键,并明确告知服务器哪些键会缓存,哪些不会。这需要在缓存新对象时使用更多带宽,但同时减少了服务器需要记住的数据量和客户端收到的无效化消息的数量。为此,必须使用 OPTIN 选项启用跟踪:
CLIENT TRACKING ON REDIRECT 1234 OPTIN
在这种模式下,默认情况下,读取查询中的键不会被缓存。客户端需要在获取数据的命令之前,先发送一个特殊命令来指定要缓存的键:
CLIENT CACHING YES
+OK
GET foo
"bar"
CACHING 命令只影响紧接其后的命令。如果下一个命令是 MULTI,事务中的所有命令都会被跟踪。Lua 脚本中的所有命令也会被跟踪。
Opt-out 模式
Opt-out 模式允许客户端自动在本地缓存键,而无需对每个键显式选择加入。这种方法确保所有键默认被缓存,除非另有说明。Opt-out 模式可以简化客户端缓存的实现,减少为每个键启用缓存所需的显式命令。要启用Opt-out 模式,必须使用 OPTOUT 选项启用跟踪:
CLIENT TRACKING ON OPTOUT
如果要排除特定的键不被跟踪和缓存,可以使用 CLIENT UNTRACKING 命令:
CLIENT UNTRACKING key
广播模式
广播模式不在服务器端消耗任何内存,但会向客户端发送更多的无效化消息。在这种模式下,我们有以下主要行为:
- 客户端使用
BCAST选项启用客户端缓存,并通过PREFIX选项指定一个或多个前缀。例如:CLIENT TRACKING on REDIRECT 10 BCAST PREFIX object: PREFIX user:。如果没有指定前缀,则假定前缀为空字符串,客户端将接收每个被修改的键的无效化消息。如果使用一个或多个前缀,则只有匹配指定前缀的键才会在无效化消息中发送。 - 服务器不会在无效化表中存储任何内容。相反,它使用一个不同的前缀表,其中每个前缀都与一个客户端列表相关联。
- 不能有两个前缀跟踪重叠的键空间部分。例如,前缀 “foo” 和 “foob” 是不允许的,因为它们都会触发对键 “foobar” 的无效化。然而,仅使用前缀 “foo” 就足够了。
- 每次修改匹配任意前缀的键时,所有订阅该前缀的客户端将收到无效化消息。
- 服务器的 CPU 使用量与注册的前缀数量成正比。如果前缀很少,差异不大。但如果前缀数量很多,CPU 消耗可能会变得很大。
- 在这种模式下,服务器可以优化为所有订阅了某个前缀的客户端创建一个统一的回复,并将相同的回复发送给所有客户端。这有助于降低 CPU 使用率。
NOLOOP选项
默认情况下,客户端侧跟踪会将无效化消息发送到修改了键的客户端。有时候客户端需要这种行为,因为它们实现的逻辑非常基础,不涉及自动在本地缓存写入。然而,更高级的客户端可能希望在本地内存表中缓存它们所做的写入。在这种情况下,收到写入后的无效化消息会成为一个问题,因为这会迫使客户端清除刚刚缓存的值。
在这种情况下,可以使用 NOLOOP 选项:它在正常模式和广播模式下都有效。使用此选项,客户端可以告诉服务器它们不希望接收自己修改的键的无效化消息。
避免竟态条件
在实现客户端侧缓存并将无效化消息重定向到不同的连接时,需要注意可能出现的竞态条件。以下是一个示例交互,其中我们将数据连接称为 “D”,无效化连接称为 “I”:
[D]客户端 -> 服务器:GET foo[I]服务器 -> 客户端: 无效化foo(其他人修改了它)[D]服务器 -> 客户端:"bar"(GET foo的回复)
如您所见,由于 GET 请求的回复比无效化消息到达客户端的时间要慢,我们先收到了无效化消息,然后才是已不再有效的数据。因此,我们会继续提供一个过时的 foo 键的值。为避免这种问题,建议在发送命令时用占位符填充缓存:
- 客户端缓存: 将
foo的本地副本设置为"caching-in-progress" [D]客户端 -> 服务器:GET foo[I]服务器 -> 客户端: 无效化foo(其他人修改了它)- 客户端缓存: 从本地缓存中删除
foo [D]服务器 -> 客户端:"bar"(GET foo的回复)- 客户端缓存: 不设置
"bar",因为foo的条目已缺失
当使用单一连接处理数据和无效化消息时,由于消息的顺序总是已知的,因此不会出现这种竞态条件。
当与服务器失去连接怎么办
同样地,如果我们丢失了用于接收无效化消息的连接,我们可能会面临过时的数据。为了避免这个问题,需要做以下几件事:
- 确保如果连接丢失,本地缓存被清空。
- 无论是使用 RESP2 的 Pub/Sub 还是 RESP3,都要定期对无效化频道发送 PING 命令(即使在 Pub/Sub 模式下也可以发送 PING 命令!)。如果连接看起来断开并且无法接收到 PING 的回响,在最大时间后关闭连接并清空缓存。
什么值得缓存
客户端可能希望运行内部统计,以了解某个缓存的键在请求中被实际服务的次数,以便未来了解哪些内容值得缓存。一般来说:
- 我们不想缓存那些持续变化的键。
- 我们不想缓存那些请求非常少的键。
- 我们希望缓存那些被频繁请求且变化速度适中的键。例如,变化速度过快的键可能是一个持续增加的全局计数器。
然而,更简单的客户端可能仅通过随机抽样来驱逐数据,只记录某个缓存值最后一次被服务的时间,尝试驱逐那些最近没有被服务的键。
流水线
请求/响应协议和往返时间(RTT)
Redis 是一个使用客户端-服务器模型和请求/响应协议的 TCP 服务器。这意味着通常一个请求的处理步骤如下:
- 客户端向服务器发送查询,并通常以阻塞方式从套接字读取服务器的响应。
- 服务器处理命令并将响应发送回客户端。
例如,一系列四个命令的操作如下:
客户端:INCR X
服务器:1
客户端:INCR X
服务器:2
客户端:INCR X
服务器:3
客户端:INCR X
服务器:4
客户端和服务器通过网络连接。这样的连接可以非常快(如回环接口)或非常慢(例如,通过互联网建立的连接,两个主机之间有多个跳数)。无论网络延迟是多少,从客户端到服务器的数据包传输时间,以及从服务器到客户端的回复传输时间,都是有限的。这个时间被称为 RTT(往返时间)。当客户端需要连续执行多个请求时(例如,向同一个列表添加多个元素,或向数据库中填充多个键),这将影响性能。例如,如果 RTT 时间为 250 毫秒(在非常慢的互联网连接中),即使服务器能够处理每秒 100k 个请求,我们也只能每秒处理最多四个请求。如果使用的是回环接口,则 RTT 会短得多,通常为亚毫秒级,但如果需要连续执行许多写操作,这种延迟也会累积。 幸运的是,有一种方法可以改善这种情况。
Redis管道
请求/响应服务器可以实现一种机制,使其能够处理新的请求,即使客户端尚未读取旧的响应。这使得客户端可以在不等待回复的情况下,发送多个命令到服务器,并最终在一个步骤中读取所有的回复。
这种机制称为流水线(pipelining),这是一个已经使用了几十年的技术。例如,许多 POP3 协议实现已经支持这一功能,显著加快了从服务器下载新邮件的过程。
Redis 从早期版本就支持流水线,因此无论你使用的是哪个版本,都可以使用流水线。以下是使用原始的 netcat 工具进行的一个示例:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
在这种情况下,我们不需要为每个调用支付 RTT(往返时间)的成本,而是仅为这三个命令支付一次 RTT 成本。
具体来说,使用流水线的操作顺序如下:
- 客户端发送命令:
INCR XINCR XINCR XINCR X
- 服务器处理命令并发送响应:
1234
注意:虽然客户端使用流水线发送命令时,服务器必须使用内存排队回复。因此,如果需要发送大量命令,最好将它们分批发送,每批包含一个合理的数量,例如 10,000 个命令,然后读取回复,再发送下一批 10,000 个命令。速度将几乎相同,但额外使用的内存最多为排队这些 10,000 个命令的回复所需的内存。
这不仅仅是RTT的问题
流水线不仅仅是一种减少往返时间(RTT)相关延迟成本的方法,它实际上可以大大提高在给定 Redis 服务器上每秒可以执行的操作数量。这是因为,如果不使用流水线,服务每个命令从访问数据结构和生成回复的角度来看是非常便宜的,但从进行套接字 I/O 的角度来看则非常昂贵。这涉及到调用 read() 和 write() 系统调用,即从用户空间到内核空间的转换。上下文切换是一个巨大的速度开销。
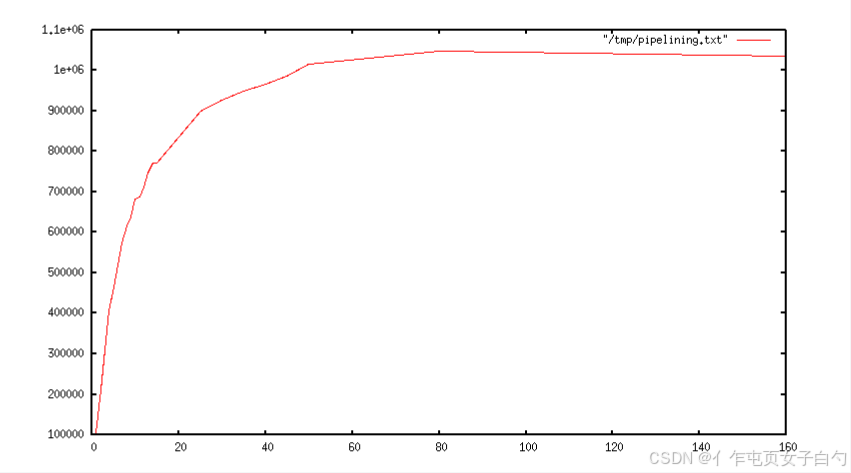
当使用流水线时,通常可以通过一次 read() 系统调用读取多个命令,并通过一次 write() 系统调用发送多个回复。因此,总的查询每秒执行的数量最初会随着流水线的增加而几乎线性增长,最终达到没有使用流水线时的 10 倍,如下图所示:
流水线VS脚本
自 Redis 2.6 起,引入的 Redis 脚本功能可以更高效地处理许多流水线的用例。脚本的一个大优点是能够在服务器端执行大量工作,减少延迟,使得像读取、计算和写入这样的操作非常快速(因为流水线无法在这种情况下提供帮助,因为客户端需要在调用写入命令之前获得读取命令的回复)。
有时,应用程序可能还希望在流水线中发送 EVAL 或 EVALSHA 命令。这完全是可能的,Redis 通过 SCRIPT LOAD 命令显式支持这一点(它确保 EVALSHA 可以在没有失败风险的情况下调用)。
为什么在一台机器上进行死循环测试依旧很慢
即使在本页面中介绍了所有背景知识,你可能仍然会感到困惑:即使在回环接口上运行且服务器和客户端都在同一台物理机器上,为什么如下的 Redis 基准测试(伪代码)运行依然很慢:
FOR-ONE-SECOND:
Redis.SET("foo", "bar")
END
毕竟,如果 Redis 进程和基准测试都在同一台机器上运行,这不只是将消息从一个地方复制到另一个地方,不涉及实际的延迟或网络传输吗?原因在于系统中的进程并不总是运行,实际上是内核调度器决定进程何时运行。例如,当基准测试运行时,它读取 Redis 服务器的回复(与最后执行的命令相关),并写入一个新命令。此时命令在回环接口缓冲区中,但为了被服务器读取,内核需要调度服务器进程(当前被阻塞在系统调用中)运行,依此类推。因此,从实际操作的角度来看,回环接口仍然涉及网络类似的延迟,因为内核调度器的工作方式。基本上,一个死循环的基准测试在网络服务器上进行性能测量时是最愚蠢的方式。明智的做法是避免以这种方式进行基准测试。
键空间通知
键空间通知允许客户端订阅 Pub/Sub 渠道,以接收影响 Redis 数据集的事件。可以接收的事件示例包括:
- 所有影响某个键的命令。
- 所有执行
LPUSH操作的键。 - 数据库 0 中的所有过期键。
注意:Redis Pub/Sub 是发射即忘(fire and forget)模式;即如果你的 Pub/Sub 客户端断开连接并在稍后重新连接,则在客户端断开期间发送的所有事件都将丢失。
事件的类型
键空间通知通过发送两种不同类型的事件来实现,这些事件针对影响 Redis 数据空间的每个操作。例如,对数据库 0 中名为 mykey 的键执行 DEL 操作将触发两个消息的发送,这两个消息分别对应以下两个 PUBLISH 命令:
PUBLISH __keyspace@0__:mykey del
PUBLISH __keyevent@0__:del mykey
第一个频道监听所有针对键 mykey 的事件,第二个频道仅监听针对键 mykey 的 del 操作事件。第一种事件类型(频道以 __keyspace__ 前缀开头)称为键空间通知(Key-space notification),而第二种事件类型(频道以 __keyevent__ 前缀开头)称为键事件通知(Key-event notification)。
在上述示例中,针对键 mykey 生成了一个 del 事件,从而产生了两个消息:
- 键空间频道接收到的消息是事件名称。
- 键事件频道接收到的消息是键的名称。
可以仅启用其中一种通知,以只接收我们感兴趣的事件子集。
配置
默认情况下,键空间事件通知是禁用的,因为尽管它的开销不大,但会消耗一些 CPU 资源。可以通过 redis.conf 中的 notify-keyspace-events 参数或通过 CONFIG SET 命令来启用通知。将该参数设置为空字符串会禁用通知。要启用该功能,需要使用非空字符串,该字符串由多个字符组成,每个字符具有特定含义,如下表所示:
K:键空间事件,通过__keyspace@<db>__前缀发布。E:键事件,通过__keyevent@<db>__前缀发布。g:通用命令(非特定类型),如DEL、EXPIRE、RENAME等。$:字符串命令l:列表命令s:集合命令h:哈希命令z:有序集合命令t:流命令d:模块键类型事件x:过期事件(每当键过期时生成的事件)e:驱逐事件(当键因内存限制被驱逐时生成的事件)m:键未命中事件(当访问一个不存在的键时生成的事件)n:新键事件(注意:不包括在A类中)A:表示 “g$lshztxed” 的别名,即 “AKE” 字符串表示除了 “m” 和 “n” 之外的所有事件。
字符串中至少应包含 K 或 E,否则无论字符串的其他部分如何,都不会传递任何事件。例如,要仅启用列表的键空间事件,配置参数应设置为 Kl,以此类推。可以使用字符串 KEA 来启用大多数类型的事件。
不同命令产生的事件
不同的命令会生成不同类型的事件,详情请阅读原文。
时间和过期事件
与 Redis 相关的过期键有两种过期方式:
- 当键被命令访问时,如果发现其已过期。
- 通过后台系统逐步查找过期的键,以便收集那些从未被访问过的键。
过期事件是在上述系统之一发现键已过期时生成的,因此不能保证 Redis 服务器能够在键的生存时间(TTL)达到零时生成过期事件。如果没有命令不断访问该键,并且有许多带有 TTL 的键,可能会在键的 TTL 降至零与生成过期事件之间存在显著的延迟。过期事件是在 Redis 服务器删除键时生成的,而不是在 TTL 理论上达到零时生成的。
集群中的事件
Redis集群的每个节点都会生成关于自己的键空间子集的事件。然而,与集群中常规的Pub/Sub通信不同,事件通知不会广播到所有节点。换句话说,键空间事件是特定于节点的。这意味着要接收集群的所有键空间事件,客户端需要订阅每个节点。
使用Redis的方式
批量加载
批量加载是将大量现有数据加载到 Redis 中的过程。理想情况下,您希望快速、高效地执行此操作。本文档介绍了一些在 Redis 中进行批量加载数据的策略。
使用Redis协议进行批量加载
使用普通的 Redis 客户端来执行批量加载并不是一个好主意,原因有几个:
- 以逐个发送命令的方式进行操作效率很低,因为每个命令都需要等待往返时间 (RTT)。
- 虽然可以使用管道 (pipelining) 技术,但在加载大量记录时,需要同时写入新命令并读取响应,以确保尽可能快地插入数据。
只有少数客户端支持非阻塞 I/O,并且并非所有客户端都能够有效地解析响应,从而最大化吞吐量。由于以上原因,批量导入数据到 Redis 的首选方法是生成一个包含 Redis 协议的文本文件,以原始格式调用插入所需数据的命令。
例如,如果我需要生成一个包含数十亿个键的数据集,格式为 keyN -> ValueN,我会创建一个文件,其中包含以下格式的命令:
SET Key0 Value0
SET Key1 Value1
...
SET KeyN ValueN
一旦创建了这个文件,剩下的任务就是尽可能快地将它导入 Redis。过去,这通常通过使用 netcat 命令来实现:
(cat data.txt; sleep 10) | nc localhost 6379 > /dev/null
然而,这种方法并不可靠,因为 netcat 无法准确知道何时所有数据已传输完成,也无法检查错误。在 Redis 2.6 或更高版本中,redis-cli 工具支持一种新的模式,称为管道模式 (pipe mode),专门设计用于批量加载。
使用管道模式的命令如下所示:
cat data.txt | redis-cli --pipe
执行后,会得到类似如下的输出:
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000000
redis-cli 工具还会确保仅将 Redis 实例接收到的错误重定向到标准输出。
生成Redis协议
Redis 协议非常简单,易于生成和解析,其具体实现方式在 Redis 文档中有详细描述。不过,为了实现批量加载的目标,你不需要理解协议的每一个细节,只需知道每个命令是以下列方式表示的:
*<args><cr><lf>
$<len><cr><lf>
<arg0><cr><lf>
<arg1><cr><lf>
...
<argN><cr><lf>
其中,<cr> 表示 \r(或 ASCII 字符 13),<lf> 表示 \n(或 ASCII 字符 10)。
例如,SET key value 命令在协议中的表示如下:
*3<cr><lf>
$3<cr><lf>
SET<cr><lf>
$3<cr><lf>
key<cr><lf>
$5<cr><lf>
value<cr><lf>
或用字符串表示:
"*3\r\n$3\r\nSET\r\n$3\r\nkey\r\n$5\r\nvalue\r\n"
你需要生成的批量加载文件,就是由上述格式表示的命令组成的一个接一个的序列。
以下是一个生成有效协议的 Ruby 函数示例:
def gen_redis_proto(*cmd)
proto = ""
proto << "*"+cmd.length.to_s+"\r\n"
cmd.each{|arg|
proto << "$"+arg.to_s.bytesize.to_s+"\r\n"
proto << arg.to_s+"\r\n"
}
proto
end
puts gen_redis_proto("SET","mykey","Hello World!").inspect
使用上述函数,可以轻松生成键值对协议,如下所示:
(0...1000).each{|n|
STDOUT.write(gen_redis_proto("SET","Key#{n}","Value#{n}"))
}
然后,我们可以将这个程序直接通过管道传递给 redis-cli,以执行我们的首次批量导入操作。
$ ruby proto.rb | redis-cli --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000
这将生成 1000 个键值对,并通过 redis-cli 进行批量加载。
管道模式是如何在引擎下工作的
在 redis-cli 的管道模式中,关键的“魔法”在于如何像 netcat 一样快速地将数据发送到服务器,同时还能在发送的最后一条回复时正确地理解并识别出来。
这通过以下方式实现:
redis-cli --pipe尽可能快地将数据发送到服务器。- 同时,它会在有数据可用时读取数据并尝试解析它。
- 一旦从标准输入读取不到更多数据,它会发送一个特殊的
ECHO命令,其中包含一个随机生成的 20 字节字符串:我们确定这是发送的最后一个命令,并且可以通过检查是否收到相同的 20 字节作为批量回复来匹配该回复。 - 一旦发送了这个特殊的最终命令,接收回复的代码将开始匹配这些 20 字节的回复。一旦匹配到这个回复,它就可以成功退出。
通过这个技巧,我们无需解析发送给服务器的协议来了解我们发送了多少命令,只需解析收到的回复即可。
然而,在解析回复的同时,我们会计数所有解析的回复,这样在结束时我们就能够告诉用户在此次批量插入会话中传输到服务器的命令数量。
分布式锁
分布式锁在许多需要不同进程以互斥方式操作共享资源的环境中是非常有用的原语。
有许多库和博客文章描述了如何使用 Redis 实现分布式锁管理器 (DLM),但每个库使用的方法都不同,并且许多方法使用的是简单的实现方式,保证性较低,而通过稍微复杂的设计可以实现更高的保证。
本文描述了一种更规范的算法来使用 Redis 实现分布式锁。我们提出了一种称为 Redlock 的算法,它实现了一个分布式锁管理器,我们认为该算法比简单的单实例方法更安全。我们希望社区能够对此进行分析、提供反馈,并将其作为实现更复杂或替代设计的起点。
安全性和活性
我们将通过三项属性来建模我们的设计,从我们的角度来看,这是有效使用分布式锁所需的最低保证。
- 安全属性:互斥性。 在任何给定时刻,只有一个客户端可以持有锁。
- 活性属性 A:无死锁。 最终,总是可以获得锁,即使锁定资源的客户端崩溃或发生分区。
- 活性属性 B:容错性。 只要大多数 Redis 节点保持正常运行,客户端就能够获取和释放锁。
为什么基于故障转移的实现还不够
为了理解我们想要改进的内容,让我们分析一下目前大多数基于 Redis 的分布式锁库的现状。
使用 Redis 锁定资源的最简单方法是创建一个实例中的键。这个键通常会设置有限的生存时间,使用 Redis 的过期功能,以便最终释放(在我们的列表中是属性 2)。当客户端需要释放资源时,它会删除这个键。
从表面上看,这种方法有效,但存在一个问题:这是我们架构中的单点故障。如果 Redis 主节点发生故障怎么办?好吧,我们可以添加一个副本!并在主节点不可用时使用副本。不幸的是,这种做法是不可行的。这样做会导致我们无法实现互斥性(安全属性),因为 Redis 的复制是异步的。
这个模型存在竞态条件:
- 客户端 A 在主节点上获取锁。
- 主节点在将键的写入操作传输到副本之前崩溃。
- 副本被提升为主节点。
- 客户端 B 对与客户端 A 已经持有锁的相同资源获取锁。安全性违背!
在某些特殊情况下,例如在发生故障期间,多个客户端同时持有锁可能是完全可以接受的。如果是这种情况,您可以使用基于复制的解决方案。否则,我们建议实现本文描述的解决方案。
单例分布式锁的正确实现
在尝试克服上述单实例设置的限制之前,让我们首先检查如何在这种简单情况下正确地执行,因为这实际上在某些应用中是一个可行的解决方案,如果偶尔出现竞态条件是可以接受的,并且因为单实例的锁定是我们在此描述的分布式算法的基础。
为了获取锁,可以使用以下方式:
SET resource_name my_random_value NX PX 30000
这个命令会在键不存在时设置它(NX 选项),并设置过期时间为 30000 毫秒(PX 选项)。键被设置为值“my_random_value”。这个值必须在所有客户端和所有锁请求中是唯一的。
基本上,随机值用于以安全的方式释放锁,使用一个脚本告诉 Redis:仅在键存在且键中存储的值正好是我期望的值时才删除键。这是通过以下 Lua 脚本实现的:
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
这很重要,以避免删除由其他客户端创建的锁。例如,一个客户端可能获取了锁,但在执行某个操作时被阻塞,超过了锁的有效时间(即键的过期时间),然后在另一个客户端已经获取锁之后删除它。使用仅仅 DEL 是不安全的,因为一个客户端可能会删除另一个客户端的锁。使用上述脚本,每个锁都用一个随机字符串“签名”,因此只有当锁仍然是客户端尝试删除时设置的那个锁时,才会被删除。
这个随机字符串应该是什么?我们假设它是来自 /dev/urandom 的 20 字节,但你可以找到更便宜的方法来确保它的唯一性。例如,可以使用 /dev/urandom 来播种 RC4,并从中生成伪随机流。更简单的解决方案是使用具有微秒精度的 UNIX 时间戳,将时间戳与客户端 ID 连接起来。虽然这不如前者安全,但对于大多数环境来说可能足够。
“锁有效时间”是我们用作键的生存时间的时间。这既是自动释放时间,也是客户端在另一客户端能够再次获取锁之前需要执行所需操作的时间,这在技术上不会违反互斥性保证,互斥性保证仅限于从获取锁时起的特定时间窗口。
所以现在我们有了获取和释放锁的好方法。使用这个系统,对于由单个始终可用的实例组成的非分布式系统的推理是安全的。让我们将这个概念扩展到一个没有这种保证的分布式系统中。
RedLock算法
在分布式版本的算法中,我们假设有 N 个 Redis 主节点。这些节点是完全独立的,因此我们不使用复制或其他隐式协调系统。我们已经描述了如何在单个实例中安全地获取和释放锁。我们默认算法将使用这种方法在单个实例中获取和释放锁。在我们的示例中,我们设置了 N=5,这个值是合理的,因此我们需要在不同的计算机或虚拟机上运行 5 个 Redis 主节点,以确保它们在大多数情况下以独立的方式发生故障。为了获取锁,客户端执行以下操作:
- 获取当前时间(以毫秒为单位)。
- 依次尝试在所有 N 个实例中获取锁,在所有实例中使用相同的键名和随机值。在第 2 步中,当在每个实例中设置锁时,客户端使用一个小于总锁自动释放时间的超时值。例如,如果自动释放时间为 10 秒,则超时值可以在 ~5-50 毫秒范围内。这防止客户端因尝试与一个不可用的 Redis 节点通信而被长时间阻塞:如果某个实例不可用,我们应该尽快尝试与下一个实例通信。
- 计算获取锁所经过的时间,通过从当前时间减去在第 1 步中获得的时间戳。如果并且仅当客户端能够在大多数实例中(至少 3 个)成功获取锁,并且获取锁所花费的总时间小于锁的有效时间,则认为锁已成功获取。
- 如果锁被成功获取,其有效时间被认为是初始有效时间减去在第 3 步中计算的经过时间。
- 如果客户端未能成功获取锁(无论是因为它未能锁定 N/2+1 个实例,还是有效时间为负),它将尝试解锁所有实例(即使是它认为未能锁定的实例)。
算法是异步的吗
该算法依赖于以下假设:虽然进程之间没有同步时钟,但每个进程的本地时间大致以相同的速率更新,与锁的自动释放时间相比,存在一个小的误差范围。这一假设与实际计算机情况相似:每台计算机都有一个本地时钟,我们通常可以依赖不同计算机的时钟漂移较小。
在这一点上,我们需要更好地指定我们的互斥规则:只有当持有锁的客户端在锁的有效时间(如第 3 步中获得)内完成其工作,并减去一些时间(仅几毫秒,以补偿进程之间的时钟漂移)时,互斥才会得到保证。
有关类似系统所需的时钟漂移边界的更多信息,请参见本文:Leases: an efficient fault-tolerant mechanism for distributed file cache consistency。
失败时重试
释放锁
安全参数
活性参数
性能、崩溃恢复和fsync
二级索引
Redis 不是传统意义上的键值存储,因为其值可以是复杂的数据结构。然而,它提供了一个外部的键值接口:在 API 层面上,数据是通过键名进行访问的。可以说,Redis 本质上只提供了主键访问。不过,由于 Redis 是一个数据结构服务器,它的功能可以用于创建索引,包括不同类型的二级索引和复合(多列)索引。本节解释了如何使用 Redis 的以下数据结构创建索引:
- 有序集合:
- 数值索引:适用于按数值字段进行索引。例如,可以按 ID 或其他数值属性索引项。有序集合允许快速查询值的范围。
- 词典顺序索引:可以使用带有词典顺序范围的有序集合来创建更高级的索引,包括复合索引,即将多个字段组合成一个有序集合。还可以使用有序集合实现图遍历索引。
- 集合:
- 随机索引:集合适用于创建随机索引或维护唯一的项集合。虽然不支持有序查询,但在成员检查和基本操作上非常高效。
- 列表:
- 可迭代索引:列表可以用于简单的可迭代索引,例如维护最后 N 项,或创建需要遍历的有序序列。
虽然 Redis 能够处理这些类型的索引,但评估是否关系型数据库更适合复杂查询或涉及高级索引的场景是很重要的。在缓存场景中或需要高速访问索引数据时,Redis 索引可以非常有效。
使用排序集的简单数值索引
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » RedisStack十部曲之二:Redis的核心概念

发表评论 取消回复